J Health Tech Assess 2015;3(1):35-47 ISSN 2288-5811
Copyright © 2015 The Korean Association for Health Technology Assessment서 론
최근 정보통신 및 금융 영역뿐 아니라 보건의료 분야에서 도 빅데이터 활용에 대한 논의가 활발하다. 빅데이터를 이용 한 보건의료 연구개발 지원
1,2)및 보건의료 비용 절감 시도
3-5)그리고 산개되어 있는 보건의료 빅데이터들 간 연계의 필요 성
6)등이 논의되고 있다. Groves 등
7)은 빅데이터로 인해 보 건의료계에 일어날 것으로 예상되는 변화로서 근거에 입각
한 임상진료, 임상결과에 최적화된 의료 서비스 제공, 비용 절감과 동시에 보건의료 가치를 지속적으로 증진시킬 수 방 안 모색 및 보건의료 연구개발을 향상시킬 수 있는 혁신법 등을 손꼽았다. 또한 보건의료 빅데이터는 가치 창출을 위한 성장동력의 하나로써 보건의료 서비스 분야에 있어 새로운 패러다임을 제공할 수 있을 것으로 기대되었다.
8)특히, 우리나라는 전국민의 98%가 국민건강보험에 가입 하고 있으며, 7개 질병군에 대한 포괄수가제(Diagnosis Re-
Development of Open-Source Data Analysis Program for Healthcare Big Data
Hyung-Deuk Park, MSc, RAC and Sang-Soo Lee, MBA
Corporate Affairs, Medtronic Korea, Seoul, Korea
보건의료 빅데이터 이용 활성화를 위한 오픈 소스 데이터 분석 프로그램의 개발
메드트로닉코리아
박 형 득·이 상 수
Received March 31, 2015 Revised May 7, 2015 Accepted May 13, 2015 Address for Correspondence:
Hyung-Deuk Park, MSc, RAC Corporate Affairs, Medtronic Korea, 4F Sajo Building, 424 Yeongdong-daero, Gangnam-gu, Seoul 135-502, Korea Tel: +82-2-3404-7744 Fax: +82-2-562-7168
E-mail: [email protected]
Objectives: An era of open and transparent information in Korean healthcare area is now underway.
Health Insurance Review and Assessment Service has disclosed the National Patient Sample claims data since 2009 and National Health Insurance Service announced to disclose 9 year period cohort national health insurance claims database to healthcare stakeholders. Since Korea uses the fee-for-service scheme as basic payment system for all of medical treatments excepting for 7 common diseases which are run by Diagnosis Related Group, it is easy to identify the medical treatment practice and resource utility information for individual medical procedures. The use of SAS software is the generally accepted data analysis tool as the average data size of national health insurance claims data easily exceeds over 30 Giga Bytes. However, the data analysis using SAS is labor-intensive and time-consuming works and has a low accessibility due to its costly license fees. As the need to analyze the Healthcare Big Data faster and appropriately rises, demand for development of new data analysis tool is also significantly increasing.
Methods: Open-source big data analysis program with the name of BigPy was developed using Py- thon which is a high-level object oriented programming language. BigPy’s design philosophy empha- sizes on code readability and reusability, and its syntax allows users to express concepts in fewer lines of code than would be possible in statistical software such as SAS or R. Results: Bigpy program is com- posed of a series of data analysis macro and functions. The functions in BigPy can easily read, trim, sort, and merge the healthcare big data with database format and convert large dataset to a Hierarchical Data Format Version 5 file. Conclusion: Healthcare stakeholders now have access to promising new value of knowledge that is called Big Data. The efforts on Big Data analysis can address problems related to variability in healthcare quality and consequently improve healthcare treatments. The development of open-source data analysis is a noteworthy and promising methodology to handle the healthcare big data in a rapid and a cost-effective way.
Key Words Healthcare · Big Data · Open-source · National Health Insurance Claims Data.
Review Article
JoHTA
lated Group)를 제외한 나머지 상병에 대해서는 행위별수가 제(Fee For Service)를 적용하고 있기 때문에, 비급여를 제외 한 임상진료에 관계된 모든 세부 사항을 건강보험 청구자료 를 통해 확인할 수 있다는 장점이 있다. 건강보험심사평가원 (이하 심평원)은 2009~2013년 환자표본자료(Health Insur- ance Review and Assessment Service National Patient Sam- ple)를 통해 전국민의 보건의료 환경을 반영한 데이터를 제 공해 오고 있으며,
9-11)국민건강보험공단(이하 공단)은 최근 약 100만 명에 대한 9년 기간의 코호트 자료를 공개한 바 있 다.
12)이외에도 질병관리본부에서 관리하고 있는 국민건강 영양조사자료, 국립암센터의 암 등록자료, 통계청의 사망 통 계자료, 한국의료패널자료 등 국내 보건의료 빅데이터 자료 원은 지속적으로 증가하고 있다. 이에 정부도 지난 2014년 발 표한 ‘정부 3.0’ 계획을
13)통해, 보건의료산업 관련 분야에서 의료기관 평가 인증정보, 의약품 정보 등의 정보공개 확대 계 획을 발표하고 현재 이를 추진 중에 있다.
이처럼 국내외적으로 보건의료 빅데이터의 활용방안이 활발히 논의되고 있음에도 불구하고, 보건의료 빅데이터 활 용을 위한 데이터 분석 도구 및 관련 기술 개발에 대한 논의 는 상대적으로 부족하다. 본 연구는 보건의료 분야 빅데이터 이용 활성화를 위한 오픈 소스 기반의 데이터 분석 프로그 램의 개발과정과 그 활용사례를 보고하고자 한다.
BigPy 보건의료 빅데이터 분석 프로그램의 개발
프로그램 개발 동기
심평원의 환자표본자료 또는 공단의 표본 코호트 자료와 같은 보건의료 빅데이터를 분석할 수 있는 데이터 분석 프로 그램은 현재 R과 SAS 프로그램이 이용 가능한 분석 도구로 평가되고 있다. R 프로그램은 분산-네트워크 기술인 하둡 (Hadoop)
14)기술과의 연계를 통해 빅데이터 분석이 가능하다.
하지만, 하둡의 경우 서버-클라이언트 네트워크 프로그래밍 에 대한 전문적인 지식을 필요로 하며, 분석 대상 데이터의 크 기와 형태가 미리 정의되지 않은 비정형 형태의 빅데이터를 처리하는 목적으로 사용되는 제한점이 존재한다. SAS 프로그 램은 과학적이고 통합된 데이터 분석 환경을 제공해주는 장점 이 있지만, 라이센스 비용이 고가이며 자료 분석을 위해 SAS 프로그래밍 코딩법을 익히는 과정이 필요하다. 이처럼 적절한 보건의료 빅데이터 분석 도구의 부재 및 낮은 접근성으로 인 하여 보건의료 빅데이터 이용 활성화가 저해되고 있는 실정 이다. 보건의료 빅데이터 사용을 확산시키기 위해서는 자료원 공개 및 연계 계획뿐만 아니라 해당 자료를 분석하고 의미 있
는 데이터를 추출할 수 있는 데이터 분석관련 도구의 기술 개 발도 뒤따라야 한다고 생각하며, 이와 같은 생각이 BigPy 프로 그램을 개발하게 된 주요 동기로 작용하였다. 본 프로그램은 파이썬 프로그래밍 언어(Python programing language)를
15,16)기반으로 한 오픈 소스 빅데이터 분석 프로그램으로써, 건강 보험 청구자료와 같은 데이터베이스 형태의 보건의료 빅데이 터를 빠르고 손쉽게 분석하기 위한 목적으로 개발되었다.
BigPy 프로그램의 빅데이터 분석 알고리즘
일반적인 통계 분석 프로그램들을 이용하여 분석이 가능한 자료원의 크기는 해당 컴퓨터의 메모리 용량 이내로 제한된 다. 이와 같은 인-메모리(in-memory) 데이터 분석 알고리즘 은 데이터 용량이 통상 10 GB 이상이 되는 보건의료 빅데이 터를 분석하기에 적합하지 않기 때문에, 본 프로그램에는 ‘데 이터 조각내기(data chunking)’ 알고리즘이 활용되었다. ‘데 이터 조각내기’ 알고리즘은 원시 자료원을 메모리가 한 번에 처리할 수 있는 용량 이내로 데이터를 블록 형태로 잘게 나 눈 다음, 나누어진 데이터 블록별로 분석 작업을 반복 처리 하는 개념이다. 본 프로그램에서 “데이터 조각내기”의 상세 알고리즘과 의사코드(pseudo code)는 다음과 같다(그림 1).
1) 파일 생성(file creation): 하드디스크상에 원시 자료원 을 저장할 파일 생성
2) 데이터 조각내기(data chunking): 원시 자료원을 메모 리에 적재 가능한 용량 이내의 데이터 블록 형태로 조각 냄
3) 데이터 분석(data analyzing): 나눠진 데이터 블록을 순 서대로 메모리로 불러들여 분석을 실시하는 작업을 반복적 으로 실시
4) 데이터 재결합(data rejoining): 각각의 데이터 블록에 대해 분석된 결과를 메모리가 아닌 하드디스크 상에서 순서 대로 연결시킨 후 저장
BigPy 프로그램 밸리데이션(Validation)
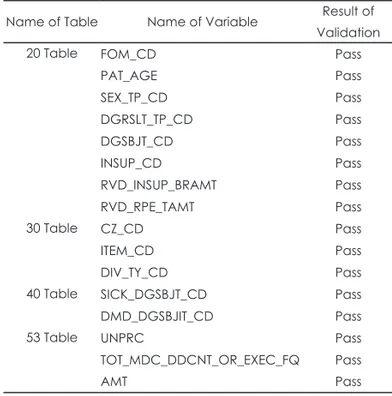
본 프로그램의 밸리데이션은 ‘2011년 환자표본자료’에 포 함된 변수들의 빈도 및 기초통계량 값이
17)SAS 프로그램 분
Fig. 1. Algorithm of Data Chunking and BigPy Pseudo-code.
석 시와 동일한지 여부를 확인하는 것으로 진행하였다. 예를 들어, 심평원이 공개한 명세서 상세내역 테이블에 포함되어 있는 ‘서식코드’(변수명: FOM_CD)에 대해 빈도 값은 다음과 같으며(표 1), 해당 변수에 대한 빈도 값을 BigPy 프로그램으 로 계산한 결과는 다음과 같다(그림 2). 마찬가지로 심평원이 공개한 ‘심결요양급여비용총액’(변수명: RVD_RPE_TAMT)
에 대한 기초 통계량은 다음과 같으며(표 2), 해당 변수에 대 한 기초통계량을 BigPy 프로그램으로 계산한 결과는 다음과 같다(그림 3). 프로그램 밸리데이션에 포함된 전체 환자표본 자료 변수명과 밸리데이션 실시 결과는 다음과 같다(표 3).
BigPy 프로그램 특성 및 제한점
본 프로그램의 개발 목표는 데이터 분석관련 프로그래밍 절차를 단순화하고 작성한 코드를 재사용 가능하도록 하여 사용자로 하여금 프로그래밍 코딩보다는 빅데이터 분석 알 고리즘 그 자체에 집중할 수 있도록 한 점이다. 즉, 기존의 통 계분석 프로그램을 이용하여 보건의료 빅데이터를 가공・분 석하는 것과 동일한 기능을 제공하되, 직관적인 프로그래밍 코딩 방법을 도입하여 SAS 프로그램 데이터 스텝과 같은 복
Fig. 2. Analysis Result of Form Code (Name of Variable: ‘FOM_
CD’) using BigPy.
Fig. 3. Analysis Result of Total Medical Treatment Amount (Name of Variable: ‘RVD_RPE_TAMT)’ using BigPy.
Table 1. Number of Frequency for ‘FOM_CD’ Variable in 20 table Coding
Value Description No. of
Frequency
2 Medicine In-Patient 340,552
3 Medicine Out-Patient 18,870,258
4 Dental In-Patient 922
5 Dental Out-Patient 1,721,494
6 Maternity Hospital In-Patient - 7 Public Health Facility In-Patient - 8 Public Health Facility Out-Patient 458,615
9 Psychiatry Daytime Ward 216
10 Psychiatry In-Patient 17,665
11 Psychiatry Out-Patient 52,865
12 Oriental Medicine In-Patient 22,536 13 Oriental Medicine Out-Patient 2,859,250
20 Filling Prescriptions 35,057
Table 3. List of Variable used for Program Validation and Valida- tion Result
Name of Table Name of Variable Result of Validation
20 Table FOM_CD Pass
PAT_AGE Pass
SEX_TP_CD Pass
DGRSLT_TP_CD Pass
DGSBJT_CD Pass
INSUP_CD Pass
RVD_INSUP_BRAMT Pass
RVD_RPE_TAMT Pass
30 Table CZ_CD Pass
ITEM_CD Pass
DIV_TY_CD Pass
40 Table SICK_DGSBJT_CD Pass
DMD_DGSBJIT_CD Pass
53 Table UNPRC Pass
TOT_MDC_DDCNT_OR_EXEC_FQ Pass
AMT Pass
Table 2. Basic Statistics of ‘Total Medical Treatment Cost’ (Name of variable: ‘RVD_RPE_TAMT’)
Item Basic Statistics
N 1,375,842
Total -
Mean 823,549.713
S.D. 2,879,336
Min 0
Max 506,619,890
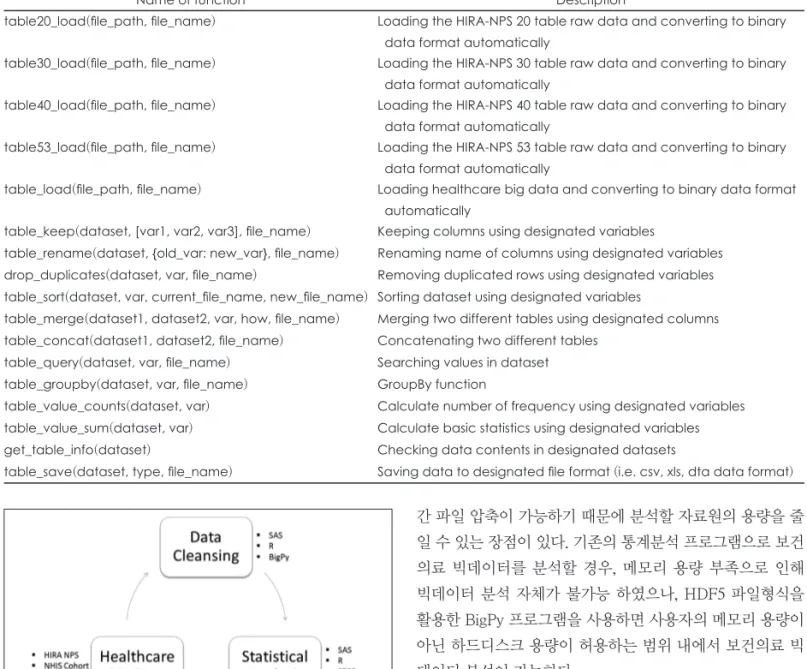
잡한 절차를 거치지 않아도 빅데이터 분석이 가능하도록 프 로그램이 설계되었다. 본 프로그램에서 제공되는 주요 데이 터 분석기능들은 1) 원시 자료원 불러오기, 2) 데이터 가공, 3) 데이터 탐색 및 4) 특수 목적 함수들로 구성되어 있다(표 4).
SAS 프로그램의 데이터 스텝 프로그래밍 구문과 BigPy 프로 그래밍 구문의 비교는 다음에 상세히 기술되어 있다(부록).
본 프로그램을 통해 분석되는 보건의료 빅데이터는 Hier - archical Data Format Version 5(이하 HDF5) 파일 형식으로
18)저장되도록 설계되어 있다. HDF5 파일 형식은 데이터를 이 진(binary)형태로 저장하기 때문에 텍스트(text) 파일 저장방 식에 비해 데이터 용량이 커지더라도 데이터를 안정적으로 보관할 수 있다. 또한 데이터를 파일에 저장함과 동시에 실시
간 파일 압축이 가능하기 때문에 분석할 자료원의 용량을 줄 일 수 있는 장점이 있다. 기존의 통계분석 프로그램으로 보건 의료 빅데이터를 분석할 경우, 메모리 용량 부족으로 인해 빅데이터 분석 자체가 불가능 하였으나, HDF5 파일형식을 활용한 BigPy 프로그램을 사용하면 사용자의 메모리 용량이 아닌 하드디스크 용량이 허용하는 범위 내에서 보건의료 빅 데이터 분석이 가능하다.
빅데이터 처리 및 분석을 통해 도출된 최종 결과물은 HDF5 파일 형식 이외에 텍스트, Comma Separated Value, HTML 및 Stata 프로그램의 dta 파일 형식으로도 저장할 수 있다. 본 프 로그램은 보건의료 빅데이터와 통계분석 프로그램 사이에서 징검다리 역할을 함으로써, 사용자는 선호하는 통계 분석 프 로그램을 그대로 사용할 수 있도록 설계되었다(그림 4).
BigPy 프로그램은 데이터베이스 형태의 정형 빅데이터 분 석에 적합하며, 저장할 자료의 형태가 미리 정의되지 않은 비 정형 형태의 데이터 분석작업에는 사용할 수 없는 제한점이 있 다. 또한 본 프로그램으로 분석 가능한 자료원의 크기는 500 GB 이하인 경우가 적절하며, 그 이상의 빅데이터 분석시에는 본 프로그램의 사용이 적절하지 않다. 그리고 본 프로그램은 데 이터 분석 기능 이외에 통계분석 기능은 제공하고 있지 않다.
본 프로그램의 전체 코드는 오픈 소스 프로그램 개발 공유 사이트인 GitHub에(https://github.com/bondgem0/BigPy/
Fig. 4. General Data Analysis Diagram for Healthcare Big Data.
Table 4. List of Major Functions in BigPy Program
Name of function Description
table20_load(file_path, file_name) Loading the HIRA-NPS 20 table raw data and converting to binary data format automatically
table30_load(file_path, file_name) Loading the HIRA-NPS 30 table raw data and converting to binary data format automatically
table40_load(file_path, file_name) Loading the HIRA-NPS 40 table raw data and converting to binary data format automatically
table53_load(file_path, file_name) Loading the HIRA-NPS 53 table raw data and converting to binary data format automatically
table_load(file_path, file_name) Loading healthcare big data and converting to binary data format automatically
table_keep(dataset, [var1, var2, var3], file_name) Keeping columns using designated variables
table_rename(dataset, {old_var: new_var}, file_name) Renaming name of columns using designated variables drop_duplicates(dataset, var, file_name) Removing duplicated rows using designated variables table_sort(dataset, var, current_file_name, new_file_name) Sorting dataset using designated variables
table_merge(dataset1, dataset2, var, how, file_name) Merging two different tables using designated columns table_concat(dataset1, dataset2, file_name) Concatenating two different tables
table_query(dataset, var, file_name) Searching values in dataset table_groupby(dataset, var, file_name) GroupBy function
table_value_counts(dataset, var) Calculate number of frequency using designated variables table_value_sum(dataset, var) Calculate basic statistics using designated variables
get_table_info(dataset) Checking data contents in designated datasets
table_save(dataset, type, file_name) Saving data to designated file format (i.e. csv, xls, dta data format)
blob/master/v0.1.2) 공개되어 있으며, 프로그램의 성능 향상 을 위해 누구나 자유롭게 프로그램 소스를 수정 및 배포하는 것이 가능하다.
BigPy 프로그램을 활용한 건강보험심사평가 연구원 환자표본자료 분석 사례
BigPy 프로그램의 실행
본 프로그램을 실행시키기 위해서는 파이썬 인터프리터
(Python interpreter)가 사용자 컴퓨터에 설치되어 있어야 한다. 파이썬 인터프리터를 실행시킨 후, 본 프로그램을 호 출하면, 프로그램이 실행된다(그림 5).
건강보험심사평가원 환자표본자료 불러오기
2011년 환자표본자료의 경우 표 2와 같이 한 건의 청구서 가 명세서 일반 내역, 진료내역, 수진자 상병내역, 처방전 교 부 상세 내역과 같이 각각의 데이터 셋으로 구분되어 있으며, 이들 데이터는 행과 열로 구성된 테이블 형태의 정형 데이터이 다. 환자표본자료는 텍스트 형태의 원시 자료로 제공되고 있으 며, 빅데이터 분석을 위해서 우선 원시 자료를 읽어 들여 추후 분석을 위한 파일로 변환하는 작업이 필요하다. 본 프로그램 에는 데이터베이스 형식의 정형 데이터를 읽어들여 HDF5 파 일로 자동 변환 시켜주는 table_load 함수가 포함되어 있다.
table_load 함수를 사용하여 원시 환자표본자료 데이터를 읽 어 들인 결과는 다음과 같다(그림 6).
데이터 셋에서 분석에 필요한 변수만 지정
환자표본자료에는 ‘샘플 추출확률’ 및 ‘샘플 가중치’ 등과 같 은 실제 자료 분석과는 관계 없는 변수들이 포함되어 있다. 데 이터 셋의 용량이 클수록 분석에 소요되는 시간은 증가되며, Fig. 5. Execution of BigPy Program.
Fig. 6. Demonstration of Data Load Function in BigPy.
▶ 사용법
▶ 실행 결과(20 테이블)
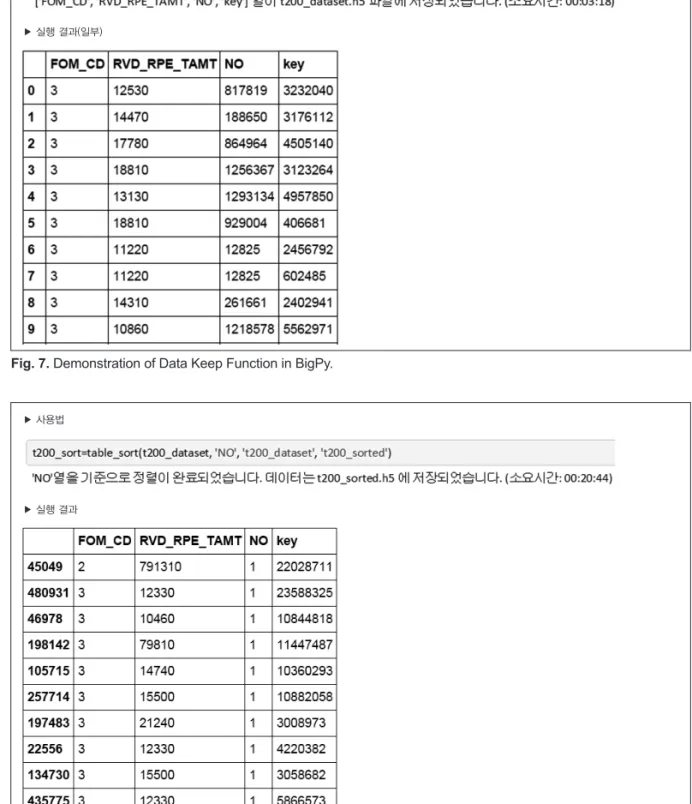
특히 데이터 셋의 정렬이나 병합과정에는 많은 시간이 소모 되기 때문에 연구주제와 관련 없는 변수를 굳이 데이터 셋에 포함시킬 필요는 없다. 이럴 경우 table_keep 함수를 이용해 환자표본자료 데이터 셋에서 필요한 변수만 선별적으로 취할 수 있다. table_keep 함수를 사용하여 환자표본자료 중 필요한 변수만 지정하는 방법과 그 실행 결과는 다음과 같다(그림 7).
데이터 셋의 변수명을 기준으로 데이터 정렬
환자표본자료 분석시 수진자고유번호키(변수명: NO)나 명세서 연결키(변수명: key) 등을 기준으로 전체 데이터 셋 을 정렬하는 작업이 필요하다. 본 프로그램에는 환자표본자 료와 같은 정형 테이블 형태의 자료에 대해 지정된 변수명을 기준으로 전체 데이터 셋을 정렬하는 table_sort 함수를 제공 하고 있으며 실행 방법과 그 결과는 다음과 같다(그림 8).
Fig. 7. Demonstration of Data Keep Function in BigPy.
▶ 사용법
▶ 실행 결과(일부)
Fig. 8. Demonstration of Data Sort Function in BigPy.
▶ 사용법
▶ 실행 결과
데이터 셋 중복제거
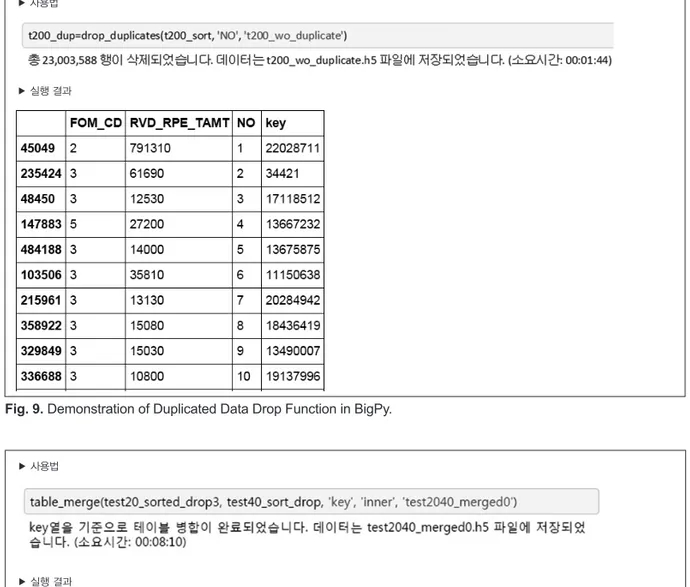
환자표본자료 분석시 동일한 수진자고유번호키 또는 명 세서 연결키를 기준으로 중복되는 데이터를 제거할 필요가 있다. 본 프로그램의 drop_duplicates 함수를 사용해 이러한 중복 데이터를 제거할 수 있으며, 실행 방법 및 결과는 아래 와 같다(그림 9).
변수명을 기준으로 데이터 셋 병합
환자표본자료 분석시, 수진자고유번호키 또는 명세서 연 결키 등을 기준으로 서로 다른 데이터 셋을 병합해야 하는
경우가 발생한다. 본 프로그램에서 환자표본자료 중 지정된 변수명을 기준으로 데이터 셋을 병합하는 기능을 제공하는 함수인 table_merge 및 table_concat가 있으며 실행 방법과 결과는 다음과 같다(그림 10).
데이터 셋의 변수명 변경
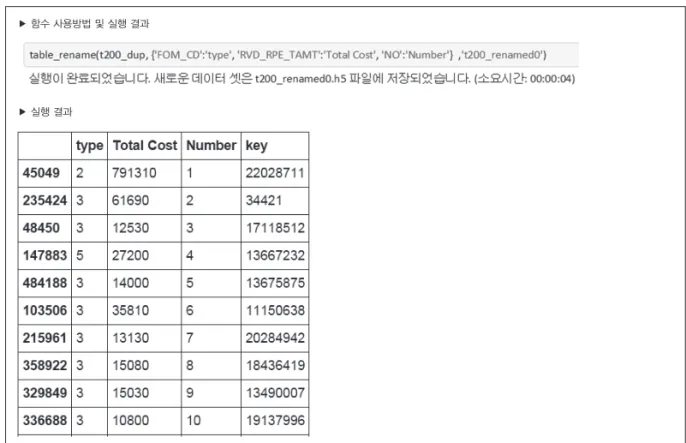
환자표본자료 데이터 셋의 변수명칭을 변경하고 싶을 때, 본 프로그램에 포함된 table_rename 함수를 사용하여 변수 명을 변경할 수 있다. 환자표본자료의 변수명을 변경하는 방 법과 그 결과는 다음과 같다(그림 11).
Fig. 9. Demonstration of Duplicated Data Drop Function in BigPy.
▶ 사용법
▶ 실행 결과
Fig. 10. Demonstration of Data Merge Function in BigPy.
▶ 사용법
▶ 실행 결과
변수명에 포함된 특정 값의 빈도 확인
환자표본자료 데이터 셋에 포함된 변수들 별로 특정 값의 빈도수를 확인해야 할 경우가 있다. 지정된 열에 포함된 특 정 값의 빈도수 확인은 본 프로그램의 table_value_counts 함수를 통해 확인할 수 있으며 그 사용방법과 결과는 다음 과 같다(그림 12).
변수명에 포함된 값의 기초 통계량 계산
환자표본자료 데이터 셋의 지정된 변수명에 포함된 값의 기초통계량을 계산하고 싶을 때, 본 프로그램에 포함된 ta- ble_value_sum 함수를 사용하여 데이터의 총합 및 기초 통 계량 값을 확인할 수 있다. 환자표본자료의 지정된 변수명에 포함된 데이터의 총 합을 계산하는 방법과 그 결과는 아래 와 같다(그림 13).
고찰 및 결론
Das 등
19)은 R과 하둡을 연동하여 인-메모리(in-memory) 방식으로 빅데이터에 대한 통계분석을 할 수 있는 오픈 소 스 형태의 프로그램을 발표하였다. 하둡과 같은 분산-네트 워크 기술은 페타 바이트(10
15bytes) 이상의 데이터 처리가 가능하지만, 데이터 분석 효용도가 일반적인 통계 프로그램 들에 비해 상대적으로 뒤떨어진다. 반대로 R과 같은 통계 프로그램은 데이터 처리 및 통계분석 기능은 뛰어나지만 처 Fig. 11. Demonstration of Data Re-name Function in BigPy.
▶ 함수 사용방법 및 실행 결과
▶ 실행 결과
Fig. 12. Demonstration of Data Frequency Analysis Function in BigPy.
▶ 함수 사용방법 및 실행 결과
Fig. 13. Demonstration of Basic Statistics Calculation Function in BigPy.
▶ 함수 사용방법 및 실행 결과