Deep Learning based violent protest detection system
1)
전체 글
1)
수치
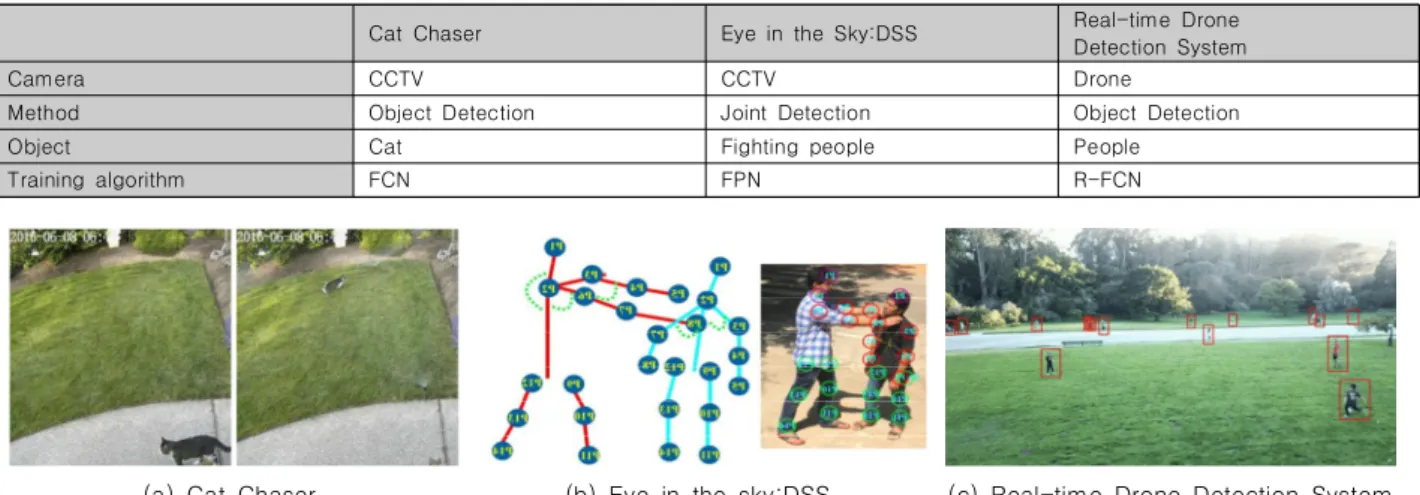
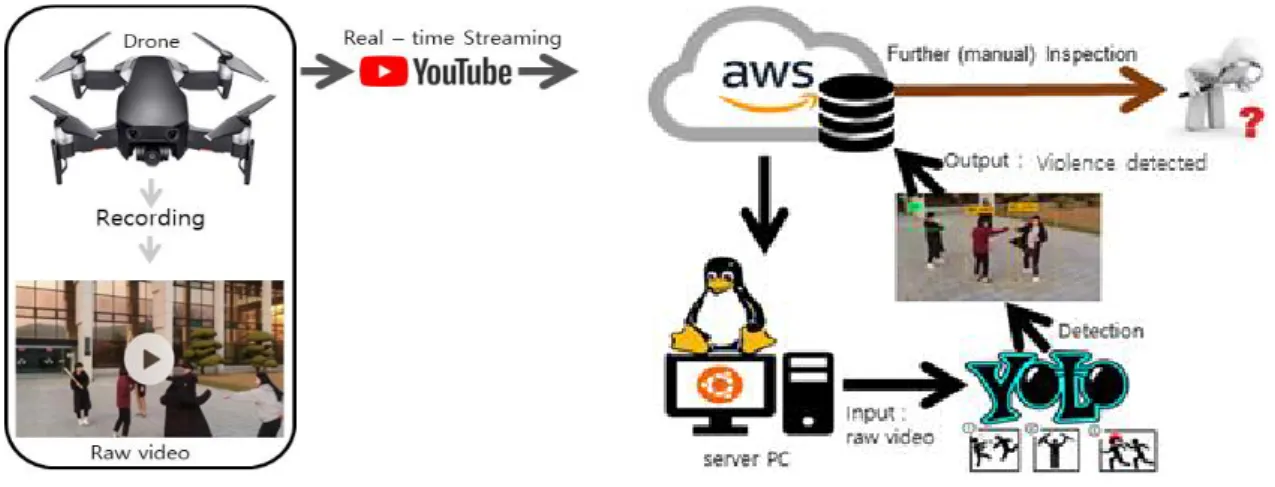


관련 문서
What is the relative number of presentations that will target the audience as a logical Expression unnecessary information is released or increased alignment will fail.... Python
What is the relative number of presentations that will target the audience as a logical Expression unnecessary information is released or increased alignment will fail.... Python
1) An LSTM network model is designed to deep extract the speech feature of Log-Mel Spectrogram/MFCC, which solves the high dimensional and temporality of the speech data. 2)
[43] Bahl, S., Sharma, S.K, “A minimal subset of features using correlation feature selection model for intrusion detection system,” in Proc. of Proceedings of the
Metz, “Unsupervised representation learning with deep convolutional generative adversarial networks”, ICLR(International Conference on Learning Representations)
As a specific educational method, we proposed the cultural elements teaching model and the model through the learning plan based on the prototype Moran-model, and took
Preliminary Study of IR Sensor Equipped Drone-based Nuclear Power Plant Diagnosis Method using Deep Learning. Ik Jae Jin and
Motivation – Learning noisy labeled data with deep neural network.
