An alternative method in estimating propensity scores with conditional inference tree in multilevel data: A
case study
Hyunsuk Han 1 · Minho Kwak 2
1 Institute of Educational Research, Korea University
2 Quantitative Methodology, University of Georgia
Received 16 May 2019, revised 19 June 2019, accepted 8 July 2019
Abstract
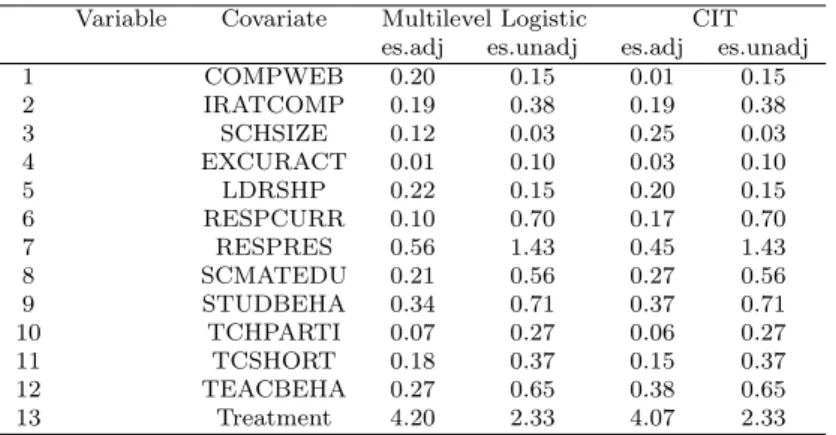
A multilevel structure of data is widely used in a variety of social science settings. To investigate the effects of interventions, researchers often conduct observational studies that use large scale secondary data and incorporate propensity score methods; this is beneficial in performing causal inference in non-randomized observational studies. The standard propensity score uses a logistic regression approach; however, this approach could be outperformed by alternative methods based on statistical learning and data mining algorithms. To date, little research had addressed data utilizing mining meth- ods within propensity score design, especially with multilevel observational data. The purpose of this study is to examine the performance of propensity scores associated with the use of stratification, estimated by a multilevel logistic versus a conditional inference tree using large scale secondary data derived from the Programme for Inter- national Student Assessment. The results showed that a conditional inference tree more conservatively estimates the treatment effect. In addition, the covariate balance result showed that the CIT better produced a randomized treatment/control design than did the multilevel logistic regression.
Keywords: Conditional inference tree, multilevel, multilevel logistic regression, non- randomized, propensity score.
1. Introduction
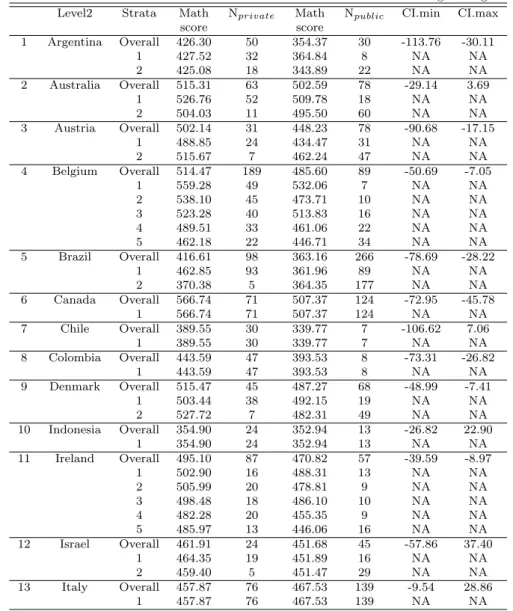
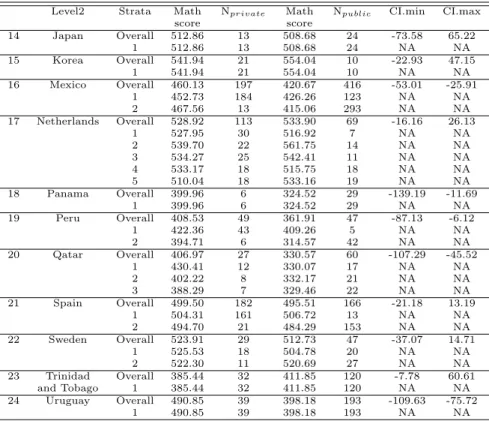
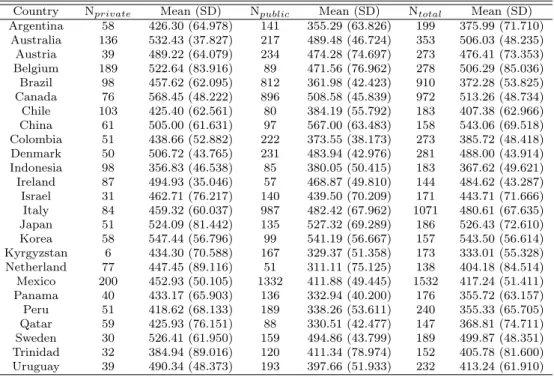
Social science researchers often conduct studies to investigate the effects of interventions using large scale secondary data (e.g., Bryer and Pruzek, 2011; Hwang et al., 2017; Park and Hwang, 2018). In this case, there are two considerable factors significant to performing the valid study. First of all, the non-randomized property of the data. Since the data are not intended to perform experimental design with non-random sampling, it might be inade- quate to reveal the treatment effect using regression methods that employ direct comparison
1
Research professor, Institute of Educational Research, Korea University, Seoul, Republic of Korea.
2