제31회 한글 및 한국어 정보처리 학술대회 논문집 (2019년)
한국어 언어학적 특성 기반 감성분석 모델 비교 분석
김경민◦, 박찬준, 조재춘*, 임희석
고려대학교 컴퓨터학과, 상명대학교 스마트정보통신공학과*
{totoro4007, bcj1210, limhseok}@korea.ac.kr, [email protected]*
Comparative Study of Sentiment Analysis Model based on Korean Linguistic Characteristics
Gyeong-Min Kim◦, Chanjun Park, Jaechoon Jo, Heui-Seok Lim
Dept. of Computer Science and Engineering, College of Informatics, Korea University Dept. of Smart Information Communication Engineering, Sangmyung University*
요 약
감성분석이란 입력된 텍스트의 감성을 분류하는 자연어처리의 한 분야로, 최근 CNN, RNN, Transformer등의 딥러닝 기법을 적용한 다양한 연구가 있다. 한국어 감성분석을 진행하기 위해서는 형태소, 음절 등의 추가 자질을 활용하는 것이 효과적이며 성능 향상을 기대할 수 있는 방법이다. 모델 생성에 있어서 아키텍쳐 구성도 중요하지만 문맥에 따른 언어를 컴퓨터가 표현할 수 있는 지식 표현 체계 구성도 상당히 중요하다. 이러한 맥락에서 BERT모델은 문맥을 완전한 양방향으로 이해할 수있는 Language Representation 기반 모델이다. 본 논문에서는 최근 CNN, RNN이 융합된 모델과 Transformer 기반의 한국어 KoBERT 모델에 대해 감성분석 task에서 다양한 성능비교를 진행했다.
성능분석 결과 어절단위 한국어 KoBERT모델에서 90.50%의 성능을 보여주었다.
주제어: 감성분석, 딥러닝, Text Classification, KoBERT
1. 서론
감성분석(sentiment analysis)은 텍스트에 포함된 감성을 분 류하는 자연언어처리의 한 분야이다. 감성분석 기술은 트윗 데 이터를 분석하여 선거 결과를 예측하거나 뉴스, 신문기사 댓 글의 감성을 분석하여 사용자 여론을 분석하는것에 활용될 수 있다 [1]. 최근 CNN, RNN, Transformer [2] 등의 딥러닝 기법 을 활용한 text classification 연구가 활발히 진행되고 있으나 대부분 영어에 초점이 맞추어져 있다 [3]. 교착어적 특성을 갖 는 한국어의 경우 어절 단위 어휘 사전에 수많은 OOV(Out of vocabulary, OOV)가 생성될 수 있다. 이는 곧 모델의 성능과 직접적인 연관을 갖는다. 따라서 한국어 감성분석에서 효과적 인 성능을 기대하기 위한 적합한 모델 및 자질 활용은 중요한 요소이다.
한국어 감성분석에 대한 연구 중 네이버 감성분석 영화 리뷰 NSMC(Naver Sentiment Movie Corpus, NSMC)1 말뭉치를 활용한 모델에서 다양한 연구가 진행중이다. 모델 생성에 있 어 아키텍쳐를 구성하는 방법과 컴퓨터가 이해할 수 있는 체 계적인 지식 표현은 상당히 중요하다. 기존 one-hot encoding 방식의 언어 표현 방법은 언어의 의미간 관계 파악이 어려우며 단어의 개수가 곧 벡터의 차원이 되므로 메모리 낭비가 심하 다는 단점이 있다. Word2Vec, Glove, FastText의 경우 단어 가 고차원의 특정 벡터로 맵핑되는 방식으로, 단어 간의 관계 파악이 가능하고 기존 one-hot encoding 기법보다 밀집된 벡
1https://github.com/e9t/nsmc
터를 가진다는 장점이 있으나 문맥을 파악하기 어렵다는 단점 이 있다. 이러한 단점 극복을 위해 ELMO(Embedding from Language Model, ELMO) [4]는 훈련된 Bi-LSTM 신경망을 통해 word embedding을 수행하는 형태로 동작하여 동일한 단 어가 문맥에 따라 다른 벡터로 표현될 수 있도록 만든 구조 이다. 그러나 단순히 forward와 backward를 합하는(concate- nate) 방식을 취했기 때문에 완전한 양방향을 구현해낸 것은 아니다. BERT(Bidirectional Encoder Representations from Transformers, BERT) [5]는 Transformer 인코더 기반의 모델 로, random masking 기법을 통해 언어를 완전한 양방향으로 이해할 수 있는 언어적 표현(Language Representation)방식을 체계화한다. 최근 XLNET [6]과 RoBERTa [7]의 경우 BERT 가 위치정보에 대한 의존성을 고려하지 않는다는 점과 BERT 의 추가 하이퍼파라미터 튜닝 및 Dynamic Masking 기법 활 용이 가능하다는 점을 언급하며 각각 개선된 모델을 내세웠다.
그러나해당 연구들은 아직까지 한국어 특성을 반영하지 못한 다는 한계점이 있다. 단어에 따라 다양한 의미 표현을 갖는 한 국어는 영어와는 다르게 어절 단위에서 모든 텍스트를 표현할 수 없다. 따라서, 한국어 자연어처리에 있어서 교착어적 특성까 지 반영하여 모델을 구성하는 것은 무엇보다 중요하기 때문에 한국어의 형태소와 음절 등의 자질을 활용하는 자연어처리 기 법이 요구된다.
최근 공개된 KoBERT2는 한국어 대용량 코퍼스를 pre-
2http://aiopen.etri.re.kr/
- 149 -
제31회 한글 및 한국어 정보처리 학술대회 논문집 (2019년)
training하여 fine-tuning 과정을 통해 다양한 한국어 task에서 좋은 결과를 나타내었다. 본 논문에서는 한국어 영화 리뷰 데 이터를 활용하여 감성분석 task에서 다양한 방식으로 성능을 향상시킨 모델과 KoBERT 모델 성능에 대해 비교 분석하고자 한다.
본 논문의 구성은 다음과 같다. 2장에서는 한국어 감성분석 에 대해 설명하고, 3장은 감성분석 분류 모델 중 CNN, RNN 을 활용 융합한 모델과 Transformer 기반의 한국어 KoBERT 모델에 대해 설명한다. 4장에서는 실험 분석, 5장은 분석 결과, 6장은 결론에 대해 설명한다.
2. 한국어 감성분석
기존 텍스트 처리에 딥러닝 기술을 적용하여 어절단위에서 CNN 기법을 활용한 연구는 [8]가 있다. [8]는 어절 단위에 서 문맥정보를 보존하기 위한 방법으로, 실질적 의미를 가진 어간에 문법적 기능을 가진 조사나 접사 등이 결합한 교착어 적 특성을 갖는 한국어에서는 어절 단위의 사전을 사용할 경우 심각한 OOV문제를 초래한다. 한국어는 단어 형태가 변하지 않는 태국어, 미얀마어와 같은 고립어나 단어 형태의 변화로 문장에 문법적 의미를 부여하는 영어와 같은 굴절어와는 전혀 다른 성질이다. 따라서 교착어는 고립어와 굴절어에 비해 자연 언어처리 task를 진행하기가 난해하다. 최근 [9, 10, 11]에서는 이러한 문제점 극복을 위해 어절 단위뿐만 아니라 형태소, 음절 등의 추가 자질을 활용하여 보다 높은 성능 향상을 보여주었다.
이를 통해 하나의 어간에 여러 어미가 붙더라도 완벽한 어휘를 생성할 수는 없으나 기존 어절 단위에서 불가능했던 상당한 부 분을 해결할 수 있었다. 예를 들어 ‘갤럭시 노트10’라는 단어가
‘삼성갤노트10’, ‘갤놋10’, ‘갤놋’과 같이 변형된 합성어 및 줄 임말에 대해서도 모델 학습을 통해 생성된 자질은 유사한 벡터 공간에 구성을 이루고 있으므로 비슷한 예측이 가능하다. 그러 나 이러한 연구들은 동일한 문맥에서 고려된 의미이다. 하나의 단어가 서로 다른 문맥에서 다른 의미를 갖는 경우, 위의 예시는 대표적인 예가 될 수 없다. 예를 들어 ‘사과’는 ‘사과는 맛있다’
와 ‘미안해, 사과할게’라는 문장에서 서로 다른 의미의 ‘사과’로 표현되기 때문에 문맥에 따라 가변적인 자질을 필요로 한다.
3. 감성분석 분류 모델
3.1 데이터 구성
NSMC 말뭉치는 네이버 영화 리뷰 중 영화당 100개의 리뷰 를 모아 총 200,000(train data:15만, test data:5만)개의 긍정, 부정, 중립 데이터로 구성 되어있다.
평점 1∼4 사이의 리뷰들은 부정, 평점 9∼10 사이의 리뷰들 은 긍정을 나타내는 데이터로, 본 연구에서는 긍정의 경우 1, 부정은 0으로 분류된 데이터를 사용한다. 해당 데이터는 표 1
표 1. 네이버 영화 리뷰 감성 데이터 예제
문장 감성
“영화평보고 재미없을줄알았는데 너무너무재밌게봤음. 소닉붐전율” 긍정
“음악은 좀 남발된 느낌이네요.”” 부정
“재밌게봤음. 일본 소재뽑는 능력은..진짜..대단함. 2편도 기대되는데.” 긍정
“배우는 좋은데 이렇게 재미없다니...” 부정
과 같이 실제 사용자의 평가 결과로, 구어체를 포함한 데이터로 구성되어있기 때문에 맞춤법이 맞지 않거나 신조어를 사용하는 등 문법이 맞지 않은 문장을 다수 포함한다.
3.2 CNN기반 감성분석 모델
어절 기반 CNN의 문제점 극복을 위해 그림 1와 같이 형 태소, 자소, 음절 등의 자질을 활용할 수 있다. 형태소 기반의 입력 자질은 어절단위에서 해결하기 어려운 한국어 특성을 해 결할 수 있으며 음절 및 자소와 같은 더 작은 단위의 자질은 합성어나 줄임말에서의 예측을 가능하게 한다. [12]는 OOV 에 좀 더 강건한 모델 생성을 위해 음절 단위의 자질을 입력 으로 활용하였고 [13]는 문자단위와 자소단위를 CNN모델에 입력으로 사용하였으며 결과적으로 두 모델 모두 기존 CNN 모델보다 개선된 결과를 보여준다. 최근 [11]은 이러한 연구를 바탕으로 형태소, 음절, 자소 정보를 동시에 고려하여 문장의 감성을 분류하는 Multi-channel CNN 모델을 제안하였다.
그림 1. 형태소, 자소, 음절 자질 바탕의 CNN 구조
3.3 RNN기반 감성분석 모델
그림 2은 Bi-directional RNN 방식으로 기존 RNN 모델 과 크기는 동일하나 양방향으로 네트워크를 구성한다. RNN 기반의 모델은 이전 상태 정보만을 메모리에 저장하므로 Bi- directional 방식을 통해 서로 다른 방향의 정보를 활용할 수 있다. 양방향 출력을 이어붙여(concatenate) softmax를 취하 고 출력값에 따라 긍정과 부정을 분류한다. 추가적으로 CRF
- 150 -
제31회 한글 및 한국어 정보처리 학술대회 논문집 (2019년)
와 같은 층을 추가적으로 활용할 수 있으며 본 연구의 비교 실험에서는 Bi-LSTM 모델을 사용했다.
그림 2. 다양한 자질 바탕의 Bi-RNN 구조
3.4 Transformer기반 감성분석 모델
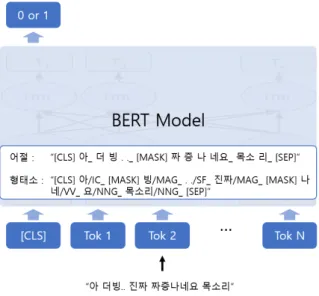
BERT는 Transformer encoder 기반의 사전 학습 모델로 random masking, next sentence prediction 과정을 통해 언 어를 완전한 양방향으로 이해할 수 있도록 구현했으며, pre- training과 fine-tuning을 통한 학습 기법은 다양한 task에서 뛰 어난성능 향상이 있음을 보였다 [5]. 그림 3에서 볼 수 있듯이 첫 번째 토큰은 [CLS] 토큰으로 입력된 문장의 함축된 정보를 포함하고 있으며 모델을 통과하여 문장의 감성을 분류한다.
그림 3. Text classification BERT 모델 구조
4. 실험 분석
본 논문의 실험 분석은 다음 표 2를 통해 확인할 수 있다.
각각의 모델과 해당 모델이 사용한 자질(features)을 나타내고 그에 따른 성능 평가 척도로 정확도(accuracy)를 사용하였다.
기본 모델로는 Y. Kim [8]의 어절단위 CNN 모델(1)을 사용했 다. 형태소 자질이 입력으로 활용된 모델(2, 4, 8)의 경우 공개된
형태소 분석기3를 사용했다. 감성분석에서의 성능 비교를 위 해 본 연구에서는 최근 공개된 한국어 특성이 반영된 KoBERT 모델을 사용한다. 대용량 코퍼스로 pre-training된 KoBERT 모델에 네이버 영화 리뷰 데이터를 사용하여 감성분석 task에 적용시키기 위한 fine-tuning과정을 수행했다. BERT의 pre- training 과정에서는 대용량 코퍼스를 학습시켜야 하므로 많은 리소스와 시간을 필요로 한다. 최근 [14]는 이러한 대용량 코퍼 스를 사용한 BERT와 달리 적은 데이터의 학습을 진행했음에도 기존 모델들에 준하는 성능을 보여주었다.
표 2. 감성분석 성능 비교 분석 결과
No. Model Features Accuracy
1 CNN [8] (어절) 79.17%
2 CNN (형태소) 84.97%
3 Multi-channel CNN [11] (형태소+음절+자소) 86.27%
4 Bi-LSTM (형태소) 85.86%
5 BERT [14] (형태소-태그) 86.57%
6 BERT-multilingual (어절) 86.40%
7 KoBERT (어절) 90.50%
8 KoBERT (형태소) 90.17%
5. 분석 결과
본 연구에서는 결과적으로 다양한 방식을 활용한 기존 모델 보다 3.91%∼11%의 성능 차이를 보였다. CNN기반의 모델 중 에서는 위 3개의 모델 중 형태소, 음절, 자소 단위의 모델(3)이 가장 좋은 성능을 보였다. 모델(2)와 동일한 형태소 단위의 Bi- LSTM모델(4)은 (3)보다 약간 낮은 성능을 나타냈다. 그리고 기존 BERT에서 공개한 multilingual모델(6)과의 비교에서도 한국어에 최적화된 KoBERT모델(7, 8)에서 더욱 성능 향상이 있음을 확인할 수 있었다. 영화 리뷰 데이터 자체에 구어체적인 문체를 포함하고 있었으므로 형태소가 제대로 분석되지 않은 경우가 발생했다. 따라서 pre-trained KoBERT 모델의 사전에 없는 형태소 어휘의 경우에도 제대로 형태소로 분석될 수 없 었다고 판단되었으며, 본 연구에서도 형태소단위 모델(8)보다 어절단위 모델(7)에서 좋은 성능을 보여주었다.
6. 결론
본 논문에서는 다양한 모델을 활용하여 감성분석에 적용 시 킨 최근 연구들과 transformer 기반 BERT 모델의 성능 비교 분석을 진행하였다. 기존 CNN,RNN에 다양한 자질을 활용한 모델보다 BERT에서 더 좋은 성능을 낼 수 있었던 것은 이유는 대용량 코퍼스를 활용한 pre-trained 과정과 문맥에 따라 다른
3https://github.com/kakao/khaiii
- 151 -
제31회 한글 및 한국어 정보처리 학술대회 논문집 (2019년)
벡터로 표현 가능한 완전한 양방향 방식이기 적용됐기 때문으 로 보여진다. 한국어 특성에 좀 더 강건한 모델을 생성하기 위 해 RoBERTa나 XLNET과 같은 모델을 한국어에 적용시켜볼 예정이다.
감사의 글
이 논문은 2018년도 정부(교육부)의 재원으로 한국 연구재단의 지원을 받아 수행된 기초연구사업임(No.
2018R1D1A1B07051369)
참고문헌
[1] L. S. Lee Hyun Gyu, “Developing a sentiment analysing and tagging system,” KIPS Transactions on Software and Data Engineering, Vol. 5, No. 8, pp. 377–384, 2016.
[2] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin,
“Attention is all you need,” Advances in neural infor- mation processing systems, pp. 5998–6008, 2017.
[3] M. Bautin, L. Vijayarenu, and S. Skiena, “International sentiment analysis for news and blogs.” ICWSM, 2008.
[4] M. E. Peters, M. Neumann, M. Iyyer, M. Gard- ner, C. Clark, K. Lee, and L. Zettlemoyer, “Deep contextualized word representations,” arXiv preprint arXiv:1802.05365, 2018.
[5] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova,
“Bert: Pre-training of deep bidirectional transform- ers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
[6] Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. Salakhutdi- nov, and Q. V. Le, “Xlnet: Generalized autoregressive pretraining for language understanding,” arXiv preprint arXiv:1906.08237, 2019.
[7] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov,
“Roberta: A robustly optimized bert pretraining ap- proach,” arXiv preprint arXiv:1907.11692, 2019.
[8] Y. Kim, “Convolutional neural networks for sentence classification,” arXiv preprint arXiv:1408.5882, 2014.
[9] 박천음, “문맥 표현 기반 한국어 영화평 감성 분석,” 제30 회 한글 및 한국어 정보처리 학술발표 논문집, pp. 75–78, 2018.
[10] 김원우, “합성 곱 신경망을 이용한 한글 텍스트 감성 분류 기 설계,” 한국정보과학회 학술발표 논문집, pp. 642–644, 2017.
[11] 김민, “Multi-channel cnn을 이용한 한국어 감성분석,”
제30회 한글 및 한국어 정보처리 학술발표 논문집, pp.
79–83, 2018.
[12] S. Choi, T. Kim, J. Seol, and S.-g. Lee, “A syllable- based technique for word embeddings of korean words,”
arXiv preprint arXiv:1708.01766, 2017.
[13] M. J. P. K. Kyounghyun Mo, Jaesun Park, “Text clas- sification based on convolutional neural network with word and character level,” Journal of the Korean Insti- tute of Industrial Engineers, Vol. 3, No. 44, pp. 180–188, 2018.
[14] 박광현, “Bert를 이용한 한국어 자연어처리: 개체명 인식, 감성분석, 의존 파싱, 의미역 결정,” 한국정보과학회 학술 발표 논문집, pp. 584–586, 2019.