A development of bivariate regional drought frequency analysis model using copula function
15
0
0
전체 글
(2) 986. J.-G. Kim et al. / Journal of Korea Water Resources Association 52(12) 985-999. 1. 서 론. 된 동질 지역을 바탕으로 확률강우량을 산정하여 국내 적용성 을 검토하였다. Kwon et al. (2013)은 기존 지역빈도해석 방법에. 가뭄은 강우량이 부족한 현상이 장기간에 걸쳐 발생하는. 계층적 Bayesian 기법을 적용하여 해석결과에 대한 불확실성을. 기상재해를 말하며, 이러한 가뭄현상은 전 세계적으로 다양한. 정량적으로 분석하였으며, Kim et al. (2014)는 지역특성(위도,. 요인에 의해 발생되고 있다. 국지성 호우에 의해 발생되는 돌. 경도, 고도)과 기후학적 특성을 계층적 Bayesian 모형 안에서. 발홍수와 같이 단기간에 발생하는 자연재해와 달리 가뭄은 특. 연계하여 극치수문변량의 공간적 해석 및 불확실성 분석이 가. 정 지역에 국한되지 않고 수개월에 걸쳐 진행되며, 지속된 시. 능한 지역빈도해석 기법을 제시하였다.. 간에 비례하여 피해가 증가함에 따라 정상적인 강우패턴으로. 앞서 언급하였듯이 특정 극치사상 자료에 대한 특성을 분. 회복된 뒤에도 장기간에 걸쳐 가뭄의 영향이 지속된다(Park. 석 시, 일반적으로 단변량 중심의 지점빈도해석이 수행된다.. and Lee, 2018). 특히 2013~2015년 우리나라에는 예측하지. 그러나 두 가지 이상의 변량이 서로 상관성을 가지는 경우 다변. 못한 유례없는 가뭄이 발생한 바 있으며, 이와 같은 기존 기상. 량(multivariate) 지점빈도해석 이 요구되며, 이를 단변량으. 패턴과 다른 극한가뭄에 대한 심각성이 대두되고 있다(Kim. 로 해석하는 경우 재현기간의 과소추정 등의 문제점이 발생할. et al., 2017). 이처럼 최근 발생빈도가 커지고 있는 가뭄에 대. 수 있다. 최근 이러한 점을 개선하기 위하여 다변량 빈도해석. 해 용수공급 관리측면에서 효율적인 대응 및 대안 수립을 위. 에 관한 연구가 지속적으로 진행되고 있다(Kwon and Lall,. 해서는 가뭄을 정량적으로 평가하는 연구가 선행되어야 하며. 2016; Vaziri et al., 2018). 특히, 가뭄의 경우, 강도(intensity). (Lee and Son, 2016), 국내외에서는 가뭄의 특성을 위험도 관. 뿐만 아니라 지속기간(duration), 심도(severity)도 매우 중요. 점에서 평가하기 위한 방안으로 가뭄빈도해석이 수행되고 있. 한 인자로 고려되고 있다. 특히, 가뭄 지속기간과 심도의 경우. 다(Kim et al., 2017). 이밖에 국내외 연구를 살펴보면 선제적. 두 인자간의 상관성이 매우 크기 때문에 단변량 가뭄빈도해석. 인 가뭄에 대비하기 위해 위성자료 및 빅데이터 등을 활용한. 보다 다변량으로 가뭄빈도해석을 수행하는 것이 가뭄위험도. 가뭄 예측인자 발견에 대한 다양한 연구가 진행되고 있지만,. 평가측면에서 유리하다고 알려져 있다(Shiau and Shen, 2001;. 가뭄의 자연현상을 물리적으로 설명하기에는 한계가 존재하. Kim et al., 2017).. 며, 가뭄 전이과정 또한 명확한 규명이 어려운 실정이다.. Skalr (1959)가 제시한 Copula 함수는 자유로운 주변확률. 수문자료에 대한 빈도해석은 일반적으로 단일 확률변수를. 분포(marginal probability distribution) 선택과 결합확률분. 기준으로 이루어지는 단변량(univariate) 해석 방법이 활용되. 포(joint probability distribution)의 추정이 용이하다는 장점. 며, 신뢰성 있는 빈도해석 결과를 도출하기 위해서는 많은 자. 이 있어 최근 10년 동안 활용성이 크게 증대되고 있으며, 여러. 료의 수를 확보하는 것이 필수적이다. 빈도해석을 통해 도출. 분야에 다양한 목적으로 적용되고 있다. 수문학 분야에서도. 되는 재현기간은 특정 강도의 수문학적 극치사상이 발생하는. 다변량의 극치 값을 다루기 위해 Copula 함수를 기반으로 수. 평균적인 발생 주기로서 수자원 계획측면에서 가장 기본적인. 행된 연구가 다수 진행된바 있다(Fernández and Salas, 1999;. 설계인자로 활용된다(Kwak et al., 2012). 그러나 수문학 분야. Bonaccorso et al., 2003; Canclliere and Salas, 2010; Kwon. 에서 자료의 해석 시 사용되는 자료들의 대부분은 관측연수가. and Lall, 2016; Kim et al., 2017). 이처럼 Copula 함수를 활용. 짧으며, 미계측 유역의 경우 해당 유역에 대한 측정자료가 존재. 한 다수의 이변량 빈도해석에 대한 연구가 진행되었지만, 대. 하지 않는 등 제한적인 자료로 인한 표본오차로 인해 지점빈도. 부분의 연구는 지점빈도해석에 국한되었으며, 유사한 통계. 해석(point frequency analysis)시 통계적으로 신뢰성이 결여. 적 특성을 가지는 지역 내 관측소의 수문특성을 단순히 자료. 되는 단점이 있다(Kwon et al., 2013). 이러한 문제점들을 해결. 를 Pooling 하는 것에서 벗어나 확률분포특성을 체계적으로. 하기 위한 대안으로 지역빈도해석(regional frequency analysis). 고려한 연구는 미진한 실정이다.. 방법이 제안되었으며, 다수의 연구에 의해 지역빈도해석의 효. 이러한 점에서 본 연구에서는 이변량 빈도해석 시 널리 활용. 율성이 확인되었다(Potter, 1987; Hosking and Wallis, 2005; Oh. 되고 있는 Archimedean Copula 함수를 활용하였으며, 확률. et al., 2006; Lee and Kwon, 2011). 국내에서도 지역빈도해석에. 분포 매개변수의 불확실성을 정량화하기 위하여 Bayesian 기. 대한 연구가 다양하게 진행되었다. Oh et al. (2008)은 우리나라. 법과 연계한 Bayesian Copula 기반 이변량 가뭄 지역빈도해. 강우관측소를 6개 지역으로 구분하여 지역빈도해석 방법을 통. 석 모형을 제안하고자 한다. 본 연구에서는 주변확률분포와. 해 확률강우량을 산정하여 비교하였으며, Nam et al. (2008)은. Copula 함수의 매개변수를 동시에 추정하기 위하여 주변확률. Procrustes analysis를 통해 최소 변수를 선정하고, 요인분석. 분포와 주요 Archimedean Copula 함수의 우도함수(likelihood. (factor analysis)과 군집해석(cluster analysis)을 적용하여 구분. function)를 연계하였으며, 기존의 지역빈도해석 방법과는 다르게.
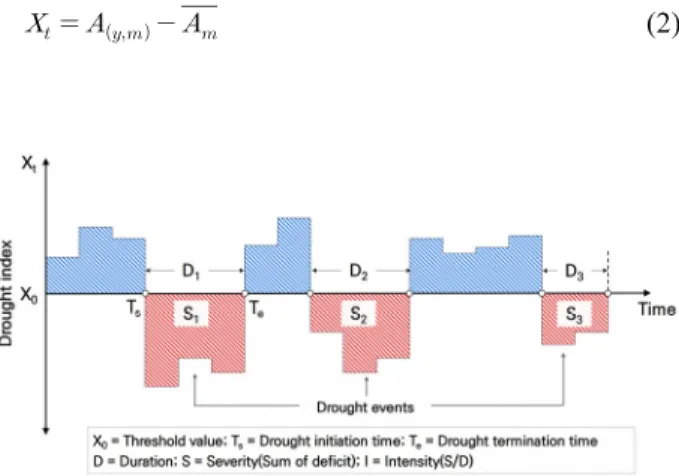
(3) J.-G. Kim et al. / Journal of Korea Water Resources Association 52(12) 985-999. 987. 각 지점에 확률분포를 추정하되 상위단계에서 각 지점의 매개변수. 해석 연구가 활발히 진행되고 있다(Hong and Lee, 2011; Kim. 들이 서로 연계가 가능하도록 계층적(hierarchical)으로모형을구성. et al., 2017). 이에 본 연구에서는 기상청 관측자료를 활용하여. 하여 매개변수의 사후분포(posterior distribution)를 추정하였다.. 산정된 Anomaly를 통해 가뭄사상을 구분하였으며, 산정된. 본 연구는 Kim et al. (2017)이 제시한 이변량 Bayesian Copula. Anomaly의 시계열이 0이하로 떨어졌을 때, 가뭄의 시작부터. 지점빈도해석 모형을 지역빈도 개념으로 확장하는데 목적이. 종료까지 기간을 의미하는 가뭄 지속기간, 떨어진 양의 총합을. 있다. 이에 선행 연구와 동일한 자료를 활용하여 모형을 검증. 강우부족량을 의미하는 가뭄 심도로 정의하였으며, 가뭄 지역. 하였으며, 2013-2015년도에 한강유역에서 발생한 가뭄에 대. 빈도해석을 위한 주요 변량으로 활용하였다.. 한 이변량 지역빈도해석을 수행하여 동일 지역의 지점빈도해. 앞서 언급하였듯이, 본 연구에서는 기상학적 측면의 가뭄. 석 결과와 비교함으로써 본 연구에서 활용한 방법의 국내 적. 해석을 수행하고자 한강유역에 위치한 기상청 강우관측소. 용특성을 검토하였다.. 중 유사한 통계적 특성을 나타내는 관측소를 선별하였다. 가. 본 논문의 구성은 다음과 같다. 1장에서는 본 연구 내용의 전. 뭄빈도해석시 결과에 대한 신뢰성을 확보하기 위해서는 장. 반적인 내용에 대해 서술하였으며, 2장에서는 가뭄의 정의 및. 기간의 강우량 자료가 요구된다. 확률분포를 활용한 수문자. Coupla 함수, 간략한 Bayesian 기법과 개발된 이변량 가뭄 지역. 료의 통계적 분석시, 강우량 자료는 최소 30년 이상이 필요하. 빈도해석 모형에 대해 설명하였다. 3장에서는 개발된 Bayesian. 지만, 50년 이상의 강우량 자료를 사용할 것을 권장하고 있다. Copula 기반 이변량 가뭄 지역빈도해석의 실제 가뭄사상에. (Guttman,1999). 본 연구에서는 1974년부터 2015년 사이에. 대한 적용 결과를 제시하였으며, 4장에서는 결론 및 향후 연구. 관측된 강우량 자료를 이용하여 연속이론에 따른 가뭄 특성인. 방향에 대해 서술하였다.. 자를 추출하였다. 가뭄 특성인자 추출을 위하여 기상청 강우 관측소의 정상년 강우량을 기준으로 월강우량 자료를 6개월 마다 누적하였으며, 가뭄의 절단수준을 결정하기 위하여 Eq.. 2. 연구방법 지점 및 지역빈도해석은 국내외에서 많은 연구들이 수행 되었기에 본 절에서는 가뭄의 정의 및 Copula 함수, Bayesian. (1)을 통해 강우의 Anomaly를 산정하였다.. . ⋯ . (1). 방법에 대한 핵심적인 부분만 간략히 기술하였으며, 본 연구 에서 개발한 Bayesian Copula 기반 이변량 가뭄 지역빈도해석. 여기서 각각 y, m은 Anomaly의 연도, 월을 나타내며, n은 월강. 모형에 대해 상세히 수록하였다.. 우량의 누적 개월 수, R(y, m)은 6개월 누적 강우량, A(y, m)은 해당 년 월의 Anomaly를 의미한다. 최종적으로 Eq. (2)를 통해 가뭄. 2.1 가뭄의 정의 가뭄이란 어느 지역에서 일정 기간 이상 평균 이하의 강우. 은 자료기간에 대한 m월의 을 구분하였으며, 여기서 . Anomaly 평균을, Xt는 가뭄상태를 의미한다.. 로 인해 강우량 부족이 장기화 되는 현상으로, 판단 기준에 의 해 기상학적(meteorological), 농업적(agricultural), 수문학 적(hydrological), 사회경제적(socioeconomic) 가뭄으로 분. . (2). 류하여 정의된다. 본 연구에서는 일정기간 평균 강우량보다 적은 강우로 인해 건조한 날이 지속되는 기상학적 가뭄에 대 한 지역빈도해석을 수행하였으며, Yevjevich (1967)에 의해 제안된 연속이론(run theory)을 통해 대상유역에 대한 가뭄을 정의하였다. 연속이론에 대한 기본적인 정의는 Fig. 1과 같다. Fig. 1에 도시된 개념과 같이, 연속이론은 수문변수 Xt가 정의 된 특정 값(threshold value) X0이하로 떨어졌을 때, 이를 사건이 일어난 사상(event)으로 정의한다. 최근 국내외에서는 가뭄빈 도해석과 관련된 연구를 수행하는데 있어, 가뭄의 복합적 특성 을 고려하기 위해 지속시간과 심도를 활용한 이변량 가뭄빈도. Fig. 1. Drought characteristics identified from the run theory (Yevjevich, 1967)..
(4) 988. J.-G. Kim et al. / Journal of Korea Water Resources Association 52(12) 985-999. 2.2 Copula 함수. 여기서, L은 가뭄 사상 간의 간격(inter-arrival time), E(L)은. Copula 함수는 Sklar (1959)에 의해 처음 제시되었으며, 두. 평균가뭄발생 간격이며, FD(d), FS(s)는 가뭄의 지속기간 및 심. 개 이상의 확률변수들 사이의 복합한 의존성을 파악하는데. 도에 대한 누가분포함수(cumulative distribution function,. 있어 용이한 기법이라 알려져 있다. 1990년대 후반을 기점으로. CDF)이다. 이는 Shiau (2006)에 의해 정의된 지속기간과 가. 다양한 이론 및 방법론이 정립되었으며, 현재까지도 Copula 함. 뭄 심도를 활용한 이변량 가뭄 지역빈도해석 식의 입력 값으. 수는 통계 및 경제 분야 등 여러 분야에 적용이 이루어지고 있다. 로 활용되며, 식의 형태는 Eq. (4)와 같다.. (Joe, 1997; Nelsen, 2007; Radice et al., 2016). 최근 수문학 분 야에서도 다변량 분석시 Copula 함수를 활용한 다수의 연구가 진행되었으며(Kim et al., 2016), 특히 가뭄과 같이 복합인자가 동시에 발생하는 변량의 경우 상호 의존성이 뚜렷하기 때문에 가뭄빈도해석 시 Copula 함수의 적용을 통해 다양한 장점을 활 용할 수 있다. 수문학 분야에서 사용되는 변량의 경우 분포 형태. ≥ and ≥ . (4a). ′ (4b) ≥ or ≥ . 가 비대칭적이면서, 꼬리(tail)가 두꺼운 극치값(극대 또는 극 소)값을 보이는 경향이 강하다. 따라서 이러한 자료의 꼬리 부. 여기서, E(L)은 평균가뭄발생 간격이며, TDDS는 가뭄 지속기. 분에 대한 분포를 다루는데 있어 Copula 함수 활용이 타당하다. 간과 심도가 모두 초과할 확률(D ≥ d and S ≥ s)일 때 결합재. 고 알려져 있다(Kim et al., 2016). 특히, 가뭄의 경우 일반적으. 현기간(joint return period), T DDS는 가뭄 지속기간과 심도 중. 로 복합적인 인자가 동시에 고려되기 때문에 가뭄에 대한 빈도. 하나가 초과할 확률(D ≥ d or S ≥ s)을 의미한다.. '. 해석시 단변량 가뭄빈도해석보다 다변량의 인자를 고려한 가 뭄빈도해석의 적용이 정량적인 가뭄위험도 평가측면에서 유 리하다고 알려져 있다(Shiau and Shen, 2001).. 2.3 Bayesian Copula 기반 이변량 가뭄 지역빈도해석 최근 수문학 분야에서는 관측자료에 대한 지점빈도해석시. Copula 함수는 2개 이상의 주변확률분포를 이용하여 결합. 제한적인 자료의 길이로 인해 신뢰성이 결여되는 문제점을. 확률분포를 구축하는 역할을 하며, 기본적으로 누가분포함. 해결하기 위한 대안으로 지역빈도해석 방법을 활용한 연구가. 수가 입력자료로 활용된다. 본 연구에서는 Copula 함수의 적. 진행되었으며, 다수의 연구에서 효율성이 확인되었다. 그러. 용 시 비교적 과정이 간편하고 다양한 확률분포형 적용이 가. 나 빈도해석 수행시 자료 및 모형의 매개변수에서 나타나는. 능한 Archimedean Copula 함수를 활용하였다. 대표적으로 이. 불확실성 정도와 이에 따른 설계수문량에 신뢰성에 대한 연구. 용되는 Copula 함수는 Clayton, Frank, Gumbel Coupla 등이. 는 미진한 실정이다. 기존 이변량 가뭄빈도해석 결과의 경우,. 있으며, 각각의 함수식을 Table 1에 정리하였다.. 산정된 빈도의 불확실성 구간에 대한 정량적 제시가 어려우. Shiau and Shen (2001)은 변량간 결합확률분포를 활용하. 며, 특히 자료연한이 짧은 자료를 대상으로 분석이 이루어지. 여 가뭄과 비 가뭄의 지속기간이 기하학적 분포를 따른다는. 는 경우 해석결과에 대한 신뢰성을 판단하는데 어려운 단점이. 가정 하에 평균 가뭄사상 발생 간격을 산정하였다. 본 연구에. 있다(Kim et al., 2017). 이에 본 연구에서는 불확실성 평가에. 서 산정한 가뭄의 분포를 고려할 때 가뭄의 지속기간(TD)과. 대표적으로 활용되는 Bayesian 방법을 기존 Copula 함수 이론. 심도(TS)에 대한 재현기간은 Eq. (3)과 같이 정의된다.. 과 결합한 이변량 가뭄 지역빈도해석 기법을 개발하였다. 제시 된 모형을 통해 기존의 강우관측소별 가뭄 지점빈도해석 과정. . (3a). . (3b). 으로부터, 지역의 가뭄특성을 전반적으로 고려하여 선별된 유사한 가뭄특성을 갖는 지점을 통합적으로 고려하여 하나의 지역화 된 가뭄빈도해석 결과를 제시하였다. Bayesian 기법을. Table 1. The Archimedean copula functions used in this study. Name of copula. Bivariate Copula . Parameter . Clayton. max exp exp exp exp log log . ∈ ∞╲ . Frank Gumbel. ∈╲ ∈ ∞.
(5) 989. J.-G. Kim et al. / Journal of Korea Water Resources Association 52(12) 985-999. 도입하여 동일한 지역적 조건에 대한 모형의 최적화된 매개변. 은 우도함수를 의미하며, n은 자료의 개수, k는 매개 이때, . 수가 추정될 수 있도록 하였으며, 이분화 되어 있던 계산 과정. 변수의 개수를 의미한다. 본 연구에서 활용된 가뭄 지속시간. 을 통합하여 주변확률분포와 Copula 함수의 우도(likelihood). 및 심도에 대한 확률분포형은 각각 대수정규분포(Log-normal. 가 동시에 추정될 수 있도록 모형을 구성하였다.. distribution) 및 감마분포(Gamma distribution)로 채택되었. Bayesian 확률은 두 확률 변수의 조건부확률(conditional probability)을 나타내는 정리로, A라는 사건이 발생할 때 확률. 으며, 각각의 확률분포형에 대한 누가확률밀도함수는 Eqs. (9) and (10)과 같다.. (P(A))을 기준으로 B라는 새로운 자료의 증가에 의해서 정보가 갱신되며 최종적으로 사건이 일어날 확률(P(A|B)) 사이의 관계 를 나타낸다. 여기서 P(A)는 사전확률(prior probability), P(A|B) 는 사후확률(posterior probability)을 말한다(Gelman et al., 2004). Bayesian을 통한 매개변수 추정기법은 기존 방법들(최 우도법, 모멘트법, 확률가중모멘트법)과는 다르게 매개변수. log . . (9). . (10). 를 확률변수로 취급한다. 즉, 매개변수가 단일 값이 아닌 확률 분포의 형태로 부여되어 최종적으로 매개변수의 사후분포를. 여기서 는 평균, 는 분산, k는 형상, 는 크기 매개변수를. 추정하는데 목적을 두며, Bayes 정리(Bayes’s rule)를 기반으. 의미하며, 는 감마함수를 의미한다.. 로 한다. Bayes 정리에 대한 기본적인 개념은 다음과 같다. 주어. 본 연구의 목적은 대상유역에 대한 지역빈도해석을 통해 통계. 진 확률변수 와 매개변수들의 집합 가 있을 때, 두 확률변수. 적으로 신뢰성 있는 결과를 도출하는데 목적이 있다. 이에 자료. 들의 결합확률분포는 Eq. (5)와 같이 사전분포 와 우도. 의 분포 형태를 바탕으로 각각의 Archimedean Copula (Clayton,. 의 곱으로 표현할 수 있다. Bayes 정리에서 매개변수 와. Gumbel, Frank)함수에 대한 우도를 추정하였으며, 우도가 가장. 변량 의 조건부확률과 주변확률의 관계는 Eq. (6)과 같으며,. 크게 나온 Frank Copula 함수를 대상유역에 대한 최적 함수로. Eq. (7)에서 좌변 는 사후분포를 나타내며 사전분포와. 선정하였다. 최종적으로 지속기관과 심도에 대한 각각의 분포형. 우도 의 곱으로 추정될 수 있다(Gelman et al., 2003).. 과 Frank Copula 함수와 결합하여 결합우도함수(joint likelihood function)로 유도하면 Eq. (11)과 같이 나타낼 수 있다.. . (5) . . (6). ∝ . (7). 본 연구에서 개발한 Bayesian Copula 기반 이변량 가뭄 지 역빈도해석 모형의 주요 장점은 다음과 같다. 기존 연구에서 수행되는 분석절차는 각 변량의 주변확률분포를 독립적으로 산정 후 Copula 모형에 적용하여 빈도해석이 수행되는 반면, 제시된 모형에서는 이분화 되어 있던 계산 과정을 통합하여 주변확률분포와 Copula 함수가 동시에 추정된다. 모형을 개 발하기에 앞서, 지속시간과 심도의 주변확률분포는 대표적 인 적합통계량 선정방법 중 하나인 BIC (Bayesian information criterion)를 기준으로 각각 최소의 BIC값을 갖는 확률분포형 을 선택하였다. BIC 통계량을 산정하는 일반적인 식은 Eq. (8) 과 같이 나타낼 수 있다(Findley, 1991).. . . log log log . . . log log log × log × log log log . . (11). 여기서 LF는 Frank Copula의 결합우도함수를 의미하며, i는 대상유역의 강우관측소 지점수, j는 각각의 지점에서 발생한 가뭄사상 횟수를 나타낸다. Eq. (11)은 앞서 제시된 Table 1의 Frank Copula 함수와 가뭄 특성인자의 주변확률분포인 대수 정규분포와 감마분포를 우도함수 형태로 나타낸 것이다. 본 연구에서는 제시된 식을 활용하여 각 매개변수 및 도출된 결 과에 대한 불확실성 구간을 정량적으로 산정할 수 있는 계층 적 Bayesian 모형으로 확장하였다. 즉, 대상유역에 모든 지점 의 특성인자를 Eq. (11)의 대수정규분포 매개변수( )와 감 마분포 매개변수( ), 그리고 Copula 함수 매개변수( )의. ln ln. (8). 사전분포는 Eqs. (12)~(16)과 같이 부여하였다. 매개변수 와.
(6) 990. J.-G. Kim et al. / Journal of Korea Water Resources Association 52(12) 985-999. 같은 경우 음(-),양(+)의 값을 모두 고려해야하기 때문에 정규분. ∼ . (19a). 포를 부여하였으며, 매개변수 의 경우 양(+)의 값만 고려. ∼ . (19b). ∼ . (20a). ∼ . (20b). min ∼ ∼. (21a). max ∼ min . (21b). 하기 위하여 감마분포를 부여하였다. Copula 함수 매개변수 는 Copula 이론의 기본 가정에 근거하여 균등분포로 가정하였다. ∼ . (12). ∼ . (13). ∼ . (14). ∼ . (15). ∼ min max . (16). 위에서 정의된 우도함수와 매개변수들의 사전분포를 Eq. (5)에 대입하여 정리하면 Eq. (22)와 같이 나타낼 수 있으며, 이를 통해서 매개변수들의 사후분포 추정이 가능해진다.. 여기서 N은 정규분포를, 는 감마분포를, U는 균등분포를 의 미한다.. ∝ ∙ . (22). 매개변수들의 사전분포( )는 자료를 기반으로 하는 정. 여기서 ∼ ∼ min max 는 본. 보적 사전분포(informative priors)와 자료에 크게 상관하지 않. 연구에서 추정되는 매개변수를 나타내며, 는 매개변수. 는 비정보적 사전분포(noninformative priors)가 있으며, 비정. 사전분포를 나타낸다. 최종적으로 우도함수를 나타내는. 보적 사전분포로는 정규분포, 균일분포, 지수분포가 대표적. 는 Eq. (23)과 같이 표현할 수 있다.. 으로 활용된다(Gelman et al., 2004; Lee et al., 2010). 앞서 언급한 바와 같이 사후분포는 사전분포와 우도함수의 곱으로 계산되며, 매개변수 추정을 위한 자료가 충분한 경우 우도함수. . . . . . (23). 가 비교적 정확하게 추정이 가능하기 때문에 사후분포 추정에 있어서 주도적인 역할을 하게 되며 사전분포의 중요성은 상대. 여기서 I는 기상청 강우관측소의 개수를 나타내며, J는 각 지. 적으로 작아진다. 그러나 사전분포에 대한 정보가 명확하지 않. 점에서 발생한 가뭄의 개수를 의미한다. 위에서 정의된 우도함. 은 상태에서 상대적으로 좁은 범위를 갖는 사전분포를 적용하. 수와 매개변수들의 사전분포들을 Eq. (22)에 대입시킴으로서. 게 되면 사후분포 추정에 있어 신뢰성이 결여되는 문제점이 발. Eq. (24)와 같이 사후분포를 식으로 나타낼 수 있다.. 생한다. 즉, 우도가 최대가 되는 지점으로 사후분포의 중심으 로 이동하지 못하고 멈추게 되며, 실제 매개변수의 분포와는 상이한 왜곡된 매개변수를 추정하는 결과를 초래할 수 있다. 본 연구에서는 각각의 가뭄변량에 대해 최우도법을 통해 통계적 특성으로부터 정보적 사전분포를 활용하여 사후분포 를 추정하였으며, ∼ ∼ min max 는 각각의 분포 에서 추정되는 매개변수를 나타낸다. 각각의 매개변수에 대 한 사전분포는 Eqs. (17)~(21)과 같이 부여하였다.. . . . ∝. . . ∙ ∙ ∙ ∙ ∙ min max ∙ ∙ ∙ ∙ ∙ ∙ ∙ ∙ ∙ min. (24). ∼ . (17a). ∼ . 본 연구에서는 Eq. (24)의 모든 매개변수를 추정하기 위하. (17b). 여 Bayesian 모형 기반의 깁스샘플링(Gibbs sampling) 기법을. ∼ . (18a). 을 활용하여 사후분포를 산정하였다. 깁스샘플링은 Markov. ∼ . (18b). Chain Monte Carlo (MCMC) 기법의 대표적인 방법으로서. 활용하였으며, 각각의 매개변수에서 추정된 샘플(sample).
(7) 991. J.-G. Kim et al. / Journal of Korea Water Resources Association 52(12) 985-999. 이미 오래전부터 물리학 분야에서 복잡한 수식의 해를 찾기 위 해서 사용되던 방법이었으나, Gelfand and Smith (1990)에 의 하여 Bayesian 모형에 도입되어 이후 Bayesian 통계 추정 시 가장 기본이 되는 수치해석 기법이라 할 수 있다(Gelman and Hill, 2006). 또한 깁스샘플링은 조건부 확률분포를 이용하여 두개 이상의 확률 변수의 연속적인 표본을 생성하는 매우 효 율적인 알고리즘으로 알려져 있으며, 저차원 분포로부터의 표본 생성으로 구성되기 때문에 복잡한 제한조건도 쉽게 처리 할 수 있다는 장점이 있다(Geman and Geman, 1984). 깁스샘플링에 대한 자세한 내용은 기존 연구문헌들을 참조 할 수 있다(Kwon et al., 2008; Lee and Kwon, 2011). 본 연구에 서는 모형의 수렴(convergence) 여부를 확증하기 위해서 3개 의 Chain을 독립적으로 시행하여 샘플링(sampling)이 효과적 으로 혼합(mixing)되도록 하였으며, 최종적으로 MCMC 결과 에 대한 Trace Plot와 Gelman-Rubin 통계량 검정결과를 이용 하여 Markov Chain의 수렴 여부를 통계적으로 판단하였다.. 3. 연구결과 본 연구에서는 기존의 Bayesian Coupla 지점빈도해석 연구 (Kim et al., 2017)에서 수행된 한강유역에 대하여 동일한 자. Fig. 2. The map showing Han-river watershed along with KMA weather stations Table 2. Geographical characteristics of 15 weather stations operated by Korea Meteorological Adminstration (KMA). Station No.. Name. Latitude (°) Longitude (°) Elevation (El.m). 101. Chuncheon. 37.9026. 127.7357. 78. 108. Seoul. 37.5714. 126.9658. 86. 112. Incheon. 37.4776. 126.6244. 68. 114. Wonju. 37.3376. 127.9466. 149. 119. Suwon. 37.2723. 126.9853. 34. 131. Cheongju. 36.6392. 127.4407. 57. 201. Ganghwa. 37.7074. 126.4463. 47. 료를 활용하여 2013-2015년도 한강유역의 가뭄을 평가하였. 202. Yangpyeong. 37.4886. 127.4945. 48. 으며, Bayesian 기법과 Copula 함수를 연계한 이변량 지역빈. 203. Icheon. 37.2640. 127.4842. 78. 도 해석모형을 활용하여 한강유역의 가뭄 지역빈도해석 결과. 211. Inje. 38.0599. 128.1671. 200. 212. Hongcheon. 37.6836. 127.8804. 141. 221. Jecheon. 37.1593. 128.1943. 264. 를 기존의 지점빈도해석 모형과 비교하여 제시하였다.. 3.1 대상유역 한강은 서울을 관통하는 우리나라 중부의 최대 하천으로서. 226. Boeun. 36.4876. 127.7341. 175. 272. Yeongju. 36.8719. 128.5170. 211. 273. Mungyeong. 36.6273. 128.1488. 171. 크게 북한강과 한강으로 구성되어 있으며, 한강유역은 한반도 중심부(위도 36°30'~38°55'N, 경도 126°24'~129°02'E)에 위치 2. 로 선정되었으며, 한강유역의 지형적 특성을 고려하여 지역. 하고 있다. 유역면적은 약 25,594 km 로 한반도 국토면적의 약. 빈도해석을 수행하기 위하여 Frank Copula 함수의 우도 추정. 23%를 차지하고 있으며, 태백산맥과 소백산맥 등 높은 산맥이. 결과를 바탕으로 한강유역에 위치한 기상청 강우관측소 중. 두 개의 방향으로 펼쳐져 있어 같은 유역 내에서 상이한 지리적,. 본 연구에 적합한 강우관측소를 선별하였다. 최종적으로 18. 기후학적 특성을 보여주고 있다. 한강유역의 연평균 강우량은. 개 강우관측소 중 우도의 크기 차이가 현저하게 나타나는 3개. 약 1,253 mm이며, 이 중 2/3 이상의 강우(894 mm, 연평균 강우량. 의 강우관측소(속초, 대관령, 강릉)를 제외한 15개의 기상청. 의 71%)가 여름철(6월~9월)에 집중된다(Kim et al., 2012).. 강우관측소를 선별하였다. Fig. 2는 본 연구에서 활용한 한강. 본 연구에서는 선행연구에서 활용한 한강유역의 동일한. 유역 내 위치한 15개의 기상청 관측소를 도시한 결과를 나타. 18개의 강우관측소 자료를 활용하여 가뭄을 구분하였으며,. 내며, Table 2는 관측소별 속성정보를 나타낸다.. 이변량 가뭄빈도해석을 위한 최적 Copula 함수를 선정하기 위하여 각 관측소별 세 가지 Copula (Clayton, Gumbel, Frank). 3.2 분석결과. 함수에 대한 우도를 산정하였다. 결과적으로 Frank Copula. 3.2.1 가뭄 특성인자 추출 및 확률분포형 선정. 함수가 한강유역의 이변량 지역빈도해석 모형에 적합한 함수. 본 연구에서는 한강유역 내 기상청 관측 강우자료를 6개월 누적.
(8) 992. J.-G. Kim et al. / Journal of Korea Water Resources Association 52(12) 985-999. 강우량으로 변환하여 Eqs. (1) and (2)에 따라 가뭄빈도해석을 위한. 역 전반의 평균적인 특성을 확인하고자 유역평균 강우량을. 변량(지속시간, 심도)을 추출하였다. Table 2에 수록된 한강유역의. 산정하여 인자를 도출하였으며, 그 결과를 Fig. 5에 도시하였. 강우관측소 중 서울 관측소의 연속이론에 따른 가뭄을 구분한 결과. 다. Fig. 5의 결과를 살펴보면, 한강유역 전반의 평균적인 가뭄. 및 연도별 가뭄변량 산정결과를 Figs. 3 and 4에 대표로도시하였으. 특성과 “빨간별”로 나타낸 2013-2015년의 가뭄상태가 상당. 며, Fig. 3에도시된서울관측소의Anomaly를 살펴보면 2013-2015. 히 상이하다는 것을 시각적으로 확인할 수 있다. Table 3과. 년도에 발생했던 가뭄 지속시간과 심도가 이전에 발생했던 가뭄보. Fig. 5에서 확인할 수 있듯이, 2013-2015년 사이에 한강유역. 다 아주 극심했던 것을 시각적으로 확인 할 수 있다.. 에 발생한 가뭄은 전반적으로 가뭄 지속시간 및 심도가 이전. Table 3은 본 연구에서 활용한 기상청 지점별 가뭄 특성인자 를 정량적으로 제시한 결과이며, 대부분의 관측소에서. 에 발생했던 가뭄보다 지속시간이 길고, 강우누적부족량 역 시 크게 부족했던 것을 보여주고 있다.. 2013-2015년도에 이전에 발생했던 강우 누적 부족량 보다 약. 일반적으로 우도만을 가지고 최적분포형을 선택하는 경. 2-3배 정도 극심한 가뭄 사상을 보이고 있는 것을 확인 할 수 있다.. 우, 모분포의 자유도가 후보모델의 자유도보다 낮은 경우 잘. 예를 들어 서울 강우관측소의 경우, 2013-2015년 가뭄의 지속시. 못된 확률분포를 선택할 확률이 높은 단점이 있다(Akalke,. 간 및 강도가 전체기간으로부터 추출된 가뭄지속시간 및 강도와. 1974). 따라서 본 연구에서는 이변량 Copula 함수의 가뭄 특. 동일하며 결과적으로 최근 가뭄이 역사적으로 가장 극심한 가뭄. 성인자에 대한 적합한 확률분포형을 선택하기 위한 방법으. (지속기간 24개월, 심도 1205.1 mm)으로 분류될 수 있다. 이 외. 로 우도, 매개변수 개수, 자료 수 등을 적절하게 고려할 수 있. 에도 춘천, 인천, 수원, 강화, 양평, 인제 홍천 관측소를 살펴보면. 는 BIC 통계량 결과를 활용하였다. BIC는 자료가 해당 모형에. 2013-2015년 사이에 발생한 가뭄이 관측 이래 가장 극심한 가뭄. 적합한 정도를 평가하는 척도 중 하나이며, 널리 알려져 있는. 이며, 다른 관측소의 경우에도 이전에 발생했던 가뭄에 상응하. Akaike information criterion (AIC)와 Deviance information. 는 가뭄 패턴을 보이고 있는 것을 정량적으로 확인할 수 있다.. criterion (DIC)와 유사한 개념으로서 산정된 값이 작을수록. 본 연구에서는 도출된 가뭄 특성인자를 대상으로, 한강유. 보다 적합한 모형이라고 알려져 있다.. Fig. 3. Definition of drought onset and termination by run theory for Seoul weather station precipitation anomaly. Fig. 4. The extracted drought variables at Seoul weather station. The left panel indicates drought duration and the right panel indicates drought severity (-) during the duration.
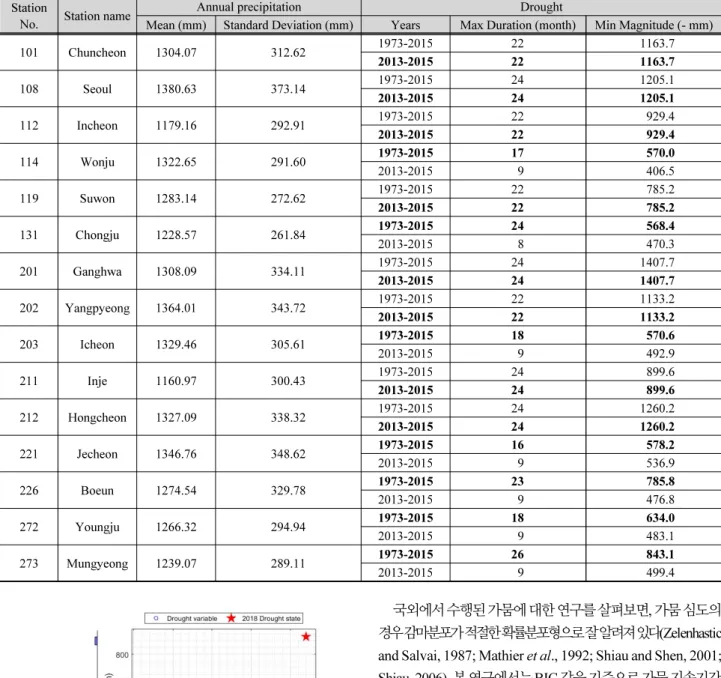
(9) 993. J.-G. Kim et al. / Journal of Korea Water Resources Association 52(12) 985-999. Table 3. Information on the gauging stations used in this study and the basic statistics for the drought characteristics. The values in parenthesis represent the maximum duration and severity calculated from the 2013-2015 drought. Annual precipitation Mean (mm) Standard Deviation (mm). Station No.. Station name. 101. Chuncheon. 1304.07. 312.62. 108. Seoul. 1380.63. 373.14. 112. Incheon. 1179.16. 292.91. 114. Wonju. 1322.65. 291.60. 119. Suwon. 1283.14. 272.62. 131. Chongju. 1228.57. 261.84. 201. Ganghwa. 1308.09. 334.11. 202. Yangpyeong. 1364.01. 343.72. 203. Icheon. 1329.46. 305.61. 211. Inje. 1160.97. 300.43. 212. Hongcheon. 1327.09. 338.32. 221. Jecheon. 1346.76. 348.62. 226. Boeun. 1274.54. 329.78. 272. Youngju. 1266.32. 294.94. 273. Mungyeong. 1239.07. 289.11. Years 1973-2015 2013-2015 1973-2015 2013-2015 1973-2015 2013-2015 1973-2015 2013-2015 1973-2015 2013-2015 1973-2015 2013-2015 1973-2015 2013-2015 1973-2015 2013-2015 1973-2015 2013-2015 1973-2015 2013-2015 1973-2015 2013-2015 1973-2015 2013-2015 1973-2015 2013-2015 1973-2015 2013-2015 1973-2015 2013-2015. Drought Max Duration (month) 22 22 24 24 22 22 17 9 22 22 24 8 24 24 22 22 18 9 24 24 24 24 16 9 23 9 18 9 26 9. Min Magnitude (- mm) 1163.7 1163.7 1205.1 1205.1 929.4 929.4 570.0 406.5 785.2 785.2 568.4 470.3 1407.7 1407.7 1133.2 1133.2 570.6 492.9 899.6 899.6 1260.2 1260.2 578.2 536.9 785.8 476.8 634.0 483.1 843.1 499.4. 국외에서 수행된 가뭄에 대한 연구를 살펴보면, 가뭄 심도의 경우감마분포가적절한확률분포형으로잘알려져있다(Zelenhastic and Salvai, 1987; Mathier et al., 1992; Shiau and Shen, 2001; Shiau, 2006). 본 연구에서는 BIC 값을 기준으로 가뭄 지속기간 과 가뭄 심도에 대한 최적 주변확률분포형으로 대수정규분포 와 감마분포를 선정하여 연구를 진행하였다. 가뭄심도의 경우 BIC를 기준으로 일부 지점에서 대수정규분포가 최적분포형으 로 고려되고 있으나, 감마분포와 BIC값의 차이가 크지 않고 지 역빈도해석을 위해서 본 연구에서는 감마분포를 가뭄심도 평 가를 위한 주변확률밀도함수로 선정하였다. 각각의 확률분포 형에 따른 BIC 산정결과는 Table 4에 제시하였으며, Fig. 6은 Fig. 5. Scatter plot of drought variables based on observed precipitation anomalies from 1974 to 2015. The symbol “red star” indicates current drought state. 각각의 인자에 대한 확률분포형의 CDF를 비교하여 도시한 결 과이다. 도시된 그림을 통해 가뭄 지속시간과 심도 모두 각각의 확률분포형을 잘 따르고 있는 것을 확인 할 수 있다..
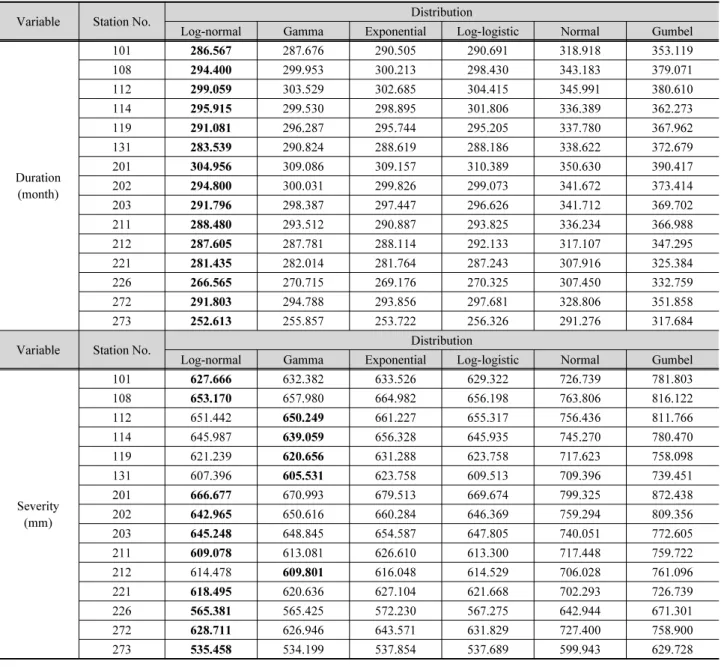
(10) 994. J.-G. Kim et al. / Journal of Korea Water Resources Association 52(12) 985-999. Table 4. BIC values for different marginal distributions across KMA weather stations. The distribution with the lowest BIC is preferred. Variable. Station No. 101. Duration (month). Variable. Severity (mm). Distribution Log-normal. Gamma. Exponential. Log-logistic. Normal. Gumbel. 286.567. 287.676. 290.505. 290.691. 318.918. 353.119. 108. 294.400. 299.953. 300.213. 298.430. 343.183. 379.071. 112. 299.059. 303.529. 302.685. 304.415. 345.991. 380.610. 114. 295.915. 299.530. 298.895. 301.806. 336.389. 362.273. 119. 291.081. 296.287. 295.744. 295.205. 337.780. 367.962. 131. 283.539. 290.824. 288.619. 288.186. 338.622. 372.679. 201. 304.956. 309.086. 309.157. 310.389. 350.630. 390.417. 202. 294.800. 300.031. 299.826. 299.073. 341.672. 373.414. 203. 291.796. 298.387. 297.447. 296.626. 341.712. 369.702. 211. 288.480. 293.512. 290.887. 293.825. 336.234. 366.988. 212. 287.605. 287.781. 288.114. 292.133. 317.107. 347.295. 221. 281.435. 282.014. 281.764. 287.243. 307.916. 325.384. 226. 266.565. 270.715. 269.176. 270.325. 307.450. 332.759. 272. 291.803. 294.788. 293.856. 297.681. 328.806. 351.858. 273. 252.613. 255.857. 253.722. 256.326. 291.276. 317.684. Log-normal. Gamma. Exponential. Normal. Gumbel. Station No.. Distribution Log-logistic. 101. 627.666. 632.382. 633.526. 629.322. 726.739. 781.803. 108. 653.170. 657.980. 664.982. 656.198. 763.806. 816.122. 112. 651.442. 650.249. 661.227. 655.317. 756.436. 811.766. 114. 645.987. 639.059. 656.328. 645.935. 745.270. 780.470. 119. 621.239. 620.656. 631.288. 623.758. 717.623. 758.098. 131. 607.396. 605.531. 623.758. 609.513. 709.396. 739.451. 201. 666.677. 670.993. 679.513. 669.674. 799.325. 872.438. 202. 642.965. 650.616. 660.284. 646.369. 759.294. 809.356. 203. 645.248. 648.845. 654.587. 647.805. 740.051. 772.605 759.722. 211. 609.078. 613.081. 626.610. 613.300. 717.448. 212. 614.478. 609.801. 616.048. 614.529. 706.028. 761.096. 221. 618.495. 620.636. 627.104. 621.668. 702.293. 726.739. 226. 565.381. 565.425. 572.230. 567.275. 642.944. 671.301. 272. 628.711. 626.946. 643.571. 631.829. 727.400. 758.900. 273. 535.458. 534.199. 537.854. 537.689. 599.943. 629.728. Fig. 6. A comparison of CDFs between theoretical and empirical CDFs of the drought variables for Seoul weather station as representative.
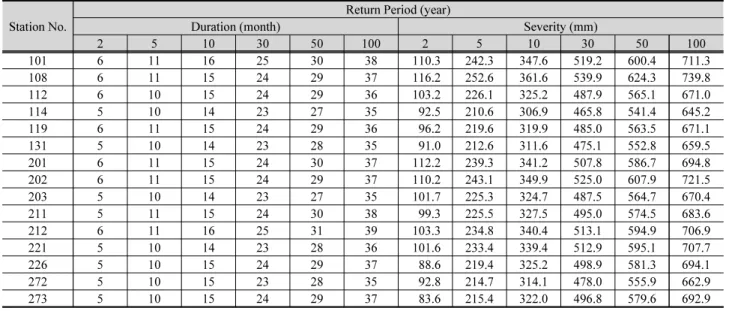
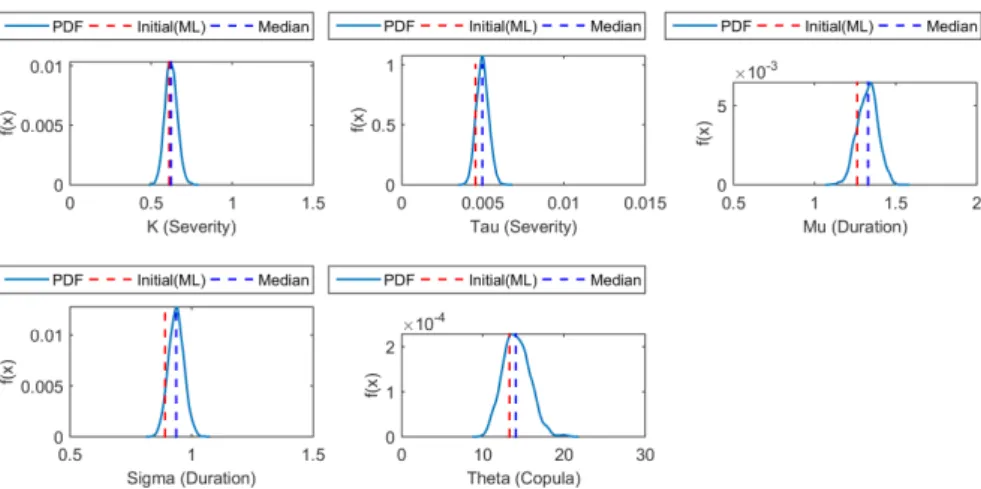
(11) 995. J.-G. Kim et al. / Journal of Korea Water Resources Association 52(12) 985-999. 3.2.2 Bayesian Copula 기반 이변량 가뭄 지역빈도모형 해석 결과. 분포로 수렴한다는 것을 의미한다(Gelman et al., 2004). 본 연. 본 연구에서는 Kim et al. (2017)에 의해 제시된 Bayesian. 구에서는 모의된 사후분포 추정 시 수치적으로 안정성을 확인. Copula 기반 이변량 가뭄 지역빈도해석 모형을 유역의 기상학적. 하기 위하여, 독립된 3개의 Markov Chain으로 부터 얻어진. 특성을 반영한 지역빈도해석 모형으로 확장하였으며, Bayesian. 2,000개의 샘플에 대한 Gelman-Rubin 검정 통계량을 산정하. Copula 함수 모형에 대한 검증은 기존 연구에서 확인할 수 있다.. 였으며, 모의된 샘플링이 정상적으로 혼합(mixing) 되었는지. 결합확률 관점에서 이변량 지역빈도해석의 결합재현기간 TDDS. 확인하였다. 최종적으로 모의된 사후분포에 대한 Gelman-Rubin. '. 는 단변량 가뭄빈도해석 결과의 최소, 최대값, 그리고 T DDS보다. 통계량 값의 대부분이 1에 매우 가깝다는 것을 확인하였으며,. 커야 하며, 이는 Eq. (25)와 같이 정리하여 나타낼 수 있다.. 이는 5,000번 이후의 모의된 샘플들이 정상적으로 수렴되었음 을 나타낸다. Fig. 7은 대표적으로 서울 강우관측소의 매개변수. ′ . ≤ min ≤ max ≤ . (25). 사후분포를 추정한 결과를 도시하였다. Fig. 7에서 빨간 점선은 모형의 매개변수 최적화를 위해 최우도법을 통해 추정된 초기. 이변량 가뭄 지역빈도해석을 수행하기에 앞서, 재현기간 (2, 5, 10, 30, 50, 100년)에 따른 가뭄 지속기간, 심도에 대한. 값을 나타내며, 파란 실선은 매개변수의 사후분포를, 파란점선 은 최적화된 매개변수의 중앙값(median)을 나타낸다.. 단변량 가뭄빈도해석을 수행하였으며, 결과를 Table 5에 제. 최종적으로 한강유역에 위치한 15개의 기상청 강우관측소. 시하였다. 분석결과, 각각의 기상청 강우관측소의 평균가뭄. 모두 앞서 제시된 Eq. (25)의 관계가 성립하는 것을 확인하기. 발생 간격(E(L))은 약 8~10개월을 갖는 것으로 확인되었다.. 위하여, 불확실성 구간과 함께 Table 6에 2013-2015년 가뭄. 앞서 언급하였듯이, 모든 매개변수를 직접적으로 추정하. 에 대한 결합재현기간 산정결과를 제시하였으며, 모두 성립하. 기는 현실적으로 많은 어려움이 따른다. 이에 본 연구에서는. 는 것을 확인하였다. 여기서, Table 6에 제시된 값은 Bayesian. Bayesian Copula 기반 이변량 가뭄 지역빈도해석 모형의 매. Copula 기반 이변량 가뭄 지역빈도해석 모형을 통해 도출된. 개변수를 추정하기 위하여 MCMC 기법 중 깁스샘플링 기법을. 결합재현기간을 정량적으로 산정한 결과이며, 도출된 가뭄. 활용하였다. 매개변수의 수렴여부를 확인하기 위해 Bayesian. 지역빈도해석 결과(quantile 50%)를 불확실성 구간(quantile. Copula 기반 이변량 가뭄 지역빈도해석 모형 내에서 3개의. 2.5%, quantile 97.5%)과 함께 제시한 결과를 나타낸다.. Chain을 독립적으로 시행하였으며, 7,000번의 샘플링 모의. 2013-2015년 사이에 발생한 가뭄사상에 대한 결합재현기. (iteration)를 수행하여 5,000개는 제거(burn-in)하고 최종적. 간 산정결과, 대부분의 관측소에서 100년 빈도를 초과하는 것. 으로 수렴된 2,000개의 샘플을 활용하여 각 매개변수의 사후분. 으로 나타났으며, 일부 지점에서는 재현기간이 1,000년이 넘는. 포를 추정하였다. 연쇄가 무한대로 진행될 때, 검정 통계량의. 극치사상을 나타내는 것으로 평가되었다. 특히, Table 3에 제시. 값이 1에 가까워지면 Chain에 의해 생성된 매개변수들이 동일한. 된 결과 중 가뭄이 가장 극심했던 지역으로 평가된 강화 관측소. Table 5. The quantiles of the drought variables according to the return periods. Return Period (year) Station No. 101 108 112 114 119 131 201 202 203 211 212 221 226 272 273. 2 6 6 6 5 6 5 6 6 5 5 6 5 5 5 5. 5 11 11 10 10 11 10 11 11 10 11 11 10 10 10 10. Duration (month) 10 30 16 25 15 24 15 24 14 23 15 24 14 23 15 24 15 24 14 23 15 24 16 25 14 23 15 24 15 23 15 24. 50 30 29 29 27 29 28 30 29 27 30 31 28 29 28 29. 100 38 37 36 35 36 35 37 37 35 38 39 36 37 35 37. 2 110.3 116.2 103.2 92.5 96.2 91.0 112.2 110.2 101.7 99.3 103.3 101.6 88.6 92.8 83.6. 5 242.3 252.6 226.1 210.6 219.6 212.6 239.3 243.1 225.3 225.5 234.8 233.4 219.4 214.7 215.4. Severity (mm) 10 30 347.6 519.2 361.6 539.9 325.2 487.9 306.9 465.8 319.9 485.0 311.6 475.1 341.2 507.8 349.9 525.0 324.7 487.5 327.5 495.0 340.4 513.1 339.4 512.9 325.2 498.9 314.1 478.0 322.0 496.8. 50 600.4 624.3 565.1 541.4 563.5 552.8 586.7 607.9 564.7 574.5 594.9 595.1 581.3 555.9 579.6. 100 711.3 739.8 671.0 645.2 671.1 659.5 694.8 721.5 670.4 683.6 706.9 707.7 694.1 662.9 692.9.
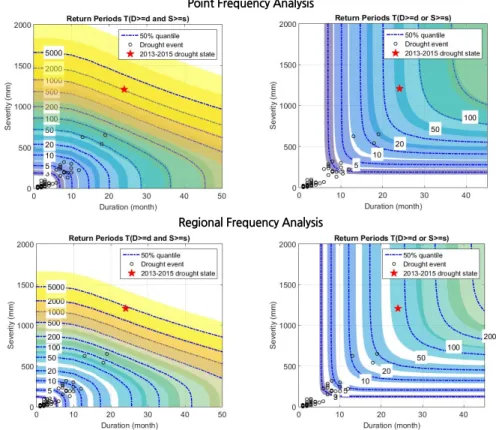
(12) 996. J.-G. Kim et al. / Journal of Korea Water Resources Association 52(12) 985-999. Fig. 7. Posterior distributions of model parameters at Seoul weather station Table 6. The univariate and joint return period and their 95% credible intervals for the 2013-2015 drought event. Return Periods (year) Station No. 101 108 112 114 119 131 201 202 203 211 212 221 226 272 273. 2.5 20 30 20 5 17 3 21 17 4 19 18 4 3 4 3. TDD 50 27 42 27 5 24 4 30 23 5 26 24 4 4 5 4. 97.5 38 61 38 7 33 4 42 33 6 38 35 5 5 6 5. 2.5 547 596 196 15 84 16 1861 344 19 131 675 19 14 19 15. TDS 50 1096 1207 350 20 137 22 4285 678 26 227 1417 26 19 26 21. 97.5 2312 2574 649 27 235 31 10629 1397 37 410 3156 37 26 37 30. 2.5 1239 1757 492 17 198 17 5454 911 21 352 1731 22 15 21 16. TDDS 50 2917 4231 1028 24 382 24 14895 2084 30 737 4197 31 20 29 23. 97.5 7262 11014 2244 33 761 35 44045 4983 44 1653 11369 46 28 42 34. 2.5 20 29 19 4 16 3 21 17 4 18 17 4 3 4 3. T'DDS 50 26 41 26 5 22 4 29 23 5 24 24 4 4 5 4. 97.5 37 59 36 6 29 4 42 32 5 35 34 5 5 5 5. 의 경우 10,000년 이상의 재현기간을 상회하는 것으로 평가되. 최우도법과는 다르게 모든 매개변수에 확률분포를 부여하고. 었으며, 불확실성을 고려하더라도 2013-2015년 발생한 가뭄. 최종적으로 사후분포를 추정이 가능하기 때문에 매개변수의. 의 강도가 과거와는 상당히 다른 크기를 갖는 것으로 판단할 수. 불확실성을 객관적으로 정량화 할 수 있다는 장점이 있다.. 있다. 그럼에도 불구하고 이러한 결과는 가뭄분석을 위해 사용. Fig. 8에서 확인할 수 있듯이, 지점빈도해석의 불확실성 구간. 된 자료의 부족으로 인해 나타나는 표본오차로 판단할 수 있다.. 이 지역빈도해석 결과에 비해서 상대적으로 크게 추정되는. Fig. 8은 대표적으로 서울관측소 지점에 대하여 기존 이변량. 것을 확인할 수 있다. 즉, 본 연구에서 제안한 가뭄 지역빈도해. 지점빈도해석 결과 및 본 연구에서 수행한 이변량 지역빈도. 석 방법의 경우, 기존 지점빈도해석에 비해 불확실성 구간이. 해석 결과를 비교하여 도시하였다. Fig. 8에서 “빨간별”은. 확연히 개선된 것을 시각적으로 확인할 수 있다. 평균적으로. 2013-2015년도에 발생한 가뭄 상태를, “검은원”은 해당 관측. 판단해보면 지점빈도해석의 비해, 지역빈도해석의 불확실. 소에서 발생했던 과거 가뭄사상을 나타내며, 파란색 점선은 불. 성 구간이 약 3배 가까이 감소하는 것으로 평가되었다. 이는. 확실성 구간의 중앙값을, 보라색부터 노란색까지 음영(shade). 유사한 특성을 갖는 강우관측소를 선별하여 사전분포를 할당. 되어 있는 부분은 매개변수에 불확실성으로 인해 나타내는 빈도. 하고, 유역 내 강수지점별로 분석된 계산 과정을 통합하여 주. 별 가뭄지속기간 및 가뭄심도의 불확실성 구간을 나타낸다.. 변확률분포와 Copula 함수의 매개변수를 동시에 추정됨에. 앞서 언급하였듯이, Bayesian 기법은 기존 최소자승법 및. 따라 본 연구에서 제안하는 지역빈도해석 과정에서 간접적으.
(13) J.-G. Kim et al. / Journal of Korea Water Resources Association 52(12) 985-999. 997. Point Frequency Analysis. Regional Frequency Analysis. Fig. 8. Joint return periods of drought duration and severity for point (above) and regional (below) frequency analysis based on Bayesian copula model at Seoul weather station. 로 자료의 개수를 증가시키는 역할을 하는 것으로 판단할 수 있다. 즉, 본 연구에서 개발한 Bayesian Copula 기반 이변량 가 뭄 지역빈도해석 모형으로 산정된 결합재현기간의 경우, 기 존 이변량 지점빈도해석 방법 결과와 유사한 결과가 도출 되 었으나, 최적 매개변수의 추정과 더불어 불확실성을 줄이는 데 있어서 상대적으로 우수한 결과가 도출됨을 확인할 수 있다. 최종적으로 Bayesian 기법에 의해서 추정된 Hyper Parameter 를 활용하여 한강유역 전체에 대한 이변량 가뭄지역빈도 해석 이 가능하며, 이를 Fig. 9에 도시하였다. 모든 매개변수는 Hyper Parameter로부터 추정되며, 대상지역 전체를 대표하는 매개변 수라고 할 수 있다. 즉, Hyper Parameter는 모든 지점에서 개별적 으로 추정되는 매개변수의 상위 매개변수로 결과적으로 지역화 된 매개변수로 고려될 수 있다. 앞서 언급한 바와 같이, 유역에 대 한 가뭄지점빈도 해석 시 부족한 자료의 수로 인해 발생하는 매개 변수의 불확실성이 크게 감소되는 것을 확인할 수 있으며, 지역적 인 가뭄특성을 효과적으로 평가할 수 있는 방안으로서 본 연구에 서 제안된 방법론이 적합성을 갖는 것으로 판단할 수 있다. Fig. 9. Joint return periods of drought duration and severity from regional frequency analysis based on Bayesian copula model over the entire weather stations.
(14) 998. J.-G. Kim et al. / Journal of Korea Water Resources Association 52(12) 985-999. 4. 결 론 본 연구에서는 가뭄 지속기간 및 심도를 활용한 기존의 이 변량 가뭄 지점빈도해석 모형에서, 이변량 가뭄 지역빈도해 석 개념으로 확장을 통해 한강유역의 2013-2015년 사이에 발 생한 가뭄에 대해 평가하였다. 이변량 가뭄빈도해석시 모형 의 매개변수 최적화 및 결과에 대한 불확실성을 정량화하기 위하여 Bayesian 모형을 Copula 모형과 연계한 새로운 가뭄 지역빈도해석 방안을 제시하였으며, 본 연구결과를 통해 도출 된 결과는 다음과 같이 요약할 수 있다. 1) 본 연구에서는 2013-2015년도 한강유역 가뭄을 평가하 기 위하여 한강유역에 위치한 기상청 강우관측소 중 동질 한 통계적 특성을 갖는 관측소를 선별하였다. 1974년부터 2015년까지 기록된 월강우량 자료의 6개월 누적 Anomaly. 전반적인 가뭄특성을 고려하기 위한 가뭄해석시 보다 안정 적인 결과를 도출하기 위해서는 지점별 자료의 수를 충분히 고려한 가뭄 지역빈도해석 수행이 필요할 것으로 판단된다. 더불어 본 연구에서 제안된 방법론은 가뭄빈도해석 시 지역 의 가뭄특성을 개별지점으로부터 지역으로 연계하여 반영 할 수 있다는 측면에서 유리한 장점을 확인할 수 있었다. 향후 가뭄취약지역에 대한 행정·유역 단위의 이변량 가뭄 지역빈도해석을 수행함으로써 신뢰성 있는 가뭄 위험도 분석 이 가능하며, 재현기간에 따른 강우부족량을 기반으로 한 극 한가뭄 시나리오의 생성을 통해 상황별 용수공급능력 평가가 함께 이루어진다면, 물 배분 의사결정 및 가뭄대책 수립 등 향 후 가뭄관리의 효율성을 극대화 할 수 있는 중요한 근거를 제 공하는 기초자료로써 활용될 수 있을 것으로 사료된다.. 를 활용하여 연속이론에 따른 가뭄 지속기간 및 심도를 산 정하여 가뭄 특성인자로 활용하였으며, Copula 함수에 적용 하기 위하여 각각의 인자에 대한 확률분포형을 선택하였다. 그 결과, 가뭄 지속기간과 심도에 대한 확률분포형으로 대수 정규분포, 감마분포가 적정 확률분포형으로 선택되었다.. 감사의 글 본 연구는 환경부/한국환경산업기술원의 지원으로 수행 되었음(과제번호 83073).. 2) 기존 Bayesian 기법과 Copula 함수를 연계한 지점빈도해석 방법에 지역빈도해석 개념을 도입하여 이변량 지역빈도해석 모형으로 확장하였으며, 제시된 이변량 지역빈도해석 모형. References. 을 활용하여 2013-2015년도 한강유역 가뭄을 정량적으로 평 가하였다. 결과적으로 대부분의 관측소에서 결합재현기간이 100년 빈도 이상을 갖는 것으로 평가되었으며, 일부 지역에서 는 1,000년 이상의 빈도를 갖는 극치사상으로 평가되어, 불확 실성을 고려하더라도 2013-2015년 발생한 가뭄의 강도가 과 거와는 상당히 다른 크기를 갖는 것으로 판단할 수 있다. 3) 이변량 지점빈도해석 결과의 경우, 추정된 빈도의 불확실 성 구간 또한 매우 크게 추정된 점을 고려할 때 1,000년 이상 의 빈도는 표본 오차로 인해 나타나는 사항으로 판단할 수 있다. 즉, 최근 가뭄이 과거 40년 동안 발생한 가뭄과는 심도 측면에서 큰 차이를 나타낸다는 점에서 이들 가뭄사상의 재 현기간은 자료부족으로 인해 과대추정 될 개연성이 크다는 의미로 평가할 수 있다. 그러나 지역빈도해석 개념을 도입 함으로써, 유사한 특성을 갖는 강우관측소를 선별하여 사 전분포를 할당하고, 이분화 되어 있던 계산 과정을 통합하 여 주변확률분포와 Copula 함수가 동시에 추정됨에 따라 불확실성 구간이 상대적으로 작게 추정됨을 확인하였다. 4) 최종적으로 Bayesian 기법을 통해 지역화 된 매개변수를 활용하여 한강유역의 대표 이변량 가뭄 지역빈도해석 결과 를 불확실성 구간과 함께 도시하였다. 결과적으로, 지역의. Akalke, H. (1974). “A new look at the statistical model identification.” IEEE Transactions on Automatic Control, Vol. 19, No. 6, pp. 716-723. Bonaccorse, B., Cancelliere, A., and Rossi, G. (2003). “An analytical formulation of return period of drought severity.” Stochastic Environmental Research and Risk Assessment, Vol. 17, No. 3, pp. 157-174. Cancelliere, A., and Salas, J.D. (2010). “Drought probabilities and return period for annual streamflows series.” Journal of Hydrology, Vol. 391, No. 1-2, pp. 77-89. Fernández, B., and Salas, J.D. (1999). “Return period and risk of hydrologic events. I: mathematical formulation.” Journal of Hydrologic Engineering, Vol. 4, No. 4, pp. 297-307. Findley, D.F. (1991). “Counterexamples to parsimony and BIC.” Annals of the Institute of Statistical Mathematics, Vol. 43, No. 3, pp. 505-514. Gelfand, A.E., and Smith, A.F. (1990). “Sampling-based approaches to calculating marginal densities.” Journal of The American Statistical Association, Vol. 85, No. 410, pp. 398-409. Gelman, A., and Hill, J. (2006). Data analysis using regression and multilevel/hierarchical models. Cambridge University Press, New York. Gelman, A., Carlin, J.B., Stern, H.S., and Rubin, D.B. (2003). Bayesian data analysis. CRC press, United States of America..
(15) J.-G. Kim et al. / Journal of Korea Water Resources Association 52(12) 985-999. Gelman, A., Carlin, J.B., Stern, H.S., and Rubin, D.B. (2004). Bayesian data analysis (2nd ed.). Boca Raton: Chapman and Hall/CRC, CRC press, USA. Geman, S., and Geman, D. (1984). “Stochastic relaxation, gibbs distributions, and the Bayesian restoration of images.” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 6, pp. 721-741. Guttman, N.B. (1999). “Accepting the standardized precipitation index: a calculation algorithm 1.” Journal of the American Water Resources Association, Vol. 35, No. 2, pp. 311-322. Hong, C.S., and Lee, J.H. (2011). “VaR estimation of multivariate distribution using copula functions.” Korean Journal of Applied Statistics, Vol. 24, No. 3, pp. 523-533. Hosking, J.R.M., and Wallis, J.R. (2005). Regional frequency analysis: an approach based on L-moments. Cambridge University Press, New York. Joe, H. (1997). Multivariate models and dependence concept. CRC Press, USA. Kim, J.S., Jain, S., and Yoon, S.K. (2012). “Warm season streamflow variability in the Korean Han River basin: links with atmospheric teleconnections.” International Journal of Climatology, Vol. 32, No. 4, pp. 635-640. Kim, J.Y., Kim, J.G., Cho, Y.H., and Kwon, H.H. (2017). “A development of Bayesian copula model for a bivariate drought frequency analysis.” Journal of Korea Water Resource Association, KWRA, Vol. 50, No. 11, pp. 745-758. Kim, J.Y., So, B.J., Kim, T.W., and Kwon, H.H. (2016). “A development of trivariate drought frequency analysis approach using copula function.” Journal of Korea Water Resource Association, KWRA, Vol. 49, No. 10, pp. 823-833. Kim, J., Lim, J., and Kwon, H. (2014). “Development of hierarchical Bayesian spatial regional frequency analysis model considering geographical characteristics.” Journal of Korea Water Resource Association, KWRA, Vol. 47, No. 5, pp. 469-482. Kwak, J.W., Kim, D.G., Lee, J.S., and Kim, H.S. (2012). “Hydrological drought analysis using copula theory.” Journal of The Korean Society of Civil Engineers, KSCE, Vol. 32, No. 3B, pp. 161-168. Kwon, H.H., and Lall, U. (2016). “A copula-based nonstationary frequency analysis for the 2012-2015 drought in California.” Water Resources Research, Vol. 52, No. 7, pp. 5662-5675. Kwon, H.H., Brown, C., and Lall, U. (2008). “Climate informed flood frequency analysis and prediction in Montana using hierarchical Bayesian modeling.” Geophysical Research Letters, Vol. 35, No. 5. Kwon, H.H., Kim, J.Y., Kim, O.K., and Lee, J.J. (2013). “A development of regional frequency model based on hierarchical Bayesian model.” Journal of Korea Water Resource Association, KWRA, Vol. 46, No. 1, pp. 13-24. Lee, J.J., and Kwon, H.H. (2011). “Analysis on spatio-temporal pattern and regionalization of extreme rainfall data.” Journal of The Korean Society of Civil Engineers, KSCE, Vol. 31, No. 1B, pp. 13-20. Lee, J.J., Kwon, H.H., and Kim, T.W. (2010). “Concept of trend analysis of hydrologic extreme variables and nonstationary. 999. frequency analysis.” Journal of The Korean Society of Civil Engineers, KSCE, Vol. 30, No. 4B, pp. 389-397. Lee, T., and Son, C. (2016). “Analyzing the drought event in 2015 through statistical drought frequency analysis.” Journal of Korea Water Resource Association, KWRA, Vol. 49, No. 3, pp. 177-186. Mathier, L., Perreault, L., Bobée, B., and Ashkar, F. (1992). “The use of geometric and gamma-related distributions for frequency analysis of water deficit.” Stochastic Hydrology and Hydraulics, Vol. 6, No. 4, pp. 239-254. Nam, W.S., Kim, T.S., Shin, J.Y., and Heo, J.H. (2008). “Regional rainfall frequency analysis by multivariate techniques.” Journal of Korea Water Resource Association, KWRA, Vol. 41, No. 5, pp. 517-525. Nelsen, R.B. (2007). An introduction to copulas. Springer Science & Business Media, USA. Oh, T.S., Kim, J.S., Moon, Y.I., and Yoo, S.Y. (2006). “The study on application of regional frequency analysis using kernel density function.” Journal of Korea Water Resource Association, KWRA, Vol. 39, No. 10, pp. 891-904. Oh, T.S., Moon Y.I., and Oh, K.T. (2008). “Estimation of probability precipitation by regional frequency analysis using cluster analysis and variable kernel density function.” Journal of The Korean Society of Civil Engineers, KSCE, Vol. 28, No. 2B, pp. 225-236. Park, S.J., and Lee, C.W. (2018). “Monitoring of the drought in the upstream area of Soyang river, Inje-Gun, Kangwon-do using KOMPSAT-2/3 satellite.” Korean Journal of Remote Sensing, Vol. 34, No. 6-3, pp. 1319-1327. Potter, K.W. (1987). “Research on flood frequency analysis: 19831986.” Reviews of Geophysics, Vol. 25, No. 2, pp. 113-118. Radice, R., Marra, G., and Wojtyś, M. (2016). “Copula regression spline models for binary outcomes.” Statistics and Computing, Vol. 26, No. 5, pp. 981-995. Shiau, J.T. (2006). “Fitting drought duration and severity with twodimensional copulas.” Water resources management, Vol. 20, No. 5, pp. 795-815. Shiau, J.T., and Shen, H.W. (2001). “Recurrence analysis of hydrologic droughts of differing severity.” Journal of Water Resources Planning and Management, Vol. 127, No. 1, pp. 30-40. Sklar, A. (1959). “Fonctions de répartition àn dimensions et leurs marges.” Publications de l’Institut Statistique de l’Université de Paris, Vol. 8, pp. 229-231. Vaziri, H., Karami, H., Mousavi, S.F., and Hadiani, M. (2018). “Analysis of hydrological drought characteristics using copula function approach.” Paddy and Water Environment, Vol. 16, No. 1, pp. 153-161. Yevjevich, V.M. (1967). An objective approach to definitions and investigations of continental hydrologic droughts. Hydrology papers (Colorado State University), No. 23, Fort Collins, Colorado. Zelenhasić, E., and Salvai, A. (1987). “A method of streamflow drought analysis.” Water resources research, Vol. 23, No. 1, pp. 156-168..
(16)
수치


+6
관련 문서
J Korea Water Resour Assoc Vol 54, No 7 (2021), pp 495 507 pISSN 1226 6280 doi 10 3741/JKWRA 2021 54 7 495 eISSN 2287 6138 Modeling 2D residence time distributions of pollutants in
J Korea Water Resour Assoc Vol 54, No 6 (2021), pp 365 379 pISSN 1226 6280 doi 10 3741/JKWRA 2021 54 6 365 eISSN 2287 6138 Estimating time varying parameters for monthly water balance
J Korea Water Resour Assoc Vol 53, No 12 (2020), pp 1159 1172 pISSN 1226 6280 doi 10 3741/JKWRA 2020 53 12 1159 eISSN 2287 6138 Very short term rainfall prediction based on radar
J Korea Water Resour Assoc Vol 53, No 9 (2020), pp 701 715 pISSN 1226 6280 doi 10 3741/JKWRA 2020 53 9 701 eISSN 2287 6138 Evaluation of improvement effect on the spatial
J Korea Water Resour Assoc Vol 53, No 5 (2020), pp 323 336 pISSN 1226 6280 doi 10 3741/JKWRA 2020 53 5 323 eISSN 2287 6138 Development of index for flood risk assessment on national
J Korea Water Resour Assoc Vol 52, No 8 (2019), pp 575 587 pISSN 1226 6280 doi 10 3741/JKWRA 2019 52 8 575 eISSN 2287 6138 Selecting a mother wavelet for univariate wavelet analysis of
Comparison of Return Period by applying drought magnitude, drought duration and precipitation deficit Note: Left side, bivariate frequency analysis between drought magnitude
J Korea Water Resour Assoc Vol 50, No 7 (2017), pp 455 465 pISSN 1226 6280 doi 10 3741/JKWRA 2017 50 7 455 eISSN 2287 6138 Development of an anisotropic spatial interpolation method
