1)
†To whom correspondence should be addressed.
Landscape Architecture, Gyeongnam National University of science and Technology, Korea
E-mail: [email protected]
풍수해 대응을 위한 Bootstrap방법과 SIR알고리즘 빈도해석 적용
김연수・김태균
*†・ 김형수**・ 노희성***・ 장대원
・ 장대원
(주) LIG시스템 위험관리연구소
*경남과학기술대학교 조경학과
**인하대학교 사회인프라공학과
***한국건설기술연구원 수자원·하천연구소
Frequency Analysis Using Bootstrap Method and SIR Algorithm for Prevention of Natural Disasters
Yonsoo Kim・Taegyun Kim
*†・Hung Soo Kim
**・Huisung Noh
***・Daewon Jang Risk Management Institute, LIG System Co., Ltd., Korea
*
Landscape Architecture, Gyeongnam National University of science and Technology, Korea
**
Department of Civil Engineering, Inha University, Korea
***
Hydro Science and Engineering Research Institute, KICT, Korea
(Received : 02 February 2018, Revised: 21 February 2018, Accepted: 21 February 2018)
요 약
수문기상자료의 빈도해석은 풍수해에 따른 대응 및 시설물의 설계기준에 있어 중요한 요소 중 하나이다. 일반적으로 수문기상자료 에 대한 빈도해석의 경우 관측자료는 통계적으로 정상성을 가진다고 가정하고, 확률분포의 매개변수를 고려하는 매개변수적 방법을 적용하고 있다. 이러한, 매개변수적 빈도해석을 위해서는 신뢰성 있는 충분한 자료의 수집이 필요하지만, 강수량과 다르게 적설량의 경우 계절적 특성과 함께 최근에는 기후변화로 인한 적설량 관측일수 및 평균 최심신적설량이 감소하기 때문에 부족한 자료에 대한 문제점을 보완할 필요가 있다. 이에 본 연구에서는 매개변수 빈도해석 방법과 부족한 자료의 문제점을 보완할 수 있는 표본 재추출 기법인 Bootstrap방법과 SIR(Sampling Importance Resampling)알고리즘을 적용하여 적설량의 빈도해석을 실시하였다. 58개 기상관측소에 대해 재추출된 일 최대 최심신적설량 자료를 이용한 비매개변수적 빈도해석을 통해 확률적설량을 산정하고 이를 비교 분석하였다. 빈도별 확률적설량의 증감률을 검토한 결과 매개변수적 빈도해석과 비매개변수적 빈도해석에서 증감률을 나타내는 지점들이 대부분 일치하는 것으로 나타났다. 확률적설량은 관측 자료와 Bootstrap방법에서 –19.2%∼3.9%, Bootstrap방법과 SIR알고리즘에서 –7.7%∼137.8% 정도의 차이를 보였다. 표본 재추출 기법은 관측표본이 적은 적설량의 빈도해석 및 불확실성 범위의 제시가 가능함을 확인할 수 있었고, 이는 여름철 태풍과 같이 계절적 특성을 지닌 다른 자연재난의 해석에도 적용될 수 있을 것으로 판단된다.
핵심용어 : Bootstrap방법, SIR알고리즘, 적설량, 빈도해석
Abstract
The frequency analysis of hydrometeorological data is one of the most important factors in response to natural disaster damage, and design standards for a disaster prevention facilities. In case of frequency analysis of hydrometeorological data, it assumes that observation data have statistical stationarity, and a parametric method considering the parameter of probability distribution is applied. For a parametric method, it is necessary to sufficiently collect reliable data; however, snowfall observations are needed to compensate for insufficient data in Korea, because of reducing the number of days for snowfall observations and mean maximum daily snowfall depth due to climate change. In this study, we conducted the frequency analysis for snowfall using the Bootstrap method and SIR algorithm which are the resampling methods that can overcome the problems of insufficient data. For the 58 meteorological stations distributed evenly in Korea, the probability of snowfall depth was estimated by non-parametric frequency analysis using the maximum daily snowfall depth data. The results of frequency based snowfall depth show that most stations representing the rate of change were found to be consistent in both parametric and non-parametric frequency analysis. According to the results, observed data and Bootstrap method showed a
1. 서 론
최근 기상이변에 따른 자연재난의 발생빈도와 그로 인한 피해는 심각한 수준으로 발생하고 있다. 하지만 이와 관련 된 연구는 홍수, 가뭄 및 지진 등 물리적 피해를 직접적으 로 체감할 수 있는 자연재난에 초점이 맞춰져 있는 것이 사 실이다. 과거 우리나라의 연 강수량은 계절적으로 하절기인 7∼8월에, 공간적으로 태백산맥 주변지역에 집중호우의 강 도 증가가 뚜렷하게 나타났다. 반면, 겨울철 강수량의 변화 는 뚜렷하지 않으나 온난화에 의해서 강설에서 강우로 나 타나는 비율이 점차 높아지고 있는 것으로 나타났다(KMA, http://www.kma.go.kr). 하지만, 지구 온난화에 따른 기후 변화로 연 평균 최심신적설량이 감소하는 경향과는 다르게 여름철 집중호우와 같이 짧은 시간동안 많은 양의 눈이 내 리는 현상은 증가하고 있다. 최근 우리나라의 경우 지난 2010년 1월 서울에는 40년 만에 최대 적설량을 기록한 것 을 비롯하여 2011년 2월에는 동해안의 폭설로 인하여 동해 안 지방 최심신적설량 극값 1위를 경신하였고, 2012년 창 원, 통영, 진주, 밀양 등 경남 해안지역에는 12월 최심신적 설량 기준으로 역대 가장 많은 적설량을 기록하면서 사회 적·경제적으로 큰 피해가 발생하였다. 적설로 인한 피해유 형 및 형태, 종류는 다양하지만 국내의 경우 매년 발생하는 집중호우 및 홍수에 대한 다양한 분석과 대비를 하고 있는 반면에, 적설량에 대해서는 일부 연구에 의해 어느 정도 진 전되어 있을 뿐 아직은 미흡한 실정이다. 풍수해에 따른 대 응 및 시설물의 설계기준에 있어 적설량은 중요한 요소 중 하나이며, 기후변화로 인한 적설량의 시공간 변동성은 커지 고 지역별로 상반되는 발생양상이 나타날 가능성이 높기 때문에 상대적으로 소홀했던 적설량과 관련된 연구의 중요 성이 대두되고 있다(Kim et al., 2014).
수문기상과 관련된 설계기준의 산정은 빈도해석을 통해 산정하도록 되어 있기에, 적설과 관련된 시설기준 및 방재 대책을 수립에 있어서도 적설량의 빈도해석과 적용이 필요 하다. 일반적으로 재현기간(T)이 100년인 경우 4.5×T개, 200년인 경우 5×T개 정도의 자료를 이용해야 비교적 정 확한 확률값을 얻을 수 있다(Kim et al., 2004). 그러나 최 심신적설량의 경우 강수량과 다르게 빈도해석에 필요한 지 점별 관측자료가 충분하지 않다. 그렇기 때문에 추계학적 방법 등을 이용하여 자료를 생성하고 이용하는 방법이 일 반적으로 적용되고 있다.
부족한 자료의 수를 충분한 수 만큼 만들어 내고자 할 때 일반적으로 통계학적 방법인 표본 재추출기법이 사용된다.
가장 대표적인 방법으로 Bootstrap방법과 SIR알고리즘이 있는데, Bootstrap방법은 비교적 간단하기 때문에 많은 연 구가 이루어지고 있으며, SIR알고리즘은 Bootstrap에서 파 생된 기법으로 우도함수를 고려하여 표본을 재추출할 수 있는 장점을 가지고 있다(Moon et al., 2010). Zhao et al.
(1997)은 단위도의 불확실성 분석을 위해 Bootstrap방법을 적용하여 태풍시기의 강우사상을 표본 재추출 하였으며, Beersma et al. (2007)은 연 최대치 강우사상을 이용하여 Bootstrap방법을 통해 시계열분석과 지역빈도해석을 통해 네덜란드 지역의 가뭄에 대한 평가를 수행하였다. Lee et al. (2005)은 Bootstrap방법과 SIR알고리즘을 이용하여 확 률강우량의 비교와 위험도 분석을 수행하였으며, Li (2007) 는 저수지의 용량을 정하기 위해 SIR알고리즘을 적용한 바 있다. Moon et al. (2008)은 SIR알고리즘을 이용하여 홍수 량의 변화양상을 고려한 빈도해석을 수행하였고, Moon et al. (2010)은 SIR알고리즘과 Bootstrap방법을 활용하여 기 후변화로 인한 극한강우의 빈도별 확률강우량의 변화를 산 정하였다. 그리고 Lee et al. (2011)은 Bootstrap방법 및 SIR알고리즘을 이용하여 수문해석과정에 포함된 불확실성 을 고려한 예상홍수 피해액을 도출하였다.
본 연구에서는 Bootstrap방법과 SIR알고리즘을 이용하여 확률적설량을 산정하는 방안을 제시하고자 한다.
Bootstrap방법과 함께 SIR알고리즘을 적용할 경우에 우도 함수를 사용하게 되는데 이러한 우도함수를 사용할 경우, 최근에 발생하고 있는 이상치를 반영할 수 있어 적설량 변화양상을 고려하면서 빈도해석에 필요한 충분한 자료를 생성할 수 있다는 장점이 있다. 이러한 표본 재추출 기법 은 관측표본이 적은 적설량의 빈도해석 및 불확실성 범위 의 제시가 가능함을 확인할 수 있으며, 풍수해 대응을 위 한 계절적 특성을 지닌 다른 자연재난의 해석에도 적용될 수 있다.
2. 적설량의 빈도해석 방법
2.1 매개변수적 방법을 이용한 빈도해석
확률분포를 이용한 빈도해석은 수자원분야에서 널리 이 용되고 있다. 그러나 매개적 빈도해석을 위해서는 양질의 많은 자료가 필요하며, 자연사상이 선정된 확률분포형을 따 른다는 가정이 필요하다. 또한 매개변수의 선정 방법에 의 해 결과가 달라지며, 관측자료에 따라 분포형이 달라지기도 한다(Moon et al., 2010).
수문자료 해석에 일반적으로 사용되는 확률분포형으로 difference of –19.2% to 3.9%, and the Bootstrap method and SIR(Sampling Importance Resampling) algorithm showed a difference of –7.7 to 137.8%. This study shows that the resampling methods can do the frequency analysis of the snowfall depth that has insufficient observed samples, which can be applied to interpretation of other natural disasters such as summer typhoons with seasonal characteristics.
Key words : Bootstrap Method, SIR Algorithm, Snowfall Depth, Frequency Analysis
Gamma 분포형, GEV(General Extreme Value)분포형, Gumbel 분포형, log-Gumbel 분포형, lognormal 분포형, log-Pearson type Ⅲ 분포형, Weibull 분포형, Wakeby 등 의 확률분포형을 적용하여 적정분포형을 산정한다. 모집단 의 특성을 반영하는 매개변수를 추정한 후, 적합도 검정을 통하여 추정된 매개변수와 확률분포형의 적합성을 판단하게 되는데, 확률분포형의 매개변수를 추정하는 방법 중 일반적으 로 빈도해석시 널리 사용되는 모멘트법(Method of Moments
; MOM),최우도법(Method of Maximum Likelihood ; ML), 확률가중모멘트법(Method of Probability Weighted Moments ; PWM)이 있다.
임의의 확률분포에 대한 적합도의 검정은 그 확률분포의 상대도수함수와 누가 도수함수의 이론값과 표본값을 비교 하여 그 정도를 판별하게 되며, 이에 대한 검정 방법으로
-검정, Cramer Von Mises 검정, Kolmogorov-Smirnov 검정, Probability Plot Correlation Coefficient(PPCC)검정 등이 있으며, 전 구간에 대한 적합도를 나타내는 -검정과 각각의 소구간별 적합도 분석을 위한 Kolmogorov-Smirnov 검정, Cramer Von Mises 검정 및 최근에 제안된 PPCC 검 정을 함께 적용하는 것이 적정 확률분포형을 선정하는데 있어서 신뢰도를 높일 수 있다.
2.2 비매개변수적 방법을 이용한 빈도해석
확률분포의 선정에 있어 적은 자료를 이용하여 통계학적 방법으로 확률분포를 찾아내는 것은 그만큼 불확실성이 커 지는 것이다. 그렇기 때문에 빈도해석을 위해서는 가능한 많은 양질의 자료가 필요하다(Moon et al., 2010). 이러한 문제를 보완하기 위한 방법으로 비매개변수적 표본 재추출 방법인 Bootstrap방법과 SIR알고리즘을 이용하였고, 재추 출된 충분한 수의 자료를 이용하여 빈도별 확률적설량을 산정하였다.
2.2.1 Bootstrap 방법
Eforn(1979)에 의해 제안된 Bootstrap 방법은 주어진 표 본을 토대로 표본 재추출을 하여 연구대상이 되는 통계량 의 성질을 파악하는 기법으로 통상적인 접근이 어려운 문 제들을 포함한 많은 통계문제에 여러 가지 이론적 이점들 이 밝혀져 왔다. 더욱이 컴퓨터의 발전과 더불어 그 효용성 이 나날이 높아지고 있는 실정이다(Jhun, 1996).
Bootstrap방법은 알려져 있지 않은 확률분포 로부터 크기가 인 무작위 표본 ··· 을 얻었다고 할 때, 이 관찰값 로부터 경험적 분포 를 만든 뒤 무 작위 추출 표본 ··· 를 로부터 얻는 것 을 말하며, 이를 Bootstrap 표본이라고 통칭한다. 여기서, 근본적인 생각은 표본 ··· 에 근거한 추측통 계량과 Bootstrap표본 ··· 에 의한 추측통 계량의 조건부확률분포가 적절한 조건하에서 유사할 것이 라는 점이다. 따라서 관찰된 자료에 근거한 Bootstrap분포
로서 표본분포를 추정하는 것이다. 실제계산에서는 Taylor 전개에 의한 선형 근사방법이 있으나, Monte Carlo 근사 방법이 일반적으로 받아들여지고 있다(Jhun, 1990).
2.2.2 SIR(Sampling Importance Resampling) 알고리즘 SIR(Sampling Importance Resampling) 알고리즘은 Monte Carlo 베이시안 기법의 한 종류인데, 베이시안 추론은 기존 의 고전적인 분석 방법에 비해 유용한 사전정보의 사용을 가능하게 할 뿐 아니라 표본의 크기가 작을 때에 상대적으 로 더 신뢰성 있는 분석을 할 수 있는 장점을 가지고 있다.
베이시안 추론의 주된 목적은 관심있는 모수(parameter)의 사후밀도함수를 사전밀도함수(prior density function)와 우 도함수로부터 구하는 것이다. Monte Carlo 방법은 사전에 매개변수에 임의의 값을 설정하고 관측 안 되는 변수 (unobservable variables)의 값에 대해서는 일정한 밀도함 수를 가정한 뒤 밀도함수로부터 무작위 값(random number)을 생성시킨 후 이 값을 가지고 다시 거꾸로 매개 변수를 추정하는 과정을 반복하여 모수에 대한 속성을 사 후적으로 구하는 방법이다(Kang and Park, 1996). Rubin (1987)이 제안한 SIR 알고리즘의 원리는 다음과 같다.
라는 확률분포로부터 표본의 값을 직접 모의하기 어려 울 때 와 비슷하고 모의가 쉬운 라는 확률분포를 도입하게 된다. 즉, 사전확률분포 를 결정하고, 결정된 사전 확률분포 로부터 크기가 인 표본
··· 를 취한다. 다음으로 취해진 표본 의 가중치 , ··· 를 계산한다.
여기서 표본 로부터 가 선택될 확률이 에 비례한 다고 가정한 후 새로운 표본 ··· 를 취한 다. 새롭게 취해진 를 대체하며, 와 확률적으로 비 례하는 우리가 알고자 하는 의 근사인 것이다. 사전분 포로부터 사후분포 표본의 모의를 위해 SIR 알고리즘은 다 음과 같이 적용될 수 있다. 즉, 는 우리가 관심있고 알고자 하는 매개변수이고, 이 는 사후밀도함수
··로부터 취해진다. 여기서 는 사전밀도함 수, 는 우도함수, 는 비례상수이며, 사전밀도로부터 표본을 취하는 것은 쉽다고 가정한다. 위의 SIR알고리즘에 서 이고, 로 놓으면 가중 함수 는 식(1)과 같다.
· (1)
여기서, ··· 를 사전밀도함수 로부터의 표본이라 하면, 이로부터 우리는 사전밀도함수의 표본
··· 를 특정한 가중확률
···를 갖고 대체하는 사후밀도함수의 대략적 표본 ··· 를 얻을 수 있다. 초기 표본 는 사 용자의 첫 번째 믿음을 반영하며, 매개변수의 위치에 관한 것 도 반영하게 된다. 자료를 관측하기 이전에 각 는 모두
만큼의 가중치를 갖고 있다. 이러한 가중치는 우도함수와의 곱을 통해 배가된다.(Lee et al., 2005; Moon et al., 2010)
3. 자료의 선정 및 확률적설량 산정
3.1 대상 지점 및 관측자료 선정
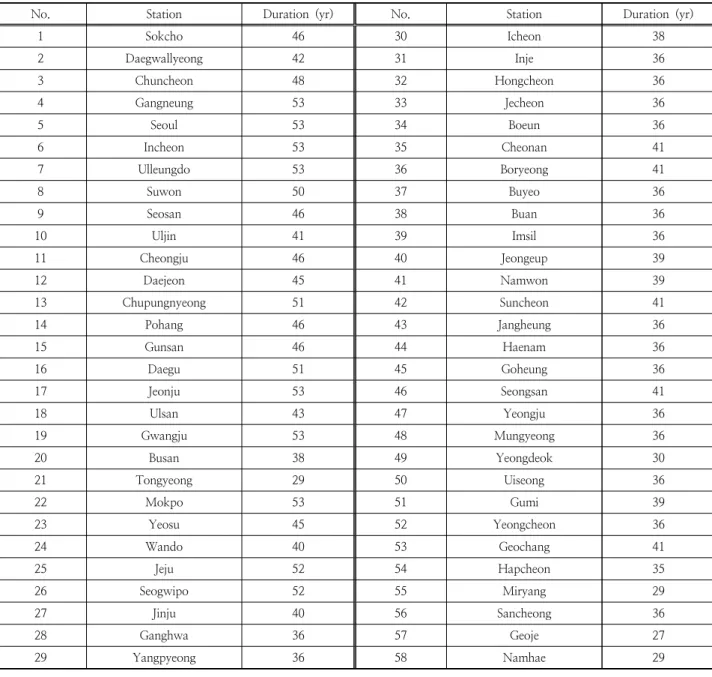
기상청 산하 관측지점 중 최심신적설량 관측자료를 보유 하고 있으며 매개변수적 및 비매개변수적 확률적설량을 산 정하고 평가가 가능한 58개 지점을 Fig. 1과 같이 선정하였 다. 관측개시일 부터 2013년까지의 최심신적설량 자료를 이용하였는데 관측소별 자료 보유기간은 Table 1과 같다.
그리고 전체 관측지점 중 지역적 위치를 고려하여 서울, 강 릉, 대전, 부산, 광주, 제주를 대표지점으로 선정하고 시계 열 및 통계수치를 제시하였다.
Fig. 1. Weather stations
Table 1. Weather station and duration
No. Station Duration (yr) No. Station Duration (yr)
1 Sokcho 46 30 Icheon 38
2 Daegwallyeong 42 31 Inje 36
3 Chuncheon 48 32 Hongcheon 36
4 Gangneung 53 33 Jecheon 36
5 Seoul 53 34 Boeun 36
6 Incheon 53 35 Cheonan 41
7 Ulleungdo 53 36 Boryeong 41
8 Suwon 50 37 Buyeo 36
9 Seosan 46 38 Buan 36
10 Uljin 41 39 Imsil 36
11 Cheongju 46 40 Jeongeup 39
12 Daejeon 45 41 Namwon 39
13 Chupungnyeong 51 42 Suncheon 41
14 Pohang 46 43 Jangheung 36
15 Gunsan 46 44 Haenam 36
16 Daegu 51 45 Goheung 36
17 Jeonju 53 46 Seongsan 41
18 Ulsan 43 47 Yeongju 36
19 Gwangju 53 48 Mungyeong 36
20 Busan 38 49 Yeongdeok 30
21 Tongyeong 29 50 Uiseong 36
22 Mokpo 53 51 Gumi 39
23 Yeosu 45 52 Yeongcheon 36
24 Wando 40 53 Geochang 41
25 Jeju 52 54 Hapcheon 35
26 Seogwipo 52 55 Miryang 29
27 Jinju 40 56 Sancheong 36
28 Ganghwa 36 57 Geoje 27
29 Yangpyeong 36 58 Namhae 29
Fig. 3. Box plot for snowfall depth distribution 대표지점에 대한 최심신적설량을 살펴보면 Fig. 2 및 Fig.
3에서와 같이 최심신적설량은 감소하고 있으나 최댓값을 넘어 이상치로 볼 수 있는 최심신적설량은 지속적으로 발생하고 있음을 알 수 있다. 매개변수적 빈도해석을 위해 서는 신뢰성 있는 충분한 자료의 수집이 필요하지만, 강수 량과 다르게 적설량의 경우 계절적 특성과 함께 최근에는 기후변화로 인한 적설량 관측일수 및 평균 최심신적설량 또한 감소하기에 관측년 수에 비해 부족한 자료를 보완할
필요가 있다. 이에 본 연구에서는 매개변수 빈도해석 방법 과 부족한 자료의 문제점을 보완할 수 있는 표본 재추출 기 법인 Bootstrap 기법과 SIR 알고리즘을 적용하여 적설량의 빈도해석을 실시하였다. 특히 SIR 알고리즘을 통한 빈도해 석은 우도함수를 고려했기 때문에 재추출된 표본에서 이상 치에 해당하는 극치사상을 고려할 수 있다.
3.2 매개변수적 방법을 통한 확률적설량 산정
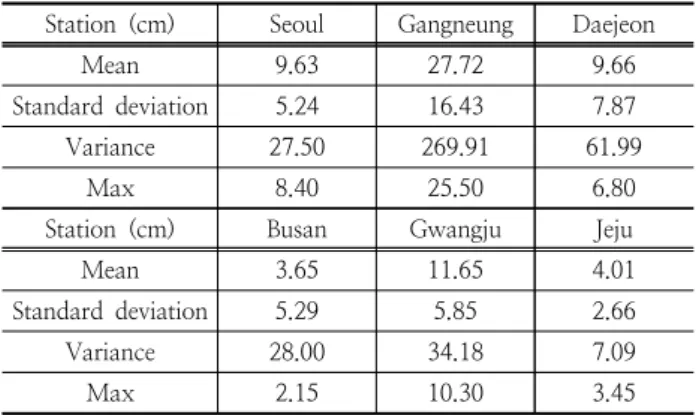
매개변수적 빈도해석에서는 관측개시일 부터 2013년까지 관측된 최심신적설량 자료의 연 최대 최심신적설량을 이용하 였으며, 대표지점의 기초통계 특성은 Table 2와 같다. 수문자료
Table 2. Statistical characteristics of observation data Station (cm) Seoul Gangneung Daejeon
Mean 9.63 27.72 9.66
Standard deviation 5.24 16.43 7.87
Variance 27.50 269.91 61.99
Max 8.40 25.50 6.80
Station (cm) Busan Gwangju Jeju
Mean 3.65 11.65 4.01
Standard deviation 5.29 5.85 2.66
Variance 28.00 34.18 7.09
Max 2.15 10.30 3.45
(a) Seoul Station (b) Gangneung Station (c) Daejeon Station
(d) Busan Station (e) Gwangju Station (f) Jeju Station
Fig. 2. Annual maximum snowfall depth
해석에 일반적으로 사용되는 확률분포형으로 Gamma 분포형, GEV(General Extreme Value)분포형, Gumbel분포형, Log-Normal 분포형, Log-Pearson type III 분포형, Weibull 분포형, Wakeby 분포형 등의 확률분포형을 적용하여 적정분포형을 산정한다. 모집단의 특성을 반영하는 매개변 수를 추정한 후, 적합도 검정을 통하여 추정된 매개변수와 확 률분포형의 적합성을 판단하게 되는데, 확률분포형의 매개 변 수를 추정하는 방법 중 일반적으로 빈도해석시 널리 사용되 는 모멘트법(Method of Moments; MOM),최우도법 (Method of Maximum Likelihood; ML), 확률가중모멘트 법(Method of Probability Weighted Moments; PWM)이 있 다. 임의의 확률분포에 대한 적합도의 검정은 그 확률분포의 상 대도수함수와 누가 도수함수의 이론값과 표본값을 비교하여 그 정도를 판별하게 되며, 이에 대한 검정 방법으로 -검정, Cramer Von Mises -검정, Kolmogorov-Smirnov 검정, Probability Plot Correlation Coefficient(PPCC)검정 등이 있 으며, 전 구간에 대한 적합도를 나타내는 -검정과 각각의 소구간별 적합도 분석을 위한 Kolmogorov-Smirnov 검정, Cramer Von Mises 검정 및 최근에 제안된 PPCC 검정을 함께 적용하는 것이 적정 확률분포형을 선정하는데 있어서 신뢰도를 높일 수 있다. 매개변수는 모멘트법, 최우도법, 확 률가중모멘트법을 사용하여 추정하였으며, 확률분포형 선정 은 기존에 연구된 내용을 종합적으로 고려하여 확률가중모 멘트법(PWM)을 이용하였다. 적합도검정은 기각력이 가장 뛰어난 PPCC 분포형을 선정하였으며, 산정지점에 대한 검 정을 1순위로, 2순위로는 -검정, 3순위 및 4순위로 Kolmogorov-Smirnov 검정과 Cramervon Mises 검정을 채 택하였다. 적설량 자료에 대한 적정분포형으로는 분포형 검 정결과 가장 적합하다고 판정되는 Gumbel분포형을 선정하 였으며, 관측자료에 대한 빈도별 확률적설량을 Table 3과 같 이 산정하였다.
3.2 Bootstrap 방법을 통한 확률적설량 산정
3.2.1 Bootstrap방법을 이용한 표본 재추출
본 연구에서는 기상관측지점별 연 최대 최심신적설량 자 료를 이용하여 Bootstrap 방법을 적용하였다. 자료의 재추출 은 1,000개 하였으며, 재추출된 자료에 대한 모의 결과 300번
Table 4. Statistical characteristics of Bootstrap data Station (cm) Seoul Gangneung Daejeon
Mean 9.66 27.96 9.53
Standard deviation 5.05 16.23 7.54
Variance 25.54 263.40 56.79
Max 8.51 26.26 6.93
Station (cm) Busan Gwangju Jeju
Mean 3.98 11.66 4.03
Standard deviation 5.08 5.61 2.63
Variance 25.81 31.44 6.92
Max 2.43 10.19 3.52
이상의 모의에서 수렴하기에 모의 횟수는 300회로 하였다. 이 에 대한 기초통계 특성은 Table 4와 같은데 관측 최심신적 설량의 기초통계특성인 Table 2와 비교하면 Bootstrap방법 이 관측 최심신적설량의 통계적 특성을 반영하고 있음을 확인할 수 있다.
3.2.2 Bootstrap방법을 이용한 빈도해석
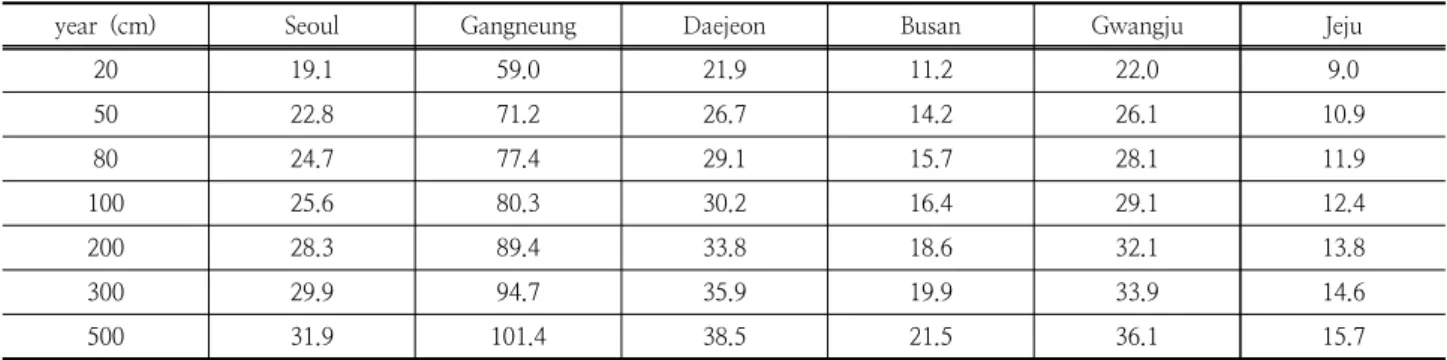
Bootstrap방법으로 재추출된 표본자료의 빈도해석을 위 한 분포형을 선정하고자 매개변수는 모멘트법(MOM),최우 도법(ML), 확률가중모멘트법(PWM)을 사용하여 추정하였 으며, 확률분포형 선정은 기존에 연구된 내용을 종합적으로 고려하여 확률가중모멘트법(PWM)을 이용하였다. 적합도 검정은 기각력이 가장 뛰어난 PPCC 분포형을 선정하였으 며, 산정지점에 대한 검정을 1순위로, 2순위로는 -검정, 3순위 및 4순위로 Kolmogorov-Smirnov 검정과 Cramer von Mises 검정을 채택하였다. 적설량 자료에 대한 적정분 포형으로는 분포형 검정결과 가장 적합하다고 판정되는 Gumbel 분포형을 선정하여 빈도별 평균 확률적설량을 Table 5 및 Fig. 4와 같이 산정하였다.
빈도별 평균 확률적설량은 300회 모의에 대한 모의 횟수 별 빈도해석에 대한 평균값으로 Table 5와 같으며 빈도해 석에 대한 불확실성 범위는 Fig. 4와 같이 도시화 하였다.
재현기간이 커짐에 따라 불확실성도 커지는 것을 확인할 수 있으며, 빈도별 확률적설량은 강릉지점이 가장 크게 나 타났다.
Table 3. Frequency based snowfall depth (Observation data)
year (cm) Seoul Gangneung Daejeon Busan Gwangju Jeju
20 19.1 59.0 21.9 11.2 22.0 9.0
50 22.8 71.2 26.7 14.2 26.1 10.9
80 24.7 77.4 29.1 15.7 28.1 11.9
100 25.6 80.3 30.2 16.4 29.1 12.4
200 28.3 89.4 33.8 18.6 32.1 13.8
300 29.9 94.7 35.9 19.9 33.9 14.6
500 31.9 101.4 38.5 21.5 36.1 15.7
3.3 SIR알고리즘을 이용한 확률적설량 산정
3.3.1 SIR알고리즘을 이용한 표본 재추출
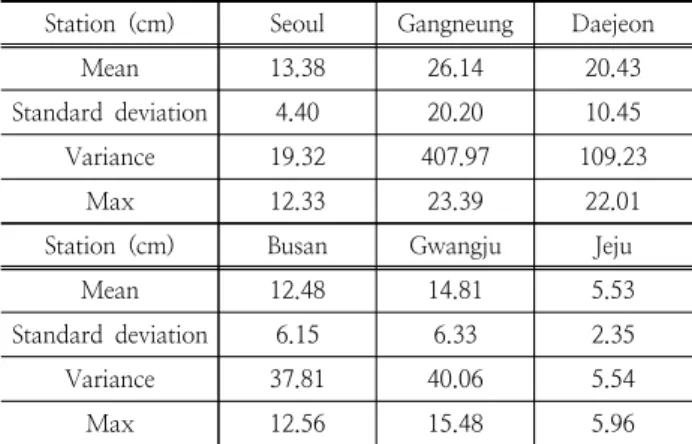
SIR알고리즘을 이용한 표본 재추출에서 우도함수의 선정 은 연 최대치 최심신적설량 중 상위 10% 이상의 최심신적 설량을 이용하였으며, Bootstrap방법과 같이 1,000개 자료 를 재추출하여 300회 모의하였다. 앞서 산정된 관측자료 및 Bootstrap방법과 SIR알고리즘을 통해 재추출된 표본의 의 기초통계특성인 Table 6과 비교하면 통계수치가 상대적 으로 크게 산정되는 것을 알 수 있다. 이는 우도함수 선정 시 Fig. 2 및 Fig. 3에서와 같이 관측지점의 경향성을 벗어 나는 관측 값이 이용되면서 극치값의 재추출 비율이 높기 때문이다.
Table 6. Statistical characteristics of SIR data
Station (cm) Seoul Gangneung Daejeon
Mean 13.38 26.14 20.43
Standard deviation 4.40 20.20 10.45
Variance 19.32 407.97 109.23
Max 12.33 23.39 22.01
Station (cm) Busan Gwangju Jeju
Mean 12.48 14.81 5.53
Standard deviation 6.15 6.33 2.35
Variance 37.81 40.06 5.54
Max 12.56 15.48 5.96
Table 5. Frequency based snowfall depth (Bootstrap data)
year (cm) Seoul Gangneung Daejeon Busan Gwangju Jeju
20 17.9 59.1 19.2 9.3 20.6 8.7
50 21.2 71.3 23.1 11.6 24.1 10.5
80 22.9 77.4 25.1 12.7 25.9 11.5
100 23.7 80.4 26.1 13.2 26.7 11.9
200 26.2 89.4 29.0 14.9 29.4 13.3
300 27.6 94.7 30.7 15.8 30.9 14.1
500 29.4 101.4 32.9 17.1 32.8 15.1
(a) Seoul Station (b) Gangneung Station (c) Daejeon Station
(d) Busan Station (e) Gwangju Station (f) Jeju Station
Fig. 4. The uncertainty of rainfall quantile using Bootstrap
3.3.2 SIR알고리즘을 이용한 빈도해석
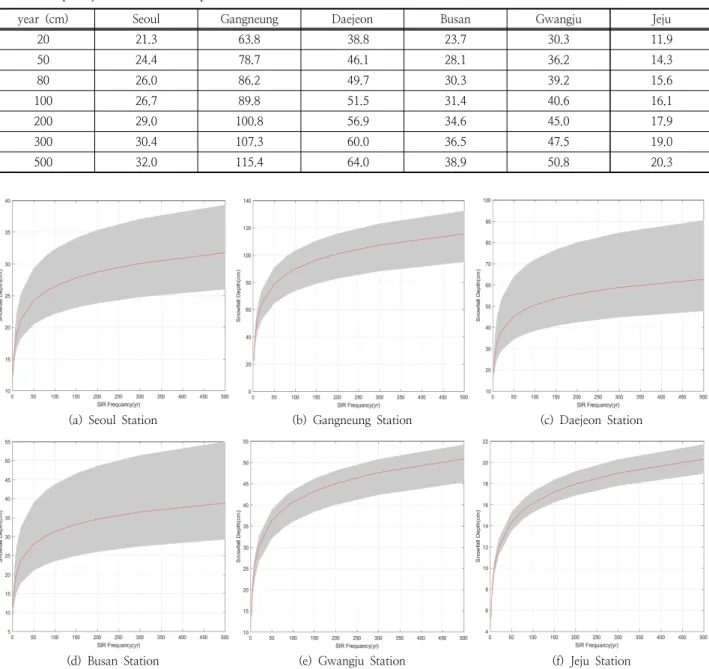
SIR알고리즘으로 재추출된 표본자료의 빈도해석을 위한 분포형 선정 및 적합도 검정은 Bootstrap방법을 이용한 빈 도해석과 같은 검정방법으로 분포형을 선정하고 확률적설 량을 산정하였다. 재추출된 표본자료의 빈도해석을 위한 분 포형은 확률가중모멘트법(PWM)을 이용하였으며, 적합도 검정은 PPCC 분포형, 산정지점에 대한 검정을 -검정, Kolmogorov-Smirnov 검정과 Cramer von Mises 검정을 채택하였다. 적정분포형으로는 Gumbel 분포형을 선정하여 빈도별 확률적설량을 Table 7 및 Fig. 5와 같이 산정하였다.
Table 7은 300회 모의에 대한 모의 횟수별 빈도해석에 대한 평균 확률적설량을 나타내며, Fig. 5는 Fig. 4와 마찬 가지로 재현기간이 증가하면서 재추출된 표본자료의 최소 및 최댓값의 편차가 커져 불확실성 범위도 넓어지는 것을
확인할 수 있다. SIR알고리즘을 이용하여 산정된 빈도별 확률적설량에서도 강릉지점이 가장 크게 나타났다.
4. 표본 재추출 방법별 확률적설량 산정 결과
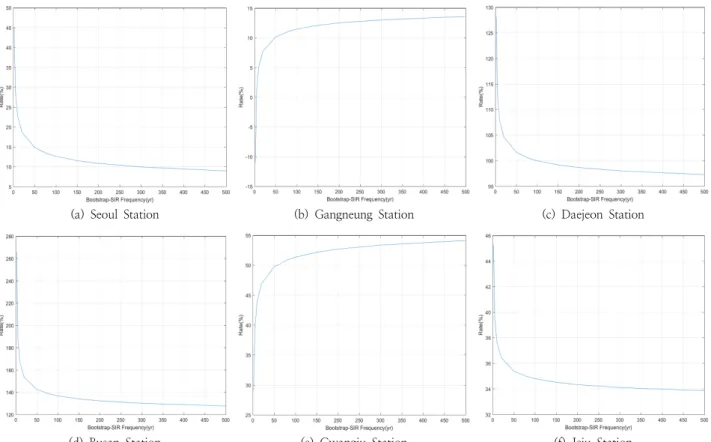
Bootstrap방법과 SIR알고리즘을 이용하여 재추출된 표본 의 빈도해석을 통해 산정된 확률적설량을 비교하였다. Fig.
6은 두 방법에 대한 결과치의 증가 및 감소율을 나타낸 것 으로 Bootstrap을 기준으로 우도함수를 고려한 SIR알고리 즘의 증감률을 비교하였다. 관측자료 및 Bootstrap방법에 의한 확률강우량인 Table 3과 Table 5를 보면 Bootstrap방 법은 관측자료의 분포형이 반영되었기에 차이가 크지 않음 을 알 수 있다.
그러나 SIR 알고리즘의 경우 우도함수 선정에 극치사상이
Table 7. Frequency based snowfall depth (SIR data)
year (cm) Seoul Gangneung Daejeon Busan Gwangju Jeju
20 21.3 63.8 38.8 23.7 30.3 11.9
50 24.4 78.7 46.1 28.1 36.2 14.3
80 26.0 86.2 49.7 30.3 39.2 15.6
100 26.7 89.8 51.5 31.4 40.6 16.1
200 29.0 100.8 56.9 34.6 45.0 17.9
300 30.4 107.3 60.0 36.5 47.5 19.0
500 32.0 115.4 64.0 38.9 50.8 20.3
(a) Seoul Station (b) Gangneung Station (c) Daejeon Station
(d) Busan Station (e) Gwangju Station (f) Jeju Station
Fig. 5. The uncertainty of snowfall depth quantile using SIR algorithm
(a) Seoul Station (b) Gangneung Station (c) Daejeon Station
(d) Busan Station (e) Gwangju Station (f) Jeju Station
Fig. 6. Bootstrap and SIR Rate of snowfall depth
(a) Observed (20yr)
(b) Bootstrap (20yr)
(c) SIR (20yr)
(d) Observed (50yr)
(e) Bootstrap (50yr)
(f) SIR (50yr)
반영되었기에 Bootstrap 방법을 이용하여 확률적설량을 산정 했을 때보다 확률적설량이 크게 증가하는 것을 확인할 수 있다.
서울, 강릉의 경우 8%~19%정도 증가하였으나, 제주의 경우 약 35%, 광주는 약 52%, 대전, 부산의 경우 약 97~155%정도 증가하였다. 강릉과 광주를 제외한 나머지 지점은 빈도가 커질 수록 확률적설량이 증가율이 감소하는 경향을 나타냈다.
관측 최심신적설량에 대한 매개변수적 빈도해석과 Bootstrap 방법과 SIR알고리즘으로 재추출된 자료를 이용하여 58개 기 상관측소를 대상으로 20년, 50년, 100년, 300년 빈도의 확률강 우량을 Fig. 7과 같이 도시화 하였다. Bootstrap방법으로 재추 출한 표본의 빈도해석 결과는 관측자료에 비하여 평균 – 7.7%(최소 –19.2%, 최대 3.9%)정도로 관측자료와의 빈도해 석 결과와 큰 차이를 보이지 않았다. 이는 Bootstrap방법이 관측 최심신적설량의 특성 및 분포형을 유지하면서 생성되었 기 때문이다. 반면에 SIR 알고리즘을 이용한 재추출된 표본의 빈도해석 결과는 평균 29.7%(최소 –7.7%, 최대 137.8%)정 도 더 크게 산정되었는데, 이는 SIR 알고리즘을 이용하여 표본 을 재추출할 때 우도함수를 고려했기 때문에 재추출된 표본에 서 극한사상이 Bootstrap방법보다 많이 생성되었기 때문이다.
Bootstrap의 경우 남원, 임실, 제천, 부안, 강릉, 전주 등 은 빈도별 확률적설량이 0.0~3.9% 크게 나타났으며, 고흥, 문경, 거제, 영덕, 울산, 부산은 –16.4~-19.2% 정도 작게
나타났다. 반면 SIR알고리즘의 경우 추풍령, 제천이 – 7.7~-5.7% 작게 나타낸 반면 남해, 영덕, 진주, 완도, 목 포, 대전, 부산 68.6~137.8% 크게 나타났으며 이외 지점들 도 0.3~55.6%사이로 Bootstrap방법에 비하여 확률적설량 의 증가폭이 큰 것으로 나타났다.
5. 결 론
매개변수적 빈도해석을 위해서는 신뢰성 있는 충분한 자 료의 수집이 필요하지만, 적설량의 경우 계절적 특성과 함 께 최근에는 기후변화로 인한 적설량 관측일수 및 평균 최 심신적설량 또한 감소하기에 부족한 자료에 대한 문제점을 보완할 필요가 있다. 또한, 기후변화에 따른 이상치에 해당 하는 최심신적설량이 관측되고 있기에 이러한 경향성을 반 영하고자 하였다.
이에 본 연구에서는 표본 재추출 기법인 Bootstrap방법 과 SIR알고리즘을 적용하여 관측자료가 부족한 최심신적설 량의 빈도해석에 유의한 자료를 생성하고 관측자료의 빈도 해석 결과와 비교하였다. 우도함수를 고려하여 재추출된 표 본으로 빈도해석이 이루어진 SIR알고리즘이 관측 최심신적 설량의 특성 및 분포형을 유지하면서 표본 재추출된 Bootstrap 방법보다 확률적설량 값이 크게 산정되었다. 이 (g) Observed (100yr)
(h) Bootstrap (100yr)
(i) SIR (100yr)
(j) Observed (300yr)
(k) Bootstrap (300yr)
(l) SIR (300yr) Fig. 7. Frequency based snowfall depth of observation, Bootstrap and SIR algorithm
는 Bootstrap방법으로 재추출된 자료들은 관측자료의 분포 를 잘 반영하고 있지만 SIR 알고리즘은 빈도해석시 우도함 수 선정에 극한사상이 반영되기 때문에 상대적으로 확률적 설량이 큰 것으로 나타났다.
최근 기상이변에 따른 임계치를 넘어서는 최심신적설량 이 발생하고 있기 때문에 우도함수를 극한사상으로 고려하 여 적설량 발생 특성을 반영하고자 하였다. 우도함수 선정 시 연 최대 최심신적설량 중 상위 10% 값을 이용했으나, 극한사상의 범위에 따라 결과가 달라지기 때문에 추후 적 정범위 선정에 관한 연구가 보완된다면 산정된 확률적설량 의 불확실성을 감소시킬 수 있을 것으로 판단된다.
본 연구를 통해 관측자료의 표본 재추출 및 변화양상에 따른 우도함수 예측은 관측표본이 적은 적설량의 빈도해석 및 불확실성 범위의 제시가 가능함을 확인할 수 있었고, 이 는 여름철 태풍과 같이 계절적 특성을 지닌 다른 자연재난 의 해석에도 적용될 수 있을 것으로 판단된다.
사 사
이 논문은 2016년도 경남과학기술대학교 대학회계 연구비 지원에 의하여 연구되었음.
References
Beersma, J.J. and Buishand, T.A. (2007) Drought in the Netherlands – Regional frequency analysis versus time series simulation, J. of Hydrology, 347(3-4), pp.332-346.
[DOI https://doi.org/10.1016/j.jhydrol.2007.09.042]
Eform, B. (1979) Bootstrap Methods: Another Look at the Jack-nife, The annual of statistics, Institute of Mathmatical Statistics, 7(1), pp.1-26
Jhun, MS (1990) A Computer Intensive Method for Modern Statistical Data Analysis Ⅰ ; Bootstrap Method and Its Applications, The Korean J. of applied statistics, 3(1), pp.121-141. [Korean Literature]
Jhun, MS (1996) Practical application of bootstrap method-Focusing on analysis of contingency table based on cluster sampling method, Communications of the Korean Statistical Society, 3(1), pp.179-188. [Korean Literature]
Kang, SH and Park, TS (1996) Analysis and Applications of Monte Carlo Bayesian, Communications of the Korean Statistical Society, 3(1), pp.169-177. [Korean Literature]
Kim, KD and Heo, JH (2004). Review on the Application of Regional Frequency Analysis According to the Sample Size of Hydrologic Data, Proceedings of the Korea Water Resources Association Conference in 2004, pp.27. [Korean Literature]
Kim, YS, Kim, SJ, Kang, NR, Kim, TG and Kim, HS (2014) Estimation of Frequency Based Snowfall Depth Considering Climate Change Using Neural Network, J. of the Korean Society of Hazard Mitigation, 14(1), pp.93-107. [Korean Literature] [DOI http://dx.doi.org/
10.9798/KOSHAM.2014.14.1.93]
Lee, KH, Lee, JK, Kim, SJ and Kim, HS (2011) Uncertainty Analysis of Flood Damage Estimation Using Bootstrap Method and SIR Algorithm, J. of wetlands research, 13(1), pp.53-66. [Korean Literature]
Lee, MW, Lee, CS, Kim, HS and Shim, MP (2005) Rainfall Frequency Determination by Bootstrap Method and SIR Algorithm and Risk Analysis, J. of the Korean Society of Civil Engineers, 25(5B), pp.365-373. [Korean Literature]
Li, K.-H. (2007) Pool size selection for the sampling/
importance resampling algorithm, Statistica Sinica, 17(3), pp.895-907.
Moon, KH, Kyoung, MS, Kim, DK, Kwak, JW and Kim, HS (2008) Flood Frequency Analysis using SIR Algorithm, J.
of wetlands research, 10(3), pp.125-132. [Korean Literature]
Moon, KH, Kyoung, MS and Kim, HS (2010), Rainfall Frequency Analysis Using SIR Algorithm and Bootstrap Methods, J. of the Korean Society of Civil Engineers, 30(4B), pp.367-377. [Korean Literature]
Rubin D.B. (1987) A Noniterative sampling/importance resampling alternative to the data augementation algorithm for creating a few imputation are modest: The SIR algorithm, J. of the american statistical addiciation, 82, pp.543-546
Zhao, B., Tung, Y.K., Yeh, K.C. and Yang, J.C. (1997) Storm resampling for uncertainty analysis of a multiple-storm unit hydrograph, J. of Hydrology, 194(1-4), pp.366-384.