접수일자 : 2010년 9월 6일 완료일자 : 2010년 10월 7일
* “이 논문은 2010년도 대구가톨릭대학교 교내연구비 지원에 의한 것임”
통계적 속성을 이용한 히스토그램 기반 효율적인 서명인식
An Efficient Signature Recognition Based on Histogram Using Statistical Characteristics
조용현O Yong-Hyun ChoO
대구가톨릭대학교 컴퓨터정보통신공학부
School of Computer and Information Comm. Eng., Catholic Univ. of Daegu E-mail : [email protected]
요 약
본 논문에서는 영상간의 거리에 반비례하고 상관성에 비례하는 조합형 유사성 척도에 의한 효율적인 서명인식 방법을 제 안하였다. 여기서 거리는 영상의 공간적 속성을 반영하기 위함이고, 상관성은 통계적 속성을 반영하기 위함이다. 이렇게 하 면 서명의 위치, 크기, 회전과 같은 기하학적 변화와 모양변화에 강건한 인식이 가능하다. 상관성의 척도로 이진영상의 히 스토그램에 기반을 둔 4 방향의 위치를 고려한 정규상호상관계수를 이용함으로써 서명사이의 유사성을 좀 더 빠르고 정확 하게 반영하였다. 제안된 방법을 20개의 288x288 픽셀 트럭영상과 105개의 256x256 픽셀의 서명영상을 대상으로 각각 실 험한 결과, 영상의 속성을 잘 반영한 우수한 인식성능이 있음을 확인하였다. 특히 정규상호상관계수와 순서값의 거리를 조 합한 척도가 city-block이나 Euclidean 거리를 각각 조합한 척도보다 우수한 인식성능이 있음도 알 수 있었다.
Abstract
This paper presents an efficient signature recognition method by using the hybrid similarity criterion, which is in inverse proportion to distance and in proportion to correlation between the images. The distance is applied to express the spacial property of image, and the correlation is also applied to express the statistical property. The proposed criterion provides the robust recognition to both the geometrical variations such as position, size, and rotation and the shape variation. The normalized cross-correlation(NCC), which is calculated by considering 4 directions based on the histogram of binary image, is applied to express rapidly and accurately the similarity between the images. The proposed method has been applied to the problem for recognizing the 20 truck images of 288*288 pixels and the 105(3 persons * 35 images) signature images of 256*256 pixels, respectively. The experimental results show that the proposed method has a superior recognition performance that appears the image characters well. Especially, the hybrid criterion of NCC and ordinal distance has a superior recognition performance to the hybrid criterion using city-block or Euclidean distance.
Key Words : Signature recognition, Similarity criterion, Distance, Normalized cross-correlation, Histogram of binary image
1. 서 론
식별번호나 패스워드와 같이 항상 기억해야 할 필요가 없고, 도장, 열쇠, 카드 등과 같이 항상 소지해야 할 필요도 없는 생체인식이 개인 인증수단으로 각광을 받고 있다. 그 중에서도 서명인식은 기존 인증수단에서 대두되는 분실, 유 출, 도난 등의 문제들을 해결할 수 있을 뿐만 아니라 다른 생체신호인 지문이나 얼굴 등을 이용한 인식과는 달리 거부 감이 없어 자연스럽게 적용될 수 있다. 현재 서명을 인증매 체로 사용하는 분야로는 신용카드, 은행통장, 출입국관리,
전자문서, 전자상거래 등이 있다[1-4].
서명은 전자펜 등을 이용한 필기로 입력되며, 입력된 서 명은 특성벡터인 형태, 속도, 압력, 획순 등에 의해 검증되 고, 출력으로는 인증 또는 기각의 형태로 이루어진다. 그 중 에서도 가장 중요한 서명검증은 입력방법에 따라 온라인과 오프라인 검증으로 나누어진다. 온라인 방법은 필기된 입력 서명을 받아 서명의 동적정보를 이용하여 검증하는 방법이 다. 오프라인 방법은 카메라나 스캐너 등을 통하여 입력되 는 서명을 대상으로 형태나 두께 등을 이용하여 검증하는 방법이다. 이러한 검증에서 발생하는 오류에는 진실서명을 잘못으로 기각하는 진실거부(true rejection)의 typeⅠ오류 와 위조서명을 인증하는 거짓수락(false acceptance)의 typeⅡ오류가 있다[1,2]. 또한 검증을 위한 서명간의 비교방 법에는 전역 단위 특징비교, 점 단위 특징비교, 그리고 분절 단위 특징비교가 있다. 여기서 전역 단위 특징비교는 서명
의 통계적 모델 생성이 용이한 반면, 국부적인 차이가 쉽게 드러나지 않으며, 점 단위 특징비교는 국부적 비교는 가능 하나 서명이 가지는 구조적 지식의 활용이 떨어지는 제약이 있다. 그리고 분절 단위 특징비교는 서명을 분할한 후 대응 하는 분절 단위로 비교하는 것으로 분절 간에는 국부적 또 는 통계적 모델의 사용이 가능하다. 하지만 여기에도 일관 성 있는 서명분할의 어려움은 여전히 존재한다[2-4].
일반적으로 서명을 검증하기 위해서는 참조서명과 입력 되는 서명간의 거리를 계산하여 이용한다. 특히 영상으로 표 현되는 서명에서는 히스토그램(histogram) 사이의 거리를 계산하여 그 유사성을 찾는다[5]. 히스토그램은 영상 내 명 암도의 빈도를 나타낸 도표로 패턴분류나 군집화, 영상추출 등에 널리 이용되고 있다. 히스토그램 사이의 유사성을 측정 하기 위해 벡터나 확률함수에 기반을 둔 접근법이 정의되고 있다[6-10]. 벡터 접근법은 히스토그램을 고정된 차원의 벡 터로 취급하는 것으로 city-block(L1-norm), Euclidean(L2-norm)의 거리가 있으며, 주로 색인 (indexing)이나 추출에 이용된다. 확률적 접근법은 히스토그 램을 확률밀도함수의 경험적 판단을 위한 기준으로 이용하 며, 거리의 측정을 두 확률밀도함수 사이의 중첩을 측정하는 것으로 간주하는 방법이다[7]. Bhattacharyya 거리나 Kullback-Leibler(K-L) 거리가 있다. 한편 히스토그램 사이 의 거리를 측정하는 형태에 따라서는 공칭값(nominal val- ue), 순서값(ordinal value), 그리고 법값(modulo value)을 이용하는 측정법이 있다[9]. 먼저 공칭값의 거리는 히스토그 램 내 각 레벨 사이의 일치성을 나타내는 것으로 Bhattacharyya, K-L 등의 거리 척도들이 이러한 속성을 만 족한다. 또한 순서값과 법값의 거리는 레벨 사이의 절대값 차와 환(ring)을 형성한 법값으로 각각 계산된다. 대부분의 영상인식에서는 회백색 명암도와 같은 크기에 따른 순서값 의 거리가 주로 이용되고 있다[9]. 하지만 이러한 방법들에 서는 레벨의 증가에 따라 비례한 거리계산 시간이 요구되며, 또한 레벨분포에 따라 거리측정의 정확성에 한계가 있다.
한편 기하학적 패턴이나 모양의 정합과 분석은 컴퓨터 비전이나 인식 등의 분야에서 중요하게 이용된다[10]. 서명 인식도 모양이나 형태 등을 분석하여 디지털화한 시스템으 로 다양한 특징을 추출함으로써 수행될 수 있다. 즉, 서명이 가지는 모양을 바탕으로 이루어지는 인식 과정을 살펴보면 정합, 식별, 명명의 단계로 구성된다[3]. 이를 위해 모양을 가지는 서명 사이의 거리, 방향, 체적, 면적 등의 파라미터 들을 측정하여 이용하고 있다. 일반적으로 모양을 이용한 인식은 컴퓨터로 하여금 예측가능하며 개략적이 스타일을 검출할 수 있도록 하는 것이다. 하지만 인식을 위한 정보의 처리는 복잡하여 처리시간이 오래 걸리는 제약이 있다.
이러한 모양을 이용한 서명영상의 인식방법에는 특징기 반과 영역기반 방법이 있다. 특징기반 방법은 영상들로부터 추출된 특징에 바탕을 두며, 영역기반 방법은 영상의 전체 영역을 기반으로 한다[10]. 일반적으로 후자에 바탕을 둔 기 법이 특징검출에 소요되는 비용부담이 적어 널리 이용되며, 주로 거리 계수나 상관성 계수를 척도로 이용한다[7-13].
하지만 거리 계수나 상관성 계수만을 이용하여 유사도를 측 정하는 데는 모양이 가지는 속성을 충분히 반영하지 못하거 나 계산부하가 증가하는 제약은 그대로 내포하고 있다. 따 라서 계산시간을 줄이면서도 모양이 가지는 특징들을 충분 히 반영할 수 있는 효과적인 분류척도의 제시가 요구된다.
본 논문에서는 영상간의 거리에 반비례하고 상관성에 비 례하는 조합형 유사성 척도에 의한 효율적인 서명인식 방법
을 제안한다. 이렇게 하면 공간적 속성인 위치, 크기, 회전 과 같은 기하학적 변화와 통계적 속성인 모양변화에 강건한 서명인식이 가능하다. 특히 서명사이의 유사성을 좀 더 빠 르고 정확하게 반영하기 위하여 이진서명영상의 히스토그 램에 기반을 둔 4 방향의 위치를 고려한 정규상호상관계수 이용한다. 제안된 방법을 20개의 288x288 픽셀 트럭영상과 105개(3인*35개)의 256x256 픽셀의 서명영상을 대상으로 실험하고, 정규상호상관계수와 city-block, Euclidean, 순서 값의 거리를 각각 조합한 결과들을 비교․고찰하였다.
2. 서명 영상사이의 유사성 측정
서명의 검증을 위해서는 참조서명과 입력서명간의 유사 성을 비교하여야 한다. 유사성을 비교하는 방법으로 특징기 반 방법은 영상들로부터 추출될 수 있는 두드러진 구조들을 이용하며, 영역기반 방법은 영상의 전체 영역을 대상으로 특징의 검출보다는 오히려 특징의 정합에 주안점을 둔다.
일반적으로 널리 이용되고 있는 영역기반 방법에 의한 인식 은 참조영상과 입력영상간의 거리나 상관성을 유사성의 척 도로 이용하고 있다[1-4].
한편 거리는 비교대상 영상간의 상이성 정도를 나타내는 것으로 그 값이 클수록 유사성은 떨어지므로 비유사성 계수 이다. 하지만 상관성은 인식대상 영상간의 통계적 상관도를 나타내는 것으로 그 값이 클수록 유사성이 증가함으로 유사 성 계수이다. 거리계수에 바탕을 둔 유사성 비교는 계산 부 하는 적으나 구성성분에 대한 비교가 불가능하며, 대상 영 상간의 평균값 사이에 차이가 심할 경우 분류오차가 크다.
하지만 유사성 계수는 구성성분의 비교도 가능하며, 지역독 립성(location-free)과 척도독립성(scale-free)이 있으나 계 산 부하가 큰 제약이 있다. 본 연구에서는 거리계수와 유사 성 계수가 가지는 특징을 결합한 조합형 유사성 척도를 제 안한다.
2.1 히스토그램 사이의 거리측정
비유사성의 비교를 위한 각 서명영상의 히스토그램간 거 리측정에는 공칭값, 순서값, 그리고 법값을 이용하는 방법이 있으며, 이들 각각의 계산 복잡도는 명암도 레벨 수 b에 따 라 O(b), O(b), O(b2)를 가진다. 특히 공칭값의 측정법에서 는 히스토그램 상의 레벨 사이에 특별한 순서가 고려되지 않으나 순서값과 법값의 측정법에서는 순서가 고려된다 [7-10].
공칭값의 측정법는 두 히스토그램 사이의 거리를 구할 때, 레벨들이 서로 동일한 순서를 유지하는 한 출력에 영향 을 미치지 않는 뒤섞임 불변의 속성을 만족하지만, 순서값 이나 법값의 측정법은 이 속성이 만족되지 않는다[1]. 일반 적으로 2개 레벨 와 ′ 사이의 차이로 공칭값, 순서값, 법 값 각각의 거리는 다음 식 (1), (2), (3)와 같이 정의된다.
nominal : ′ i f ′
(1) ordinal : or′ ′ (2)
modulo : mod′
′ i f ′ ≤
′
(3)
여기서도 b는 레벨수이며, 식 (1)의 공칭값 거리는 2개
레벨사이의 일치여부를 나타내는 것으로 레벨의 치환이 가 능하다. 하지만 식 (2)의 순서값 거리는 순서화되고 치환불 가능하며, 2개 레벨사이의 절대값으로 표현된다. 마지막으 로 식 (3)의 법값 거리는 순환구조인 환을 형성하며 치환불 가능이고, 2개 레벨사이의 내부적인 차이로 표현된다.
한편 벡터나 확률함수에 기반을 둔 히스토그램 사이의 유사성을 측정하기 위한 접근법에는 여러 가지의 거리가 정 의된다. 참조영상 F와 입력영상 G 각각의 히스토그램을 b 차원의 벡터로 가정할 때, 공칭값의 측정법에서는 2개 히스 토그램 와 사이의 거리 로 표준 벡터 norm을 이용한다. 먼저 L1-norm인 city-block 거리
은 식 (4)과 같으며,
(4)
L2-norm인 Euclidean 거리 는 식 (5) 과 같다.
(5)
일반적으로 city-block 거리는 Minkowski 거리에서의 차원이 1차원인 경우로 차원에 따른 개체의 특성이 뚜렷하 게 나타날 경우에 유용하며, Euclidean 거리는 개체의 단편 적인 기하학적 거리를 각각 나타낸 다[7-9].
순서값의 측정법은 레벨 사이의 상관성으로 뒤섞임 불변 의 속성이 없으며, 여기서의 히스토그램은 레벨 가 선형 적으로 증가한다. 순서값의 측정법에서 히스토그램 사이의 거리 or는 식 (6)과 같다.
or =
(6)
식 (6)은 각 명암도 레벨을 위한 차의 사전합의 절대치 합으로 계산되며 3단계로 수행된다. 첫 단계에서는 각 레벨 에 대한 차를 구하고, 다음 단계에서는 각 레벨에 대한 차 의 사전합을 계산하며, 마지막 단계에서는 사전합의 절대치 를 더한다.
일반적으로 거리에 기반을 둔 히스토그램 사이의 유사성 측정은 영상의 공간적 속성을 고려한 것으로 위치, 크기, 회 전과 같은 기하학적 변화를 비교하는데 이용된다.
2.2 정규상관계수를 이용한 유사성 측정
서명 영상간의 유사성을 측정하기 위해서는 거리를 이용 한 비유사도와 상관성을 고려한 유사도가 각각 이용되고 있 다. 하지만 이들 각 방법에도 비교성능이나 분류오차 및 계 산부하 등에서 여전히 한계가 있다. 특히 상관성 계수는 처 리 중에 있는 영상이 다른 영상과 어느 정도의 관계를 가지 는지를 나타내는 상호상관(cross-corelation) 계수와 동일 영상에서 다른 순간에 수집된 샘플들이 서로 어느 정도 상 호관계를 가지는지를 나타내는 자기상관(auto-corelation) 계수로 나누어진다[11-13]. 일반적으로 상관성 계수에 바탕 을 둔 유사성 측정은 어떤 사전지식을 요구하지 않아 공정 감시, 센싱, 공정모델추정, 인식이나 비전분야에 주로 이용 되고 있다.
한편 상관성을 이용한 영상의 분류는 참조영상의 픽셀과 입력영상의 픽셀 각각 사이의 위치를 비교함으로써 가능하
다. 하지만 상관성을 측정하기 위한 유사성 계수로 상호상 관계수는 영상의 에너지가 위치에 따라 변한다면 정합이 되 지 않는 경우가 발생되며, 상관성의 범위가 영상의 크기에 의존하고, 나아가 조명과 같은 선형적인 변화에 매우 민감 한 제약들이 있다. 이러한 제약들을 해결하기 위해 정규상 호상관(normalized cross-correlation : NCC)계수가 제안되 었다[11,12]. NCC는 두 개의 대상 영상사이의 상관성을 평 가하기 위한 척도로 가장 널리 이용되고 있다. 특히 NCC는 -1에서 1사이의 값을 가져 검출이나 판정을 위한 문턱치의 설정이 기존의 상호상관보다 훨씬 용이하다. 하지만 NCC도 주파수 영역으로의 표현이 불가능하여 공간영역에서의 계 산만 가능하다. 특히 NCC는 영상의 크기가 증가함에 따라 계산부하가 기하급수적으로 증가하는 제약이 있다.
NxN의 픽셀크기를 가지는 2차원 참조영상과 입력영상 각각의 번째 픽셀의 명암값 와 가 주어질 때, 축과 축 방향으로 각각 와 번 이동된 번째 픽셀 위치에서 두 영상사이의 NCC는 식 (7)과 같다.
(7)
여기서 와 는 각각 ⋯ 사이의 값을 가지 며, 는 입력영상 의 평균 명암값으로 한 번에 계산 된다. 또한 는 번째 픽셀 위치로 이동된 입력영상 영역 내에서의 참조영상 의 평균 명암값으로 식 (8) 과 같다.
(8) 한편 식 (7)의 NCC에서 분모 항은 참조영상의 영 평균 (zero-mean) 명암값 함수와 이동된 입력영상 의 영 평균 명암값 함수의 분산이다. 특히 정규화로 NCC는 평균값과 표준편차에 의존하는 영상의 밝 기나 대비의 변화에 독립성을 가지는 지역독립성을 가지며, -1에서 1사이의 값을 가져 모양변화에 대한 독립성을 가지 는 척도독립성을 가진다. 따라서 영상의 인식에 NCC를 이 용하면 조명이나 모양 변화에 강건한 결과를 얻을 수 있다.
3. 히스토그램 기반 4차원 상관성 측정 및 조합형 척도
히스토그램은 영상처리와 모양인식 등에서 다양하게 이 용되고 있다[5-8]. 이는 주로 데이터의 통계적 분석에 이용 되어 왔으나 최근에는 신호분류, 영상인식, 그리고 거리계산 등에도 이용되고 있다.
일반적으로 히스토그램의 상관성을 이용한 영상인식은 영상내의 각 명암값을 비롯한 측정의 정량적인 값인 척도의 빈도수에 근거하여 유사성을 비교한다[6-9]. 하지만 기존의 방법들에서는 척도의 증가에 따라 히스토그램의 규모가 기 하급수적으로 증가하여 이에 비례한 유사도 계산시간이 요 구된다. 또한 척도의 분포에 기반을 둔 방법으로 두 히스토 그램의 중첩된 영역만을 고려함으로써 정확한 유사도를 측 정하는데 한계가 있다. 이러한 제약들을 해결하기 위해서 본 연구에서는 이진영상에 기반을 둔 각 대응되는 차원의
위치를 비교하여 유사성을 측정하는 기법을 제안한다. 이진 영상의 이용은 데이터의 량을 줄여 계산시간을 줄이기 위함 이다.
제안된 기법은 위치에 기반을 둔 2개 히스토그램 사이의 NCC를 상관성 척도로 이용하는 것이다. 이를 위해 2차원 행렬로 표현되는 영상으로부터 1차원 벡터로 표현되는 히 스토그램을 생성한다. 식 (9)는 식 (7)을 바탕으로 위치가
개인 2개의 벡터 와 에 대한 NCC인 상관성 계 수 를 나타낸 것이다.
(9)
여기서 와 는 각각 벡터 와 의 평균이며,
는 ⋯ 사이의 값을 가지는 모든 가능한 지연을 나타낸다. 특히 상관성을 극대화하기 위하여 여기에서는 식 (10)과 같이 에 따라 변하는 NCC 중에서 가장 큰 값의 NCC인 을 이용한다.
(10) 한편 영상 상호간의 상관성을 좀 더 정확하게 고려하기 위해서 4개의 방향을 고려한 4차원의 유사성 비교를 제안한 다. 이를 위해 2차원 행렬의 영상을 4방향인 x축, y축, 대각 선 D축, 그리고 역대각선 ID축 각각에 위치한 모든 히스토 그램의 명암값을 합하여 1차원 벡터로 표현한다. 각축에 대 해 표현된 1차원 벡터를 대상으로 서로 일치하는 축 사이의
을 계산한다. 식 (11)은 상호 비교행렬의 유 사성을 측정하기 위해 제안한 4차원 히스토그램 기반 정규 상호상관계수 을 나타낸 것이다.
∙ ∙ ∙
(11) 여기서
는 영상의 행렬에서 x축 상의 각 행에 위치하는 모든 명암값의 빈도수를 합한 1차원 벡터
와 사이의 유사도 이고,
는 y축 상의 각 열에 대한 상호 유사도이다.
또한 는 영상의 행렬에서 각 하단 좌측에서 상단 우측방향으로의 각 대각선상에 위치하는 모든 명암값 의 빈도수를 합한 1차원 벡터 상호간의 유사도
이고, 는 각 하단 우측에서 상단 좌측방향으로의 각 역대각선 상의 유사도이다. 특히
와 는 기본적인 순차적 정렬 상태에 의한 구조를 반영하기 위함이고,
와
는 각각 기울어진 대각 정렬상태에 의한 구 조를 반영하기 위함이다. 따라서 제안된 4차원 히스토그램 기반 NCC 계수를 계산하여 유사성을 측정하면 서명영상 상호간의 작은 구조적 차이도 잘 반영되어 좀 더 효과적인 인식이 가능하다.
본 논문에서는 참조서명과 입력서명 간의 유사성을 비교 하기 위하여 거리에 바탕을 둔 비유사성과 제안된 4차원 히 스토그램 기반 NCC 계수에 바탕을 둔 유사성을 함께 고려
한 조합형 척도를 제안한다. 이는 거리를 이용한 공간적 속 성으로 서명영상의 명암값을 고려하여 위치, 크기, 회전과 같은 기하학적 변화에 강건한 인식성능을 얻기 위함이고, 정규상호상관계수를 이용한 통계적 속성으로 모양변화에 강건한 인식성능을 얻기 위함이다. 특히 히스토그램에 기반 을 둔 4방향의 위치를 고려한 정규상호상관계수의 통계적 속성을 이용함으로써 서명 영상사이의 유사성을 더욱 더 정 확하게 반영한다. 따라서 거리에 반비례하고 상관성 계수에 비례하는 제안된 조합형 유사성 척도 는 식 (12) 과 같이 정의된다.
(12) 여기서 분모 는 식 (4)와 식 (5)에서 각각 정의 된 공칭값에 기반을 둔 거리나 식 (6)에서 정의된 순서값에 기반을 둔 거리를 각각의 최대값으로 나눈 정규화 거리이 다. 또한 분자 는 식 (11)에서 제안된 4차 원 히스토그램 기반 정규상호상관계수이다. 일반적으로 거 리는 0에서 무한대의 값을 가지며, 정규상호상관계수는 -1 에서 1까지의 값을 가진다. 따라서 거리는 각각의 최대값으 로 나누어 0과 1사이의 값으로 정규화 하였다. 결국 식 (12) 의 조합형 척도는 -∞에서 +∞사이의 값을 가지며, 그 값이 클수록 유사성은 증가하게 된다.
4. 실험 및 결과분석
제안된 히스토그램 기반 조합형 유사성 척도를 이용한 인식의 성능을 평가하기 위해 20개의 트럭영상과 105개(3 인*35개)의 서명영상을 대상으로 실험하였다. 실험환경은 펜티엄Ⅳ-3.0G 컴퓨터에서 Matlab 2008로 구현하였다. 특 히 4차원의 히스토그램 기반 정규상호상관계수 계산을 위 해 영상은 그 각각의 평균 명암값을 임계기준으로 하여 이 진화 하였다.
그림 1은 288x288 픽셀의 20개 회백색(gray) 트럭영상들 을 나타낸 것이다. 그림 1에서 보면 전체 영상 크기는 동일 하나 각 영상 내 트럭영상의 고유한 모양, 크기, 위치에는 차이가 있음을 알 수 있다. 특히 트럭영상은 위치에 따라서 도 모양과 크기가 변함을 알 수 있다. 그림 2는 그림 1에서 첫 행 첫 열의 회백색 트럭영상과 그 이진영상을 각각 나타 낸 것이다. 그림 2(a) 트럭영상의 평균 명암값은 10.82이며, 그림 2(b)는 이 값을 임계기준으로 하여 0과 255의 명암값 을 가지는 이진화 영상이다. 특히 그림 2(b)의 이진영상은 288*288 픽셀의 크기를 가져 x축과 y축의 차원은 각각 288 이고, 대각선과 역대각선 축의 차원은 각각 575이다. 4축의 각각에 해당하는 위치에서 255의 명암값을 가지는 픽셀 수 를 계수하여 각 축에 대한 히스토그램을 생성한다. 따라서 참조영상과 입력영상 각각의 회백색 트럭영상의 히스토그 램으로부터 city-block, Euclidean, 순서값의 정규화 거리
을 각각 구하고, 이진영상에 대한 4차원의 히스토 그램을 생성하여 정규상호상관계수 을 구 한 다음, 제안된 조합형 척도 을 계산하여 유사성 을 비교한다.
그림 1. 288x288 픽셀의 20개 트럭영상 Fig. 1. 20-truck images of 288*288 pixels
(a) (b) 그림 2. 회백색 영상(a)과 이진영상(b) Fig. 2. Gray image(a) and its binary image(b) 그림 3(a)은 그림 2의 truck 1을 기준으로 자신을 포함한 20개의 다른 truck들 간의 정규상호상관계수
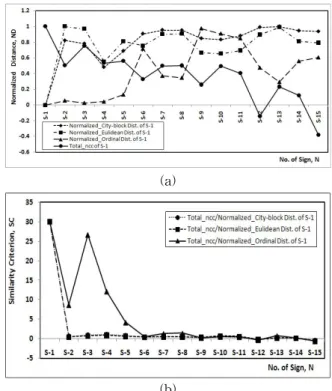
와 city-block, Euclidean, 순서값 각각의 정규화 거리 을 나타낸 것이고, 그림 3(b)은 각 거 리에 대한 제안된 유사성 척도 을 나타낸 것이다.
그림 3(a)에서 truck 1과 20개 truck 각각과의
을 보면, 자신과의 가장 큰 1 값으로부터 truck 2에서 truck 20으로 갈수록 선형적으로 작은 값을 가 짐을 알 수 있다. 이는 그림 1에서 볼 수 있듯이 자기 자신과 는 완벽히 일치함을 보이나 다른 truck들과는 크기, 위치, 모 양 등에서 차이를 보여 상관성이 떨어짐을 나타낸다. 특히 truck 1은 truck 5까지 사이에서는 0.87이상의
을 가져 나머지 truck 6에서 20까지 보다 상대적으로 유사함을 알 수 있다. 한편 truck 1에 대한 city-block, Euclidean, 그리고 순서값 각각의 정규화 거리들 은 유사한 변화특성을 가져 각각의 거리들은 truck 상호간의 상관성을 유사하게 반영한다. 하지만 각각의 거리들은 truck 1에서 truck 9까지와 truck 10에서 truck 20까지 2영역으로 구별된 정규화 거리를 가진다. 이는 그림 1에서 truck 1이 truck 9까지는 유사한 기하학적 속성을 가지나 truck 10부터 는 상대적으로 크기나 위치, 모양 등에서 큰 차이가 있음을
뒷받침한다. 또한 순서값, Euclidean, city-block 거리 순으 로 유사한 속성을 가지는 truck들 사이에서는 작은 값은 가 지나 그렇지 않는 경우에는 큰 값을 가짐을 알 수 있다. 이는 각 영상사이의 상관성이 얻어진 거리 순으로 더욱 더 잘 반 영됨을 보여 주는 것이다. 한편 그림 3(b)의 는 그 림 3(a)의 을 각 로 나눈 것이다.
여기서도 truck 1은 truck 5까지 비교적 큰 값을 가져 상호 유사성이 높으나 truck 6부터는 작은 값을 가져 유사성이 낮음을 알 수 있다. 또한 truck 1 상호간에는 완벽 히 일치하여 유사성 척도가 무한대이나 그림 3(b)에서는 도 식을 위해 편의상 14로 정하였다. 특히 그림 3(b)에서도 그림 3(a)에서처럼 순서값, Euclidean, city-block의 거리 기반 유 사성 척도 순으로 각 truck사이의 상관성은 더욱 더 잘 반영 됨을 알 수 있다. 한편 동일한 truck간의 비교에서도 순서값 의 기반 가 다른 Euclidean이나 city-block의 기반 에 비해 훨씬 큰 값 을 가져 좀 더 신뢰성 높은 유사도 비교가 가능함을 알 수 있 다. 하지만 Euclidean과 city-block의 기반
의 변화는 적으며, city-block의 경우, truck 1 자 신 외에는 거의 거의 변화가 없어 인식의 정확도가 떨어짐을 알 수 있다. 한편 그림 3(a)에서처럼 단순히
나 둘 중의 하나만을 이용하는 것은 영상의 상호 통계적 속성이나 공간적 속성만을 반영하 는 것으로 이는 기하학적 특징이나 명암값 중 어느 하나만을 이용한 유사성 비교이다. 하지만 그림 3(b)에서처럼 이들 두 속성을 동시에 고려한 제안된 유사성 척도 을 이용 하면 좀 더 정확한 유사성 비교가 가능하여 인식성능이 개선 될 수 있음을 알 수 있다. 따라서 순서값 기반의 제안된 유사 성 척도가 가장 정확한 인식성능을 가짐을 알 수 있다.
(a)
(b)
그림 3. Truck 1에 대한 정규화 거리(a) 및 유사성 척도(b) Fig. 3. Normalized distance(a) and similarity criterion(b)
to truck 1.
그림 4(a)와 그림 4(b)는 20개의 truck 영상 상호간의 평 균 정규상호상관계수 와 평균 정규화 거리
및 평균 유사성 척도 을 각각 나타낸 것이다. 그림 4(a)에서 평균 는 자신을 제 외한 19개의 다른 truck 간의 값을 나타낸 것으로 truck 10 과 11이 가장 큰 0.82의 값을 가지며, 그것을 중심으로 양방 향으로 감소함을 알 수 있으며, truck 1과 truck 20에서는 각각 0.55와 0.59의 값을 가진다. 이는 그림 1에서 볼 수 있 듯이 20개의 truck 중에서 가운데에 위치한 truck 10과 11 이 가장 많은 공통된 기하학적 속성을 가짐을 의미한다. 또 한 city-block, Euclidean, 그리고 순서값 각각의 평균
들에서는 서로 유사한 분포특성을 보이나 상기의 순으로 작은 값을 가짐도 알 수 있다. 이러한 특성으로 단 순히 평균 로만 truck 상호간의 유사성 비교가 어 려워 영상인식에 한계가 있음을 알 수 있다. 한편 그림 4(b) 의 평균 에서는 반대로 순서값, Euclidean, city-block의 평균 기반 평균 순으로 큰 값을 가짐을 알 수 있다. 이는 각 truck의 평균
을 기준으로 상기 순으로 평균 는 작은 값을 가지기 때문이다. 여기에서도 그림 3의 truck 1에 대한 결과 고찰에서처럼 동일한 truck 각각에 대해서 순서값에 기반을 둔 평균 가 가장 큰 값을 가지며, 또한 전체적으로는 가장 큰 값의 변화를 보여 Euclidean이 나 city-block에 비해 높은 유사성 비교가 가능함을 알 수 있다.
(a)
(b)
그림 4. 20개 Truck 각각에 대한 평균 정규화 거리(a) 및 유사성 척도(b)
Fig. 4. Mean of normalized distance(a) and similarity criterion(b) to 20-truck each.
그림 5. 256*256 픽셀의 105개 회백색 서명영상 Fig. 5. 105 gray sign images of 256*256 pixels 그림 5는 3인의 각자 35개 서명으로 구성된 105개 회백 색 영상들을 나타낸 것이다. 그림 5에서 서명 각각의 크기 는 256*256 픽셀로 동일하나 동일인의 서명영상 내에서도 서명의 모양, 크기, 위치, 그리고 회전 등에서 차이가 있으 며, 각자의 서명 간에도 동일한 차이가 있음을 알 수 있다.
그림 6(a)은 그림 5에서 3인 각자의 서명으로부터 첫 행의 서명만을 모은 15개의 서명을 대표로 나타낸 것이며, 앞으 로 본문에서 서술할 내용은 이를 기준으로 실험한 결과들이 다. 그림 6(b)은 그림 6(a)의 첫 행 첫 열 서명의 이진영상 을 보여준 것으로, 이 영상의 평균 명암값은 249로 이 값을 임계기준으로 하여 0과 255의 명암값을 가지는 이진영상을 생성하였다. 이진영상의 생성은 4차원 히스토그램 기반 정 규상호상관계수를 구하는 계산 부하를 줄이기 위함이다. 또 한 그림 6(c)은 정규화 거리를 구하기 위해 사용된 회백색 영상의 히스토그램을 도시한 것이다. 여기서 서명영상은 75 부터 130사이의 명암값에 각각 20개 이상의 빈도수가 분포 하며, 240부터 255까지에 다시 20개 이상 분포하고, 특히 명암값 249이상에 전체 총 명암값 빈도수 65,536개 중 62,010개가 분포하여 서명영상의 대다수는 백색배경으로 이 루어짐을 알 수 있다.
(a)
(b) (c)
그림 6. 15개 서명영상(a), 첫 번째 서명의 이진영상(b), 그리고 그 히스토그램(c)
Fig. 6. 15 sign images(a), binary image of 1st sign(b), and its histogram(c)
한편 그림 7은 그림 6(a)의 15개 서명 중에서 첫 행 첫 열의 서명 s-1을 기준으로 자신을 포함한 15개의 다른 서 명 간 정규상호상관계수 와 city-block, Euclidean, 그리고 순서값 각각의 정규화 거리 및 유사성 척도 을 각각 나타낸 것이다. 먼저 그 림 7(a)에서 서명 s-1과 15개 서명 각각과의
을 보면, 자신과의 가장 큰 값인 1로부터 s-2부터 s-15로 갈수록 점차 작은 값을 가짐을 알 수 있다.
이는 그림 6에서 살펴본 것처럼 자신과는 완전히 일치하며, s-2에서 s-5까지는 동일인의 서명으로 상대적으로 유사하 고, s-6에서 s-10이나 s-11에서 s-15로 갈수록 다른 사람 의 서명으로 유사성이 감소함을 나타낸다. 특히 s-1과 s-12 및 s-15 사이에는 음수의 값을 가진다. 이 는 식 (11)에서 알 수 있듯이 4개축 각각의 에 의한 의 계산에서 1개 또는 3개축의
가 음수인 경우로, 각 서명 상호간 대응되는 축의 히스토그램 분포가 서로 대응됨을 의미한다. 또한 s-1 에 대한 의 변화특성을 살펴보면, city-block과 Euclidean의 는 서로 유사하나 순서값의
는 차이가 있음을 알 수 있다. 특히 city-block과 Euclidean의 을 살펴보면, s-1 자신을 제외한 다 른 14개 서명 간에 큰 값을 가지며 변화도 적음을 알 수 있 다. 하지만 순서값의 에서는 s-1에서 s-5까지는 작은 값을 가지며, s-6부터 s-15까지는 큰 값을 가짐을 알 수 있다. 이는 순서값의 가 city-block과 Euclidean의 보다 서명 상호간의 상관성을 더욱 더 잘 반영함을 의미한다. 다음의 그림 7(b) 역시 그림 7(a)
의 을 각 로 나눈 유사성 척도
을 나타낸 것이다. 여기에서도 s-1은 s-5까지 큰
값을 가져 상호 유사성이 높으나 s-6부터는 작 은 값을 가져 유사성이 낮음을 알 수 있다. 또한 s-1 자신 간에는 완전한 일치로 가 무한대이나 그림 7(b)에 서는 도시의 편의상 30으로 하였으며, s-12와 s-15에서는 음수값을 가진다. 이 또한 그림 7(a)의 가 음수이기 때문이다. 특히 그림 7(a)의 고찰에서처럼 순서값 기반 은 city-block이나 Euclidean 기반
보다 각 서명사이의 유사성을 더욱 더 잘 반영함 을 알 수 있다. 한편 나머지 14개의 서명 각각을 대상으로 동일한 실험을 행한 결과, 그림 7에서처럼 순서값의
가 city-block과 Euclidean의 보다 서 명 상호간의 상관성을 더욱 더 잘 반영하며, 제안된 유사성 척도 의 이용이 단순히 정규상호상관계수
나 정규화 거리 각각만의 이용 보다도 좀 더 정확한 인식이 가능함을 알 수 있었다. 따라 서 서명영상에서도 그림 3의 truck 영상에서 살펴본 것처럼 순서값 기반의 제안된 유사성 척도를 이용하면 정확한 서명 인식이 가능함을 확인할 수 있다.
(a)
(b)
그림 7. 서명 s-1에 대한 정규화 거리(a) 및 유사성 척도(b) Fig. 7. Normalized distance(a) and similarity criterion(b)
to sign s-1.
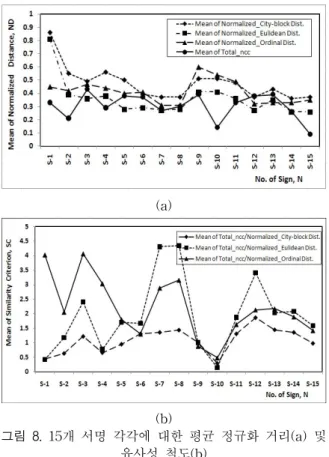
그림 8(a)와 그림 8(b)는 15개의 서명영상 상호간의 평균 정규상호상관계수 와 평균 정규화 거리
및 평균 유사성 척도 을 각각 나타낸 것이다. 그림 8(a)에서 평균 는 자신을 제 외한 14개의 다른 서명간의 값을 나타낸 것으로 s-3이 가 장 큰 0.43의 값을 가지며, s-15가 가장 작은 0.09의 값을 가진다. 이는 그림 6(a)에서 볼 수 있듯이 15개의 서명 중에 서 s-3이 가장 공통된 기하학적 속성이 많고 s-15가 가장 적음을 의미한다. 또한 city-block, Euclidean, 그리고 순서