A Method of Data Hiding in a File System by Modifying Directory Information
1)
전체 글
1)
수치
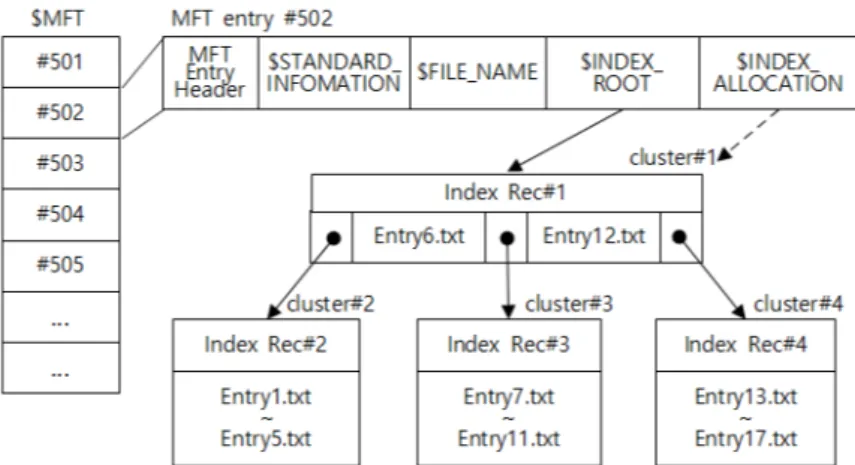
![Table 1. Structure of an index record [11,15]](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5315894.384443/3.892.456.806.456.697/table-structure-index-record.webp)
![Table 3. Structure of $FILE_NAME attribute [11,15]](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5315894.384443/4.892.94.441.447.707/table-structure-of-file-name-attribute.webp)

관련 문서
This study has a distinguished meaning from existing studies in that it presented a learning method and a teaching plan that are helpful for
As a result of the study, it was confirmed that only human resource competency had a positive(+) effect on the intercompany cooperation method of IT SMEs,
(Attached to a noun) This is used to indicate the topics, to compare two information or to emphasize the preceding noun in a sentence.. (Attached to a noun) This is used
Additionally, all Google user to download the query index data as a CVS file. So, we gather the individual companies listed on KOSPI100’s search volume index by
ECG is a valuable noninvasive diagnostic method for detection of NSTE-ACS. In addition, it has a important role in the management of NSTE-ACS such as
The simplest method of storing a raster layer in the memory of the computer is using a data structure called an array.. We consider alternative methods for searching through
We have implemented and developed a virtual angioscopy system based on the proposed methods, and tested it using several actual data sets of human blood
A preceding research regarding analysis of lifeguard’s education, operating system of developed nations and international leisure athletic tournaments is used to obtain a