더 좋은 인코더 표현을 위한 뇌 동기화 모방 이중 번역
최규현◦, 김선훈, 장헌석, 강인호 네이버, NLP
{gyuhyeon.choi, seonhoon.kim, heonseok.jang, once.ihkang}@navercorp.com
Dual Translation Imitating Brain-To-Brain Coupling for Better Encoder Representations
GyuHyeon Choi◦, Seon Hoon Kim, HeonSeok Jang, Inho Kang NLP, NAVER
요 약
인코더-디코더(Encoder-decoder)는 현대 기계 번역(Machine translation)의 가장 기본이 되는 모델이다. 인코딩은 마치 인간의 뇌가 출발어(Source language) 문장을 읽고 이해를 하는 과정과 유사하고, 디코딩은 뇌가 이해한 의미를 상응하는 도착어(Target language) 문장으로 재구성하는 행위와 비슷하다. 그렇다면 벡터로 된 인코더 표현은 문장을 읽고 이해함으로써 변화된 뇌의 상태에 해당한다고 볼 수 있다. 사람이 어떤 문장을 잘 번역하기 위해서는 그 문장에 대한 이해가 뒷받침되어야 하는 것처럼, 기계 역시 원 문장이 가진 의미를 제대로 인코딩해야 향상된 성능의 번역이 가능할 것이다. 본 논문에서는 뇌과학에서 뇌 동기화(Brain-to-brain coupling)라 일컫는 현상을 모방해, 출발어와 도착어의 공통된 의미를 인코딩하여 기계 번역 성능 향상에 도움을 줄 수 있는 이중 번역 기법을 소개한다.
주제어: 자연어처리, 기계번역, 딥러닝, 뇌동기화
1. 서론
오늘날 기계 번역 모델은 대부분 인코더-디코더 구조[1]에 기 반을 두고 있다. 인코더는 주로 임베딩 된 출발어 문장을 비교적 낮게 고정된 차원의 벡터로 압축하여 표현하고, 디코더는 반대 로 압축된 벡터를 도착어 문장으로 변환하는 역할을 한다. 이는 마치 인간의 뇌가 어떤 문장을 읽고 이해한 다음, 이해한 내용을 상응하는 의미의 타언어 문장으로 바꿔 나타내는 일련의 과정 과 아주 흡사하다. 이런 관점에서 보면 인코딩된 벡터는 문장을 이해함으로써 읽기 전과 달라진 뇌의 상태를 표현한다고 할 수 있을 것이다. 여기서 이런 의문이 생긴다. 언어가 달라도 의미 가 같은 문장이라면 그 뜻을 이해한 뇌의 상태가 크게 다르지 않을 테니, 두 문장의 인코더 표현 역시 서로 유사해야 하지 않을까?
뇌과학에서 뇌의 상태가 유사하게 유지되는 현상을 뇌 동 기화라 일컫는다[2]. 여러 사람에게 같은 이야기를 들려줄 때 사람들의 뇌가 비슷한 변화 양상을 보이는 것을 예로 들 수 있다. 더 흥미로운 사실은 의미가 같다면 언어의 종류와 문자, 소리, 수화 등의 전달 방식에 상관없이 뇌 동기화가 발생한다 는 점이다. 사실 이러한 현상은 응당 자연스러울 뿐 아니라 딥 러닝(Deep learning) 분야에서도 쉽게 관찰할 수 있다. 가령 NLG(Natural Language Generation) 기술로 어떤 이미지에 대한 한국어 설명과 영어 설명을 생성한다면, 두 설명은 의미 적 측면에서 당연히 상통해야 한다.
본 논문에서는 뇌 동기화 현상에서 착안한 뇌과학적 아이디 어를 인코더-디코더 모델에 적용하여 기계 번역 실험을 수행하
였다. 출발어 문장과 도착어 문장은 의미가 같으니 두 문장의 인코더 표현을 유사하게 만드는 방법으로, 서로 다른 언어로 같은 내용의 이야기를 들은 두 사람의 뇌가 동기화되는 현상을 모방했다. 이런 시도를 통하여 한 언어 내에서 문자가 담당하는 의미가 아닌, 여러 언어에 걸쳐 다른 형태의 문자로 나타나는 공통된 의미 그 자체가 인코딩되었다고 볼 수 있는 결과를 얻 었다. 더불어 상대적으로 향상된 기계 번역 성능 또한 얻을 수 있었기에, 본 논문을 통해 뇌 동기화 모방 기법을 소개하고자 한다.
2. 관련 연구
[2]에서 영어 이야기와 러시아어로 번역된 이야기를 각 언어 를 사용하는 두 집단에 들려준 다음 전두엽의 반응을 비교하였 다. 두 언어의 소리가 매우 다르기 때문에 청각 피질 상에는 두 집단 간 유사점이 발견되지 않았지만, 의미를 해석하는 전두엽 등의 고차원적인 부분에서는 비슷한 반응이 나타났다. 본 논문 에서는 다음 관련 연구들을 바탕으로 이러한 뇌 동기화 현상을 모방하는 실험을 진행하였다.
2.1 인코더-디코더 구조
딥 러닝 분야 전반에서 [3]처럼 모델이 점점 커지고 복잡해 지는 경향을 보인다. 최신 성능을 달성하려면 거대한 모델로 최대한 많은 데이터를 학습해야 하고, 새로운 기법을 적극 적 용하여 모델을 점점 더 복잡하게 만들 필요가 있기 때문이다.
크고 복잡한 모델은 실사용 측면에서는 장점이 될 수 있으나 새로운 기법을 시험할 때는 부적합한 면이 있다. 실험 결과가
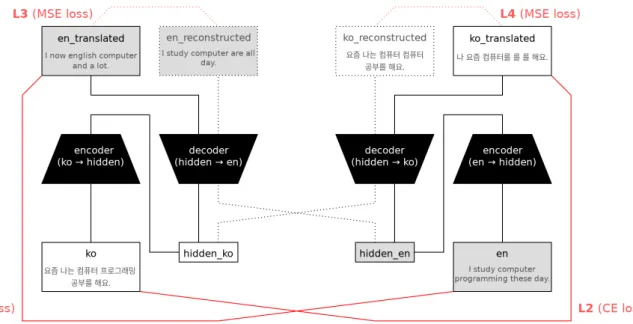
그림 1. 두 개의 서브모델이 서로 반대 방향으로 이중 번역을 하는 구조. 점선으로 표시된 부분에 의해 두 히든 스테이트가 유사해지며 뇌 동기화 현상을 모방한다.
그기법에 일차적 영향을 받았는지 아니면 어떤 다른 요인이 개 입해 이차적으로 발현되었는지 알기 어려워, 모델을 절제 연구 (Ablation study) 해야 되기 때문이다.
본 논문의 목표는 뇌 동기화 모방 기법의 검증에 있으므로 실험에는 [1]의 모델을 사용하였다. 초기 모델인 만큼 비록 최 신 성능에는 미치지 못하지만 현 인공신경망(Artificial neural network) 기계 번역 모델 대부분의 뼈대가 되었다고 해도 과언 이 아닌 기본 모델로, 인코더-디코더 구조의 간단하고 직관적 인 형태를 갖추고 있다. 가변 길이의 출발어 문장을 고정된 차 원의 벡터로 인코딩한 다음, 조건부 로그-가능도(Conditional log-likelihood)가 최대가 되게 하는 다음 토큰을 반복적으로 예측하여 가변 길이의 도착어 문장으로 디코딩 하는 방식으로 작동한다.
2.2 재구성 오류 (Reconstruction Error)
기계 번역에서 재구성 오류는 인코딩된 벡터를 도착어로 번 역하지 않고 출발어로 복원하였을 때 인코딩되기 전 출발어와 의 차이를 뜻하며, 인코딩된 벡터에 원 문장의 정보를 저장하기 위한 목적으로 사용된다. 최신 기계 번역 연구에서도 어렵지 않 게 사용 사례를 찾을 수 있다[4, 5]. 뇌 동기화 모방 기법에도 원 문장을 복원하는 재구성 절차가 있다.
2.3 전이 학습 (Transfer Learning)
전이 학습은 일반적 표현(Universal representation)을 선행 학습(Pre-training) 하는 방식을 말한다[6]. 특히 특정 과제의 학습 데이터가 부족할 경우 쉽게 구할 수 있는 대용량 데이 터를 활용해 좀 더 보편적인 목적 함수(Objective function)로
사전 학습을 하게 되는데, 이는 기술적인 관점에서 목적 함수 의 표면을 최대한 넓게 탐색해보고 가능한 깊은 극소점(Local minimum)을 갖는 구간에서 학습을 시작하기 위한 것으로 본 다. [3]의 BERT(Bidirectional Encoder Representations from Transformers)는 자연어 처리 분야의 대표적인 전이 학습 사 례로, 여러 세부 과제에 통용될 수 있는 선행 학습된 인코더 표현을 제공한다.
기계 번역 분야에서도 데이터의 병렬성을 이용한 이중 번 역(Dual translation)으로 전이 학습을 하는 방법이 제안되었 다[7]. [5]는 영어에서 독일어로 번역하는 모델과 반대 방향으로 번역하는 두 모델의 히든 스테이트(Hidden state)를 서로 바꿔 디코딩 한 후 대응하는 정답 문장에 대한 재구성 오류를 함께 학습하여 번역 성능을 높였다. 뇌 동기화 모방 기법 또한 이중 번역과 히든 스테이트를 교차하는 접근법을 사용하지만, 복원 의 용이성이 아니라 출발어와 도착어 문장의 공통성에 초점을 맞추는 차별점이 있다.
3. 방법
그림 1은 뇌 동기화 현상을 모방하기 위해 설계한 모델의 전체적인 구조이다. 왼쪽에는 한국어를 영어로 번역하는 인코 더-디코더(한영 서브모델)가 있고, 오른쪽에는 영어를 한국어 로 번역하는 인코더-디코더(영한 서브모델)가 있다. 번역의 출 발어와 도착어가 반대인 서브모델 두 개가 이중 번역을 하는 형태이며, 점선으로 표시된 부분에 의해 간접적으로 연결되어 있다. 네 개의 손실 함수(Loss function)는 붉게 표시하였다.
3.1 이중 번역
두 서브모델이 각자 번역을 학습할 때는 소프트맥스 함수 (Softmax function)와 음의(Negative) 로그-가능도를 결합한 교차 엔트로피(Cross entropy)[8] 손실 함수를 번역 방향에 따 라 다음과 같이 사용한다.
L1= −
m
X
i=1
log exp (eni) P
e∈Ven,iexp (e)
!
(1)
L2= −
n
X
i=1
log exp (koi) P
k∈Vko,iexp (k)
!
(2)
m과 n은 각각 영어 문장(en)과 한국어 문장(ko)의 길이를 나 타낸다. eni와 koi는 영어와 한국어 문장의 i번째 토큰에 대한 각 서브모델의 출력값을 가리키며, V 는 각 언어의 토큰 집합 (Vocabulary) 전체에 대한 출력값의 분포를 의미한다. 다른 손 실 함수 없이 이 두 개만 사용할 경우, 한영 서브모델과 영한 서브모델이 서로 독립적으로 학습된다.
두 히든 스테이트(그림 1의 hidden ko, hidden en)를 서로 바꿔 디코딩 하면 번역 대신 복원이 되는데(ko reconstructed, en reconstructed), 이를 출발어 문장(ko, en)과 비교하면 재 구성 오류를 구할 수 있다. 여기에 이전 토큰과 현재 토큰의 유사도가 낮을수록 중요성을 강조하는 정규화까지 추가하면 [5]에서 제안하는 손실 함수가 된다.
3.2 뇌 동기화 모방 기법
[2]에서 설명하는 바에 의하면 같은 이야기를 한국어로 한국 어 사용자에게 들려주고 영어로 영어 사용자에게 들려주었을 때 두 사람의 뇌 상태는 비슷해져야 한다. 본 논문에서는 문장 이 인코딩된 벡터를 문장을 읽고 이해한 뇌의 상태로 보므로 두 서브모델의 히든 스테이트를 서로 유사하게 만들어 뇌 동기화 현상을 모방한다. 뇌 동기화 모방 기법은 아래 두 MSE(Mean Squared Error) 손실 함수를 추가로 사용하게 된다.
L3= 1 m
m
X
i=1
(entranslated,i− enreconstructed,i)2 (3)
L4= 1 n
n
X
i=1
(kotranslated,i− koreconstructed,i)2 (4)
이와 같이 히든 스테이트(hidden ko, hidden en)를 교차 하여 디코딩 한 문장(ko reconstructed, en reconstructed) 과 교차하지 않고 그대로 디코딩 한 결과(ko translated, en translated) 사이의 손실을 줄이면 궁극적으로 두 히든 스 테이트 간 차이를 줄일 수 있다. 디코더는 LSTM(Long Short- Term Memory) 등의 복잡한 비선형 함수이므로, 하나의 디코 더를 서로 다른 두 입력에 대해 유사한 결괏값을 계산하도록
회귀(Regression) 시키기보다 차라리 입력값인 두 히든 스테 이트를 유사하게 만드는 쪽으로 역전파(Backpropagation) 될 것이기 때문이다[9].
3.3 단반향 번역
테스트 혹은 서비스 등의 실제 상황에서는 정답 도착어 문장 이 없는 상태에서 번역이 이루어진다. 다시 말해 역방향 번역 모델로부터 도착어 문장이 인코딩된 벡터를 자질(Feature)로 전달받을 수가 없다. 하지만 그림 1에서 점선으로 된 부분을 제거하여 간접적으로 연결된 두 서브모델을 완전한 두 개의 모델로 분리하면, 각 모델은 독립적으로 단방향 번역을 할 수 있게 된다.
4. 실험
AI 오픈 이노베이션 허브에서 제공하는 한국어-영어 번역 병렬 말뭉치 AI 데이터1 중 구어체 한영 번역 문장을 이용해 실험을 진행하였다. 총 75,000개의 문장 쌍을 52,500개, 7,500 개, 15,000개로 나누어 학습, 검증, 테스트 데이터로 사용했다.
한국어 문장의 평균 토큰 수는 11.17개, 영어 문장의 평균 토큰 수는 10.49개로 거의 비슷하나, 한국어 데이터의 고유한 토큰 수는 30,213개로 영어 데이터의 19,366개와 다소 큰 차이가 있 었다. 한국어 동사의 어미변화가 주된 원인이나, 영어 문장을 토큰으로 바꿀 때 동사를 원형으로 복원하지 않았으므로 한국 어 문장도 과도하게 토큰화하지는 않았다. 인코더와 디코더는 LSTM으로 구성하였고, 보고자 하는 차이점이 명확히 드러나 도록 부수적인 기법과 변수의 사용은 최대한 자제하였다.
4.1 PPL (Perplexity)
그림 2. 학습 진행에 따른 검증 PPL
그림 2는 네 모델의 성능 변화 과정을 한눈에 비교하기 위
1http://aihub.or.kr/content/605
해 한영과 영한 이중 번역 결과를 함께 고려했을 때의 PPL을 학습 진행 시간(Epoch)에 따라 나타낸 그래프이다. 총 네 가 지 모델을 대상으로 성능을 비교하였으며, 두 서브모델이 서로 독립적으로 학습한 경우를 베이스라인(Baseline)으로 삼았다.
[5]의 변형 모델 중 L1과 L2에 재구성 오류까지만 더한 NAT- RR(NAT-BASE + reconstruction regularization) 모델과 제 안하는 뇌 동기화 모방 기법을 적용한 모델, 마지막으로 두 방 법을 결합한 모델의 검증 PPL을 측정하였다.
베이스라인보다 재구성 오류를 사용해 학습한 NAT-RR 모 델에서 살짝 우세한 변화 양상이 나타났다. 뇌 동기화 모방 기법 을 적용한 경우 눈에 띄는 성능 향상과 안정적인 변화 추이를 보였고, 큰 차이는 없지만 둘을 함께 사용할 때 학습 과정이 제일 안정적이고 검증 성능 또한 가장 우수했다.
두 개의 서브모델이 연결된 형태의 세 모델 모두 베이스라 인보다 초반 PPL 감소 속도가 조금 느렸지만, 학습 과정에서 결국 더 낮은 PPL을 달성하였다. 특히 과적합(Overfitting)이 상대적으로 천천히 진행되는 점이 인상적이다. 반복적인 대조 실험에서 이 같은 추이가 지속 관측되었고, 한영 서브모델과 영한 서브모델의 PPL을 각각 따로 비교해도 변화 양상은 항 상 비슷하게 나타났다. 이러한 현상의 원인은 이중 번역으로 전이 학습 함으로써 간접적인 데이터 증가 효과가 발생했기 때문이다. 번역의 방향이 서로 반대인 두 개의 서브모델을 동 시에 학습하며 서로의 문장을 인코딩하여 공유하기 때문에, 직 접적이지는 않지만 더 학습할 수 있는 유의미한 정보가 늘어난 것이다. 특히 재구성 오류를 사용했을 때보다 뇌 동기화 모방 기법을 적용했을 때가 과적합 지연에 더 효과적이므로 본 논문 에서 제안하는 기법의 전이 학습 효과가 상대적으로 크다고 볼 수 있다.
표 1. 네 모델의 테스트 PPL
모델 한영 PPL 영한 PPL 이중 PPL (단위: 십) (단위: 십) (단위: 천) Baseline 4.53 ± 0.10 4.91 ± 0.08 2.22 ± 0.06 NAT-RR 4.50 ± 0.08 4.94 ± 0.09 2.22 ± 0.07 Ours 4.31 ± 0.11 4.56 ± 0.09 1.97 ± 0.04 Ours + NAT-RR 4.19 ± 0.06 4.36 ± 0.05 1.83 ± 0.03
표 1에서는 네 모델을 독립적으로 10번씩 학습한 후 테스트 성능을 대조하였다. 두 개의 서브모델을 동시에 학습하므로 각 학습 시도에서 한영 번역 PPL, 영한 번역 PPL, 그리고 둘을 함께 고려한 이중 번역 PPL, 총 세 종류의 테스트 PPL을 사 용하였다.
재구성 오류를 사용한 NAT-RR 모델은 영한 번역 성능이 오
히려 떨어지는 등 베이스라인에 비해 큰 개선이 없었다. 하지만 그림 2에서는 전체적인 학습 과정을 안정시키는 모습을 보이기 때문에 보조적인 학습 수단으로서의 기능은 유효하다고 볼 수 있다. 뇌 동기화 모방 기법에 재구성 오류를 함께 사용했을 때 가 제안하는 기법만 사용했을 때보다 성능이 높고 검증 PPL이 변화하는 과정도 더 안정적이므로 이 같은 추측은 타당하다.
뇌 동기화 모방 기법을 적용한 경우는 확실한 성능 향상을 보였다. 베이스라인뿐만 아니라 NAT-RR 모델에 적용했을 때 에도 성능이 큰 폭으로 증가하였다. 두 서브모델을 따로 비교 해도 마찬가지 결과를 얻을 수 있다. 대조 실험의 이와 같은 결과는 뇌 동기화 모방 기법이 기계 번역 모델의 성능 향상을 위해 응용될 수 있는 가능성을 보여준다. 이미 재구성 오류가 사용된 모델에도 추가로 적용하여 성능을 높였기 때문이다.
4.2 유클리드 거리 (Euclidean Distance)
관측된 성능 향상이 정말 뇌 동기화 현상을 모방한 것에서 비롯된 결과인지 아니면 다른 요인에 의한 우연인지 확인할 필요가 있겠다. 한영 서브모델과 영한 서브모델의 두 히든 스 테이트 사이의 거리와 유사도를 분석하면 동기화 흔적을 엿볼 수 있다. 먼저 유클리드 거리는 실험에 사용한 네 모델 모두 최 초의 거리보다는 상당히 감소한다. 학습이 진행되며 깊은 계산 과정에서 값이 지나치게 증폭되지 않도록 모델이 안정화되는 데, 이에 따라 히든 스테이트의 각 성분도 안전한 범위 내에서 계산될 수 있게 절댓값이 작아지기 때문이다.
그림 3. 두 서브모델의 히든 스테이트 간 거리
그림 3은 상호 간 유클리드 거리의 변화 추이를 나타낸 그래 프이다. 모델이 안정화되는 과정은 중, 후반부의 변화 양상으 로서 네 모델 모두에서 관측이 되지만, 뇌 동기화 모방 기법을 사용한 경우(실선으로 표시)는 사용하지 않은 경우(점선으로 표시)와 최종 거리에서 눈에 띄는 차이가 존재한다. 제안하는 기법을 사용한 경우 두 서브모델의 히든 스테이트 사이의 최종
거리가 훨씬 가까워지므로 안정화 외에 동기화 현상도 분명히 발생했다고 할 수 있다. 재구성 오류를 사용한 경우(검은 실선 과 점선)는 오히려 최초 거리와 최종 거리에 큰 차이가 없었고, 초반부에 거리가 증가하는 구간이 길어지는 특징도 발견되었 다. 따라서 재구성 오류가 뇌 동기화 현상을 촉진하는 일차적인 원인은 될 수 없는 것으로 추측된다.
4.3 코사인 유사도 (Cosine Similarity)
코사인 유사도를 대조한 결과는 더욱 흥미롭다. 그림 4를 보 면 우선 두 서브모델이 독립적인 베이스라인에서는 서브모델 간 히든 스테이트의 유사도가 평균적으로 0에 가깝게 나타난다.
이는 어느 벡터에 쌍으로 대응되는 벡터가 직교(Orthogonal) 평면을 중심으로 정규 분포(Normal distribution) 혹은 연속 균등 분포(Continuous uniform distribution) 할 때 가능한 수 치이다. 두 서브모델이 서로 독립적으로 학습하는 상황에서는 서로의 히든 스테이트 분포에 영향을 미치지 못하므로 별도의 기준점이 없는 연속 균등 분포일 것으로 짐작할 수 있는데, 이 는 곧 어느 한 히든 스테이트에 상응하는 다른 히든 스테이트의 분포가 완전히 불규칙하다는 의미이다. 비록 다른 언어로 쓰인 문장이지만 같은 의미로 대응되는 문장인데, 문장의 의미를 담 고 있어야 할 인코딩된 벡터는 서로 아무런 유사성이 없다니 의외일 따름이다.
그림 4. 두 서브모델의 히든 스테이트 간 유사도
반면, 두 서브모델이 연결된 다른 세 모델에서는 베이스라인 에서는 전혀 보이지 않던 상호 간 유사성이 분명히 발생하였다.
한영 서브모델이 한국어 문장을 읽고, 영한 서브모델은 같은 의 미의 영어 문장을 읽었을 때, 이해를 마친 뇌의 상태로 가정한 히든 스테이트가 서로 비슷해진 것이다.
NAT-RR 모델에서도 유사도가 조금 생기는 이유는 재구성 오류 역시 간접적으로 히든 스테이트를 같게 하는 효과가 있 기 때문이다. 번역한 문장과 복원한 문장 둘을 동일한 도착어
문장과 비슷하게 만들므로, 앞에서 설명한 바와 같이 디코더의 입력값인 두 히든 스테이트가 어느 정도 유사해질 수 있다[9].
하지만 뇌 동기화 모방 기법은 번역한 문장과 복원한 문장을 정답이 아닌 서로에 대해 손실을 계산하기 때문에 더 직접적 인 동기화가 가능하다. 특히 학습 초기에는 디코더의 결괏값이 굉장히 부정확하고 불규칙하기 때문에, 번역한 문장과 복원한 문장이 전혀 비슷하지 않고 정답 문장과도 많은 차이가 있다.
그런불완전한 두 결과를 정답에 가깝게 하는 대신, 뇌 동기화 현상을 모방하기 위해 서로 유사해지도록 하는 것이다.
4.4 결과 분석
재구성 오류를 사용하는 경우 초반에 유클리드 거리가 증 가하거나(그림 3의 검은 실선과 점선) 코사인 유사도가 급격히 떨어지는(그림 4의 검은 실선과 점선) 현상도 위와 같이 설명할 수 있다. 초기 불안정한 디코더가 동기화에 대한 고려 없이 번역 만 성급하게 학습하는 것이다. 뇌 동기화 모방 기법을 사용하면 초반 동기화 양상(그림 3, 4의 붉은 실선)이 비교적 안정적인 것에서 미루어 짐작할 수 있다. 재구성 오류가 간접적으로 두 히든 스테이트를 유사하게 만들어도 주 목적이 출발어 문장에 대한 정보 보관인만큼, 뇌 동기화 현상과의 관련은 적은 것으로 봐야 한다. 뇌 동기화 모방 기법보다 동기화 정도가 떨어지는 점, 함께 사용했을 때도 제안하는 기법만 적용했을 때와 동기화 정도가 유사한 점 등을 근거로 들 수 있다.
반대로 뇌 동기화 기법만 사용한 경우 초반에 유사도가 증가 하다가 다시 감소한 상태에서 유지되는 모습을 보인다. 이 역시 같은 맥락에서 설명이 가능하다. 아직 불완전한 상태의 초기 서 브모델이 동기화의 영향을 먼저 받고 번역을 학습하면서 차츰 안정된 상태가 되는 것이다. 코사인 유사도에 대한 분석은 학습 과정이 진행될수록 동기화 현상이 더뎌지므로 두 서브모델이 스펀지 같은 초기 상태일 때부터 동기화해야 할 필요성 역시 말해주고 있다.
번역 성능이 높아짐에 따라 동기화 정도도 계속해서 높아지 지 않은 점은 일견 아쉬운 부분이다. 하지만 실제 뇌 동기화 현상도 뇌의 상태가 100% 완벽히 일치하는 것은 아니고 각 언어에는 문자 만으로는 표현될수 없는 뉘앙스가 존재하므로 40%에 가까운 유사도에는 분명 의미가 있다.
이상 뇌 동기화 현상을 모방한 실험을 통해 서로 반대 방향으 로 번역하는 두 서브모델의 히든 스테이트가 유사해지고 이로 인해 번역 성능이 향상되는 것을 볼 수 있었다. 이러한 결과는 표면적으로 서로 다른 문자 표현에 담긴 공통된 의미가 인코 딩되었음은 물론, 문자 너머의 의미 그 자체를 담아 더 좋은 인코더 표현을 찾을 수 있는 가능성을 시사한다.
5. 결론
본 논문에서는 뇌 동기화라는 뇌과학적 현상에서 얻은 아이 디어를 기계 번역 모델에 적용하기 위해 뇌 동기화 모방 기법을 고안하였다. 이 기법으로 대조 실험에서 번역 모델의 성능 향상 과 더불어 서로 독립적인 두 번역 모델 사이에서 동기화 현상이 나타나는 것을 관찰할 수 있었다. 사후 해석에 의존하는 한계 가 있지만 분명한 사실은 독립적인 두 번역 모델 사이에서 뇌 동기화와 유사한 현상과 성능 향상이 동시에 나타났다는 것이 다. 이는 서로 다른 언어로 쓰인 문장에 대해 각각 독립적으로 인코딩하는 것보다 의미적 유사성을 고려하여 더 좋은 인코더 표현을 찾을 수 있음을 보여준다.
그러나 뇌 동기화 모방 기법이 진정으로 의미가 있으려 면 궁극적으로 새로운 최신 성능을 달성하는데 보탬이 되어 야 할 것이다. 따라서 향후 연구에서는 양방향(Bidirectional) LSTM[10]이나 트랜스포머[11] 등 우수한 성능을 보이는 다른 인코더-디코더로 구성된 번역 모델에 적용할 수 있도록 기법을 확장할 필요가 있다. 또한, 본 연구에서 제안하는 기법을 재구성 오류와 결합하여 사용할 수 있는 것을 확인하였으므로 다양한 기법이 한데 어우러진 최신 모델에 추가 적용하여 번역 성능 향 상을 시도하는 실사용 측면의 연구도 마땅히 함께 진행되어야 하겠다.
참고문헌
[1] K. Cho, B. Van Merri¨enboer, C. Gulcehre, D. Bah- danau, F. Bougares, H. Schwenk, and Y. Bengio,
“Learning phrase representations using rnn encoder- decoder for statistical machine translation,” arXiv preprint arXiv:1406.1078, 2014.
[2] U. Hasson, A. A. Ghazanfar, B. Galantucci, S. Garrod, and C. Keysers, “Brain-to-brain coupling: a mechanism for creating and sharing a social world,” Trends in cog- nitive sciences, Vol. 16, No. 2, pp. 114–121, 2012.
[3] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova,
“Bert: Pre-training of deep bidirectional transform- ers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
[4] X. Niu, W. Xu, and M. Carpuat, “Bi-directional dif- ferentiable input reconstruction for low-resource neural machine translation,” arXiv preprint arXiv:1811.01116, 2018.
[5] Y. Wang, F. Tian, D. He, T. Qin, C. Zhai, and T.-Y. Liu,
“Non-autoregressive machine translation with auxiliary regularization,” AAAI Vol. 91, pp. 584-589, 2019.
[6] L. Y. Pratt, J. Mostow, C. A. Kamm, and A. A. Kamm,
“Direct transfer of learned information among neural networks.” AAAI, Vol. 91, pp. 584–589, 1991.
[7] D. He, Y. Xia, T. Qin, L. Wang, N. Yu, T.-Y. Liu, and W.-Y. Ma, “Dual learning for machine translation,” Ad- vances in Neural Information Processing Systems, pp.
820–828, 2016.
[8] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “Automatic differentiation in pytorch,” 2017.
[9] D. E. Rumelhart, G. E. Hinton, R. J. Williams et al.,
“Learning representations by back-propagating errors,”
Cognitive modeling, Vol. 5, No. 3, p. 1, 1988.
[10] A. Graves and J. Schmidhuber, “Framewise phoneme classification with bidirectional lstm and other neural network architectures,” Neural networks, Vol. 18, No.
5-6, pp. 602–610, 2005.
[11] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin,
“Attention is all you need,” Advances in neural infor- mation processing systems, pp. 5998–6008, 2017.