LDAM 손실 함수를 활용한 클래스 불균형 상황에서의 옷차림 T.P.O 추론 모델 학습
서울대학교 산업공학과 박사 과정, ai.m 연구원박종혁
Learning T.P.O Inference Model of Fashion Outfit Using LDAM Loss in Class Imbalance
Jonghyuk Park
Ph. D. Candidate, Division of Industrial Engineering, Seoul National University Researcher, ai.m
요 약 의복을 착용하는데 있어 목적 상황에 부합하는 옷차림을 구성하는 것은 중요하다. 따라서 인공지능 기반의 다양 한 패션 추천 시스템에서 의복 착용의 T.P.O(Time, Place, Occasion)를 고려하고 있다. 하지만 옷차림으로부터 직접 T.P.O를 추론하는 연구는 많지 않은데, 이는 문제 특성 상 다중 레이블 및 클래스 불균형 문제가 발생하여 모델 학습을 어렵게 하기 때문이다. 이에 본 연구에서는 label-distribution-aware margin(LDAM) loss를 도입하여 옷차림의 T.P.O를 추론할 수 있는 모델을 제안한다. 모델의 학습 및 평가를 위한 데이터셋은 패션 쇼핑몰로부터 수집되었고 이를 바탕으로 성능을 측정한 결과, 제안 모델은 비교 모델 대비 모든 T.P.O 클래스에서 균형잡힌 성능을 보여주는 것을 확인할 수 있었다.
주제어 : 융합, 패션, T.P.O, 다중 레이블, 클래스 불균형, 딥러닝
Abstract When a person wears clothing, it is important to configure an outfit appropriate to the intended occasion. Therefore, T.P.O(Time, Place, Occasion) of the outfit is considered in various fashion recommendation systems based on artificial intelligence. However, there are few studies that directly infer the T.P.O from outfit images, as the nature of the problem causes multi-label and class imbalance problems, which makes model training challenging. Therefore, in this study, we propose a model that can infer the T.P.O of outfit images by employing a label-distribution-aware margin(LDAM) loss function. Datasets for the model training and evaluation were collected from fashion shopping malls. As a result of measuring performance, it was confirmed that the proposed model showed balanced performance in all T.P.O classes compared to baselines.
Key Words : Convergence, Fashion, T.P.O, Multi-label problem, Class imbalance problem, Deep learning
*Corresponding Author : Jonghyuk Park([email protected]) Received February 1, 2021
Accepted March 20, 2021 Revised February 26, 2021
Published March 28, 2021
1. 서론
사람은 단순히 신체의 특정 부위를 가리기 위해 옷을 입지 않는다. 일반적으로, 각자가 속해있는 문화권에 따
라 T.P.O(Time, Place, Occasion)에 맞게 옷차림을 구 성하게 된다[1,2]. 따라서 옷차림을 통해 의복 착용자의 목적 시간, 장소, 계기 등을 파악할 수 있으며 이러한 정 보를 학습한 모델은 여러 산업에서 다양한 방식으로 활
용될 수 있다. 예를 들어 사회 관계망 서비스(Social Network Service, SNS)의 경우, 이용자들은 본인의 이 미지를 관련 태그(Tag)와 함께 공개한다. 이때 옷차림 이 미지의 T.P.O 태그를 자동으로 추천해주는 서비스를 통 해 이용자의 편의성을 높일 수 있다.
T.P.O 추론 모델은 또한 패션 관련 다른 인공지능 기 반 서비스에도 활용 가능하다. 합성곱 신경망[3]이 이미 지 기반 데이터의 처리에 효과적임이 밝혀지면서[4-7]
패션 산업에서도 이를 활용한 서비스가 개발되고 있다.
그중 옷차림 추천 서비스의 경우 옷차림 구성의 목적 상 황이 고려되어야 이에 부합하는 옷차림을 추천할 수 있 다. 따라서 옷차림 추천 서비스를 위한 인공지능 모델을 학습하려면 관련 이미지와 T.P.O 쌍으로 구성된 데이터 셋이 필요하다. 하지만 우리가 아는 바에 따르면, 패션 이 미지의 T.P.O 정보가 포함되어 있는 패션 데이터셋은 공 개되어 있는 것이 없다. 따라서 옷차림의 목적 상황을 추 론할 수 있는 모델이 있다면, 자기 지도 학습 (Self-supervised Learning)을 통해 옷차림의 목적 상 황을 고려한 패션 추천 모델의 학습이 가능해진다.
이렇게, T.P.O 추론 모델은 다방면으로 활용 가능하 지만 이에 대한 연구는 찾아보기 힘들다. 이는 모델 학습 을 어렵게 하는 세 가지 이유로부터 기인한다. 먼저, 위에 서도 언급한 학습 및 평가를 위한 데이터셋이 존재하지 않는다는 점이 연구를 진행하기 어렵게 한다. 두 번째로, 한 옷차림이 여러 상황에서 착용 가능할 수 있기 때문에 패션 이미지가 다중 레이블을 갖게 되어 단일 레이블 문 제보다 모델 학습이 어렵게 된다. 마지막으로, 데이터 수 집 과정에서 클래스 불균형 문제(Class imbalance problem)에 직면하게 된다. 빈번하게 발생하는 상황에 서 착용하는 옷차림의 경우 데이터를 수집하기 쉽지만, 장례 복장같은 특별한 옷차림의 이미지는 상대적으로 수 집하기 어렵다. 이러한 특징으로부터 클래스 불균형 문제 가 발생하기 때문에 이를 고려한 모델 학습이 수행되지 않으면 이미지 수가 부족한 클래스에 대한 T.P.O 인식 성능이 떨어지게 된다.
따라서 본 연구에서는 label-distribution-aware margin(LDAM) 손실 함수[8]를 도입하여 클래스 불균형 문제가 만들어내는 이미지 수가 부족한 클래스에 대한 낮은 성능을 개선하였다. LDAM 손실 함수는 손실 계산 시 학습 데이터셋의 클래스별 샘플 수가 반영한다. 이는 모델의 클래스별 분류 경계를 조절하게 하여 샘플 수가 부족한 클래스에 대해서도 상대적으로 우수한 성능을 만 들어낸다. 우리는 ResNet-50[9] 기반의 합성곱 신경망
을 다중 레이블을 위한 LDAM 손실 함수로 학습하여 모 델의 편향 추론을 개선하였다.
학습 및 평가를 위한 이미지는 한국의 패션 쇼핑몰로 부터 수집되었다. 또한 T.P.O 클래스는 패션 전문가들에 의해 선정된 총 11개의 클래스 중에서 선택되도록 하였다.
수집한 데이터셋으로 모델을 학습하고 평가한 결과 제 안 모델은 비교 모델 대비 모든 클래스에서 전반적으로 우수한 성능을 보이는 것을 확인할 수 있었다. 특히 샘플 수가 부족한 클래스의 성능이 향상될 때 발생하는 샘플 수가 많은 클래스의 성능이 떨어지는 현상[10]이 완화되 는 것을 확인할 수 있었다.
본 논문의 구성은 다음과 같다. 2장은 관련 연구에 대 해 설명한다. 특히, 패션 관련 인공지능 연구 동향과 클래 스 불균형이 만들어내는 편향 추론을 해소하기 위해 제 안된 손실 함수를 살펴본다. 3장에서는 제안 모델의 구조 및 학습 방법에 대해서 기술한다. 4장에서는 사용한 데이 터셋을 소개하고, 실험을 위한 설정과 실험 결과에 대해 논한다. 마지막으로 5장에서는 본 연구의 의의 및 추후 연구 방향에 대해 기술한다.
2. 관련 연구 2.1 패션 인공지능 연구
딥러닝 기반의 인공지능 연구가 이미지 데이터의 처리 에 효과적인 것이 밝혀지면서, 패션 관련 인공지능 연구 또한 활발히 제안되고 있다. 구체적으로, 옷차림 추천, 의 상 종류 분류 문제[11,12], 패션 아이템 검출 및 영역 분 리[13,14], 패션 스타일 인식[15] 등 다양한 영역에서 연 구가 시도되고 있다.
앞에서 언급한 것처럼, 옷차림 추천 연구에서는 옷차 림의 목적 상황을 주로 활용한다. Verma[16]는 합성곱 신경망을 통해 이미지의 특징을 추출하여 목적 상황을 나타내는 군집과의 유사도를 계산하였다. 이를 통해 유사 도가 가장 높은 군집에 속하는 결과들을 이용자에게 제 시함으로써 배경 정보가 없는 새로운 이용자에 대해서도 효과적으로 작동할 수 있는 추천 시스템을 제안하였다.
Ma[17]는 SNS에서 데이터를 수집하여 이로부터 사람, 의복의 종류, 목적 상황 등의 패션 지식을 추출하였다. 그 리고 추출된 패션 지식을 활용하여 bidirectional long short term memory(BiLSTM)[18] 기반의 모델을 학습 시켜 패션 지식에 부합하는 이미지가 검출 가능하도록 하였다.
Fig. 1. T.P.O inference with the ResNet-50 한편, Takagi[19]는 일본의 패션 쇼핑몰에서 수집한
패션 스타일 데이터셋을 제안하면서 합성곱 신경망 기반 모델을 통해 패션 이미지의 스타일을 학습하였다. 또한, 여러 합성곱 신경망으로 비교 실험을 수행하여 ResNet-50 신경망이 가장 우수한 성능을 보이는 것을 확인하였다.
위와 같은 실험 결과를 바탕으로 본 연구에서도 ResNet-50 기반의 합성곱 신경망으로 패션 이미지의 T.P.O를 추론하고자 한다.
2.2 클래스 불균형 상황에서의 손실 함수
Lin[20]은 cross entropy 손실 함수를 발전시켜 분류 가 쉬운 학습 데이터에 대해서는 가중치를 작게 하는 focal 손실 함수를 제안하였다. 이를 통해 학습 모델이 상대적으로 더 어려운 학습 데이터에 집중하게 하였다.
Li[21]는 학습 데이터의 클래스별 샘플 수에 따른 gradient norm의 분포를 측정하여 쉬운 샘플들과 이상 치에 가까운 아주 어려운 샘플이 학습에 큰 영향을 미친 다는 사실을 발견하였다. 이에 저자들은 손실 함수에서 쉬운 샘플과 아주 어려운 샘플에 대한 가중치를 낮춤으 로써 클래스 불균형 상황에서의 성능을 개선하였다.
한편, LDAM 손실 함수는 학습 데이터셋의 클래스별 샘플 수를 손실 함수에 반영, 클래스의 분류 경계를 조절 하여 클래스 불균형 상황에서 학습 시 분류 성능을 향상 시킨다. LDAM 손실 함수를 제안한 저자들은 클래스 에 대해서 분류 경계까지의 마진(Margin) 이 클래스 별 샘플 수 의 1/4승에 비례하는 것을 보이면서, 이를 활용하여 cross entropy 손실 함수와 결합된 형태의 LDAM 손실 함수를 제안하였다.
ℒ log
∆
≠
∆
(1)
∆
∈ … (2)
식 (1)에서 는 클래스를 의미하고 는 클래스 에 해당하는 logit 값이다. 또한, 식 (2)의 하이퍼 파라미터 (Hyper-parameter) 는 상수 값, 은 클래스의 개수 이다. 본 연구에서는 LDAM 손실 함수를 사용하여 클래 스 불균형 상황에서의 T.P.O 추론 성능을 개선하고자 한 다. 또한 focal 손실 함수로 학습한 모델을 비교 모델로 하여 테스트 데이터셋의 성능을 비교한다.
3. T.P.O 추론 모델
Fig. 1에서 확인할 수 있는 것처럼 옷차림의 T.P.O는 ResNet-50 기반의 합성곱 신경망으로 추론된다. 이어 나오는 3.1절에서는 먼저 ResNet-50 구조와 이를 활용 한 T.P.O 추론 모델에 대해서 살펴보고, 3.2절에서는 구 체적인 학습 방법에 대해 기술한다.
3.1 ResNet-50을 활용한 T.P.O 추론 모델 ResNet-50 구조는 총 4개의 합성곱 블락 (Convolution block)을 바탕으로 이미지의 특징을 추 출할 수 있는 모델이다. 크기가 조절된 이미지는 7×7의 filter 크기를 갖는 합성곱 연산을 통해 64개의 feature map을 생성한다. Max pooling을 통해 크기가 작아진 64개의 feature map은 그 이후 4개의 합성곱 블락 (Convolution block)을 거치게 된다. Fig. 2에서 확인 할 수 있는 것처럼, 합성곱 블락은 합성곱 연산과 rectified linear unit(ReLU)[22] 활성 함수로 구성되어 있다. 3개의 합성곱 블락을 통해 계산된 값은 합성곱 블 락의 최초 입력 값과 더해져 합성곱 블락의 출력 값을 만
Fig. 2. Convolution block
들게 되는데, 이를 통해 역전파를 통한 학습에서 gradient가 0에 가깝게 되어 가중치가 갱신되지 않는 gradient vanishing 문제를 완화하게 된다.
ResNet-50은 총 네 가지 형태의 합성곱 블락을 활용 한다. 각 합성곱 블락들은 3번, 4번, 6번, 3번 반복되어 각각 256개, 512개, 1024개, 2048개의 feature map을 생성하게 되며, global average pooling을 통해 최종적 으로 2048 차원의 벡터를 만들어낸다. 이를 fully- connected layer의 입력 값으로 하여 각 T.P.O 클래스 에 해당하는 logit 값을 계산하게 된다.
3.2 모델 학습
모델의 모든 학습 파라미터들은 ImageNet 데이터셋 으로 학습된 값들로 초기화되었고, 이후 T.P.O 데이터셋 으로 미세조정된다. 미세조정 시, RGB의 3차원으로 표 현된 옷차림의 이미지는 모델에 투입되기 전 크기가 조 절된다(Fig. 1의 Resizing and cropping 단계).
224×224의 크기로 조절된 이미지는 ResNet-50 모델 을 통해 각 T.P.O 클래스에 해당하는 logit 값을 생성한 다. 생성된 logit 값은 sigmoid 활성 함수로 0에서 1 사 이의 값을 갖게 되고, 이로부터 식 (1)을 통해 손실이 계 산된다. 손실은 확률적 경사하강법으로 역전파된다. 이때 momentum 은 0.9, learning rate의 초기 값은 0.001 을 사용하였으며 L2 정규화를 통해 과적합을 방지하였
다. 또한 learning rate는 매 epoch 모델 평가 데이터 셋을 통해 손실을 계산하여 개선되지 않으면 0.1의 비율 로 감소하도록 설계되었다. 한편, 식 (2)의 는 LDAM 손실 함수를 제안한 저자들이 공식 홈페이지에서 제공하 는 값으로, 식 (3)와 같이 설정되었다.
×
∈ …max (3)
4. 실험 4.1 데이터셋
T.P.O 추론을 위한 학습 및 평가 데이터셋은 한국 여 성복 쇼핑몰로부터 수집되었다. 수집된 이미지는 패션 전 문가에 의해 선정된 11개의 T.P.O(비즈니스(Business), 비즈니스 캐쥬얼(Business casual), 면접(Interview), 데일리룩(Daily), 홈웨어(Homewear), 레저/바캉스(Leisure), 데이트(Date), 하객(Guest), 조문(Condolence), 파티 (Party), 상견례(Family)) 중 이미지에 해당하는 T.P.O 로 레이블링 되었다. 각 T.P.O에 해당하는 이미지 예시 는 Fig. 3에 나타나 있다. 이렇게 구성된 이미지-레이블 쌍은 총 9,805장의 이미지를 포함하고 있으며, 한 이미 지는 최소 1개에서 최대 6개의 T.P.O 레이블을 갖고 있 다. Fig. 4는 한 이미지가 여러 개의 T.P.O 레이블을 갖 는 이미지 예시로, 이미지 당 3개의 T.P.O 레이블을 갖 는 것을 확인할 수 있다. 각 T.P.O 레이블 개수에 따른 이미지의 수의 분포는 Table 1과 같다.
Fig. 3. Examples of T.P.O dataset
Fig. 4. Examples of T.P.O annotation
The number of T.P.O
labels The number of images
1 4,219
2 4,331
3 1,050
4 175
5 24
6 6
Table 1. The number of images corresponding to the number of T.P.O labels
한편, 수집한 T.P.O 데이터셋에는 서론에서 언급한 것처럼 문제의 특성으로부터 기인하는 클래스 불균형이 존재한다. Fig. 5는 수집한 T.P.O 데이터셋의 클래스별 이미지 수 분포를 나타낸 그래프로, 일상적인 상황에서 착용하는 데일리룩의 경우 7,027장의 이미지가 수집되 었지만, 특수한 상황인 조문이나 면접의 경우, 각각 65 장, 19장의 적은 이미지가 수집된 것을 확인할 수 있다.
Fig. 5. Distribution of the number of images in the collected T.P.O dataset
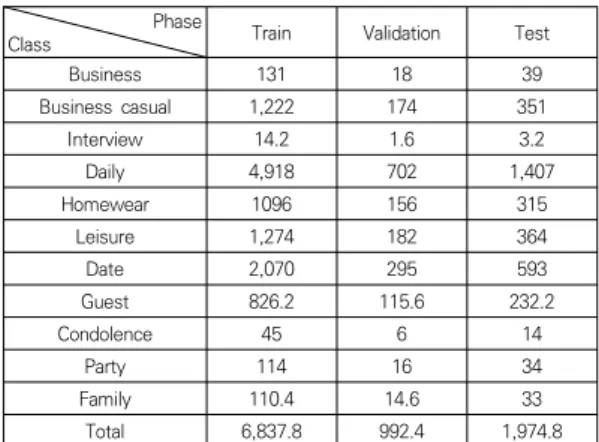
모델 학습 및 평가를 위하여 각 T.P.O 별 70%의 이미 지는 학습용으로, 10%의 이미지는 모델 평가용으로, 나 머지 20%를 테스트용으로 분리하였다. 이때 다양한 학습 데이터셋으로 모델을 학습시키고 평가하기 위해 위와 같 은 구성 비율을 갖는 총 5개의 무작위 추출(random sampling) 분리 데이터셋을 생성하였다. 이 데이터셋들 의 각 T.P.O 클래스별 평균 샘플 수는 Table 2와 같다.
Phase
Class Train Validation Test
Business 131 18 39
Business casual 1,222 174 351
Interview 14.2 1.6 3.2
Daily 4,918 702 1,407
Homewear 1096 156 315
Leisure 1,274 182 364
Date 2,070 295 593
Guest 826.2 115.6 232.2
Condolence 45 6 14
Party 114 16 34
Family 110.4 14.6 33
Total 6,837.8 992.4 1,974.8
Table 2. Average number of samples per class
이미지는 T.P.O 추론 모델에 투입되기 전 크기가 조 정되었다. 옷차림이 존재하지 않을 가능성이 높은 이미지 의 외곽 부분을 제거하기 위하여 이미지를 256×256의 크기로 조정(resizing)한 후 가운데 224×224 부분을 잘 라내어(cropping) 이를 모델의 입력 값으로 활용하였다.
또한 모델의 안정적이고 빠른 학습을 위해 ImageNet 데 이터셋의 평균과 표준편차를 활용하여 RGB 채널에 해당 하는 값을 정규화하였다.
4.2 비교 모델
제안 모델의 성능을 검증하기 위해서, 세 가지의 다른 손실 함수로 학습된 ResNet-50 모델이 고려되었다. 먼 저, binary cross entropy(BCE) 손실 함수로 학습된 모 델을 비교 모델로 선정하였다. BCE 손실 함수는 다음과 같다.
ℒ
ℒ (4)
ℒ log
log
(5) 여기서, 는 클래스 의 이진 표현이고, ⋅ 은
sigmoid 활성 함수이다.
또 다른 비교 모델은 weighted binary cross entropy(Weighted BCE) 손실 함수로 학습된 모델이 다. Weighted BCE 손실 함수는 BCE 손실 함수의 positive 클래스를 의미하는 항인 log 에 가중치
를 곱하여, 샘플 수가 적은 클래스의 경우 큰 손실 값 이 발생한다. 이를 수식으로 표현하면 다음과 같다.
ℒ
ℒ (6)
ℒ log
log
(7)
≠
(8)
마지막으로 고려된 모델은 focal 손실 함수로 학습된 모델이다. 2장에서 설명한 것처럼, focal 손실 함수는 cross entropy 손실 값이 큰, 분류하기 어려운 샘플에 대하여 더 큰 손실 값을 갖게 한다. 이를 수식으로 표현 하면 다음과 같다.
ℒ
ℒℒ (9)ℒ log
log
(10)
여기서 는 하이퍼 파라미터로, 가장 성능이 좋다고 알 려진 값인 2를 사용하였다.
4.3 평가 척도
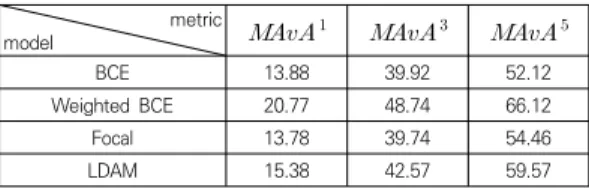
클래스 불균형 상황에서 모델의 성능을 평가하기 위하 여 본 연구에서는 macro average arithmetic ()[23,24]를 주 평가 척도로 활용하였다. 는 각 클래스별 accuracy를 산술 평균한 값으로, 본 연구에 서는 accuracy 척도로 top- accuracy()를 활용 하였다. Top- accuracy는 전체 테스트 데이터셋에서 모델의 상위 개 추론 중 정답 레이블이 포함되어 있는 테스트 샘플의 비율을 의미한다. 이를 바탕으로 Top- macro average arithmetic()를 정의하면 식 (11)과 같다.
(11)
여기서 는 클래스 의 top- accuracy를 의미 하는 것으로, 클래스 에 해당하는 모든 샘플에서 모델 의 상위 개의 추론에 클래스 가 포함되어 있는 샘플 수의 비율을 의미한다.
한편, 수집된 전체 데이터셋에서 샘플 수가 200개 미 만인 비즈니스, 파티, 상견례, 조문, 면접 클래스를 minority 클래스로 선정하여 minority 클래스에 대한 모델의 top-1 accuracy(
)값과 top-3 accuracy( ), top-5 accuracy( ) 또한 보조 평가 척도로 활용하였다. Fig. 5에서 확인할 수 있 는 것처럼, 수집한 데이터셋의 클래스를 이미지 수의 내 림차순으로 정렬했을 때 비즈니스 클래스부터 이미지 수 가 200개 미만으로 급격히 줄게 된다. 따라서 해당 클래 스들의 accuracy를 측정하여 샘플 수가 부족한 클래스 에 대한 성능을 확인하였다.
T.P.O 추론 문제는 다중 레이블 문제이기 때문에
의 경우, 샘플의 전체 레이블 중 한 개만 포함되어 도 정답으로 판정하였다. 그 이외의 경우는 상위 개의 추론에 샘플의 모든 레이블이 포함되어 있어야 정답으로 판정하였다. 만약 보다 샘플이 가지고 있는 레이블 수 가 더 크다면, 상위 개의 모든 추론이 해당 샘플의 레이 블들로 구성되어 있는 경우를 정답으로 판정하였다.
metric
model
BCE 13.88 39.92 52.12
Weighted BCE 20.77 48.74 66.12
Focal 13.78 39.74 54.46
LDAM 15.38 42.57 59.57
Table 3. Performance evaluation of models measured by macro average arithmetic metrics (%)
metric
model
BCE 0.00 0.00 1.47
Weighted BCE 4.39 18.35 40.12
Focal 0.00 0.98 9.42
LDAM 1.63 9.89 25.10
Table 4. Performance evaluation of models measured by top-k accuracy metrics for minority classes (%)
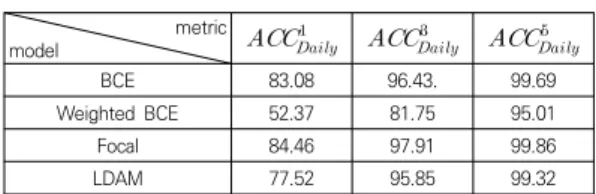
metric
model
BCE 83.08 96.43. 99.69
Weighted BCE 52.37 81.75 95.01
Focal 84.46 97.91 99.86
LDAM 77.52 95.85 99.32
Table 5. Performance evaluation of models for Daily class (%)
4.4 실험 결과 및 분석
제안 T.P.O 추론 모델인 LDAM 손실 함수로 학습된 모델과 비교 모델 각각의 지표로 평가한 결과가 Table 3, Table 4, Table 5에 제시되어 있다. 여기서 모든 성 능은 4.1에서 언급한 5개의 분리 데이터셋에 대한 평균 성능이다. 그 중 주 평가 척도인 , ,
로 평가한 결과는 Table 3에 나타나 있다.
Weighted BCE으로 학습된 모델이 세 가지 지표에 대해 평균 45.21%의 성능으로 가장 우수한 결과를 보여주었 고, LDAM 손실 함수를 활용한 제안 모델은 평균 39.17%로 두 번째로 높은 성능을 기록하였다. BCE와 focal 손실 함수로 학습된 모델을 각각 평균 35.51%, 35.59%로 weighted BCE, LDAM 손실 함수로 학습된 모델 대비 안 좋은 성능을 보여주었다.
특히 Table 4에서 확인할 수 있는 것처럼, minority 클래스에 대한 평가 척도인
에서 BCE 손실 함 수와 focal 손실 함수로 학습된 모델은 각각 세 가지 지 표 평균 0.49%와 3.46%를 기록하여 minority 클래스의 이미지를 높은 확률로 잘못 분류하였다. 반면 weighted BCE와 LDAM 손실 함수로 학습된 모델은 각각 평균 20.96%와 12.21%를 기록하여 상대적으로 우수한 성능 을 보여주었다.
하지만 weighted BCE로 학습된 모델의 경우 전체 데이터셋의 70% 이상을 차지하는 Daily 클래스에 대한 accuracy에서 평균 76.37%로 평균 90.89%의 LDAM 손실 함수로 학습된 모델 대비 낮은 성능을 기록하였다.
Weighted BCE의 경우 식 (7)에서 알 수 있는 것처럼, 손실을 계산할 때 샘플의 positive 클래스에 해당하는 항인 log 에 가중치 가 곱해진다. 클래스 불균형이 심한 데이터셋 일수록 샘플 수가 부족한 클래 스에 대한 가 커지기 때문에 이로부터 계산되는 손실 이 크게 발생하게 된다. 이는 샘플 수가 부족한 클래스에 대해 지나친 학습 파라미터 갱신을 유발하고 상대적으로 작은 가중치 가 곱해지는, 샘플 수가 많은 클래스에
대해서는 학습 파라미터 갱신이 덜 이루어지게 하여 이 에 대한 성능을 떨어뜨리게 된다. 이에 비해 LDAM 손실 함수의 경우, 마진을 재설정하여 샘플 수가 부족한 클래 스에 대한 성능을 개선함과 동시에 샘플 수가 많은 클래 스에 대한 성능도 유지하는 것을 Table 4와 Table 5를 통해 확인할 수 있다. 이로부터 LDAM 손실 함수로 학습 한 모델이 다른 비교 모델 대비 샘플 수가 많은 클래스와 샘플 수가 적은 클래스 모두에 대해서 균형잡힌 추론을 한다고 결론내릴 수 있다.
5. 결론
본 연구에서는 클래스 불균형 문제 상황에서 성능을 향상시킬 수 있는 LDAM 손실 함수를 활용하여, 클래스 불균형이 있는 T.P.O 데이터셋에 대하여 균형잡힌 추론 을 할 수 있는 모델을 제안하였다. 제안 모델은 패션 스 타일 인식에서 우수한 성능을 기록한 ResNet-50 합성 곱 신경망을 사용하여 패션 이미지의 특징을 추출하였고, LDAM 손실 함수를 사용하여 샘플 수가 부족한 클래스 에 대한 성능을 개선하였다. 모델 학습 및 성능 평가를 위하여 한국 여성복 쇼핑몰로부터 9,805장의 이미지를 수집하였고, 수집된 이미지는 패션 전문가에 의하여 선정 된 11개의 T.P.O 중 이미지에 해당하는 T.P.O로 레이블 링 되었다. 비교 모델과의 성능 비교 결과, LDAM 손실 함수로 학습된 제안 모델은 클래스 불균형 문제를 해소 하기 위한 다른 손실 함수로 학습된 모델보다 우수한 성 능을 보여주었다. 특히, 샘플 수가 많은 클래스나 샘플 수 가 적은 클래스에 치우치지 않고, 모든 클래스에 걸쳐 가 장 균형잡힌 추론을 하는 것을 확인할 수 있었다.
최근 제안된 high-resolution network(HRNet)[25]
는 고해상도의 이미지 정보를 최대한 보존하는 방식으로 ResNet-50을 비롯한 기존 합성곱 신경망의 약점을 보 완하며, ImageNet 데이터셋의 분류에서 더 우수한 성능 을 기록하였다. T.P.O 추론을 위하여 고해상도의 패션 이미지 정보를 활용하는 것이 중요한만큼, HRNet 합성 곱 신경망을 활용한다면 ResNet-50 합성곱 신경망을 사용했을 때보다 T.P.O 추론 성능을 향상시킬 수 있을 것이다.
더불어, T.P.O 추론 모델을 활용하면 서론에서 언급 한 것처럼 옷차림의 목적 상황이 고려된 옷차림 추천 모 델을 개발할 수 있기 때문에, 이것 또한 본 연구의 향후 과제라고 할 수 있다. 구체적으로, cycle consistency
손실 함수[26]를 활용하여 패션 이미지로부터 T.P.O를 추론하고, 이로부터 생성된 T.P.O 은닉 벡터가 이미지의 특징을 담고 있는 은닉 벡터와 가까워지도록 옷차림 추 천 모델을 학습시키는 방식을 통해 자기 지도 학습 형태 의 옷차림 추천 모델 학습을 시도해 볼 수 있을 것이다.
REFERENCES
[1] K. J. Tschu. (2007. Feb). Kleidungssignale als nonverbale Kommunikationsmittel. Cogito, 61, 243-260.
[2] M. J. Lee & I. S. Lee. (2012. Jan). Party Wear Industry Conditions in Korea and the Analysis of Dress Style According to Party Types. Journal of the Korean Society of Clothing and Textiles, 36(1), 12-26.
[3] Y. LeCun et al. (1990. Nov). Handwritten Digit Recognition with a Back-propagation Network. In Proceedings of the Advances in neural information processing systems (pp. 396-404).
[4] H. J. Kim, S. H. Lee, H. H. Han & J. S. Kim. (2020.
Dec). Saliency Attention Method for Salient Object Detection Based on Deep Learning. Journal of The Korea Convergence Society, 11(12), 39-47.
[5] D. W. Lee, S. H. Lee & H. H. Han. (2020. Dec). Deep Learning-based Super Resolution Method Using Combination of Channel Attention and Spatial Attention. Journal of The Korea Convergence Society, 11(12), 15-22.
[6] S. H. Sung, K. B. Lee & S. H. Park. (2020. Jun).
Research on Korea Text Recognition in Images Using Deep Learning. Journal of The Korea Convergence Society, 11(6), 1-6.
[7] D. H. Cho, Y. W. Nam, H. C. Lee & Y. H. Kim. (2019.
Sep). Image Mood Classification Using Deep CNN and Its Application to Automatic Video Generation.
Journal of The Korea Convergence Society, 10(9), 23-29.
[8] K. Cao, C. Wei, A. Gaidon, N. Arechiga & T. Ma. (2019.
Dec). Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss. In Preceedings of Advances in Neural Information Processing Systems (pp. 1567-1758).
[9] K. He, X. Zhang, S. Ren & J. Sun. (2016. Jun). Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 770-778).
[10] Y. Cui, M. Jia, T. Y. Lin, Y. Song & S. Belongie. (2019.
Jun). Class-balanced loss based on effective number of samples. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp.
9268-9277).
[11] Z. Liu, P. Luo, S. Qiu, X. Wang & X. Tang. (2016. Jun).
DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1096-1104).
[12] W. Wang, Y. Xu, J. Shen & S. C. Zhu (2018. Jun).
Attentive Fashion Grammar Network for Fashion Landmark Detection and Clothing Category Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp.
4271-4280).
[13] Y. Miao, G. Li, C. Bao, J. Zhang & J. Wang. (2020) ClothingNet: Cross-domain Clothing Retrieval with Feature Fusion and Quadruplet Loss. IEEE Access, 8, 142669-142679.
[14] M. Jia et al. (2020. Aug). Fashionpedia: Ontology, Segmentation, and an Attribute Localization Dataset.
In Proceedings of the European Conference on Computer Vision (pp. 316-332).
[15] R. Miyamoto, T. Nakajima & T. Oki. (2019. May).
Accurate Fashion Style Estimation with a Novel Training Set and Removal of Unnecessary Pixels. In Proceedings of the IEEE International Symposium on Circuits and Systems (pp. 1-5).
[16] D. Verma, K. Gulati, V. Goel & R. R. Shah. (2020. Oct).
Fashionist: Personalising Outfit Recommendation for Cold-Start Scenarios. In Proceedings of the ACM International Conference on Multimedia (pp.
4527-4529).
[17] Y. Ma, X. Yang, L. Liao, Y. Cao & T. S. Chua. (2019.
Oct). Who, Where, and What to Wear? Extracting Fashion Knowledge from Social Media. In Proceedings of the ACM International Conference on Multimedia (pp. 257-265).
[18] A. Graves & J. Schmidhuber. (2005, Jul-Aug).
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures.
Neural Networks, 18(5-6), 602-610.
[19] M. Takagi, E. Simo-Serra, S. Iizuka & H. Ishikawa, (2017. Oct). What Makes a Style: Experimental Analysis of Fashion Prediction. In Proceedings of the IEEE International Conference on Computer Vision Workshops (pp. 2247-2253).
[20] T. Y. Lin, P. Goyal, R. Girshick, K. He & P. Dollár (2017. Oct). Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (pp. 2980-2988).
[21] B. Li, Y. Liu & X. Wang (2019. Jan). Gradient Harmonized Single-stage Detector. In Proceedings of AAAI Conference on Artificial Intelligence (pp.
8577-8584).
[22] V. Nair & G. E. Hinton. (2010. Jun). Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the International Conference on Machine Learning (pp. 807-814).
[23] C. Ferri, J. Hernandex-Orallo & R. Modroiu. (2009) An experimental comparison of performance measures for classification. Pattern Recognition Letters, 30(1), 27-38.
[24] R. Alejo, J. A. Antonio, R. M. Valdovinos & J. H.
Pacheco-Sanchez. (2013. Jun). Assessments metrics for multi-class imbalance learning: A preliminary study.
in Proceedings of Mexican Conference of Pattern Recognition (pp. 335-343).
[25] J. Wang et al. (2020. Apr). Deep High-Resolution Representation Learning for Visual Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1-1.
[26] J. Y. Zhu, T. Park, P. Isola & A. A. Efros. (2017. Oct).
Unpaired Image-to-Image Translation using Cycle- Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (pp. 2223-2232).
박 종 혁(Jonghyuk Park) [정회원]
․ 2015년 2월 : 서울대학교 산업공학과 (공학사)
․ 2015년 1월 ~ 2016년 2월 : ㈜삼성전 자
․ 2016년 3월 ~ 현재 : 서울대학교 산업 공학과(석박사통합과정) 재학 중
․ 관심분야 : 컴퓨터 비전, 딥러닝, 머신 러닝 응용
․ E-Mail : [email protected]
![Fig. 1. T.P.O inference with the ResNet-50 한편, Takagi[19]는 일본의 패션 쇼핑몰에서 수집한 패션 스타일 데이터셋을 제안하면서 합성곱 신경망 기반 모델을 통해 패션 이미지의 스타일을 학습하였다](https://thumb-ap.123doks.com/thumbv2/123dokinfo/4980297.545908/3.799.425.707.560.978/inference-일본의-쇼핑몰에서-데이터셋을-제안하면서-이미지의-스타일을-학습하였다.webp)