서 론
지도학습(supervised learning)기반의 인공신경망은 모 집단에서 무작위로 추출한 표본의 학습(training)을 진행하 여, 입력층과 출력층 자료 사이의 상관성을 확보하는 기술
이다. 인공신경망의 효율성은 지도학습으로 구성되는 입 력층과 출력층 상관관계의 신뢰도에 따라 결정된다. 학습 에 기반한 인공신경망 모델은 정방향 모델링에 기반한 프 록시모델로서 저류층 시뮬레이션을 보완하여 왔다(Park et al., 2005; Kam et al., 2009; Min et al., 2011; Kam et al., 2013). 최근 Shahkarami et al.(2014)은 입력층에 생산자 료, 출력층에 저류층 물성을 학습함으로써 인공신경망을 역산모델로서 활용 가능함을 보였다. 그러나, 한 번의 학습 만을 수행하였기 때문에 학습집단에 따라 인공신경망의 성 능은 다양한 문제점이 있다. 한편, 역산모델 인공신경망은 다수의 정방향 전산모사를 수행하여야 하므로 연산효율을 위해 별도의 프록시모델(proxy model; surrogate model)이
거리기반 후보군 선정과 인공신경망을 결합한 가스생산량 히스토리매칭
김재준1)· 강주명1)· 박창협2)* · 안성인3)· 민배현4)
History Matching of Gas Production Rates Integrated
an Artificial Neural Network with Distance-based Candidate Selection
Jaejun Kim, Joe M. Kang, Changhyup Park*, Seongin Ahn, and Baehyun Min (Received 9 May 2017; Final version Received 24 August 2017; Accepted 30 August 2017)
Abstract : This paper presents a reliable history matching method that improves supervised-learning performances of an artificial neural network using the candidate models selected by distance-based clustering. The artificial neural network is used as an inverse method instead of a proxy model. The reservoir models within the cluster containing the true dataset update the training module. The developed method matches 2-year production histories and then estimates 3-year performances followed at shale gas reservoirs. The training performance improves the mean absolute error of daily gas rates from 29.2% to 4.3% while the optimum solutions, obtained by k-medoids clustering, show about 1.2% error of daily gas rates and 0.7% error of total production. The sensitivity analysis made by the optimal solutions reveals that the matrix porosity and its permeability influence the shale-gas production. The developed approach is able to estimate unknown production rates with reliable predictability.
Key words : Artificial neural network, Distance-based clustering, History matching, Gas production
요 약 : 이 연구에서는 거리기반 후보군 선정법을 인공신경망과 결합하여 생산 히스토리매칭을 수행하고, 생산추이 를 신뢰도 높게 예측하는 기법을 개발하였다. 생산추이를 입력층으로 한 역산모델 인공신경망을 구성하고, 거리기반 군집화를 통해 실제 생산자료와 유사한 추이를 보이는 후보모델을 인공신경망의 학습집단으로 활용하여 지도학습효 과를 개선하였다. 4개의 수압파쇄대를 갖는 셰일가스전에서 2년간 생산이력을 히스토리매칭하여 향후 3년간의 생산 이력을 예측하였다. 인공신경망 학습을 통해 매칭한 학습집단의 일가스생산량 오차는 초기 29.2%에서 마지막 세대 에는 4.3%로 개선되었다. 최적해는 참값과 비교하여 일가스생산량은 1.2%, 총생산량은 0.7%의 오차를 보였다. 최적 해를 이용한 민감도 분석결과, 모암의 공극률과 유체투과도가 생산추이예측에 민감하였다. 이 연구의 유사생산추이 후보군을 이용한 인공신경망 학습능력 개선기술은 효율적인 저류층 특성화와 신뢰도 높은 생산량 예측기법으로 활 용할 수 있다.
주요어 : 인공신경망, 거리기반 군집화, 히스토리매칭, 가스생산량
1) 서울대학교 에너지시스템공학부
2) 강원대학교 자원에너지시스템공학과
3) 삼성중공업 에너지플랜트연구센터
4) 이화여자대학교 기후 ․ 에너지시스템공학과
*Corresponding Author(박창협) E-mail; [email protected]
Address; Department of Energy and Resources Engineering, Kangwon National University, Chuncheon, Kangwon 24341, Korea.
연구논문
필요하며 광역해를 얻기 위해서는 검색영역의 설정, 학습 집단의 결정 및 학습성능 개선이 적절하게 이루어져야 한 다. 일반적으로 인공신경망의 학습성능을 개선하기 위해 서는 은닉층의 수를 늘리거나 표본집단을 대체하여 재학습 하는 방식을 취할 수 있다. 그러나, 오차를 포함한 초기집단 에서 부정확한 표본의 추출이 이루어지는 경우, 학습모듈 의 개선이 어렵다는 제약이 있다.
거리기반 군집화(distance-based clustering)은 동적자료 로 거리를 정의하고 유클리드 영역에서 모델간의 유사성을 공간적으로 표현한다. 거리기반 군집화는 거리기반 지도 상에서 가까운 모델끼리 분류하는 방법으로 k-평균 군집화 (k-means clustering)와 k-중간점 군집화(k-medoids cluste- ring)가 대표적이다(Berkhin, 2006; Park and Jun, 2009).
Scheidt and Caers(2009)는 DKM(Distance-Kernel Method) 를 개발하여 거리지도에서 모집단을 대표하는 표본을 군집 화를 통해 추출하는 기법을 개발하였다. k-평균 군집화는 계산시간이 빠르다는 장점이 있지만, 이상점(outlier)이 있 을 경우 제대로 된 군집화가 이루어지지 못한다는 단점이 있다(Velmurugan and Santhanam, 2010). k-중간점 군집 화는 k-평균 군집화가 이상점에 취약하다는 단점을 보완하 기 위하여 중심점이 아닌 중앙객체를 사용한다. 각 모델들 의 평균 거리값 대신에 각 군집에서 거리적으로 중심에 위 치한 모델을 중앙객체로 선정하여 같은 군집내에 존재하는 모델들을 대표한다.
일반적인 민감도분석(예, 반응표면법, 토네이도 다이어 그램, 스파이더 다이어그램 등)은 물성의 초기설정 범위에 따라 영향평가가 다양할 뿐만 아니라 시공간변수(spat- iotemporal parameter)에 대한 고려가 어렵다는 단점이 있 다. Fenwick et al.(2014)은 거리기반의 민감도분석기법인 DGSA(Distance based Generalized Sensitivity Analysis) 를 개발하여 비선형적인 입력값과 결과값의 관계를 정량화 하였다. DGSA는 결과값을 거리로 정의하는 거리기반 군 집화를 통해 군집을 나누고, 각 군집의 입력값과 전체 모집 단의 입력값의 누적분포함수 차이를 이용하여 민감도를 산 정하는 기법이다. Park et al.(2016)은 DGSA와 RSA(Reg- ionalized Sensitivity Analysis)를 비교한 결과, DGSA가 시공간 입력변수의 비선형적 관계를 신뢰도 높게 표현할 수 있음을 보였다.
수압파쇄대를 통한 셰일가스의 생산추이 예측과 영향인 자 평가는 저류층 시뮬레이션에 기초한다. 저류층 시뮬레 이션은 복잡하고 불균질한 균열대와 물성분포를 고려할 수 있는 반면 과도한 연산시간의 한계가 있다(Anderson et al., 2012; German et al., 2012). 셰일가스 생산추이 산정시간 을 줄이기 위한 프록시모델로는 유선모사(streamline simulation), 인공신경망(ANN; Artificial Neural Network),
FMM(Fast Marching Method) 등이 활발히 연구되고 있다 (Batycky et al., 1997; Kim et al., 2015; Xie et al., 2015;
Kim et al., 2016). 이 가운데 FMM은 확산도달시간(DTOF;
Diffusive Time Of Flight)으로부터 공저압력, 배유면적, 가스생산량을 추정할 수 있는 기술이다. Kim et al.(2017) 은 단일평판(bi-wing) 모델에서 블랙오일 시뮬레이터의 대 안으로 FMM이 유용함을 보였다.
이 연구에서는 저류층의 생산자료를 효과적으로 히스토 리매칭하는 인공신경망 기반의 역산모델을 개발하고, 최 적해를 이용하여 생산추이 영향인자를 분석하고자 한다.
연구목표는 프록시모델이 아닌 역산모델로서의 인공신경 망의 활용도를 높이고, 거리기반군집화를 통해 우수한 학 습표본집단을 선정함으로써 인공신경망의 학습성능을 개 선할 수 있는 방법론을 개발하는 것이다.
연구 방법
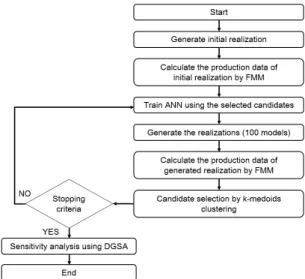
Fig. 1은 이 연구에서 제안한 거리기반 후보군 선정과 인 공신경망을 결합한 히스토리매칭 과정을 설명한 순서도이 다. 인공신경망의 학습효율을 향상시키기 위해 거리기반 군집화의 일종인 k-중간점 군집화를 통해 생산추이가 유사 한 학습집단을 선별하여 학습을 진행하였다. 학습을 통해 모집단과 동일한 수만큼의 저류층 모델을 새로 생성한 후, 참값이 포함된 군집을 다음 세대의 학습집단으로 활용하는 과정을 반복수행 하였다. 연산시간 개선을 위한 프록시모 델로는 FMM을 사용하며 민감도분석 기법은 DGSA를 이 용하였다. 순서도에 따른 구체적인 연구방법은 다음과 같다.
Fig. 1. Flow chart of the proposed method.
1) 매칭을 하고자 하는 저류층 물성값 변수들의 범위 내 에서 난수를 이용하여 무작위로 값을 추출하여 100개의 초 기 모델들을 생성한다.
2) FMM을 이용하여 초기 모델들의 생산량을 계산한다 (부록 참고).
3) Fig. 2와 같이 입력층을 각 저류층 모델의 가스 일생산 량으로 설정하고, 출력층을 불확실한 저류층 물성으로 하 는 인공신경망 모델을 구축한다. 수치 안정성을 확보하기 위해 학습을 위한 자료는 표준화한다(Centilmen et al., 1999). 이 연구에서는 식 (1)과 같이 각 모델의 생산량과 참 값인 셰일가스전의 생산량 차이를 표준화하여 입력층으로 설정하였다. 이와 같은 표준화 과정을 통하여 입·출력층을 동일한 범위로 재조정하였다.
m ax m i n
m i n
(1)
where,
위 식에서 는 번째 모델에서 시점의 입력층,
는 번째 모델에서 시점의 생산량 차이, 는 번째 모 델에서 시점의 가스 일생산량이다.
4) 예측하는 저류층 특성값은 학습자료, 검증자료, 테스 트자료 쌍의 분배와 신경망 학습과정에서 계산되는 가중치 와 편향에 따라 달라지기 때문에 독립적 학습과정을 통해
참값의 생산추이를 입력값으로 하는 100개의 저류층 모델 을 새로 생성한다.
5) 인공신경망을 통해 생성된 각각의 저류층 모델에서 가스 생산추이를 FMM으로 계산한다.
6) 계산된 생산량을 거리값으로 식 (2)와 같이 정의하고 k-중간점 군집화를 수행하여 참값인 생산량과 같은 군집에 속한 모델들을 거리기반 후보군으로 선정한다.
m ax m ax (2)
식 (2)에서 는 번째 모델과 번째 모델의 거리, 는
번째 모델에서 시점의 가스 일생산량, m ax는 모든 모 델에서 시점의 최대 가스 일생산량, 은 거리를 산정하는 최종 시점이다.
7) k-중간점 군집화를 통해 선정한 거리기반 후보군들을 다음 세대 학습집단으로 사용하여 인공신경망을 학습한다.
8) 학습한 인공신경망으로 입력층이 참값인 생산추이와 동일한 값이 주어졌을 때, 모집단의 수와 동일한 수의 저류 층모델을 생성한 후 오차의 변화를 분석한다. 충분히 작은 오차를 보일 때까지 4)에서 7)의 과정을 반복한다. 오차는 식 (3)에서 정의한 바와 같이 참값과 군집에 포함된 모델사 이의 가스 일생산량의 평균절대오차, 를 사용하였다.
또한, 개발기법의 성능평가를 위해서 생산이 종료된 시점 의 총 생산량의 평균절대오차, 를 활용하였다(식 (4)).
×
(3)
(4)
여기서, 는 번째 모델 시점의 가스생산량 는
시점의 참값인 가스생산량을 나타내고, 는 번째 모델 의 마지막 시점의 총생산량, 는 마지막 시점의 참값인 총생산량이다. 은 시간간격의 개수, 은 모델의 개수이다.
9) 최종적으로 선정한 최적해를 대상으로 DGSA를 수 행하고, 생산추이 영향변수를 평가한다. Fig. 3(a)와 같이 Fig. 2. Schematic diagram of ANN used in this study.
각 모델간의 생산량 차이를 거리로 정의하여 거리기반 군 집화를 수행하고 Fig. 3(b)와 같이 각 군집들의 누적확률분 포함수와 모집단의 누적확률분포함수와의 차이를 계산하 여 입력변수의 민감도를 산정한다.
연구 대상
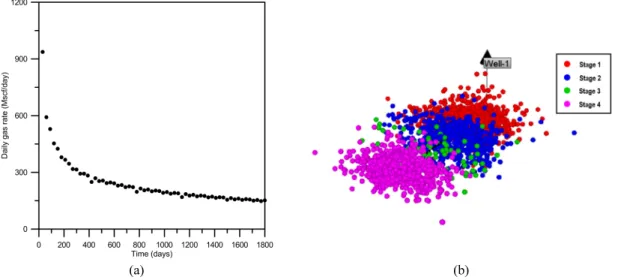
이 연구에서 개발한 인공신경망 기반의 생산 히스토리매 칭법을 검증하기 위하여 지질학적 분포특성이 복잡하지 않 은 균질 셰일가스전에 적용하였다. 연구대상 셰일가스전 에서 활용가능한 자료는 5년간의 생산추이(Fig. 4(a))와 4 개의 수압파쇄대가 존재한다는 사실을 반증하는 미소지진
파자료(Fig. 4(b))이다. 가스 일생산량은 생산 초기에는 약 750 Mscf/day 수준이었으나 5년 후 150 Mscf/day 정도로 감소하였다. 이 연구에서는 단일평판형 수압파쇄대를 이용 하였으며, 저류층 물성은 균질한 것으로 가정하였다(Fig. 5).
Table 1은 대상 저류층의 물성치를 요약하였다. 모암의 공 극률, 유체투과도, 수압파쇄대의 길이 등을 포함한 7가지 물성이 불확실하며 이 물성들이 가스 일생산량 오차의 민 감도분석 대상이다. 개발한 인공신경망의 성능을 평가하 기 위해 2년간 생산자료만을 이용하여 히스토리매칭을 한 후, 매칭을 완료한 2년부터 5년까지의 생산추이를 대상 셰 일가스전의 생산이력과 비교하여 개발기술의 성능을 평가 하였다.
(a) (b)
Fig. 3. Example of distance-based generalized sensitivity analysis: (a) distribution of reservoir models classified by three clusters in Euclidean domain and (b) cumulative distribution function curves for each cluster. At this example, cluster C is less significant than the others.
(a) (b)
Fig. 4. Available dataset used on the examination of matching and forecasting performance for the developed method: (a) daily gas rates during 5 years and (b) microseismic dataset.
연구 결과 및 토의
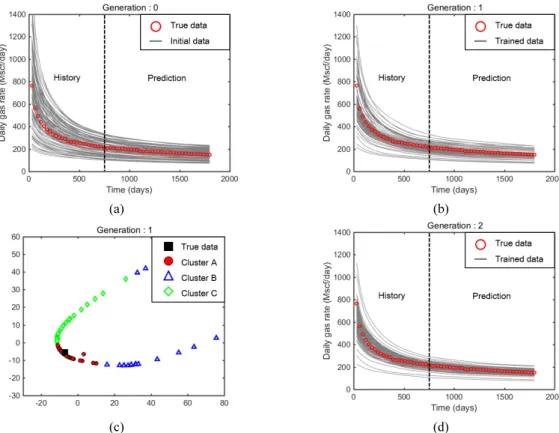
인공신경망 학습 성능 개선을 통한 히스토리매칭 Fig. 6은 연구방법과 이 연구에서 개발한 인공신경망의 학습성능 개선효과를 도시한 것이다. Fig. 6(a)는 Table 1의 물성값을 이용하여 무작위로 구성한 100개의 초기모델이
다. 이 초기모델의 생산개시이후 2년 동안의 매칭구간 평균 오차는 일생산량 기준 29.2%, 5년 후 총생산량의 경우 26.7% 수준이다. Fig. 6(b)는 100개의 초기모델을 학습집 단으로 사용하여 구성한 인공신경망으로 재생산한 100개 의 저류층 모델이다. 초기모델에 비해 일생산량은 13.8%, 총 누적생산량은 11.3%로 줄어든 효과를 보였다. Fig. 6(c) Fig. 5. Reservoir models with 4 hydraulic fractures used in the history matching.
Table 1. Reservoir properties of the shale gas reservoir
Reservoir parameters (unit) Known value Uncertain value
(minimum, maximum)
Reservoir size (x, y, z) (ft) (1000, 1250, 450)
Gas viscosity (cp) 0.02
Gas saturation (fraction) 0.6
Gas-formation-volume factor (rcf/scf) 0.008
Initial reservoir pressure (psia) 1,500
Well bottomhole pressure (psia) 500
Reservoir temperature (°F, degrees Fahrenheit) 220
Total compressibility (1/psia) 0.0002
Porosity (fraction) (0.04, 0.09)
Matrix permeability (md) (0.001, 0.004)
Enhanced permeability in the stimulated reservoir volume (md) (0.007, 0.017)
Fracture permeability (md) (0.07, 0.17)
Fracture half-length (ft) (210, 270)
Horizontal Enhanced Ratio† (0.05, 0.4)
Vertical Enhanced Ratio‡ (0.8, 1.1)
†HER (Horizontal Enhanced Ratio) = (horizontal length of enhanced zone) / (fracture length)
‡VER (Vertical Enhanced Ratio) = (vertical length of enhanced zone) / (fracture length)
는 인공신경망으로 학습한 100개의 모델을 k-중간점 군집 화를 수행하고 유클리디안 도메인에 도시한 것이다. Fig.
6(b)에서 얻어진 100개의 모델을 참값과 함께 표현하였다.
k-중간점 군집화는 개별 군집이 통계적인 의미를 가질 수 있도록 3개의 군집으로 구분하였다. Fig. 6(c)에서는 클러 스터 A(cluster A)가 참값을 포함하고 있어, 클러스터 A의 43개 모델이 다음 세대의 인공신경망 학습집단으로 사용 된다. 마지막으로 Fig. 6(d)는 클러스터 A의 43개 모델을
학습집단으로 사용하여 재생산한 100개의 저류층 모델이 다. 이 과정을 20세대까지 반복적으로 수행하였다.
Fig. 6(a), (b), (c)를 비교하면 전체적으로 참값과 유사한 생산추이를 보이는 모델이 선정되고 있다고 평가할 수 있 을 뿐만 아니라 2년(=720일) 후 생산량 예측구간의 오차도 전체적으로 줄어든 결과를 보였다. Table 2는 매칭과 예측 기간으로 구분하여 100개의 학습 후 재생산모델(Fig. 6(b), 6(c) 참조)의 일생산량 평균오차와 5년 후 총 생산량의 오차
(a) (b)
(c) (d)
Fig. 6. Plots to examine the supervised learning of developed ANN: (a) the production profiles of initial models, (b) 100 models trained using initial models in Fig. 6(a), (c) the selection of cluster involving the true dataset (the data are trained results in Fig.
6(b)), and (d) 100 models trained using the selected data in Fig. 6(c). In Fig. 6, each figure has 100 reservoir models and 1 true profile.
Table 2. Errors of 100 models generated by the trained ANN
Error Initial Generation: 1 Generation: 5 Generation: 10 Generation: 20 Daily gas rate
(matching period) 29.2% 13.8% 11.5% 7.1% 4.3%
Daily gas rate
(prediction period) 25.3% 7.5% 6.2% 2.9% 1.8%
Cumulative volume
(1,800 days) 26.7% 13.4% 11.3% 5.5% 3.5%
를 요약한 표이다. 총 20세대 가운데 1, 5, 10, 20세대를 학 습 후 재생산 모델의 오차를 요약한 것으로 세대가 거듭되 면서 실제 생산추이와 유사도가 높은 모델로 학습되고 있 음을 보여준다. 일생산량의 경우, 100개의 초기모델은 29.2%의 오차가 있었던 반면 20세대의 학습 후 재생산한 100개의 모델은 오차가 4.3% 수준으로 감소하였다.
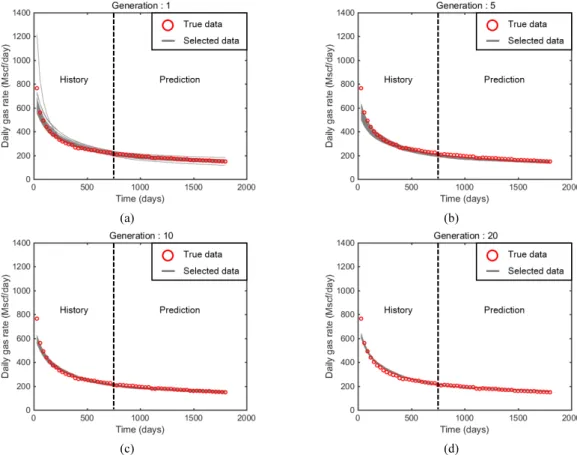
Fig. 7은 인공신경망 학습을 통해 재생산한 100개의 모델 가운데 k-중간점 군집화를 통해 선택된 표본집단과 참값을 도시한 그림이다. Fig. 7(a)는 1세대 학습후 재생산 표본 (Fig. 6(b))에서 k-중간점 군집화를 통해 얻어진 참값을 포 함한 군집(Fig. 6(c)참조)을 표현하였다. Fig. 7(b), (c), (d) 는 각각 5세대, 10세대, 20세대에서 참값을 포함한 군집이 다. 이 연구에서는 마지막 세대인 Fig. 7(d)의 23개 모델을 최적해로 평가하였다. Fig. 8은 k-중간점 군집화를 통해 선 택된 표본집단과 참값의 누적 가스생산량 추이를 보여준 다. Fig. 7에서의 결과와 동일하게 세대가 거듭되면서 히스 토리매칭의 정확도가 증가하였을 뿐만 아니라 최종 최적해 의 매칭과 예측모두 신뢰도 높게 이루어진 결과를 보였다.
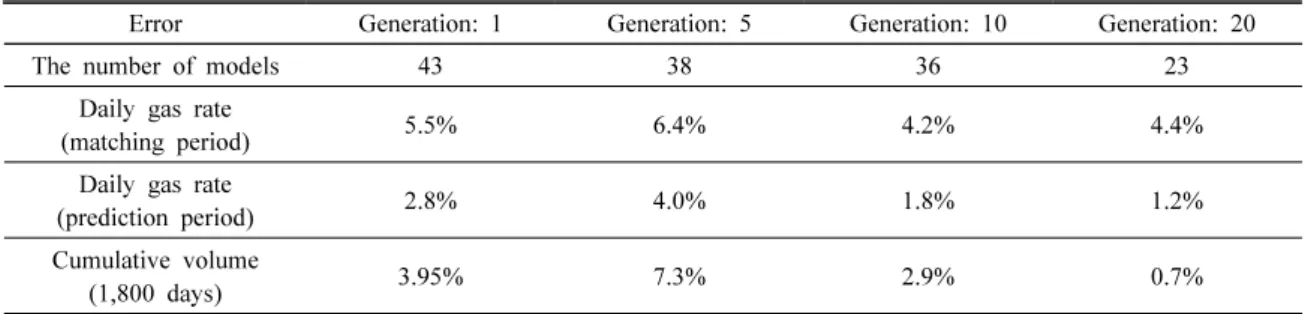
Table 3은 k-중간점 군집화이후 세대별 최적해의 오차추 이를 요약한 결과표이다. 각 세대별로 참값을 포함한 군집 의 표본수는 다양하지만 최종 20세대에서는 일생산량이 1.2%, 누적생산량이 0.7%의 예측오차를 보였다. 따라서 최종 선정한 23개의 모델은 최적해로서 일생산량의 경우, 매칭기간에는 4.4% 예측구간에서는 1.2%로 매우 신뢰도 높은 성능을 보인 것으로 분석할 수 있다.
Table 3에서 생산예측구간에서 세대가 증가하지만 오차 는 반복적인 증감현상을 보이면서 전체적으로 오차가 감소 하는 것은 k-중간점 군집화에서 그 원인을 추정할 수 있다.
이 연구에서는 참값을 포함한 군집을 구성하는 표본을 선 정하였다. 즉, 참값에 가장 가까운 모델을 1차원적으로 나 열하여 선정하지 않고 참값이 포함된 군집을 다음 세대의 학습집단으로 이용하였다. 이 방법은 최적해에 수렴하는 속도면에서는 비효율적일 수 있으나, 국소해(local minimum) 가 아닌 광역해(global minimum)에 수렴할 수 있도록 검색 공간을 확대시켜 준다. Park(2015)은 거리기반법을 이용한 모델선택법이 유사한 생산추이를 보이는 모델을 추출함에
(a) (b)
(c) (d)
Fig. 7. Comparison of daily gas rates between the true field and the selected models by k-medoids clustering: at (a) 1st generation, (b) 5th generation, (c) 10th generation, and (d) 20th generation.
효과적임을 보였으며 Lim(2016)은 참값의 생산추이만을 알고 있다고 가정한 채널저류층에서 참값과 오차가 작은 표본을 이용하여 최적해 수렴속도를 높였다. 그러나, 1차 원적으로 오차가 작은 모델을 거리지도에서 추출한다고 하 더라도 목적함수의 수에 따라서 가장 오차가 작은 모델의 수가 존재할 수 있어, 최적의 모델수 결정에 관한 불확실성 을 주장하였다. 만약 가장 빠르게 하나의 최적해를 찾기 위
해서는 히스토리매칭 구간동안 오차가 가장 작은 단일 모 델만으로 추적할 수 있으나, 신뢰할 수 있는 인공신경망 학 습은 불가능하며 학습성능 개선을 위한 최적의 모델 수를 임의로 정하여야 하는 문제점이 있다. 그리고, 최소 오차집 단을 선택한 경우에도 일정 세대이후에는 오차의 반복적인 증감은 동일하게 발생할 수 있다.
요컨대, 이 연구의 최적해 수렴경향을 분석하여 세대를
(a) (b)
(c) (d)
Fig. 8. Cumulative volume of reference field and distance-based selected data by generation: (a) generation 1, (b) generation 5, (c) generation 10, (d) generation 20.
Table 3. Errors of daily gas rates and cumulative volume for the models selected by k-medoids clustering
Error Generation: 1 Generation: 5 Generation: 10 Generation: 20
The number of models 43 38 36 23
Daily gas rate
(matching period) 5.5% 6.4% 4.2% 4.4%
Daily gas rate
(prediction period) 2.8% 4.0% 1.8% 1.2%
Cumulative volume
(1,800 days) 3.95% 7.3% 2.9% 0.7%
거듭하면서 후기 세대에서는 오차의 증감은 반복적으로 나 타날 수 있으나, 전체적인 오차추이는 감소하는 것을 확인 할 수 있었다. 작은 오차값으로 수렴하는 경향결과는 학습 능력 개선을 통해 역산모델로써 인공신경망을 히스토리매 칭 최적화기법으로 활용할 수 있음을 증명하였다. 우수한 학습모델을 구성할 수 있어서 인공신경망을 이용하여 참값 에 비교하여 오차가 작은 다수의 최적해를 확보할 수 있어 불확실성 평가에도 활용가능하다.
거리기반 민감도분석 결과
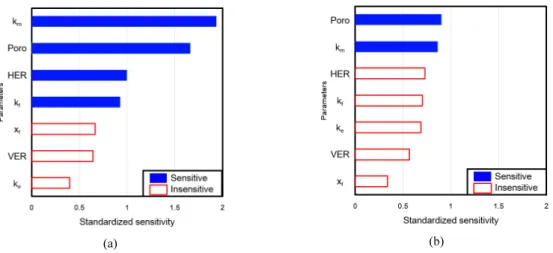
인공신경망 학습성능 개선을 통해 확보한 23개의 최적해 를 이용하여 민감도분석을 수행하고, 초기표본을 이용한 경우와 결과를 비교하였다. Fig. 9(a)는 초기 100개의 모델 (Fig. 6(a))을 이용한 거리기반 민감도분석 결과이며 Fig.
9(b)는 최종 23개의 최적해만을 이용한 결과이다. 민감도 분석은 불확실한 물성의 입력범위에 따라 민감도가 다양할 수 있다. 초기 모집단의 경우에는 일생산량 오차에 민감한 물성은 모암의 유체투과도(km), 모암의 공극률(Poro), 수압 파쇄를 통해 자극된 구역과 균열길이의 수평비(HER), 균 열의 유체투과도(kf)의 순서였으며, 균열 반길이(xf), 수압 파쇄를 통해 자극된 구역과 균열길이의 수직비(VER), 수압 파쇄를 통해 자극된 구역의 유체투과도(ke)는 민감하지 않 은 것으로 나타났다. 반면, 최적해를 이용한 민감도 분석결 과 모암의 공극률과 유체투과도의 영향도가 컸으며, 나머 지 물성의 영향도는 감소하였다. 불확실성이 큰 초기 모집 단과 최종해의 민감도 분석을 수행한 결과를 종합하면 모 암의 특성인 유체투과도와 공극률이 셰일가스전의 생산추
이에 미치는 영향이 큼을 확인할 수 있었다.
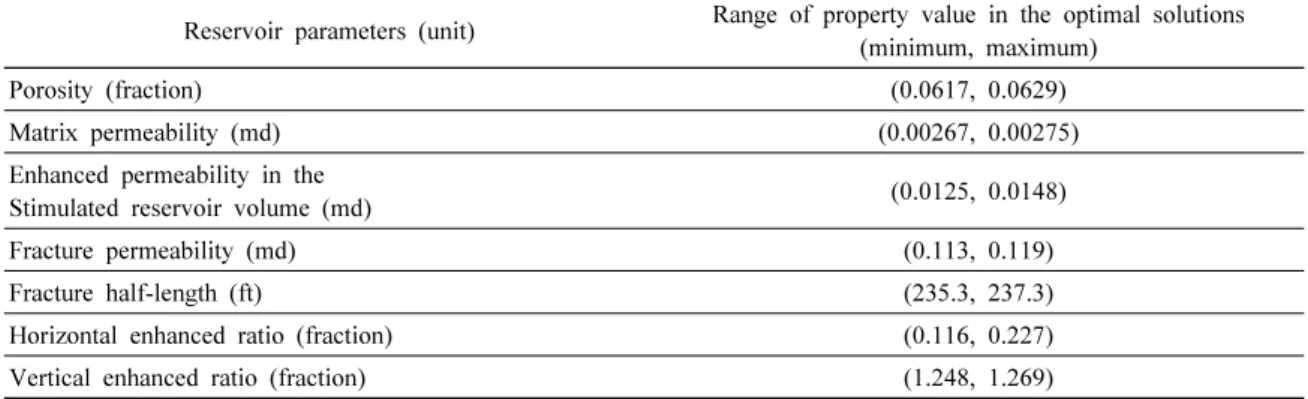
이 연구에서는 단순히 물성값의 변화에 따라 생산추이의 변화폭을 평가한 민감도 분석이 아닌, 최적해를 이용함으 로써 참값에 가까운 우수한 표본 저류층에서의 불확실성 물성을 평가할 수 있다. Table 4는 최적해의 물성분포 범위 를 요약한 표이다. 최적해를 통해 생산추이 영향도가 높은 모암의 물성치를 추정하면, 모암의 공극률은 약 0.062, 모 암의 유체투과도는 2.7 μd(micro-darcy) 수준이다. 초기 세 대는 모델의 범위가 넓은 반면에, 마지막 세대는 생산이력 이 매우 유사한 최적 모델들만으로 구성되어 있기 때문에, 참값인 생산추이에 민감하지 않은 물성은 영향도가 축소되 었다고 평가할 수 있다.
저류층 물성은 비선형적으로 생산추이에 영향을 줄 수 있으므로 유일해 문제(uniqueness problem)가 발생할 수 있다. 히스토리매칭의 유일해 문제로 인해 Table 4의 불확 실한 변수의 범위에 참값이 포함되어있다고 단정할 수는 없다. 참값과의 오차가 줄어든다는 것은 참값과 생산추이 가 유사한 다수의 저류층 모델을 확보할 개연성이 높다는 것을 의미하기도 한다. 이 연구의 셰일가스전은 균질하고 수압파쇄대는 단일평판형 모델을 가정하였기 때문에 실제 셰일가스전의 물성으로 단정하는 것은 불가능하다. 그러 나, 지질학적 특성(geological scenario)이 단순하고 암종 의 분포가 복잡하지 않은 경우, 다수의 최적해를 통해 저류 층 물성의 불확실성을 평가할 수 있었다. 지질학적 특성이 복잡하고 다수의 생산정에서 다양한 생산추이를 보이는 사 례에서는 인공신경망 출력층의 값을 지구통계학 입력변수 로 이용하여 정적 및 동적자료를 통합하는 것도 향후 연구
(a) (b)
Fig. 9. Reservoir parameters influenced the error of daily gas rates in the case of (a) initial dataset (Fig. 6(a)) and (b) the optimum solutions selected by distance-based clustering at the 20th generation (Fig. 7(d)). (km: matrix permeability, ke: enhanced permeability, kf: fracture permeability, Poro: porosity, xf: fracture half-length, HER : Horizontal Enhanced Ratio, VER : Vertical Enhanced Ratio).
주제로 고려할 수 있다. 많은 종류의 저류층 물성이 불확실 한 경우에는 물성의 대푯값을 추정하여 전체 물성분포를 예측할 수 있는 심층신경망(deep neural network) 기술도 대안이 될 수 있다(Ahn, 2017). 이 연구의 목적함수는 생산 추이인 동적자료의 매칭에 한정되어 정적자료 및 물성분포 특성은 충분히 고려되지 못한 한계가 있다. 미소지진파 자 료의 분포특성이 정적자료의 특징을 대표할 수 있기 때문 에 정적 및 동적자료를 통합 분석한 기법의 개발은 생산 히 스토리매칭 성능을 개선할 수 있을 것으로 사료된다. RTA 분석을 통해 유동특성과 영역을 규명함으로써 생산추이를 보다 정확하게 분석할 수 있는 모델링 기법을 사용한다면, 인공신경망의 예측성능 개선에 기여할 수 있을 것이다.
결 론
이 연구에서는 거리기반 군집화기법인 k-중간점 군집화 와 인공신경망 지도학습 성능개선을 통해 신뢰도 높은 예 측성능을 가진 역산모델 인공신경망기법을 개발하였다.
인공신경망의 학습성능을 개선함으로써 생산자료 히스토 리매칭을 수행하였으며 오차가 작은 다수의 최적해를 도출 하였다. 다수의 최적해를 이용한 민감도분석을 통해 생산 추이에 영향도가 높은 저류층 물성과 범위를 추정하였다.
4개의 수압파쇄대를 가지고 있는 셰일가스전 생산추이 를 히스토리매칭하여 생산추이를 예측한 결과 일생산량 평 균오차가 1.2%, 5년 후 총생산량 평균오차가 0.7%인 23개 의 최적해를 도출하였다. k-중간점 군집화를 이용하여 참 값이 포함된 군집을 인공신경망의 지도학습에 이용한 결 과, 히스토리매칭기간에서 일생산량 오차는 29.2%에서 4.3%로 개선되었다.
오차가 작은 최적해 집단을 이용한 민감도 분석결과, 일 생산량 영향인자로 모암의 공극률과 유체투과도, 수압파 쇄대의 물성의 순서로 영향도를 평가하였다. 이 연구에서
개발한 유사생산추이 군집을 이용한 인공신경망 학습능력 개선기술은 저류층의 역산모델과 신뢰도 높은 생산량 예측 기법, 민감도 분석법으로 활용할 수 있다.
Nomenclature
: hydraulic diffusivity ()
: diffusive time of flight ()
: production rate ()
: total compressibility ()
: gas formation volume factor ()
: pressure ()
: gas viscosity ()
: drainage volume ()
: permeability ()
: porosity ()
: drainage area ()
: input layer
: difference of production rates ()
: distance between two models
: cumulative production rate ()
: mean absolute error ()
사 사
이 연구는 2015년도 강원대학교 대학회계 학술연구조성 비로 연구가 이루어졌습니다(No. 520150067). 추가적으 로 2017년도 산업자원통상부의 재원으로 한국에너지기술 평가원(KETEP)의 지원(No. 20162510102040; No. 2017- 2510102150)과 서울대학교 공학연구원의 지원을 받았습 니다.
Table 4. Summary of property ranges in the optimal solutions
Reservoir parameters (unit) Range of property value in the optimal solutions (minimum, maximum)
Porosity (fraction) (0.0617, 0.0629)
Matrix permeability (md) (0.00267, 0.00275)
Enhanced permeability in the
Stimulated reservoir volume (md) (0.0125, 0.0148)
Fracture permeability (md) (0.113, 0.119)
Fracture half-length (ft) (235.3, 237.3)
Horizontal enhanced ratio (fraction) (0.116, 0.227)
Vertical enhanced ratio (fraction) (1.248, 1.269)
References
Ahn, S., 2017. Characterization of Channelized Reservoir using the Neural Network Incorporated with Deep Autoencoder, MS Thesis, Seoul National University, Seoul, Korea, 70p.
Anderson, D.M., Liang, P., and Okouma, V., 2012. Probabilistic forecasting of unconventional resources using rate transient analysis: Case studies. The SPE Americas Unconventional Resources Conference, SPE, Pittsburgh, Pennsylvania, USA, SPE-155737-MS.
Batycky, R.P., Blunt, M.J., and Thiele, M.R., 1997. A 3D field-scale streamline-based reservoir simulator. SPE Reserv.
Eng, 12, 246-254.
Berkhin, P., 2006. A survey of clustering data mining techniques. In: Kogan, J., Nicholas, C., and Teboulle, M.
(eds) Grouping Multidimensional Data, Springer, Berlin, Heidelberg, Germany, p.25-71.
Centilmen, A., Ertekin, T., and Grader, A.S., 1999. Applications of neural networks in multiwell field development. The SPE Annual Technical Conference and Exhibition, SPE, Houston, USA, SPE-56433-MS.
Fenwick, D., Scheidt, C., and Caers, J., 2014. Quantifying asymmetric parameter interactions in sensitivity analysis:
Application to reservoir modeling. Mathematical Geosciences, 46(4), 493-511.
German, G.M., Navarro-Rosales, R.A., and Dubost, F.X., 2012. Production forecasting for shale gas exploration prospects based on statistical analysis and reservoir simulation. The SPE Latin America and Caribbean Petroleum Engineering Conference, SPE, Mexico City, Mexico, SPE- 152639-MS.
Kam, D., Min, B., Chung, S., Park, C., Kang, J.M., Kim, J., Jang, I., and Choi, Y., 2009. Optimization of steam injection pressure in SAGD using artificial neural network. J. of the Korean Society for Geosystem Engineering, 46(2), 143-150.
Kam, D., Park, C., Min, B., and Kang, J.M., 2013. An optimal operation strategy of injection pressures in solvent-aided thermal recovery for viscous oil in sedimentary reservoirs.
Petroleum Science and Technology, 31(22), 2378-2387.
Kim, J., Kang, J.M., Park, C., Park, Y., Park, J., and Lim, S., 2017. Multi-objective history matching with a proxy model for the characterization of production performances at the shale gas reservoir. Energies, 10(4), 579.
Kim, J., Kang, J.M., Park, Y., Lim, S., Park C., and Park, J., 2016. Probabilistic estimation of shale gas reserves implementing fast marching method and Monte Carlo simulation. The ASME 2016 35th International Conference on Ocean, Offshore and Arctic Engineering, ASME, Busan, Korea, OMAE2016-54167.
Kim, K., Ju, S., Ahn, J., Shin, H., Shin, C., and Choe, J., 2015.
Determination of key parameters and hydraulic fracture design for shale gas productions. The Twenty-fifth International Ocean and Polar Engineering Conference, ISOPE, Kona, Hawaii, USA, ISOPE-I-15-812.
Lim, S., 2016. On the Study of a Robust History Matching of Facies Model by Distance-based Method and Ensemble Kalman Filter, MS Thesis, Seoul National University, Seoul, Korea, 68p.
Min, B., Park, C., Kang, J.M., Park, H.J., and Jang, I., 2011.
Optimal well-placement based on artificial neural network incorporating the productivity potential. Energy Sources, Part A, 33(18), 1726-1738.
Park, H., Lim, J., and Kang, J.M., 2005. Analysis of multi-well gas reservoir performance using polynomial neural network (PNN) with layer over-passing structure. J. of the Korean Society for Geosystem Engineering, 42(3), 152-159.
Park, H.S. and Jun, C.H., 2009. A simple and fast algorithm for k-medoids clustering. Expert Systems with Applications, 36(2), 3336-3341.
Park, J., 2015. A Characterization of Shale Gas Reservoir using Fast Marching Method Combined with Model Selection Approach, MS Thesis, Seoul National University, Seoul, Korea, 82p.
Park, J., Yang, G., Satija, A., Scheidt, C., and Caers, J., 2016.
DGSA: A matlab toolbox for distance-based generalized sensitivity analysis of geoscientific computer experiments.
Computers & Geosciences, 97, 15-29.
Scheidt, C. and Caers, J., 2009. Uncertainty quantification in reservoir performance using distances and kernel methods:
Application to a west Africa deepwater turbidite reservoir.
SPE Journal, 14(4), 680-692.
Sethian, J.A. and Vladimirsky, A., 2000. Fast methods for the eikonal and related Hamilton-Jacobi equations on unstructured meshes. Proceedings of the National Academy of Sciences, 97(11), 5699-5703.
Shahkarami, A., Mohaghegh, S.D., Gholami, V., and Haghighat, S.A., 2014. Artificial intelligence (AI) assisted history matching. The SPE Western North American and Rocky Mountain Joint Meeting, SPE, Denver, Colorado, USA, SPE-169507-MS.
Velmurugan, T. and Santhanam, T., 2010. Computational complexity between k-means and k-medoids clustering algorithms for normal and uniform distributions of data points. Journal of Computer Science, 6(3), 363-368.
Xie, J., Yang, C., Gupta, N., King, M.J., and Datta-Gupta, A., 2015. Depth of investigation and depletion in unconventional reservoirs with fast-marching methods. SPE Journal, 20(4), 831-841.
김 재 준
2012년 서울대학교 공과대학 에너지자원 공학과 공학사
2017년 서울대학교 공과대학 에너지시스 템공학부 공학박사
현재 서울대학교 에너지자원신기술연구소 연수연구원 (E-mail; [email protected])
박 창 협
1998년 서울대학교 공과대학 자원공학과 2000년 서울대학교 공과대학 자원공학과 공학사 2005년 서울대학교 공과대학 지구환경시공학석사
스템공학부 공학박사
현재 강원대학교 자원에너지시스템공학과(에너지자원공학과) (E-mail; [email protected])교수
민 배 현
2005년 서울대학교 공과대학 지구환경시 스템공학부 공학사
2007년 서울대학교 공과대학 지구환경시 스템공학부 공학석사
2013년 서울대학교 공과대학 에너지시스 템공학부 공학박사
현재 이화여자대학교 기후 ․ 에너지시스템공학과 교수 (E-mail; [email protected])
강 주 명
1974년 서울대학교 공과대학 자원공학과 1977년 서울대학교 공과대학 자원공학과 공학사 1981년 University of Oklahoma Dept.of 공학석사
Petroleum Engineering 공학박사 현재 서울대학교 에너지시스템공학과 교수
(E-mail; [email protected])
안 성 인
2015년 서울대학교 공과대학 에너지자원 공학과 공학사
2017년 서울대학교 공과대학 에너지시스 템공학부 공학석사
현재 삼성중공업 에너지플랜트연구센터 의장시스템연구 연구원 (E-mail; [email protected])
부 록
FMM (Fast Marching Method)을 이용한 생산량 산정 FMM은 Eikonal 방정식을 효율적으로 풀 수 있는 방법 이다. 불균질한 매질에서의 압력은 확산방정식인 식 (5)로 나타나며, 점근해법을 통해 식 (6)과 같은 Eikonal 방정식 형태로 유도할 수 있다(Sethian and Vladimirsky, 2000). 이 식에서 는 시점 일 때, 위치 에서의 압력, 는 위치 에서의 확산계수이며, 는 확산도달시간이다.
확산계수()는 식 (7)로 구할 수 있으며, 위치에 따른 유 체투과율()과 공극률(), 유체 점성도(), 총 압축률()에 따라 결정된다. 확산도달시간()은 각 격자에 배정된 확 산계수 값에 따라 계산되며, 확산계수 값이 클수록 확산도 달시간은 감소한다.
∇∙∇ (5)
∇ (6)
(7)
한 격자에 압력이 도달했다는 것은 해당 격자가 배유되 기 시작했다는 것을 의미한다. 즉, 임의의 시간에서 그 시간 보다 작은 확산도달시간 값을 가지고 있는 격자들은 이미 배유가 된 것이다. 그러므로 시간 에서 배유부피()는 식 (8)과 같이 배유된 격자들의 공극부피 합으로 계산 가능 하다.
(8) 구심유동에서의 Darcy 법칙은 식 (9)로 나타낼 수 있으
며, 변수를 배유부피로 바꾸고 연쇄법칙을 적용하면 식 (10)과 같이 표현할 수 있다.
(9)
(10)
식 (10)에서 유동량()은 유정에서의 생산량( ) 과 배유부피의 무차원 유동량()의 곱인 식 (11)로 나타낼 수 있다. 식 (11)을 식 (10)에 대입하여 정리하면 식 (12)와 같고, 일정한 정저압력 강하 조건(∆)을 가정하여 배유부 피로 적분하면 식 (13)과 같이 정리할 수 있다. 이 식에서 는 초기압력, 는 정저압력을 의미한다.
≅ ‧ (11)
‧ ≅
(12)
≅ (13)
무차원 유동량( )는 식 (14)와 같이 나타낼 수 있 으며, 이를 식 (13)에 대입하면 식 (15)와 같이 시간에 따른 유정의 생산량()을 구할 수 있다.
(14)
≅
(15)