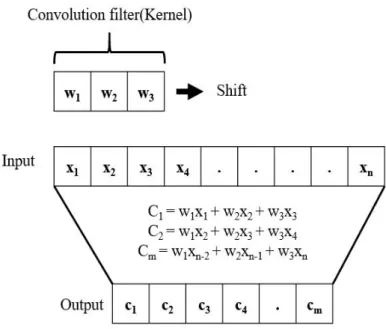
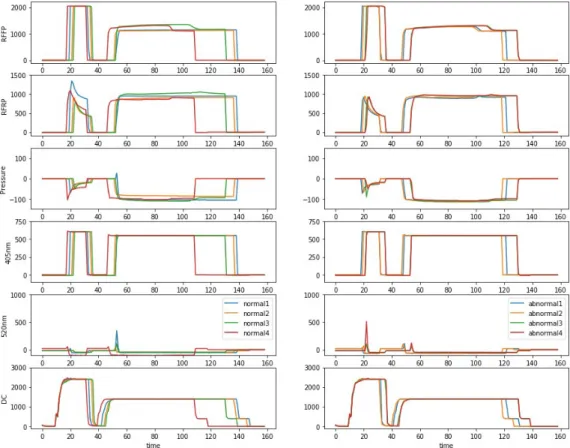
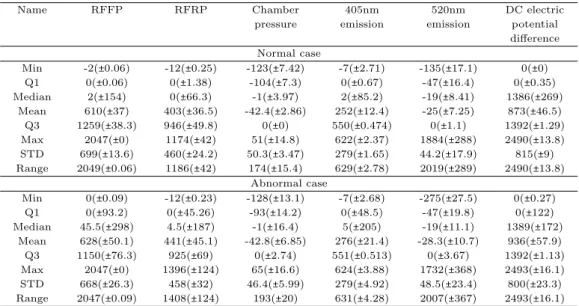
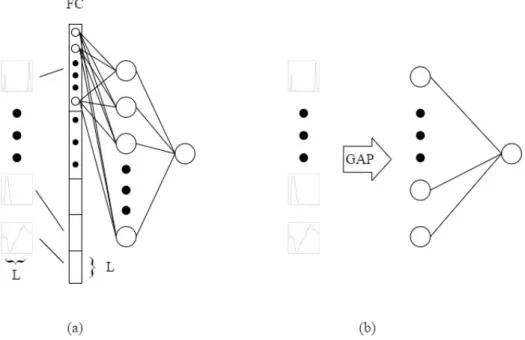
2020, 31
(5)
,691–720
신경망의 시계열 특징 추출 기능과 개선된 해석 방안을 활용한 반도체 수율 예측 모델
†
ᄋ
ᅵ원석
1
·강현희2
12(주)브릭
ᄌ ᅥ
ᆸᄉ ᅮ 2020ᄂ ᅧ ᆫ 5ᄋ ᅯ ᆯ 28ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2020ᄂ ᅧ ᆫ 8ᄋ ᅯ ᆯ 5ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2020ᄂ ᅧ ᆫ 8ᄋ ᅯ ᆯ 10ᄋ ᅵ ᆯ
요 약
ᄇ
ᅩ ᆫ ᄂ ᅩ ᆫᄆ ᅮ ᆫᄋ ᅳ ᆫ ᄉ ᅵᄀ ᅨᄋ ᅧ ᆯ ᄒ ᅧ ᆼᄐ ᅢᄋ ᅵ ᆫ ᄃ ᅡᄇ ᅧ ᆫᄅ ᅣ ᆼ ᄉ ᅥ ᆯᄆ ᅧ ᆼᄇ ᅧ ᆫᄉ ᅮᄅ ᅳ ᆯ ᄋ ᅵᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᄇ ᅮ ᆫ ᄅ ᅲ ᄋ ᅨᄎ ᅳ ᆨ ᄆ ᅩᄃ ᅦ ᆯᄋ ᅳ ᆯ ᄉ ᅢ ᆼᄉ ᅥ ᆼᄒ ᅡᄀ ᅩ ᄒ ᅢᄉ ᅥ ᆨᄒ ᅡᄂ ᅳ ᆫ ᄇ ᅡ ᆼᄋ ᅡ ᆫ ᄋ
ᅦ ᄀ ᅪ ᆫ ᄒ ᅡ ᆫ ᄀ ᅥ ᆺᄋ ᅵᄃ ᅡ. ᄐ ᅳ ᆨ ᄒ ᅵ ᄋ ᅨᄎ ᅳ ᆨ ᄆ ᅩᄃ ᅦ ᆯᄋ ᅦ ᄋ ᅧ ᆼᄒ ᅣ ᆼᄋ ᅳ ᆯ ᄆ ᅵᄎ ᅵ ᆫ ᄌ ᅮᄋ ᅭ ᄉ ᅵᄀ ᅨᄋ ᅧ ᆯ ᄀ ᅮᄀ ᅡ ᆫᄋ ᅳ ᆯ ᄑ ᅡᄋ ᅡ ᆨᄒ ᅡᄂ ᅳ ᆫ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄋ ᅳ ᆯ ᄉ ᅩᄀ ᅢᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄀ ᅵ ᄌ
ᅩ ᆫ ᄋ ᅦᄂ ᅳ ᆫ ᄉ ᅵᄀ ᅨᄋ ᅧ ᆯ ᄃ ᅦᄋ ᅵᄐ ᅥᄋ ᅴ ᄐ ᅳ ᆨᄌ ᅵ ᆼᄋ ᅳ ᆯ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄀ ᅡᄀ ᅡ ᄌ ᅵ ᆨᄌ ᅥ ᆸ ᄎ ᅮᄎ ᅮ ᆯ ᄒ ᅡ ᆫ ᄒ ᅮ ᄆ ᅩᄃ ᅦ ᆯᄋ ᅦ ᄌ ᅥ ᆨᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᄋ ᅨᄎ ᅳ ᆨ ᄉ ᅥ ᆼᄂ ᅳ ᆼ ᄋ ᅵ ᄒ ᅡᄅ ᅡ ᆨᄒ ᅡᄀ ᅥᄂ ᅡ ᄇ ᅮ ᆫ ᄉ
ᅥ ᆨ ᄇ ᅵᄋ ᅭ ᆼ ᄋ ᅵ ᄂ ᅩ ᇁ ᄃ ᅡᄂ ᅳ ᆫ ᄆ ᅮ ᆫ ᄌ ᅦᄀ ᅡ ᄋ ᅵ ᆻᄋ ᅥ ᆻᄃ ᅡ. ᄃ ᅢᄋ ᅡ ᆫᄋ ᅳᄅ ᅩ ᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼᄋ ᅳ ᆯ ᄋ ᅵᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᄐ ᅳ ᆨᄌ ᅵ ᆼᄋ ᅳ ᆯ ᄉ ᅳᄉ ᅳᄅ ᅩ ᄒ ᅡ ᆨᄉ ᅳ ᆸ ᄒ ᅡᄂ ᅳ ᆫ ᄇ ᅡ ᆼᄋ ᅡ ᆫᄋ ᅵ ᄉ ᅩᄀ ᅢ ᄃ ᅬᄋ ᅥ ᆻᄋ ᅳᄂ ᅡ ᄀ ᅧ ᆯᄀ ᅪᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄒ ᅢᄉ ᅥ ᆨᄋ ᅵ ᄇ ᅮ ᆯ ᄀ ᅡᄂ ᅳ ᆼ ᄒ ᅡᄋ ᅧ ᄉ ᅵ ᆯᄋ ᅭ ᆼᄌ ᅥ ᆨ ᄒ ᅪ ᆯᄋ ᅭ ᆼ ᄋ ᅦ ᄌ ᅦᄒ ᅡ ᆫᄋ ᅵ ᄋ ᅵ ᆻᄋ ᅥ ᆻᄃ ᅡ. ᄋ ᅮᄅ ᅵᄂ ᅳ ᆫ ᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼᄋ ᅵ ᄒ ᅡ ᆨᄉ ᅳ ᆸᄋ ᅳ ᆯ ᄐ ᅩ ᆼ ᄒ
ᅢ ᄎ ᅮᄎ ᅮ ᆯ ᄒ ᅡ ᆫ ᄀ ᅡ ᆨ ᄐ ᅳ ᆨᄌ ᅵ ᆼᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄌ ᅮ ᆼ ᄋ ᅭᄃ ᅩᄅ ᅳ ᆯ ᄀ ᅨᄉ ᅡ ᆫᄒ ᅡᄀ ᅩ ᄃ ᅥ ᄂ ᅡᄋ ᅡᄀ ᅡ ᄉ ᅵᄀ ᅨᄋ ᅧ ᆯ ᄀ ᅮᄀ ᅡ ᆫᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄌ ᅮ ᆼ ᄋ ᅭᄃ ᅩᄅ ᅳ ᆯ ᄑ ᅡᄋ ᅡ ᆨᄒ ᅡ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄃ ᅩ ᄅ
ᅩ
ᆨ ᄆ ᅩᄃ ᅦ ᆯᄋ ᅳ ᆯ ᄉ ᅥ ᆯᄀ ᅨᄒ ᅡᄀ ᅩ ᄒ ᅢᄉ ᅥ ᆨᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄃ ᅡᄇ ᅧ ᆫᄅ ᅣ ᆼ ᄉ ᅵᄀ ᅨᄋ ᅧ ᆯ ᄇ ᅮ ᆫᄉ ᅥ ᆨ, ᄅ ᅢ ᆫᄃ ᅥ ᆷ ᄑ ᅩᄅ ᅦᄉ ᅳᄐ ᅳ, ᄇ ᅡ ᆫᄃ ᅩᄎ ᅦ ᄀ ᅩ ᆼᄌ ᅥ ᆼ, ᄒ ᅡ ᆸᄉ ᅥ ᆼᄀ ᅩ ᆸ ᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼ, ᄒ ᅢᄉ ᅥ ᆨ ᄆ ᅩᄃ ᅦ ᆯ.
1. 서론 바
ᆫ도체 제조 공정은매우 복잡하고 정교하여 양품생산에 대한 실패 지점이 다수 존재한다. 반도체의 노
ᇁ은제조 단가를고려하면 생산 안정성을확보하는것은 중요한 과제이다. 게다가 반도체 분야의 제조 ᄀ
ᅩᆼ정 기술은변화가 빨라 끊임없는수율개선이 요구된다. 이러한 요구에 대응하기 위해 스마트 제조 방 시
ᆨ이 주목받게 되었고 방대한 데이터가 반도체 공정 감시, 분석, 및 예측에활용되고 있다. 덕분에 제조 ᄀ
ᅩᆼ정 변화 속도에 발맞춰 수율개선을지속하고 있다.
ᄇ
ᅡᆫ도체 제조는크게 웨이퍼, 산화, 포토, 식각, 박막, 배선, electric die sorting (EDS), 패키지 공정 등 ᄋ
ᅳ로 이루어져 있으며 수백 개에 이르는세부 공정이 있다. 따라서 수율개선은모든 공정에서 복합적으 ᄅ
ᅩ 진행되어야 하고 다양한 설비상태와 공정 조건에 영향을받는작업이다. 그리고 수율을 분석하기 위 ᄒ
ᅢ서는검사 장비를 통한 계측과정이 포함되는데 품질 향상에 대한 기여도에 비해서 시간 비용이 많이 ᄃ
ᅳ는작업이다. 따라서 웨이퍼를샘플링하여 검사를 진행하게 되는데 일반적으로 랏 (lot) 단위로 한 장 ᄋ
ᅴ 웨이퍼에 대해서만 계측한다. 그래서 비계측 웨이퍼에 대한 수율정보가 누락되게된다. 결국수율 ᄀ
ᅢ선을위한 노력은시간 비용과 정보 비용이 서로 반비례하여 작용한다. 이러한 상황을개선하기 위해 ᄇ
ᅡᆫ도체 제조 공정에서는수율예측기법을활용한다. 수율예측이란 제조 공정 과정에서 수집된데이터
†
ᄋ ᅵ ᄂ ᅩ ᆫᄆ ᅮ ᆫᄋ ᅳ ᆫ ᄌ ᅮ ᆼ ᄉ ᅩᄀ ᅵᄋ ᅥ ᆸ ᄀ ᅵᄉ ᅮ ᆯ ᄀ ᅢᄇ ᅡ ᆯᄉ ᅡᄋ ᅥ ᆸᄋ ᅴ ‘ᄇ ᅡ ᆫᄃ ᅩᄎ ᅦ/FPD ᄉ ᅳᄆ ᅡᄐ ᅳᄑ ᅢ ᆨᄐ ᅩᄅ ᅵ ᄀ ᅩᄃ ᅩᄒ ᅪᄅ ᅳ ᆯ ᄋ ᅱᄒ ᅡ ᆫ AI ᄀ ᅵᄇ ᅡ ᆫ ᄌ ᅥ ᆨᄋ ᅳ ᆼᄒ ᅧ ᆼ FDC ᄀ ᅢᄇ ᅡ ᆯ’
(S2632062) ᄀ ᅪᄌ ᅦ ᄋ ᅧ ᆫᄀ ᅮᄇ ᅵᄋ ᅦ ᄋ ᅴᄒ ᅡᄋ ᅧ ᄉ ᅮᄒ ᅢ ᆼᄃ ᅬᄋ ᅥ ᆻᄋ ᅳ ᆷ.
1
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (13493) ᄀ ᅧ ᆼᄀ ᅵᄃ ᅩ ᄉ ᅥ ᆼᄂ ᅡ ᆷᄉ ᅵ ᄇ ᅮ ᆫ ᄃ ᅡ ᆼᄀ ᅮ ᄑ ᅡ ᆫᄀ ᅭᄋ ᅧ ᆨᄅ ᅩ 230, (ᄌ ᅮ)ᄇ ᅳᄅ ᅵ ᆨ ᄀ ᅵᄋ ᅥ ᆸᄇ ᅮᄉ ᅥ ᆯᄋ ᅧ ᆫᄀ ᅮᄉ ᅩ, ᄎ ᅢ ᆨᄋ ᅵ ᆷ ᄋ ᅧ ᆫᄀ ᅮᄋ ᅯ ᆫ.
E-mail: [email protected]
2
(13493) ᄀ ᅧ ᆼᄀ ᅵᄃ ᅩ ᄉ ᅥ ᆼᄂ ᅡ ᆷᄉ ᅵ ᄇ ᅮ ᆫ ᄃ ᅡ ᆼᄀ ᅮ ᄑ ᅡ ᆫᄀ ᅭᄋ ᅧ ᆨᄅ ᅩ 230, (ᄌ ᅮ)ᄇ ᅳᄅ ᅵ ᆨ ᄀ ᅵᄋ ᅥ ᆸᄇ ᅮᄉ ᅥ ᆯᄋ ᅧ ᆫᄀ ᅮᄉ ᅩ, ᄋ ᅧ ᆫᄀ ᅮᄋ ᅯ ᆫ.
ᄋ
ᅪ 계측을 통해획득한 수율정보를기반으로 예측모델을생성하여 계측과정 없이 공정 데이터로만 수 유
ᆯ을예측하는것을 뜻한다. 따라서 비계측웨이퍼도 품질 상태를예상하고 원인 분석을할 수 있어 수 ᄋ
ᅲᆯ개선에 도움을 줄수 있다. 데이터 마이닝 기법의 발달과 함께 수율예측모델 연구는활발하게 이루 ᄋ
ᅥ지고 있다.
ᄃ
ᅢ표적으로 Chien 등 (2007)은랏의 품질을구별하기 위한 k 평균 군집화 (k-means clustering), 수 ᄆ
ᅡ
ᆭ은 공정 변수에서 중요 변수를선택하기 위한 크루스칼-왈리스 검정 (Kruskal-Wallis test), 품질 낮은 ᄅ
ᅡᆺ에 대해 의사결정나무 (decision tree) 기반의 원인 분석 방법론을제시하였다. 이를 통해 실패에 대 ᄒ
ᅡᆫ 원인 분석이 가능했지만, 이를구현하고 실행하는데 많은시간이 소요되고 특히 공정 전문가의 도움 ᄋ
ᅵ 필요하다는단점이 있었다. Wu 등 (2010)은차원 축소한 공정 데이터를퍼지 신경망 (fuzzy neural network)에 적용하여 전통적인 통계 기반의 수율예측모델 기법보다 높은예측정확도를성취하였다.
Kim 등 (2016)은 synthetic minority over-sampling technique (SMOTE)을제안하였다. 반도체 제조 ᄀ
ᅩᆼ정의 특성상 수율이 높고 계측 빈도가 낮아 불량 품질관련 데이터를수집하는데 어려움이 있기 때문 ᄋ
ᅦ 공정 데이터를예측모델에 적용할 경우 양품정보에 편향된모델이 생성될 확률이 높다. SMOTE는 ᄃ
ᅦ이터셋에서 소수 클래스의 데이터를합성해 균형 잡힌 데이터셋을생성하고 이를모델링에활용하여 ᄋ
ᅵ러한 문제를개선하였다.
이
ᆯ반적으로 반도체 제조 공정의 데이터 분석은 원데이터 (raw data)를전처리하고 전문지식을바탕 ᄋ
ᅳ로 데이터의 특징 (feature)을추출해 진행한다. 이는데이터 분석 과정이 용이하다는장점이 있지만, 부
ᆫ석 목적에 맞는설명력 높은 특징을추출하는과정에 분석가의 개입이 필요하다는단점이 있다. 반도 ᄎ
ᅦ 산업같이 공정 기술이나 제조환경이 급변하는경우 문제가 더욱부각된다. 급격한 변화로 인해 전문 ᄌ
ᅵ식을 충분히활용하지 못하거나 높은 분석 비용을초래할 수 있다. 전문 지식의 적용이 어려운경우 시
ᆯ증을 기반으로 이미 익숙한 특징을 우선 추출하고 변수 선택 과정을 진행하기도 하지만 놓친 특징이 ᄃ
ᅡ수 존재할 수 있다. 해석관점에서도 시계열 데이터인 원데이터에서 추출한 변수는시간 정보를많이 이
ᆶ어 수율에 영향을미친 시점과 지속시간을알고 싶어 하는 엔지니어에게 충분한 정보를제공하지 못 ᄒ
ᅡᆫ다는단점이 있다. 따라서 반도체 제조 공정에서 좋은예측모델이란 시간 정보를바탕으로 분석할 수 이
ᆻ는것을의미한다.
ᄉ
ᅵ계열 데이터를이용한 예측모델의 종류에는과거 추세를 분석하여 아직관측되지 않은 특정 변수의 ᄆ
ᅵ래 값을예보 (forecast)하는모델과 시계열인 설명변수를 통해 종속변수의 값을예측 (prediction)하 ᄂ
ᅳᆫ모델이 있다. 예측은다시 종속변수 형태에 따라 연속형 수치형인 회귀 (regression) 모델과 범주형 ᄋ
ᅵᆫ 분류 (classification) 모델로 나뉜다. 마지막으로 분류 모델은 종속변수의 클래스 (class)가 2개인 경 ᄋ
ᅮ, 이진 (binary class) 분류 모델, 3개 이상인 경우 다중 (multi-class)모델로 구분된다. 이렇게 구분 되
ᆫ이유는 종속변수의 형태에 따라 학습에 필요한 함수인 목적함수가 달라지기 때문이다. 여기서는 양 ᄑ
ᅮ
ᆷ과 불량에 대해서만 구분하는예측모델 생성이 목적이므로 이진 분류 모델에 해당한다.
ᄉ
ᅵ계열 분류 알고리즘은 동적 시간 워핑 (dynamic time warping)을기반으로 하는것이 많다. 동적 ᄉ
ᅵ간 워핑은두 시계열 데이터 간의 거리가 최소가 되게끔두 데이터의 시점을매칭 (alignment)하는알 ᄀ
ᅩ리즘으로 일반적으로 유클리드 거리 (euclidean distance)를사용한다. 그래서 시간 지연이나 데이터 ᄀ
ᅵᆯ이에 의한 영향을 줄여 형태에 집중할 수 있게 도와준다. 이렇게 시계열 데이터 간 거리를 측정한 다 ᄋ
ᅳ
ᆷ알고리즘을 통해 시계열 데이터를 분류한다. 대표적으로 최근접 이웃 (nearest neighbor)알고리즘 으
ᆯ사용한 NN-DTW가 있는데 시간 복잡도가 높아 이를해결하기 위한 다양한 방법들이 제안되고 있다 (Petitjean 등, 2014). 시계열 데이터의 국부적 (local) 특징을찾는샤플렛 변환(shapelet transform)도 ᄌ
ᅡ주 사용된다. 형태에 미세한 차이가 있는경우에 특히 유용하다. 그리고 여러 기법을 사용해 결과를 ᄃ
ᅩ출하는 COTE (collective of transformation-based ensembles)도 있다. COTE는시간 도메인 (time domain)기반의 유사도 측정 기법, 주파수 도메인 (frequency domain) 기반의 유사도 측정 기법, 자기