논문 2016-53-6-10
FPGA 기반 실시간 영상 워핑을 위한 영상 캐시
( Image Cache for FPGA-based Real-time Image Warping )
최 용 준*, 류 정 래*
( Yong Joon Choi and Jung Rae Ryooⓒ)
요 약
FPGA 기반 실시간 영상 워핑 시스템에서는 영상 픽셀 정보의 빠른 읽기와 메모리 접근 횟수의 감소를 위하여 영상 캐시 를 활용하지만, 일반 컴퓨터 시스템의 캐시 알고리즘은 캐시 부적중(cache miss)에 의한 시간 지연과 복잡한 온라인(on-line) 연산 구조로 인하여 실시간 성능 구현에 어려움이 있다. 본 논문에서는 FPGA 기반 실시간 영상 워핑을 위한 단순한 구조의 영상 캐시 알고리즘을 제안한다. 영상 워핑에서의 픽셀 데이터 접근 순서는 워핑에 적용할 2D 좌표변환 관계에 의하여 결정되 며 매 영상 프레임에서 반복되는 특성이 있다. 따라서, 캐시 로드(cache load)에 관한 사항을 오프라인(off-line)에서 미리 프로 그램함으로써 캐시 부적중 상황이 발생하지 않음을 보장할 수 있고, 그 결과 온라인에서의 연산이 감소하여 캐시 컨트롤러의 구조가 단순해진다. FPGA를 활용한 전체 시스템 구조를 제시하고, 실험을 통하여 제안하는 영상 캐시 알고리즘의 정확성과 타당성을 확인한다.
Abstract
In FPGA-based real-time image warping systems, image caches are utilized for fast readout of image pixel data and reduction of memory access rate. However, a cache algorithm for a general computer system is not suitable for real-time performance because of time delays from cache misses and on-line computation complexity. In this paper, a simple image cache algorithm is presented for a FPGA-based real-time image warping system. Considering that pixel data access sequence is determined from the 2D coordinate transformation and repeated identically at every image frame, a cache load sequence is off-line programmed to guarantee no cache miss condition, and reduced on-line computation results in a simple cache controller. An overall system structure using a FPGA is presented, and experimental results are provided to show accuracy and validity of the proposed cache algorithm.
Keywords: real-time image warping, image cache, bilinear interpolation, memory access rate
*정회원, 서울과학기술대학교 전기정보공학과 (Dept. of Electrical and Information Eng., Seoul National University of Science and Technology)
ⓒCorresponding Author (E-mail : [email protected])
※ 이 연구는 서울과학기술대학교 교내연구비의 지원 으로 수행되었습니다.
Received ; March 1, 2016 Revised ; May 26, 2016 Accepted ; May 28, 2016
Ⅰ. 서 론
디지털 반도체 및 영상 센서 기술의 발전에 따라 휴 대용 기기를 포함한 임베디드 시스템에 카메라를 활용 하는 사례가 증가하고 있다. 영상 센서는 다른 어떤 센 서보다 많은 양의 정보를 제공하지만, 일반 컴퓨터에 비하여 상대적으로 연산 능력이 부족한 임베디드 비전
시스템에서는 영상을 실시간으로 처리하는데 어려움이 있다. 영상 워핑(image warping)은 영상의 모든 개별 픽셀에 2D 좌표 변환을 적용하는 영상처리 알고리즘으 로서 렌즈 왜곡 보정[1], 스테레오 비전에서의 영상 편위 교정(image rectification)[2], 그리고 파노라믹 영상 합성 을 위한 영상 스티칭(image stitching)[3] 등에 활용되는 데, 실시간 처리 성능 확보를 위한 가속기(accelerator)로 GPU(Graphic Processing Unit)를 활용하거나 FPGA 등 의 디지털 하드웨어로 구현하는 방법을 사용한다.
GPU는 수천 개의 코어를 내장하여 병렬로 데이터를 처리함으로써 실시간 처리 성능 확보에 유리하며, 소프 트웨어의 특성상 GPU 프로그래밍은 하드웨어 방식보 다 개발이 쉽고 빠른 장점이 있다. 이러한 장점을 바탕
으로 GPU를 활용한 영상 왜곡 보정[4]과 스테레오 영상 편위 교정[5], HMD(Head-Mounted Display)를 위한 영 상 워핑(image warping)[6] 등을 수행한 연구 결과가 발 표되었다. 한편, FPGA를 활용한 영상 처리는 재구성이 가능하고 맞춤형 메모리 구조를 적용할 수 있으며 GPU 방식에 비하여 전력 소모가 적은 장점이 있다[7]. 본 논문에서는 FPGA를 활용한 실시간 영상 워핑 시스 템 구현을 다룬다.
FPGA를 활용한 실시간 영상 워핑 구현에 있어서 출 력 영상의 픽셀 값을 결정하는 보간(interpolation)[8] 연 산으로는 4개의 입력 픽셀을 활용한 쌍일차 보간 (bilinear interpolation) 연산이 주로 사용된다. 한편, 입 력 영상 픽셀을 읽기위한 버퍼 메모리 액세스와 관련해 서는 버퍼 메모리로 FPGA 내부 메모리[9] 또는 외부 메
모리[10~11]를 사용한 연구가 소개되었으며, 입력 영상
픽셀 주소를 생성하는 방식으로는 오프라인(off-line)에 서 픽셀 주소를 생성하는 룩업테이블(Look-Up Table, LUT) 방식[10]과 온라인(on-line) 연산 방식[9]이 연구되 었다. 각 방식에 장단점이 있으나 고해상도 영상으로의 확장성과 주소 연산의 편리성 및 유연성 등을 고려할 때, 외부 메모리를 영상 버퍼와 LUT 저장 공간으로 활 용하는 실시간 영상 워핑 방식이 보다 적합하다. 최근 에는 LUT 방식의 단점인 LUT 저장 공간을 줄이기 위 하여 LUT를 압축하는 방식이 연구되었다[12].
영상 워핑 구현에서 일반적으로 사용하는 역방향 매 핑(backward mapping) 방식에서는 LUT는 순차적으로 읽는 반면 입력 영상 픽셀은 비순차적으로 읽게 된다.
그 결과로 메모리 출력 속도가 저하되고, 특히 하나의 입력 픽셀을 반복적으로 읽음으로 인하여 메모리 접근 횟수가 증가하는 문제가 발생한다. 이를 해결하고자 LUT 메모리와 영상 버퍼 메모리로 이종의 다른 소자 를 활용한 연구[10]가 있었으나 메모리 접근 횟수 증가 문제는 해결되지 않으며, 메모리 소자를 2개 사용해야 하는 단점이 있다. 또한, FPGA 내부 메모리를 영상 캐 시(image cache)로 활용하는 연구도 발표[11]되었으나, 일반 컴퓨터 시스템의 캐시 방식을 활용한 관계로 구현 하기에 너무 복잡하다. FPGA 내부 메모리를 단순 링 버퍼(ring buffer) 형태로 사용하여 스테레오 카메라의 영상 편위 교정[13~14]과 파노라믹 영상 합성[15]에 적용한 연구도 진행되었으나, 대응하는 입출력 영상 픽셀의 수 직 위치 차이가 수십 라인 이내로 제한되는 분야에만 적용이 가능한 한계가 있다.
본 논문에서는 FPGA 기반 실시간 영상 워핑 하드웨
Image
Sensor Image
Buffer Image
Cache Interpol.
Output Image
External
SDRAM Internal
Memory FPGA
그림 1. 영상 캐시를 활용한 실시간 영상 워핑 Fig. 1. Real-time image warping using image cache.
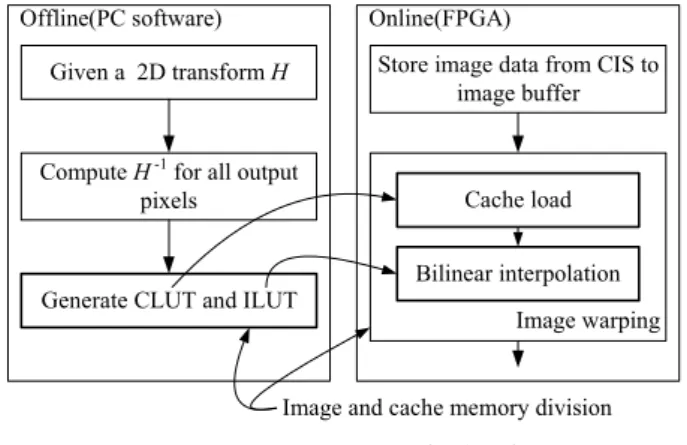
어를 위한 새로운 영상 캐시 알고리즘을 제안한다. 그 림 1에는 영상 캐시를 활용한 실시간 영상 워핑 시스템 을 나타내었다. LUT와 입력 영상이 저장되는 외부 메 모리로는 SDRAM을 사용하며, 캐시 메모리는 FPGA 내부 메모리를 사용한다. 실시간 영상 워핑에서는 입출 력 영상 간의 좌표 변환 관계가 정의되면 입력 영상 픽 셀의 액세스 관련 순서 및 시점이 결정되며, 좌표 변환 이 변경되지 않는 한 모든 영상 프레임에서 매번 동일 하게 반복되는 특성이 있다. 따라서, 캐시 컨트롤러의 동작을 오프라인에서 미리 결정하여 별도의 LUT로 저 장하고, 온라인에서는 이 LUT에 따라 영상 버퍼 메모 리에서 캐시 메모리로 입력 영상 정보를 로드하는 단순 작업만 수행하더라도 보간 연산에 필요한 픽셀 데이터 가 항상 캐시 메모리에 미리 저장됨을 보장할 수 있으 므로 캐시 컨트롤러의 구조가 매우 단순해진다. 또한, 한번 캐시로 로드된 픽셀 데이터는 현재 영상에서 더 이상 사용되지 않을 때까지 캐시 메모리에서 재사용되 므로 모든 픽셀 데이터는 단 한번만 캐시 메모리로 로 드되며, 그 결과 영상 버퍼 메모리 접근 횟수를 최소화 할 수 있다. 이를 위한 전체 하드웨어 구조 및 LUT에 포함될 정보, 그리고 오프라인에서 LUT를 생성하는 방 법을 기술한다. 제안된 캐시 컨트롤러를 포함한 실시간 영상 워핑 시스템을 FPGA 기반 하드웨어로 구현하고, 실험을 통하여 제안된 영상 캐시 알고리즘의 타당성 및 정확성을 확인한다.
본 논문은 다음과 같이 구성된다. Ⅱ절에서는 실시간 영상 워핑에 필요한 주요 연산 및 메모리 접근 특성을 설명하고, 영상 워핑을 위한 영상 캐시를 Ⅲ절에서 제 안한다. Ⅳ절에서는 제안된 영상 캐시를 활용한 시스템 구현 및 실험 결과를 제시하고, Ⅴ절에 논문의 결론을 정리한다.
Ⅱ. 실시간 영상 워핑의 주요 연산
1. 좌표 변환 및 픽셀 보간
영상 워핑은 입력 영상의 모든 픽셀에 좌표 변환 를 적용하는 과정으로 출력 영상의 픽셀 좌표 는
u
v
(x, y)=H(u, v)
y
Input Image Output Image x
α n
m+1
n+1 m
Im+1,n β Im,n+1
Im,n
Im+1,n+1 (u, v)=H-1(x, y)=(m+α , n+β ) Output Scan Line Input Scan Line
ISLk-1 ISLk
ISLk+1
OSLk-1
OSLk+1
OSLk
그림 2. 역방향 매핑을 활용한 영상 워핑 Fig. 2. Image warping using backward mapping.
입력 영상의 픽셀 좌표 로부터 다음과 같이 결정 된다.
(1)
하지만, 실제로 영상 워핑을 적용하는 과정에서는 출력 영상의 좌표로부터 이에 대응하는 입력 영상의 좌표를 구하는 역방향 매핑 방식을 주로 사용하여 다음과 같이 역변환을 적용한다[10].
(2) 여기서 과 은 정수부, 그리고 ≦ 는 소수 부를 의미한다.
그림 2에는 역방향 매핑의 적용에 따라 출력 영상의 픽셀을 생성하는 과정을 나타내었다. 출력 픽셀은 출력 스캔 라인(Output Scan Line, OSL)을 따라 생성되며,
는 번째 출력 스캔 라인을 의미한다. 또한,
는 를 역변환 로 입력 영상에 투영한 입력 스캔 라인(Input Scan Line, ISL)이다. 결국,
가 위의 한 픽셀일 때, 대응점 는
상에 존재한다. 통상적으로 좌표 변환 는 서로 다른 이 교차하지 않음을 가정한다.
입력 영상 픽셀의 좌표가 정수가 아닌 관계로 (2)에 서 구한 주변 4개 픽셀 데이터에 다음의 쌍일차 보간을 적용하여 출력 픽셀 데이터를 생성한다. 여기서
는 입력 영상 좌표 의 픽셀 데이터를 의미한다.
(3)
_
Im,n
Im+1,n+1 Im,n+1 α
β 1
1 _
Adder Multiplier
Iout
Im+1,n
Stage 1 Stage 2 Stage 3
그림 3. 쌍일차 보간 연산 구조[10]
Fig. 3. Structure of bilinear interpolation.
(3)의 보간 연산을 FPGA 등의 하드웨어로 구현하는 것은 그림 3과 같은 구조에 고정 소수점 연산(fixed- point operation)을 활용하여 처리한다[10]. 고속 연산을 위하여 다수의 곱셈기를 활용하여 병렬 연산을 적용함 과 동시에 파이프라인(pipeline)을 적용하여 고속 동작 에서의 게이트 지연 시간 문제를 해결한다.
2. 실시간 영상 워핑의 버퍼 메모리 접근 특성 실시간 영상 워핑을 위해서는 고속 보간 연산 외에 보간 연산에 사용할 픽셀 데이터를 영상 버퍼 메모리로 부터 빠르게 읽어내야 한다. 출력 필셀에 반영될 입력 영상 픽셀의 좌표는 (2)를 활용하여 구하는데, 온라인에 서 하드웨어로 연산하는 것 보다 오프라인에서 소프트 웨어로 연산하는 것이 구현의 편리성과 좌표 변환 변경 에 대한 유연성 등의 측면에서 유리하므로 모든 출력 픽셀에 대해 (2)의 변환 수식을 오프라인에서 미리 연 산하고 LUT 형태로 메모리에 저장하여 활용하는 방식 을 사용한다[10]. LUT에는 기준 픽셀의 좌표 과 보간에 사용할 가중치 와 가 저장된다.
그림 2에 나타낸 역방향 매핑을 활용한 영상 워핑에 서는 출력 픽셀을 OSL 순서로 생성할 때, 저장된 LUT 는 순차적으로 읽는 반면 보간에 사용될 입력 픽셀은 ISL 상에 존재하므로 입력 영상 버퍼 메모리를 비순차 적으로 접근하게 된다[10]. 입력 영상과 LUT를 저장할 메모리 소자는 SDRAM이 가장 보편적 선택인데, SDRAM 은 순차적 접근에서는 높은 입출력 속도를 나타내지만 비순차적 접근에서는 입출력 속도가 현저히 저하되어
Offline(PC software) Given a 2D transform H
Compute H-1 for all output pixels
Generate CLUT and ILUT
Store image data from CIS to image buffer
Image warping Online(FPGA)
Cache load Bilinear interpolation
Image and cache memory division
그림 4. 제안한 캐시 방식의 오프라인/온라인 연산 Fig. 4. Off-line/on-line operations of the proposed cache
algorithm.
실시간 성능에 문제를 발생시킨다. 또한, 하나의 출력 픽셀 생성을 위해서는 4개의 입력 픽셀 데이터가 필요 하므로 출력 영상 픽셀 수의 4배의 메모리 접근이 발생 하며, 하나의 입력 픽셀은 여러 출력 픽셀의 생성에 포 함될 수 있으므로 동일한 입력 픽셀을 반복적으로 읽기 위한 영상 버퍼 메모리 접근이 발생한다.
SDRAM의 비순차적 접근에서의 속도 저하와 불필요 한 메모리 접근 횟수를 줄이는 방법으로 일반 컴퓨터 시스템의 캐시를 응용한 영상 캐시를 활용하는 방법이 연구되었다[11]. 하지만, 일반 컴퓨터의 캐시는 캐시 태그 (cache tag) 관리 및 캐시 부적중(cache miss) 발생에 대한 대응, 그리고 캐시 부적중을 줄이는 방법[16] 등 상 당히 복잡한 기능이 필요하므로 구현하기에 어려움이 있는데, 이는 가까운 미래에 사용하게 될 데이터에 대 한 정확한 정보가 없는 관계로 예상하지 못한 동적 상 황에 대응해야 하는 필요성 때문이다. 반면, 실시간 영 상 워핑에서의 영상 버퍼 메모리 접근의 특성을 확인하 면 다음과 같다.
y 각 출력 픽셀의 생성에 필요한 입력 픽셀은 좌표 변 환 에 의하여 결정되므로 각 입력 픽셀이 필요한 시점을 오프라인에서 정확히 예측 가능함.
y 모든 영상 프레임에 동일한 좌표변환을 적용하므로 입력 영상 픽셀을 읽는 순서는 영상 프레임 단위로 항상 일정함.
이러한 특성을 바탕으로 입력 픽셀이 보간에 사용될 시점 이전에 캐시 메모리에 로드하도록 캐시 컨트롤러 의 동작을 오프라인에서 미리 결정할 수 있다. 이를 별 도의 LUT 형태로 저장하여 활용하면 캐시 부적중이 발생하지 않으며, 그 결과 캐시 부적중에 대한 대응 및
IB0,0 IB1,0 IB2,0 IB3,0
IB0,1 IB1,1 IB2,1 IB3,1
ISL0 ISLk1 ISLk2 ISLk3
(a)
CB0 CB1 ... CBN-1
(b)
그림 5. 입력 영상 및 캐시 메모리 분할 (a) 영상 블록 (b) 캐시 블록
Fig. 5. Division of input image and cache memory (a) Image block (b) Cache block.
캐시 부적중을 줄이는 기능 등이 불필요하므로 캐시 컨 트롤러가 매우 단순해진다. 또한, 한번 캐시에 로드된 입력 픽셀은 더 이상 사용되지 않는 시점까지 재사용하 므로 동일 픽셀을 읽기 위한 반복적인 메모리 접근을 없애서 메모리 접근 횟수를 줄일 수 있다.
Ⅲ. 영상 데이터 캐시를 활용한 영상 워핑
본 논문에서는 영상 워핑의 보간 연산에 필요한 입력 영상 픽셀의 순서를 확인하고, 이를 바탕으로 캐시 컨 트롤러의 동작을 오프라인에서 계획함으로써 온라인에 서의 캐시 컨트롤러 동작을 단순화하는 방법을 제안한 다. 그림 4에는 제안하는 캐시 방식을 오프라인 연산과 온라인 연산으로 구분하여 나타내었다. 우선 모든 출력 픽셀 좌표에 대하여 (2)를 연산하여 각 출력 영상 픽셀 의 보간 연산에 필요한 입력 영상 픽셀을 확인한다. 이 로부터 캐시 컨트롤러의 동작을 계획하여 캐시 LUT(Cache LUT, CLUT)에 저장하고, 보간 연산을 위 한 세부 사항은 보간 LUT(Interpolation LUT, ILUT)에 저장한다. 온라인에서는 CLUT에 따라 영상 버퍼로부 터 캐시 메모리로 영상 데이터를 이동하고, ILUT에 따 라 보간 연산을 수행하여 출력 영상 픽셀을 생성한다.
여기서 영상 버퍼 메모리의 특성을 고려하여 분할한 입 력 영상과 캐시 메모리에 대한 정보를 오프라인과 온라 인에서 활용한다.
IB0,0 IB1,0 IB2,0 IB3,0
IB0,1 IB1,1 IB2,1 IB3,1
Cache Load Scan Line Cache Free Scan Line
ISL0 ISLk1 ISLk2 ISLk3
(a)
Free all CBs CLSL # = 0 CFSL # = 0
yes IB#, CB#, CFSL # to CLUT CB#, addr. in IB, weights to ILUT
Free Cache Block?
CFSL # ++
no CLSL # ++
Final Line?
no Finish
Impossible CFSL # >= CLSL # yes
yes
no
(b)
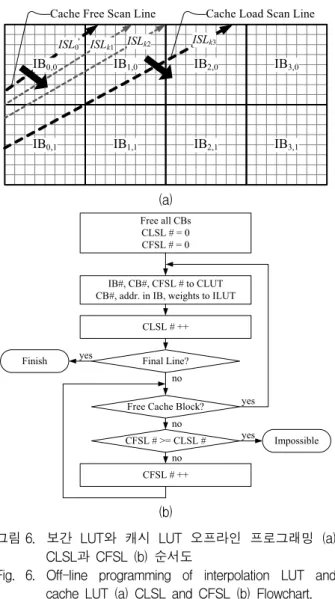
그림 6. 보간 LUT와 캐시 LUT 오프라인 프로그래밍 (a) CLSL과 CFSL (b) 순서도
Fig. 6. Off-line programming of interpolation LUT and cache LUT (a) CLSL and CFSL (b) Flowchart.
1. 입력 영상 및 캐시 메모리 분할
영상 워핑에 사용될 입력 영상 픽셀의 순서를 사전에 알고 있지만 각 픽셀 단위로 캐시에 로드하면 비순차적 접근으로 인한 영상 버퍼 메모리의 입출력 속도 저하가 발생하므로 순차적인 메모리 접근이 발생하도록 영상 버퍼 메모리로부터 영상 캐시로의 캐시 로드(cache load)는 일정 블록 단위로 실행한다. 이를 위하여 입력 영상과 캐시 메모리를 그림 5와 같이 일정한 크기의 영 상 블록(image block)과 캐시 블록(cache block)으로 분 할한다. 여기서 영상 블록과 캐시 블록은 동일한 크기 로 설정하고, 캐시 로드는 영상 블록 단위로 실행한다.
그림 5(a)에는 그림 2에서 설명한 ISL을 같이 나타내 었다. 여기서 는 출력 영상의 라인 번호를 의미한다. 가 지나는 위치의 입력 픽셀이 출력 영상의 번째 라인을 생성하는데 필요한 입력 픽 셀이므로 와 겹치는 영상 블록은 번째 라인 생성
전에 캐시에 로드하여야 한다. 예를 들어, 그림 5(a)에 서 이 지나는 영상 블록인 IB0,0과 IB1,0은 0번째 출 력 라인 생성 전에 캐시로 로드되어야 한다. 또한,
은 IB0,1도 추가로 지나가므로 IB0,1은 0번째 출력 라인 생성 전에 반드시 캐시에 로드되어야하는 것은 아 니지만 번째 라인 생성 전에는 반드시 로드되어야 한다. 한편, 를 보면 추가로 지나는 영상 블록이 존재하는 반면 ISL이 서로 교차하지 않는다는 가정 하 에 IB0,0은 더 이상 사용되지 않음을 알 수 있고, 그 결 과 IB0,0이 저장되었던 캐시 블록으로는 이후에 사용될 다른 영상 블록이 로드될 수 있다.
2. 캐시 LUT와 보간 LUT의 오프라인 생성 본 논문에서 제안하는 영상 캐시를 위해서는 오프라 인에서 CLUT와 ILUT를 생성하여야 한다. 그림 6에는 이를 위한 오프라인 프로그래밍 절차를 요약하였다. 우 선 그림 6(a)과 같이 캐시 로드 스캔 라인(Cache Load Scan Line, CLSL)과 캐시 프리 스캔 라인(Cache Free Scan Line, CFSL)을 표시한다. 이 두 라인은 입력 영상 에 표시한 ISL을 순차적으로 이동하는데, CLSL은 CLUT와 ILUT 추가를 담당하고 CFSL은 캐시 메모리 에서 지워도 되는 영상 블록을 찾아 빈 캐시 블록을 확 보하는 기능을 담당한다. 이를 활용한 오프라인 프로그 래밍 절차는 그림 6(b)에 순서도로 나타내었다. 초기 상 태로 CLSL과 CFSL는 으로 설정되며, 다음의 규 칙에 따라 진행한다.
y RULE 1 : 빈 캐시 블록이 존재하는 경우, CFSL은 고정한 채로 CLSL이 지나는 영상 블록 번호와 이 영상 블록을 저장할 캐시 블록 번호, 그리고 현재 CFSL 번호를 CLUT에 저장. 또한, 현재 CLSL 위 의 모든 대응점에 대하여 각 대응점 주변 4개 픽셀 이 저장된 캐시 번호와 영상 블록 내부 위치, 그리 고 기준 픽셀에 대한 오프셋을 ILUT에 저장한 후 CLSL은 다음 ISL로 이동. 이 과정은 모든 캐시 블 록이 영상 블록으로 채워질 때까지 반복.
y RULE 2 : 빈 캐시 블록이 남지 않은 경우, CLSL은 고정한 상태로 CFSL을 순차적으로 이동하는데, CLSL을 앞지를 수는 없음. 이 과정은 빈 캐시 블록 이 발생할 때까지 반복.
y RULE 3 : CLSL 번호가 출력 영상의 마지막 라인 이면 종료.
표 1. 캐시 LUT 항목 Table 1. Entities of cache LUT.
항목 설명
Source IB# 캐시로 로드할 영상 블록 Destination CB# 영상 블록을 저장할 캐시 블록 Out Image Line# 캐시 로드할 시점의 출력 영상 라인
표 2. 보간 LUT 항목
Table 2. Entities of interpolation LUT.
항목 설명
CB# 보간에 사용할 픽셀이 저장된 캐시 블록 Position in CB 해당 픽셀의 캐시 내부 위치
Weights 보간에 적용할 가중치 와
y RULE 4 : 빈 캐시 블록이 없는 상황에서 CFSL과 CLSL이 같아지면 더 이상 변화가 발생하지 않는데, 이 경우는 캐시 블록 갯수가 부족하여 해당 영상 워 핑을 실시간으로 수행할 수 없음을 의미함.
오프라인에서 캐시 동작을 미리 결정하여 생성한 CLUT의 구성 항목을 표 1에 나타내었다. 캐시 로드는 영상 블록 단위로 수행되므로 로드할 영상 블록 번호, 저장할 공간인 캐시 블록 번호, 그리고 캐시 로드를 실 행할 시점이 포함되어야 한다. 여기서 캐시 로드는 캐 시 로드 시점으로 명시된 출력 영상 라인을 생성한 직 후에 실행된다. 표 1의 내용은 캐시 로드 1회에 해당하 므로 캐시 로드할 횟수만큼 생성한다.
제안된 영상 캐시를 활용하면 보간 연산에 필요한 입 력 영상 픽셀을 영상 버퍼 메모리가 아닌 캐시 메모리 에서 읽어낸다. 이를 위해서 보간 LUT에 표 2와같이 각 출력 픽셀 생성을 위한 입력 픽셀이 저장된 캐시 블 록 번호, 캐시 블록 내에서 픽셀 위치, 그리고 가중치 정보를 저장하여야 한다. 쌍일차 보간에 필요한 4개의 픽셀이 서로 다른 캐시 블록에 저장되어 있을 수 있으 므로 캐시 블록 번호는 4개가 필요하다. 반면 4개의 픽 셀은 그림 2에 나타내었듯이 서로 인접하고 있으므로 한 픽셀의 캐시 블록 내부 위치로부터 나머지 3 픽셀의 캐시 블록 내부 위치를 유추해낼 수 있으므로 캐시 블 록 내부 위치는 기준 픽셀 하나에 대한 정보만 저장하 는데, 본 논문에서는 그림 2에서 좌측 상단의 픽셀인
을 기준 픽셀로 정한다. 보간 LUT는 모든 출력 픽
셀 생성을 위하여 필요한 정보이므로 출력 영상의 해상 도만큼 필요하다.
SDRAM Buffer1 Image Buffer
Interpolation LUT
FPGA Buffer2
CMOS Image Sensor
SDRAM Control & Schedule
CIS IF
Cache LUT
Interpolation Cache Memory
Cache Ctrl.
Weighting Store Image from CIS
Cache Load
Pixel Data
Line Num.
RD Addr.
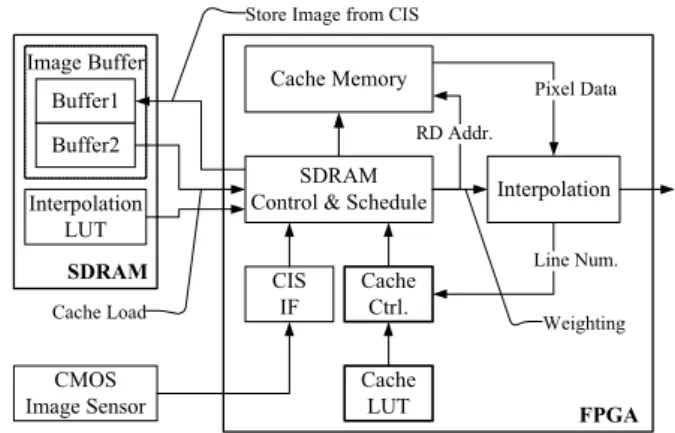
그림 7. 영상 캐시를 활용한 영상 워핑 하드웨어 구조 Fig. 7. Hardware structure for image warping using an
image cache.
3. 실시간 영상 워핑 하드웨어
그림 7에는 본 논문에서 제안하는 영상 데이터 캐시 를 활용한 영상 워핑 하드웨어의 전체 구조를 나타내었 다. 영상 워핑의 좌표 변환으로부터 캐시 컨트롤러의 동작을 오프라인에서 미리 결정하고 CLUT로 저장한 다. FPGA 외부에 장착된 SDRAM에는 영상 워핑의 좌 표 변환을 오프라인에서 연산하여 저장한 ILUT와 더블 버퍼 방식의 입력 영상 버퍼를 함께 저장하였다. ILUT 와 CLUT를 해당 메모리 공간에 저장하는 과정은 시스 템 초기화 과정에서 한번만 발생하므로 그림 7에는 생 략하였다. 각 블록의 역할을 정리하면 다음과 같다.
y CIS IF : CMOS 영상 센서 데이터를 영상 버퍼에 저장하기 위한 CIS 신호 인터페이스.
y Cache Memory : FPGA 내부 메모리를 활용한 영 상 데이터 캐시.
y Cache LUT : 캐시 컨트롤러의 동작을 오프라인에 서 미리 정의한 테이블.
y Cache Controller : Cache LUT에 따라 영상 버퍼로 부터 필요 영상 블록을 캐시 메모리로 저장.
y Interpolation : SDRAM에 저장된 ILUT에 따라 쌍 일차 보간 연산을 실행.
y SDRAM control & scheduler : 영상 버퍼 접근과 보간 LUT 읽기를 위한 SDRAM 컨트롤.
SDRAM으로의 접근은 다음의 3가지 동작으로 발생 한다.
y 입력 영상 저장 : 영상 센서에서 출력된 영상 정보 를 입력 영상 라인 단위로 영상 버퍼에 저장.
y ILUT 읽기 : 출력 픽셀 보간을 위하여 출력 영상
WR LUT RD CIS
HSYNC
SDRAM Access
Interpol.
Interpolation
WR WR
Interpol. Interpol.
(K-1)th line of Lth frame
K-1th line of (L-1)th frame Kth line of Lth frame
Kth line of (L-1)th frame
(K+1)th line of Lth frame Kth line of Lth frame
CIS
Data ... (K+1)th line of Lth frame ...
LUT RD LUT RD
cache load cache load
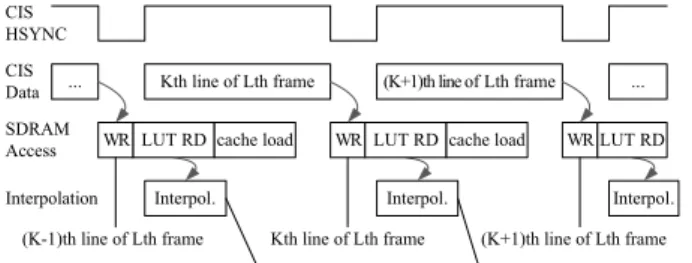
그림 8. 실시간 영상 워핑 하드웨어 동작 타이밍도 Fig. 8. Timing diagram of the real-time image warping
hardware.
한 라인 분량의 ILUT를 SDRAM에서 읽기.
y 캐시 로드 : 영상 버퍼의 영상 데이터를 영상 블록 단위로 읽기.
하나의 외부 메모리에 대해서 3가지의 메모리 접근 이 발생할 수 있으므로 스케줄링 규칙이 필요하다. 우 선, 입력 영상 저장의 우선순위를 가장 높여서 입력 영 상 정보를 잃어버리지 않도록 한다. 캐시 메모리 용량 이 허용하는 한 영상 블록은 가능한 일찍 캐시로 로드 하므로 캐시 로드의 우선순위를 가장 낮게 설정한다.
또한, 메모리 접근은 각각 일정한 시간동안 실행되므로 비선점형(non-preemptive) 방식을 사용하여 우선순위가 낮은 메모리 접근이라도 일단 시작되면 중단되지 않는 다. 가장 우선순위가 낮은 캐시 로드 시간을 확보하기 위하여 ILUT 읽기 동작이 연속적으로 발생하는 것은 방지하였다. 그림 8에는 실시간 영상 워핑 하드웨어의 동작을 타이밍도로 표현하였다. 워핑 시스템은 영상 센 서에서 출력되는 HSYNC(Horizontal Synchronization) 신호에 동기되어 동작하도록 구성하였으며, 그 결과 영 상의 수평 라인 단위로 처리된다.
Ⅳ. 실험 및 결과
1. 실험 환경 및 실시간 성능
제안된 영상 캐시를 활용한 실시간 영상 워핑 하드웨 어를 구현하고, 이를 실험에 적용하여 그 타당성을 확 인한다. 그림 9에는 실험에 활용된 FPGA 기반 영상 워 핑 시스템을 나타내었다. 영상 센서는 640x512 해상도 의 컬러 영상 센서를 사용하였지만 영상 캐시 알고리즘 검증을 위하여 문제를 단순화하는 차원에서 실험에는 512x512 해상도의 30 fps(frames per second) 흑백 영 상으로 활용한다.
전체 시스템은 Xilinx 사의 Spartan6 계열 FPGA를
PHY for GigE Vision Image sensor FPGA
SDRAMDDR2 USB3.0
그림 9. FPGA 기반 영상 워핑 실험 환경
Fig. 9. Experimental setup for FPGA-based image warping.
탑재한 EVM 보드를 활용하여 구현되었으며, 입력 영 상과 출력 영상을 동시에 PC에서 확인할 수 있도록 USB3.0과 GigE Vision 인터페이스를 각각 활용한다.
FPGA는 Verilog HDL을 활용하여 작성되었으며, FPGA 내부에서의 최대 클럭 주파수는 156 MHz를 사 용하였다. 외부 영상 버퍼 메모리로 사용된 128 MByte DDR2 SDRAM은 16 비트 데이터 버스로 최대 1.2 GB/s의 메모리 대역폭을 가진다. 캐시 메모리 용량은 1 kbyte 캐시 블록 64개에 해당하는 64 kbyte를 사용하였 는데, 이는 영상 크기의 25%에 해당한다.
실시간 처리 성능과 관련하여 구현된 시스템에서는 영상 워핑에 프레임당 15 ms가 소요된다. 실시간 처리 성능 비교를 위하여 PC와 Cortex-M4 계열의 임베디드 비전 시스템에서 소프트웨어로 처리할 때의 프레임당 소요 시간은 각각 5ms와 110 ms가 소요되었다[10]. 160 MHz 클럭 주파수를 사용하는 저사양 CPU에서는 실시 간 처리가 불가능한 반면 156 MHz의 클럭 주파수를 사용하는 FPGA에서는 실시간 처리가 가능하다. PC에 서는 2 GHz 이상의 높은 클럭 주파수와 6 MByte의 캐 시 메모리를 바탕으로 본 논문에서 구현한 FPGA 방식 보다 빠른 처리 속도를 나타내지만, 고가의 CPU가 개 별 픽셀에 대한 연산을 수행하느라 약 15%의 CPU 연 산 시간을 소모하는 문제가 있다.
또한, GPU를 활용한 기존 연구[4]에서는 576p 해상도 의 영상 워핑에 3 ms의 처리 시간이 소요되어 매우 빠 른 속도를 나타내지만, 이 경우도 1.5 GHz의 높은 클럭 주파수와 384 비트 데이터 버스를 활용한 190 GB/s의 높은 메모리 대역폭을 활용한 결과이다. 결과적으로 고 성능 CPU 또는 GPU의 경우 절대적인 처리 속도는 본 논문에서 구현한 결과보다 3배에서 5배 빠르지만 이는 10배 이상 높은 클럭 주파수와 100배 이상 높은 메모리
(a)
FPGA PC software (b)
FPGA PC software
(c)
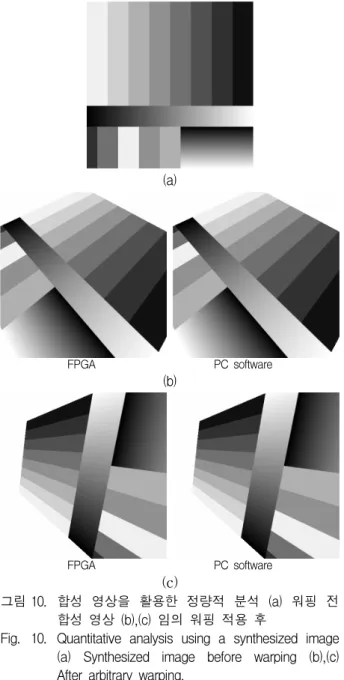
그림 10. 합성 영상을 활용한 정량적 분석 (a) 워핑 전 합성 영상 (b),(c) 임의 워핑 적용 후
Fig. 10. Quantitative analysis using a synthesized image (a) Synthesized image before warping (b),(c) After arbitrary warping.
Before warping After warping (a)
Before warping After warping (b)
Before warping After warping (c)
그림 11. 실시간 카메라 영상 워핑 (a),(b) 임의 워핑 (c) 렌즈 왜곡 보정 워핑
Fig. 11. Real-time camera image warping (a),(b) Arbitrary warping (c) Lens distortion correction warping.
대역폭을 활용한 결과로 볼 수 있다. 한편, GPU의 경우 코어에서의 연산 속도는 매우 빠른 반면 CPU와 GPU 간의 데이터 전송에 많은 오버헤드가 발생하며, 특히 GPU에서 CPU로의 데이터 전송에서의 속도 저하는 매 우 심각하다[5]. 그 결과 GPU를 활용한 영상 워핑 결과 는 디스플레이 장치로 출력하는 것으로 종료되는 응용 분야에 주로 활용된다.
2. 합성 영상을 활용한 하드웨어 검증
실제 영상 센서로부터 획득한 영상을 워핑하기에 앞 서 구현된 하드웨어의 정확성을 정량적으로 확인하기 위하여 FPGA 내부에서 합성한 테스트 영상을 구현된 영상 워핑 시스템에 입력하여 그 결과 영상을 확인한
다. 동일한 합성 영상을 PC에서 생성하여 소프트웨어로 영상 워핑을 수행하고, 그 결과를 기준으로 FPGA 출력 영상의 정확성을 확인한다.
그림 10(a)에는 정확성 검증에 활용된 합성 영상을 나타내었으며 실시간 워핑 시스템에서 임의의 워핑을 적용한 결과를 그림 10(b)와 그림 10(c)에 나타내었다.
제안한 캐시를 활용한 FPGA에서의 워핑 결과와 PC에 서 소프트웨어로 워핑한 결과를 비교하였을 때, 시각적 으로는 그 차이를 확인할 수 없다. 이는 보간 연산에 필 요한 입력 영상 픽셀이 캐시 메모리에 필요 시점 이전 에 올바르게 로드되었음을 의미한다. 한편, 그림 10(c) 에 나타낸 영상 워핑은 약 90도 정도의 회전이 포함되 어 FPGA 내부 메모리를 단순 링버퍼 형태로 활용하는
방식[13~15]에서는 실시간 처리가 불가능하다. 또한, 온라 인에서 캐시 동작을 결정하는 방식[11]과 달리 캐시 부적 중 상황이 발생하지 않으므로 시간 지연에 의한 실시간 처리 속도의 감소가 발생하지 않으며, 입력 픽셀 데이 터는 외부 영상 버퍼로부터 캐시 메모리로 단 한번만 로드되어 메모리 접근 회수를 최소화한다.
출력 영상에서 픽셀 단위의 보간 연산 정확성을 확인 해보면 PC는 부동 소수점 연산을 사용한 반면 FPGA는 고정 소수점 연산을 사용하였음에도 512x512 해상도의 8 비트 픽셀 중 각각 3개와 8개 픽셀에서만 최하위 비 트의 오차가 있었을 뿐 나머지 픽셀에서는 모두 동일한 결과를 확인하였다. 일반적인 영상 처리에서는 다양한 센서 노이즈를 감안하여 하위 2~3비트 오차는 허용 가 능한 오차로 간주[10]하므로 매우 정확한 결과로 판단할 수 있다.
3. 실시간 렌즈 왜곡 보정 적용
제안된 영상 데이터 캐시를 활용하여 실제 카메라 영 상에 대한 실시간 영상 워핑을 수행하고, CIS의 원본 영상과 워핑 후의 영상을 그림 11에 나타내었다. 그림 11(a)와 그림 11(b)에는 각각 그림 10(b)와 그림 10(c)의 합성 영상에 적용한 동일한 영상 워핑을 적용하였으며, 그림 11(c)에는 렌즈 왜곡 보정을 위한 영상 워핑을 적 용하였다. 렌즈 왜곡을 보정하기 위한 좌표 변환은 카 메라 캘리브레이션을 통하여 구하고, 이를 바탕으로 오 프라인 프로그램으로 ILUT와 CLUT를 생성하여 구현 된 시스템에 적용한다. 실제 카메라 영상에 대한 3가지 실험에서 FPGA로 구현된 영상 워핑 시스템은 모두 동 일하며, 다만 ILUT와 CLUT만 변경함으로써 다른 영 상 워핑을 적용할 수 있다. 3 경우 모두 초당 30장의 영 상을 끊김없이 실시간으로 워핑할 수 있음을 확인하였다.
Ⅴ. 결 론
본 논문에서는 FPGA를 활용한 실시간 영상 워핑 구 현을 위하여 새로운 영상 캐시 알고리즘을 제안하였다.
영상 버퍼로부터 캐시 메모리로의 캐시 로드 관련 세부 사항을 오프라인 소프트웨어에서 미리 결정하므로 캐시 컨트롤러의 구현이 단순하고, 캐시 부적중으로 인한 시 간 지연이 발생하지 않으며, 영상 버퍼로 사용되는 외 부 메모리 접근 횟수를 최소화한다. 제안된 영상 캐시 방식을 활용한 실시간 영상 워핑 시스템을 FPGA로 구 현하고, 실험을 통하여 타당성 및 정확성을 확인하였다.
실시간 처리 성능을 고성능 CPU 또는 GPU를 활용 한 영상 워핑과 비교하였을 때, 절대적인 처리 속도는 뒤지지만 낮은 클럭 주파수 및 메모리 대역폭에도 불구 하고 실시간 처리 성능을 만족함을 확인하였다. 본 논 문에서는 제안한 영상 캐시 방식의 타당성을 검증하는 차원에서 VGA급 저해상도의 흑백 영상을 사용하여 문 제를 단순화하였으나 향후 HD급 고해상도 컬러 영상으 로의 추후 연구가 필요하다.
REFERENCES
[1] J. Park, S.-C. Byun, and B.-U. Lee, “Lens distortion correction using ideal image coordinates,” IEEE Transactions on Consumer Electronics, vol. 55, no. 3, pp. 987-991, Aug.
2009.
[2] Z. Chen, C. Wu, and H. T. Tsui, “A new image rectification algorithm,” Pattern Recognition Letters, vol. 24, no. 1-3, pp. 251-260, Jan. 2003.
[3] M. Brown and D. G. Lowe, “Automatic panoramic image stitching using invariant features,” International Journal of Computer Vision, vol. 74, no. 1, pp. 59-73, Aug. 2007.
[4] R. Melo, G. Falcao, and J. P. Barreto, “Real-time HD image distortion correction in heterogenous parallel computing systems using efficient memory access patterns,” Journal of Real-Time Image Processing, vol. 11, no. 1, pp. 83-91, Jan.
2016.
[5] J. Park, J. Choi, B.-K. Seo, and J.-I. Park, “Fast stereo image rectification using mobile GPU,” in Proc. of the 3rd International Conference on Digital Information Processing and Communications 2013, pp. 485-488, Dubai, UAE, Jan. 2013.
[6] E. Peek, B. Wunsche, and C. Lutterroth, “Using integrated GPUs to perform image warping for HMD,” in Proc. of the 29th International Conference on Image and Vision Computing New Zealand, pp. 172-177, Hamilton, New Zealand, Nov. 2014.
[7] W. Wang, J. Yan, N. Xu, Y. Wang, and F.-H.
Hsu, “Real-time high-quality stereo vision system in FPGA,” IEEE Transactions on Circuits and Systems for Video Technology, vol.
25, no. 10, pp. 1691-1708, Oct. 2015.
[8] H. M. Moon and S. B. Pan, “VLSI architecture of digital image scaler combining linear interpolation and cubic convolution interpolation,”
Journal of The Institute of Electronics and
저 자 소 개 최 용 준(정회원)
2012년 서울과학기술대학교 제어 계측공학과 학사 졸업.
2014년 서울과학기술대학교 전기 정보공학과 석사 졸업.
2014년∼현재 단암시스템즈(주) 주임연구원.
<주관심분야 : 서보 제어, FPGA를 활용한 디지털 제어 시스템, 영상 신호 인터페이스>
류 정 래(정회원)
1996년 한국과학기술원 전기 및 전 자공학과 학사 졸업.
1998년 한국과학기술원 전기 및 전 자공학과 석사 졸업.
2004년 한국과학기술원 전자전산학 과 박사 졸업.
2005년∼현재 서울과학기술대학교 전기정보공학과 부교수.
<주관심분야 : 강인 동작 제어, DSP 기반 디지털 제어 시스템 설계, 실시간 영상 처리>
Information Engineers, vol. 51, no. 3, pp.
579-584, March 2014.
[9] D. Han, J. Choi, and H. C. Shin, “A real-time hardware architecture for image rectification using floating point processing,” Journal of The Institute of Electronics and Information Engineers, vol. 51, no. 2, pp. 342-353, Feb. 2014.
[10] J. R. Ryoo, E. S. Lee, and T.-Y. Doh, “An implementation of real-time image warping using FPGA,” IEMEK Journal of Embedded Systems and Applications, vol. 9, no. 6, pp.
335-344, 2014.
[11] P. Greisen, S. Heinzle, M. Gross, and A. P Burg,
“An FPGA-based processing pipeline for high-definition stereo video,” Journal of Image and Video Processing, vol. 2011, no. 18, pp.
1-13, Nov. 2011.
[12] J.-h Kim, J.-g. Kim, J.-k. Oh, S.-m. Kang, and J.-D. Cho, “Efficient hardware implementation of real-time rectification using adaptively compressed LUT,” Journal of Semiconductor Technology and Science, vol. 16, no. 1, pp. 44-57, Feb. 2016.
[13] J. Moon and J. Kim, “Real-time FPGA rectification implementation combined with stereo camera,” in Proc. of the 2015 IEEE International Symposium on Consumer Electronics, pp. 1-2, Madrid, Spain, June 2015.
[14] P. Zicari, “Efficient and high performance FPGA-based rectification architecture for stereo vision,” Microprocessors and Microsystems, vol.
37, no. 8, pp. 1144-1154, Nov. 2013.
[15] X. Yuan, Z. Qinghai, G. Liwei, Z. Mingcheng, and R. K. F. Teng, “Study of a FPGA real-time multi-cameras cylindrical panorama video system with low latency and high performance,” in Proc. of the 11th Image, Video and Multidimensional Signal Processing Workshop, pp. 1-4, Seoul, Korea, June 2014.
[16] J. L. Hennessy and D. A. Patterson, Computer Architecture a Quantitative Approach, Morgan Kaufmann Publishers, pp. 375-427, 1996.
![그림 3. 쌍일차 보간 연산 구조 [10]](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5069436.559043/3.892.478.767.145.516/그림-쌍일차-보간-연산-구조.webp)