공공 기상데이터와 기계학습 모델을 이용한 토양수분 예측
장영빈*⋅장익훈⋅최영찬1)
서울대학교 농생명과학대학 농경제사회학부 지역정보 전공 (2019년 12월 10일 접수; 2020년 2월 12일 수정; 2020년 3월 16일 수락)
Prediction of Soil Moisture with Open Source Weather Data and Machine Learning Algorithms
Young-bin Jang
*, Ik-hoon Jang, Young-chan Choe
Program in Regional Information, Department of Agricultural Economics and Rural Development, College of Agriculture and Life Sciences, Seoul National University, 1 Gwanak-ro, Gwanak-gu, Seoul 08826, Korea
(Received December 10, 2019; Revised February 12, 2020; Accepted March 16, 2020)
ABSTRACT
As one of the essential resources in the agricultural process, soil moisture has been carefully managed by predicting future changes and deficits. In recent years, statistics and machine learning based approach to predict soil moisture has been preferred in academia for its generalizability and ease of use in the field. However, little is known that machine learning based soil moisture prediction is applicable in the situation of South Korea. In this sense, this paper aims to examine 1) whether publicly available weather data generated in South Korea has sufficient quality to predict soil moisture, 2) which machine learning algorithm would perform best in the situation of South Korea, and 3) whether a single machine learning model could be generally applicable in various regions. We used various machine learning methods such as Support Vector Machines (SVM), Random Forest (RF), Extremely Randomized Trees (ET), Gradient Boosting Machines (GBM), and Deep Feedforward Network (DFN) to predict future soil moisture in Andong, Boseong, Cheolwon, Suncheon region with open source weather data. As a result, GBM model showed the lowest prediction error in every data set we used (R squared: 0.96, RMSE: 1.8). Furthermore, GBM showed the lowest variance of prediction error between regions which indicates it has the highest generalizability.
Key words: Soil moisture prediction, Machine learning, Agricultural big data, Gradient boosting machines, Publicly available data in agriculture
I. 서 론
토양 수분은 농작물 생장에 직접적으로 관여하는 중요한 변수로 작물의 정상적 생장을 위해서는 필수적
으로 관리되어야 한다. 이를 위해서는 미래의 토양 수 분을 정확히 예측하고 부족 혹은 과잉에 대처하는 것 이 필요하다. 하지만 토양 수분은 기상, 토양 특성, 작 물 등의 복잡한 관계에 의해 비선형적으로 변화하기
* Corresponding Author : Young-bin Jang ([email protected])
DOI: 10.5532/KJAFM.2020.22.1.1
ⓒ Author(s) 2020. CC Attribution 3.0 License.
때문에 이러한 복잡한 변화를 예측을 위한 다양한 연 구가 진행되어왔다.
과거 연구들에서는 프로세스 기반 모델(process- based model)을 이용한 접근법과 통계 혹은 기계학습 모델을 이용한 접근법이 활용하여 토양수분을 예측하 였다. 프로세스 기반 모델을 이용한 접근법은 기후와 지형, 외부 수원 등 토양수분의 이동에 영향을 주는 변수들과 토양수분에 대한 한 개 이상의 함수관계로 토양 수분이 이동하는 시스템을 표현하고 이를 통해 미래의 토양 수분을 예측하는 방법으로 초기의 토양수 분 예측 연구에서 주로 활용되었다; SWAP model (Van Dam et al., 1997), Community Land Model (National Center for Atmospheric Research, 2004), SAC-SMA model (National Weather Service, 1976), Rodrigueze-Iturbe model (Laio et al., 2001). 하지만 이러한 모델들은 식생, 토성, 토양의 표면 저항 등 상 당히 많은, 구체적은 변수들이 필요하고, 환경이 이질 적인 모든 지점들에 대해 별개의 모델을 만들고 파라 미터들을 교정(calibration)해야 하는 단점이 있다 (Allen et al., 1998; Shin et al., 2018).
이에 대한 대안으로 최근에는 Linear regression (Prakash et al., 2018), Support vector machines (Gill
et al., 2007), Artificial neural network (Song et al.,
2008; Cai et al., 2019) 등 다양한 통계, 기계학습 방법 론을 활용한 토양수분 예측 연구가 진행되었다. Gillet al.(2007) 은 과거 토양수분과 기온, 습도, 평균 일
사, 지표면 온도 등 핵심적인 변수만을 활용하여 미래 의 토양수분량을 예측하는 Support Vector Machine (SVM), Artificial neural network (ANN) 모델을 학습 하였고 SVM의 예측 성능이 가장 뛰어나다는 것을 확 인했다(R2 0.89, RMSE 4.05). 한편 Cai et al.(2019)의 연구에서는 최근 가장 뛰어난 성능을 보이는 기계학습 모델인 심층학습 기법을 이용하여 기상과 토양 특성이 다른 세 지역(중국의 연경, 순이, 다싱)의 토양수분을 예측하는 모델을 만들었고 세 지역 모두에서 R2 0.96 이상의 높은 설명력을 보여 이질적인 환경에서도 동일 하게 활용 가능한 모델을 만들 수 있음을 보였다.한편 국내에서는 통계, 기계학습 방법을 이용한 토 양수분 예측 연구가 상당히 부족한 실정이다. Choi et
al.(2008)은 광릉 산림유역의 토양수분데이터를 이용
한 시계열 모형을 만든 연구가 있었지만 학습된 모델 이 새로운 데이터에서는 어떠한 설명력을 가질지 검증 이 되지 않았으며 한정된 지역의 데이터만을 활용하여일반적으로 적용 가능한 모델이라고 보기는 어렵다는 한계점이 있다. 기계학습 모델들은 활용되는 입력데이 터의 특성과 품질에 따라 각 모델의 예측 성능이 상이 하다. 국내의 기상 조건과 토양 조건, 식생이 해외와 다르기 때문에 해외의 연구를 그대로 받아들이는 것은 적절하지 않으며 국내의 기상 데이터를 이용한 검증이 필요하다.
이러한 점에서, 본 연구는 국내 공공기상데이터를 이용하여 통계, 기계학습 방법론에 기반한 토양수분 예측 모델을 만들고 이의 성능을 검증하고자 하였다.
더 구체적으로는, 전날의 토양수분 및 기상정보를 이 용하여 다음날의 평균 토양수분을 예측하는 Random forest (RF), Extremely randomized tree (ET), Gradient boosted machine (GBM), Support vector machine (SVM), Deeplearning (DL)모델을 만들고 모델 별로 성능을 비교함과 동시에 다양한 Feature set, 지역에 따른 예측 성능의 변화를 확인함으로써 국내 다양한 지역에 동시에 적용 가능한 토양 수분 예측 모델을 개발하고자 한다.
II. 재료 및 방법
2.1. 대상지역 및 토양수분 자료
본 연구는 기상자료개방 포털에서 제공하는 농업기 상관측자료의 토양수분 데이터를 활용하였다(https://
data.kma.go.kr/data/grnd/selectAgrRltmList.do?pgm No=72). 농업기상관측자료는 보성, 순천, 안동, 철원, 전주, 수원 등 11개 지역에 위치한 농림기상센터에서 농업기상관측장비(AAOS, Automated Agriculture Observing System)을 이용해 관측한 토양 수분자료를 제공한다. 이 중 토양수분 정보는 10cm, 20cm, 30cm, 50cm 깊이마다 설치된 고주파 정전용량식 토양수분 센서에 의해 측정되며 토양의 단위 부피 당 물의 부피 (%)의 값으로 기록되었다. 농업기상관측자료는 농경 지와 비슷한 환경에 설치된 기상관측 시설과 각 지역 을 대표하는 작물이 시험 제배 되는 토지에 설치된 토양 수분 센서를 통해 측정한 데이터를 기록하였다.
이는 실제 농업 현장에서 생성되는 데이터와 유사하여 본 연구의 현장 적용 가능성을 높이는 효과가 있다.
다양한 깊이의 토양수분 변수 중 본 연구에서는 10cm 깊이의 토양수분을 예측 대상으로 선택하였다.
2014년 농업기상센터 점검 당시 순천, 안동, 철원, 보성 지역 관측소가 관측장비의 설치 및 관리 상태가
우수, 양호하여(Choi et al., 2015) 위 네 개의 지역의 데이터를 활용하였다. 활용 데이터에는 상당히 많은 이상치와 결측치가 포함되어 있어 활용 기간을 결정하 기에 앞서 단계에 걸쳐 이들을 처리하였다. 가장 먼저 전국적으로 관측 장비를 교체한 2011년 이후의 데이 터를 검토하고 월별 토양수분의 평균과 분산, 최대 최 소값이 이상치를 보인 월들의 데이터를 제외하였다. 그리고 낮은 기온으로 인해 이상치가 많고 농업에서 중요하지 않은 1월과 2월의 데이터를 제외하였다. 그 리하여 본 연구는 순천관측소의 2014년 3월부터 2018 년 10월까지(1469일), 보성관측소의 2015년 3월부터 2018년 12월까지(1482일), 철원지역의 2014년 3월부 터 2017년 12월(1224일), 안동지역은 2016년 10월부 터 2018년 12월까지(962일)로 각 지역별 활용 기간을 정하였다.
2.2. 기상자료
본 연구에서는 기상자료개방 포털에서 제공하는 농 업기상관측자료와 종관기상관측자료(https://data.kma.
go.kr/data/grnd/selectAsosRltmList.do?pgmNo=36) 기상변수를 활용하였다. 종관기상관측 자료는 전국 102 지점에서 개 관측소에서 종관기상관측장비(ASOS, Automated Synoptic Observing System)를 이용해 30 분에서 한시간 단위로 측정한 지면온도, 지중온도 (5cm, 10cm, 20cm, 30cm), 기상현상번호, 기온, 강수 량, 풍속, 풍향, 습도, 증기압, 이슬점, 현지기압, 해면 기압, 일조량, 일사량, 적설량, 전운량, 운형, 지면상태 등의 기상 정보를 제공한다. 각 관측소 별로 데이터의 제공기간이 다르지만 활용 대상 지역의 활용 기간 데 이터는 온전히 존재하여 추가적인 변수의 누락 없이 활용할 수 있었다.
농업기상관측 자료의 경우 습도(0.5m, 1.5m), 정시 기온(0.5m, 1.5m, 4.0m), 풍속(1.5m, 4.0m), 지면온도, 초상온도, 지중온도(0.05cm - 5.0m) 누적 순복사, 누 적 전천복사, 누적 반사복사, 조도, 지하수위 등의 기 상 변수들을 제공했다.
정시 기온과 풍속, 습도와 관련된 변수의 경우 양쪽 의 자료에서 제공하였는데 두 기상정보를 동시에 활용 하기 위해 풍속과 습도의 경우 종합기상관측자료의 데 이터를 활용하였고 정시기온의 경우 농업기상관측 자 료의 데이터를 활용하였다. 농업기상센터와 종관기상 관측소 간의 위치 차이에 의해 양쪽 자료에서 제공하 는 값 간에 미세한 차이가 있었지만 농업기상관측자료
에서 제공하는 풍속과 습도의 경우 결측치가 상당히 많아 사용이 불가하여 종관기상관측 자료의 값을 활용 하였다.
2.3. 투입변수 선정
다음날 토양수분 예측 시 필요한 투입변수로 전날 동일 깊이의 토양수분 기상변수를 기본 투입 변수 (Feature set 1)로 지정하였다. 전날 동일 깊이와 다른 깊이의 토양수분의 경우 농업기상관측 자료에서 시간 별로 제공하는 10cm 토양수분 측정값 중 해당 날짜의 0시 기준 토양 수분량(Soil moisture 10cm)을 일 단위 변수로 활용하였고 기상변수의 경우 기존 문헌들에서 토양수분을 예측 시 활용한 습도(Humidity), 기온(Air temperature), 온도(Temperature), 풍속(Wind speed), 증기압(Vapor pressure), 이슬점(Dew point), 대기압 (Pressure), 강수량(precipitation), 일조량(Sunshine), 일사량(Insolation), 누적 반사복사(Reflected radiation), 누적 순복사(Net radiation), 누적 전천복사(Global radiation)의 변수를 활용하였다(National Weather Service, 1976; Van Dam et al., 1997; Allen et al., 1998; Oleson et al., 2004; Laio et al., 2001; Gill et
al., 2007; Song et al., 2008; Prakash et al., 2018;
Cai et al., 2019).
기본 투입 변수 이외에도 다양한 변수 세트를 구성 하고 변수 세트별로 예측 성능이 어떻게 달라지는지를 확인했다. 투입변수의 선정은 기계학습 모델의 설명력 에도 큰 영향을 미치지만 실제 농업 현장에서 투입변 수들을 수집하기 위해 필요한 비용과도 큰 관련이 있 으므로 모델의 설명력과 투입변수 획득에 필요한 비용 을 고려하여 최적의 변수들을 선택하는 것이 중요하다. 다른 깊이의 정보가 있을 때 예측성능이 얼마나 달 라지는 확인하기 위해 두번째 변수 세트는 기본 변수 이외에 다른 깊이의 토양수분의 정보를 추가하였다 (Feature set 2). 그러기 위해 농업기상관측 자료에서 시간별로 제공하는 20cm(Soil moisture 20cm), 30cm (Soil moisture 30cm), 50cm(Soil moisture 50cm) 깊 이의 토양수분 변수의 전날 0시 기준 토양수분량을 일단위 변수로 활용하여 투입변수에 추가하였다.
다음 변수 세트는 기본 투입 변수 이외에 예측시점 이전의 토양 수분변수와 강수량에 관련된 파생변수를 추가하여 모델이 토양수분과 강수량에 대해 더 풍부한 정보를 학습할 수 있게 구성하였다(Feature set 3). 예 측시점 이전의 토양 수분 변수는 10일 이전부터 1일
전까지의 일평균 토양 수분에 대한 변수(Soil moisture 10cm/20cm/30cm/50cm lag1- lag10)를 선정하여 10 일전부터 예측 시점까지의 토양수분 정보를 변수 세트 에 모두 포함시켰다. 강수량 관련 파생 변수의 경우 2일 누적 강수량(2days’ precipitation), 연속 강수일 (Consecutive precipitation days), 연속 비강수일 (Consecutive non-precipitation days), 비가 그친 시각 (Last rain time)의 변수를 추가하여 현재 강수 상태에 대한 추가적인 정보를 추가한 변수 세트를 구성하였다.
데이터가 1년 이상 축적되었을 경우를 과거 같은 월의 데이터가 모델의 설명력을 더 올릴 수 있는지를 확인하기 위해 네번째 변수 세트(Feature set 4)의 경우 지역/월별 토양 수분과 강수량의 통계량을 추가하였 다. 각 지역별로 과거까지의 해당 월 토양수분량과 강 수량의 평균(Mean Soil moisture 10cm/20cm/30cm/
50cm by month), 최대값(Maximum Soil moisture 10cm/20cm/30cm/50cm by month), 최소값(Minimum Soil moisture 10cm/20cm/30cm/50cm by month), 분 산(Variance of Soil moisture 10cm/20cm/30cm/50cm by month)을 추가하였다.
마지막 변수 세트로는 변수 중요도(Feature importance) 가 높은 변수들 만을 선정하여 투입변수로 활용하였 다. 투입변수의 수가 일정 수준 이상으로 커지면 모델 이 학습이 잘 안되거나 예측성능이 떨어지는 차원의 저주(curse of dimension)이라는 현상이 발생하기 때 문에 중요한 변수들만을 이용해 모델을 만들 시 더 좋은 예측 성능을 가질 수 있다(Pavlenko, 2003). 대다 수의 연구에서 사용되는 RF와 GBM과 같은 기계학습 모델은 결과 변수를 예측하는 대에 투입변수가 얼마나 기여하는지에 따라 투입변수에 변수 중요도라는 지표 를 부여한다. 그래서 변수 중요도가 높은 변수들만을 선별하여 변수 세트를 구성하였다(Feature set 5). 구체 적인 내용은 3.결과 부분에 기술하였다.
모든 변수들은 각기 다른 단위로 측정 혹은 생성되 었는데 이러한 단위 혹은 변수 범위의 차이는 모델 내에서 변수가 미치는 영향에 왜곡을 일으킬 수 있다. 이 문제를 해결하기 위해 변수들의 원본 값( xi)을 사 용하는 대신 해당 변수의 평균(mean( xi
))을 뺀 후 표
준편차(standard deviation( xi))로 나누어 정규화한
값( )을 모델의 투입변수로 활용하였다.(Eq. 1)
각 모델들은 위의 수식과 같이 정규화가 된 투입변 수들의 변수 세트를 투입변수로 하여 다음날의 평균 토양수분(y)을 예측하는 예측치( )를 결과변수로 내 는 함수이다.
(Eq. 2)
2.4. 기계학습 알고리즘
다음날의 토양수분량을 예측하는 대에 활용될 모델 들은 기존 연구에서 자주 사용된 모델이나 더 나은 예측 성능을 보일 것으로 예상되는 모델들을 선택했 다. 그리하여 많은 선행 연구에서 가장 높은 성능을 보인 Support vector machines (Gill et al., 2007)과 일반적으로 많이 활용되는 모델인 Random forest (RF), RF와 유사하지만 무작위성을 극대화한 Extremely randomized tree (ET), 많은 분야에서 가장 높은 예측 성능을 보이는 Gradient boosted machine (GBM), Deeplearning (DL)모델을 이용해 토양수분 예측 모델 을 구축했다. 각 모델들의 예측성능을 극대화되었을 시의 성능을 비교하기 위해 각 모델의 성능을 극대화 하는 하이퍼파라미터(Hyper parameter)들을 탐색하고 최적의 값을 선택하였다.
모든 모델은 python 언어를 이용해 코딩 되었다.
Random Forest와 Extremely Randomized Tree, Gradient Boosted Machine, Support Vector Machine 은 Scikit learn (version 0.21.3)이라는 python 라이브 러리를 이용해 구현했고 Deep Feedforward Network 의 경우 tensorflow (version 1.14.0)를 활용했다.
2.4.1. Support Vector Machines (SVM)
SVM이란 Structural risk minimization 기준을 적 용해 결과변수를 판별 혹은 회귀하는 초평면인 Support Vector을 찾는 기계학습 알고리즘이다. 연속형 결과 변수를 예측하는 SVM을 Support Vector Regression 이라고 하며 일반적으로 epsilon SV Regression (Vapnik, 1997)을 사용한다. epsilon SV Regression은 Support Vector와 결과변수와의 거리가 미리 정해둔 허용 가능 오차의 최대값인 e를 넘지 않으면서도 weight의 노름(e.g., l2 norm)을 최소화하는 Support Vector를 찾고 이를 이용해 결과변수를 예측한다. 흔 히 변수들 간의 복잡한 비선형관계를 포착하기 위해 kernel을 이용해 입력변수의 공간을 변형한 kernel
SVM을 사용한다. SVM은 다양한 예측 연구에서 사용 되어왔고 토양 수분예측연구에서도 상당히 뛰어난 예 측 성능을 보여 국내의 데이터를 이용하여 검증해보고 자 한다. 모델의 성능을 최대화하기 위해 hyper parameter 인 epsilon과 C 그리고 활용할 kernel function을 tuning하였다.
2.4.2. Random Forest (RF)
Random forest는 여러 개의 약한 모델(weak model) 을 학습한 후 이들을 종합한 강한 모델(strong model) 로 예측 결과를 내는 Ensemble learning 중 Bagging 방법을 기반으로 한 기계학습 알고리즘이다. Bagging 은 각 약한 학습기를 학습할 데이터를 원본데이터에서 무작위로 추출하여 학습하고, 약한 학습기의 예측결과 를 평균 내어 최종 예측 결과로 활용하는 방법이다. 이 중 가장 널리 활용되는 모델인 Random forest (Breiman, 2001)는 Decision tree (DT)를 약한 모델로 사용하며 각 약한 학습기에서 활용할 변수 또한 모든 변수 중에 랜덤하게 추출하여 사용하는 모델이다. 여기서 활용된 DT모델은 투입변수 내에 존재하는 규칙들로 표본들 을 그룹으로 구분하고 각 그룹에 대해 예측 결과 값을 할당하는 모델로 현재 분리된 그룹들 중 결과변수를 가장 잘 구분하는 분기점(split)을 찾아 그룹을 순차적 으로 분리함으로써 모델을 학습한다. DT 모델의 경우 실제값과 예측값 간 높은 분산을 보이는 것이 한계로 지적되는데 RF 모델은 여러 개의 독립적인 DT들을 평균냄으로써 분산을 줄이고 예측성능을 향상시켰다.
RF 또한 다양한 분야에서 적용이 되고 있으며 종종 토양 수분 예측 연구에서도 활용되었다. RF 모델 또한 예측 성능을 최대화하기 위해 split 하기 위한 최소 샘플 수(min sample split), 트리의 최대 개수(n_estimators), 활용할 변수의 개수(max_features)를 튜닝하였다.
2.4.3. Extremely Randomized Trees (ET) Extremely Randomized Tree (ET)는 RF와 유사한 Bagging 기반 Ensemble 모델이다. 유일한 차이점은 RF의 경우 약한 학습기로 사용하는 DT에서 규칙(split) 을 만들 시 모든 변수에 대해 결과변수를 가장 잘 차별 화하는 지점을 탐색하지만 ET의 경우 랜덤하게 split 할 후보 지점을 지정한 후 이중 예측 성능을 가장 많이 향상시키는 split을 선택한다는 점이다. 이렇게 랜덤하 게 split 지점이 생성된 DT모델은 단일 모델로서는 예
측 성능을 극대화하지는 못할 수 있지만 여러 개의 모델을 앙상블 했을 때는 더 충분히 탐색(exploration) 하는 효과를 가져 더 나은 예측성능을 보일 수 있고, 실제로 여러 형태의 데이터셋에서 ET가 RF보다 더 낮은 예측 오차를 보였다(Geurts et al., 2006).
ET는 RF에 비해 자주 사용되지는 않지만 더 나은 예측 성능을 보이므로 본 연구의 활용 모델로 지정하 였다. 예측 성능을 극대화하기 위해 RF와 동일한 하이 퍼파라미터를 튜닝하였다.
2.4.4. Gradient Boosted Machine (GBM) Gradient Boosted Machine (GBM)(Friedman, 2001) 은 Ensemble learning의 또 다른 유형인 Boosting을 기반으로 한다. Boosting은 순차적으로 약한 모델들을 생성하는데, 각 모델을 생성할 시 이전 모델들이 예측 하지 못한 부분을 더 잘 예측하는 모델을 만들고 이들을 앙상블하는 방법이다. GBM은 경사하강법(Gradient Descent Method)에 기반하여 모델을 생성함으로써 이 과정을 수행한다. 또한 약한 모델들의 가중평균값을 최종 예측값으로 활용하는데, GBM은 매번 모델이 생 성될 때마다 가중치를 조정하여 예측값과 실제값의 차 이를 최소화한다(Natekin and Knoll, 2013).
Bagging 기반 방법들과 달리 모델을 순차적으로 생 성하기 때문에 모델을 학습할 때 더 많은 시간이 소요 되지만 다양한 분야에서 가장 높은 성능을 보이며 대 다수의 데이터 분석 대회에서 우승한 모델의 방법론으 로 채택되어(Nielsen, 2016) 토양 수분 예측 모델에서 도 활용해보았다. GBM 모델에서는 기존 RF와 ET에 서 활용한 최소 샘플 수, 트리의 최대 개수, 활용할 변수의 개수 이외에 학습률(learning rate)의 최적값을 탐색하고 모델에 적용하였다.
2.4.5. Deep Feedforward Network (DFN) Deep Feedforward Network (DFN)은 Deep Learning 의 가장 기본적인 형태로 사람의 뇌를 모사한 기계학 습 모델인 인공신경망(Neural Network)의 은닉층 (Hidden layer)을 일정 수준 이상으로 늘린 모델을 지 칭한다. 은닉층의 깊이를 일정 수준 이상으로 늘리는 것은 모델이 투입 변수에 대한 내재적 표현(internal representation)을 학습하고 모델 내에서 중요한 잠재 변수(Latent Feature)들을 도출해 낼 수 있게 한다. 그 렇기 때문에 Raw data의 인위적인 조작이 모델의 성
능에 큰 영향을 준 전통적인 머신러닝 방법들과 달리 Deep learning 방법은 모델 내에서 자동적으로 데이터 를 핵심적인 변수로 변환하는 과정을 거치기 때문에 정제되지 않은 투입변수를 바로 활용 가능하며 사람의 능력으로 찾아내지 못한 중요한 정보도 자동으로 찾아 내 활용하는 장점이 있어 여러 분야에서 활발히 사용 되고 있다(GoodFellow et al., 2016).
본 연구에서 설정한 투입변수와 미래의 토양수분 변수는 복잡한 비선형 관계를 가지고 있기 때문에 내 재적 표현 능력이 뛰어난 DFN 모델이 높은 예측 성능 을 보일 수 있을 것이라고 예상하여 DFN 모델을 학습 하였다. 모든 DFN 모델에서는 Adam optimizer (Kingma and Ba, 2014)를 이용해 weight을 update 했고, ReLu 활성함수와 He 연결강도 초기화 방법(He et al., 2015) 을 사용했으며 은닉층의 개수와 각 은닉층의 뉴런 개 수, 학습률, 한번에 학습할 학습 데이터 배치의 크기는 실험을 통해 최적값을 선택하였다.
2.5. 평가 방법
모든 모델은 예측값과 실제값의 제곱의 총합인 Mean squared error (MSE)를 최소화하는 것을 목적함 수로 가진다. 또한 본 연구는 MSE를 모델의 성능을 비교하기 위한 지표로 활용하였다.
(Eq. 3)
각 모델의 과적합(Overfitting)을 방지하기 위해 K fold cross-validation을 수행하여 활용할 Hyper parameter 를 구하였다. K fold cross-validation이란 전체 집단을 K개의 서로 겹치지 않는 샘플 집단으로 쪼갠 후 모든 집단에 대해 학습에 사용되지 않았을 시의 예측성능을 구하고 이를 평균 내어 실제 예측성능 추정하는 방법 이다. K fold cross-validation은 일반적으로 예측성능 을 과소 추정(혹은 예측 오차를 과대추정)하는 경향이 있지만 모델 선택의 지표로 활용할 시 다른 추정 방법 보다 더 나은 성능을 보인다(Kohavi, 1995). 본 연구에 서는 5개의 fold로 cross-validation을 수행하였다.
III. 결과 및 고찰
3.1. 변수 중요도(Feature importance)
모든 변수들을 이용하여 예측 모델을 만들 시 어떠 한 변수들이 모델에서 중요하게 활용되었는지를 확인 하기 위해 RF와 ET, GBM 모델에서 활용된 변수들 중 Feature importance (FI)가 가장 높은 10개 변수와 FI의 값을 확인했다(Table 1).
모든 모델에서 당일 10cm 토양수분이 가장 중요한 변수로 활용되었고 그 다음은 1일 전 토양 수분(10cm 토양수분량 lag1) 변수가 활용되었다. 하지만 그 이후 부터는 모델에 따라 중요하게 활용된 변수가 확연히 차이가 난다. RF의 경우 강수와 관련된 변수들이 높은 중요도를 보였고 습도와 일조량과 같은 기상 변수들이 중요하게 활용되었다. 하지만 ET와 GBM의 경우 과
Random Forest Extremely Randomize Tree Gradient Boosted Machines
Variable FI Variable FI Variable FI
10cm soil moisture 0.630 10cm soil moisture 0.227 10cm soil moisture 0.330 10cm soil moisture lag1 0.231 10cm soil moisture lag1 0.182 10cm soil moisture lag1 0.164 Precipitation 0.027 10cm soil moisture lag2 0.130 10cm soil moisture lag3 0.131 Last rain time 0.017 10cm soil moisture lag3 0.080 10cm soil moisture lag2 0.100 Consecutive non-precipitation days 0.009 10cm soil moisture lag4 0.057 10cm soil moisture lag7 0.027 2days’ precipitation 0.008 10cm soil moisture lag5 0.052 Precipitation 0.024 Insolation 0.007 Last rain time 0.029 20cm soil moisture 0.024 Mean soil moisture by month 0.006 10cm soil moisture lag6 0.029 10cm soil moisture lag5 0.024 10cm soil moisture lag2 0.004 10cm soil moisture lag7 0.024 10cm soil moisture lag4 0.019 10cm soil moisture lag3 0.003 10cm soil moisture lag8 0.023 2days’ precipitation 0.018
Table 1. Feature importance of trained soil moisture prediction model using weather data based on Random
Forest(RF), Extremely Randomized Tree(ET), and Gradient Boosted Machines(GBM) algorithms거 동일 깊이 토양 수분량들이 상당히 중요하게 활용 된 것을 확인할 수 있다. 각 알고리즘에서 약한 모델이 생성되는 방식을 고려했을 때, 매번 최적 split을 탐색 할 경우(RF의 경우) 토양수분 변수, 강수관련 변수, 기상관련 변수 순으로 중요하게 활용될 수 있는데, 최 적 split이 아닌 점을 더 넓게 탐색할 경우(ET) 그리고 상당히 세부적으로 토양수분량을 예측하는 모델을 만 들 경우(GBM) 과거 토양 수분이 상당히 중요하게 활 용된다는 점을 확인할 수 있다. 그리고 RF 모델에서 조차 일조량과 습도와 같은 기상 변수는 상당히 낮은 FI 를 보이는데, 이는 기존 연구들과 같이 많은 변수들이 없더라도 강수량과 과거 토양 수분량만 가지고도 충분 한 예측 성능을 가지는 모델을 만들 수 있음을 뜻한다. 각 모델의 FI를 보면 RF가 가장 skewed 된 분포를 보이고 ET가 가장 완만한 분포를 보인다. 이는 ET의 랜덤한 split 지점 탐색에 의해 더 다양한 변수들의 split 후보지점을 탐색했다는 것을 확인할 수 있다.
RF와 ET, GBM 모델에서 FI가 높은 최상위 20개까 지의 변수들을 선별해 보니 총 24개의 변수가 선별되 었다. 최상위 10개 변수의 리스트와 다르게 상당 수 변수들이 3개 모델 전부에서 활용되고 있었다. 이는 모델의 알고리즘에 따라 가장 중요한 최상위 변수들은 다를 수 있지만 상위권에 위치한 변수들은 비슷하다는 것을 나타낸다. 그리하여 본 연구는 이 24개 변수를 Feature 5로 사용하여 예측 성능을 비교했다.
3.2. 변수와 모델별 예측 성능
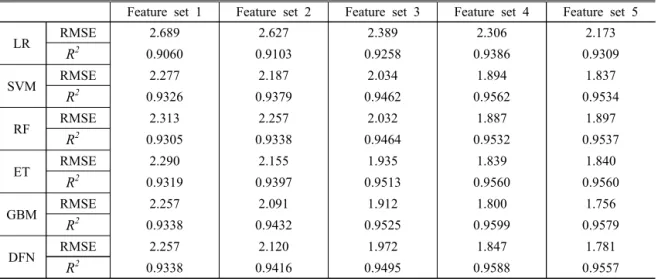
미래의 토양수분을 예측 모델을 개발하기 위해 기 후와 토양변수로 구성된 다양한 투입변수 조합과 SVM, RF, ET, GBM, DFN과 같은 머신러닝 방법론 을 활용한 예측 모델을 학습하였고 이들의 예측 성능 을 확인하였다. 각 모델은 5-fold validation에서 가장 높은 성능을 보인 Hyper parameter들을 사용하였으며, 각 지역별로 약 75% - 80%의 기간을 Train set으로, 나머지 기간을 Test set으로 활용하였다. 더 구체적으 로는, 순천지역의 2014년 3월 - 2017년 12월 데이터, 보성지역의 2015년 3월 – 2017년 12월 데이터, 철원지 역의 2014년 3월 – 2016년 12월 데이터, 안동지역의 2016년 10월 – 2018년 5월 데이터를 Train set으로 활용하였고, 순천지역의 2018년 3월 – 2018년 10월 데이터, 보성지역의 2018년 3월 – 2018년 12월 데이 터, 철원지역의 2017년 3월 – 2017년 12월 데이터, 안동지역의 2018년 6월 – 2018년 12월의 데이터를 Test set으로 활용하였다. 또한 일반적인 통계 모형에 비해 예측 성능이 얼마나 달라지는 확인하기 위해 동 일한 변수세트로 구한 선형회귀(Linear Regression) 모델의 예측 성능 또한 비교 대상으로 추가하였다.
일반적으로 모델의 성능은 훈련에 사용된 Train set 에 대한 예측성능과 훈련에 사용되지 않은 Test set에 대한 예측성능을 동시에 고려하여 평가하는데, 선형 회귀 모델을 제외한 모델들의 Train set에 대한 예측성 능이 R2 를 기준으로 0.993 – 0.999 (Feature set 1의 RF 모델을 제외하고는 모두 R2가 0.998 이상으로 나
Feature set 1 Feature set 2 Feature set 3 Feature set 4 Feature set 5
LR RMSE 2.689 2.627 2.389 2.306 2.173
R
2 0.9060 0.9103 0.9258 0.9386 0.9309SVM RMSE 2.277 2.187 2.034 1.894 1.837
R
2 0.9326 0.9379 0.9462 0.9562 0.9534RF RMSE 2.313 2.257 2.032 1.887 1.897
R
2 0.9305 0.9338 0.9464 0.9532 0.9537ET RMSE 2.290 2.155 1.935 1.839 1.840
R
2 0.9319 0.9397 0.9513 0.9560 0.9560GBM RMSE 2.257 2.091 1.912 1.800 1.756
R
2 0.9338 0.9432 0.9525 0.9599 0.9579DFN RMSE 2.257 2.120 1.972 1.847 1.781
R
2 0.9338 0.9416 0.9495 0.9588 0.9557Table 2. Predictive performance measured by Root Mean Squared Error (RMSE) and R squared of Machine
learning models and data sets in used타남)로 상당히 높게 나타나 비교하는 것이 무의미하 다고 판단하여 Test set에 대한 예측성능만 표기하였 다(Table 2).
모든 모델에서 R2가 0.9 이상을 보여 준수한 예측 성능을 보였다. 이중 가장 높은 예측 성능을 보인 모델 은 모든 변수를 활용한 GBM 모델이며 R2가 0.96, Rooted Mean squered Error(RMSE)가 1.76이었다. 이 는 해당 모델이 예측한 토양 수분량이 실제값과 평균 적의 차이의 96%를 설명하며 예측값과 실제값이 평균 적으로 1.76 차이가 난다는 것을 의미한다. 동일한 데 이터 세트를 활용한 LR 모델의 경우 R2가 0.938, RMSE가 2.17을 보여 LR에 피해 2%이상 향상된 설명 력을 보였다.
모델 별로 비교를 했을 시 모든 투입변수 조합에서 GBM 모델이 가장 높은 예측 성능을 보였고 예측 성능 은 모든 변수를 활용한 Feature set 5, 중요 변수만 추 출한 Feature set 4, 기본 변수에 강수관련 파생변수와 과거 토양수분만 추가한 Feature set 3, 기본 변수에 다른 깊이의 토양수분 변수를 추가한 Feature set 2, 기본 변수 세트 Feature set1 순으로 높았다. 그 다음으 로 DFN 모델과 ET 모델이 높은 성능을 보였는데, 기 본 변수에 과거 토양 수분과 강수 관련 파생변수를 추가한 Feature set 3와 중요한 변수만을 선별한 Feature set 5의 경우 ET가 더 높은 예측 성능을 보였 고 나머지 Feature set에서는 DFN이 더 높은 예측 성 능을 보였다. 이는 전혀 가공되지 않은 상태이거나 활 용 가능한 변수들이 상상당 많은 경우 DFN이 더 적합 한 모델이고 이 중간 단계에서는 ET가 더 적합한 모델 임을 뜻하며 데이터 셋의 구성에 따라 모델 성능의 우위가 달라질 수 있음을 뜻한다. 모든 데이터 셋에서 기계학습 모델들이 LR보다 R2가 0.0146이상(0.0146 - 0.0328) 높게 나타나 토양 수분 예측 시 간단한 LR 대신 기계학습 모델을 사용하는 것 만으로도 예측 성 능을 향상시킬 수 있음을 나타낸다.
Feature set을 기준으로 보면 대부분의 모델에서 Feature set 5, Feature set 4, Feature set 3, Feature set 2, Feature set 1 순으로 예측 성능이 높게 나타났 다. Feature set 3과 Feature set 1, Feature set 5와 Feature set 2을 비교해보면 원본데이터만을 활용한 경 우와 중요한 정보를 담고 있는 파생변수를 추가함으로 써 예측 성능을 향상시킬 수 있음을 확인할 수 있다. 동일 모델 일 시 Feature set 2을 이용한 모델이 Feature set 1을 이용한 모델보다 더 높은 예측 성능을 보였는
데, 이는 다른 깊이의 토양 수분 정보가 미래의 토양 수분 예측 시 활용될 수 있음을 뜻한다. RF와 ET의 경우 Feature set 4가 Feature set 5 보다 높은 예측 성능을 보였는데, Feature set 5의 경우 88개의 투입변 수를 포함하고 Feature set 4의 경우 24개의 투입변수 만을 포함한다. 그럼에도 일부 모델에서는 Feature set 4가 더 높은 성능을 보인 모델이 있다는 것은 많은 변 수를 인풋으로 활용하는 것도 중요하지만 이와 비슷하게 중요한 변수를 선별하는 것 또한 중요함을 나타낸다.
3.3. 지역별 예측 결과 비교
각 지역별 10cm 토양수분이 차이가 날 경우 지역별 로 예측 성능이 라질 수 있다. 이를 검증하기 위해 지 역별로 토양수분의 평균 차이에 대한 Analysis of variance (ANOVA)를 수행한 결과 각 지역별로 토양 수분의 평균이 통계적으로 유의하게 차이가 나는 것을 확인했다(Table 3).
Regions/
Statistics Boseong Suncheon Andong Chulwon Mean 23.76 7.01 9.35 14.24 Variance 39.23 10.31 27.75 12.65 Anova test F : 3429.9, P-value : 2.2e-16 ***
Table 3. Mean and variance of Soil Moisture at 10cm
depth by region기존의 토양수분 예측 모델과 본 연구에서 활용하 는 기계학습 알고리즘을 이용한 토양수분 예측 모델의 가장 차별화되는 점 중 하나는 서로 이질적인 지역에 공통적으로 적용 가능할 수 있다는 점이다. 토양수분 이 차이가 나는 이질적인 지역에 단일 모델을 공통적 으로 적용가능한지를 확인해보기 위해 가장 높은 성능 을 보인 Feature set 4과 SVM, RF, ET, GBM, DFN을 이용해 학습한 예측 모델의 지역별 예측 성능을 비교 하였다(Table 4).
GBM 모델이 가장 낮은 지역별 예측 성능 차이를 보였고 이는 본 연구에서 활용한 데이터를 학습데이터 로 사용할 시 GBM 알고리즘이 여러 지역에 일반화하 기에 가장 적절한 기계학습 모델임을 의미한다. Fig. 1 에서 GBM 모델을 활용하여 2016년 3월 1일부터 2016년 10월 1일까지의 지역별 토양수분의 예측값과 실제값을 비교하였다.
한편 DFN 모델의 경우 전체 지역에 대한 예측성능 은 두번째로 높았지만 지역별 예측 성능 편차가 상당 히 컸다. 특히 철원 지역에 대한 예측 성능은 R2 0.853 으로 모든 모델 중 가장 낮게 나타나 일반화 성능이 상대적으로 낮았다. 하지만 DFN 모델의 보성과 순천, 안동 지역에 대한 예측성능의 경우 GBM 모델과 비슷 하거나 더 높게 나타났다. DFN의 복잡한 모델 구조가 더 많은 양의 다양한 데이터를 학습할 시 다른 기계학 습 모델들이 학습하지 못하는 복잡한 패턴을 학습 가
능함을 고려할 때 더 다양한 지역의 많은 데이터를 학습함으로써 DFN모델의 예측 성능이 더 향상될 것 을 기대해 볼 수 있다.
다른 모델 또한 보성과 순천, 안동 지역의 경우 모든 모델에서 R2 0.945 이상의 준수한 예측 성능을 보였고 철원 지역에 대해서는 상대적으로 낮은 예측성능을 보 였다. 전 지역에서 철원 지역에 대한 예측 성능이 낮게 나타난 이유에 대해서 활용한 데이터 개수의 불균형 혹은 지역별 토양수분 및 기상 변수의 특성이 철원
Region/Model SVM RF ET GBM DFN
Boseong 0.9509 0.9452 0.9459 0.9564 0.9752
Suncheon 0.9566 0.9589 0.9624 0.9658 0.9635
Andong 0.9675 0.9761 0.9724 0.9736 0.9728
Chulweon 0.8729 0.8823 0.8744 0.8974 0.8530
Standard
Deviation 0.0433 0.0409 0.0443 0.0347 0.0590
Table 4. Predictive performance(R-squered measured with test set) of Machine learning models by regions
Fig. 1. True soil moisture and predicted soil moisture of best performing model (GBM,
Feature set 4) of four regions (Boseong, Suncheon, Andong, Chulwon) in 2016/03/01 to 2016/10/01.지역을 제외하고는 유사함을 의심해 볼 수 있는데, 이 러한 차이가 나타난 원인에 대한 추가적인 연구가 필 요하다.
IV. 요약 및 결론
본 연구는 국내 공공기상 데이터를 활용하여 미래 의 토양수분을 예측하는 기계학습 모델을 만들고 이의 정확도를 평가하기 위해 2014년부터 2018년까지의 보성, 순천, 안동, 철원 지역의 농업기상관측 자료와 종관기상관측 자료로부터 토양 수분 데이터와 기상데 이터를 추출하고 SVM, RF, ET, GBM, DFN 알고리 즘을 이용하여 예측 모델을 구축하였다. 또한 가공하 지 않은 데이터(Feature set 1)와 다른 깊이의 토양수분 을 추가한 데이터셋(Feature set 2), 강수관련 파생변수 와 과거 토양수분 변수를 추가한 데이터셋(Feature set3), 지역/월별 토양 수분 통계량을 추가한 데이터셋 (Feature set 4), 이 중 중요한 24개 변수를 선별한 데이 터셋(Feature set 5) 간의 예측 성능 차이를 비교하여 어떤 데이터 들이 예측 성능에 더 크게 기여하는지를 확인했다. 그 결과 모든 변수와 파생변수를 포함한 데 이터 셋(Feature set 4)를 학습한 GBM 모델이 R2 0.96, RMSE가 1.76으로 가장 높은 예측 성능을 보였다.
GBM 모델은 다른 종류의 Feature set에서도 가장 높 은 예측 성능을 보였고, 그에 이어 DFN과 ET모델 이 높은 성능을 보였고 SVM과 RF 모델이 가장 낮은 성 능을 보였다. 모든 모델이 R2 0.93 이상의 충분한 예측 성능을 보였고 비교 대상으로 활용한 LR 모델보다 더 나은 성능을 보였으며 R2이 0.0146 - 0.0328 높았으며 RMSE가 0.418 – 0.535 낮았고 이는 국내 공공기상데 이터 만을 이용해도 충분히 토양 수분예측이 가능하고 기계학습 모델을 적용 시 예측 성능을 향상시킬 수 있음을 의미한다.
기계학습 모델들에서 중요하게 활용된 변수들을 확 인한 결과 과거 토양수분 변수와, 강수관련 변수들이 상당히 중요하게 나타났고, 기상 변수들은 상대적으로 상당히 낮은 중요도를 보였다. 이는 과거 연구들에서 활용했던 다양한 토양 및 기상 변수들 없이 강수량과 토양수분모델만으로 충분한 예측성능을 가지는 모델 을 만들 수 있음을 뜻한다.
지역별로 모델의 예측 성능을 비교한 결과 철원 지 역을 제외하고는 지역별로 비슷한 수준의 예측성능을 보였고 GBM 모델이 지역별 예측 성능 편차가 가장
낮았다. 이는 기계학습 모델을 활용할 시 여러 지역에 일반적으로 적용가능한 모델을 만드는 게 가능함을 의 미한다. 게다가 DL 모델의 특성상 데이터가 복잡하더 라도 데이터만 충분하다면 상당히 높은 예측 성능을 가지는 모델을 만들 수 있어 더 많은 지역의 더 오랜 기간의 데이터를 활용한다면 예측성능의 향상을 기대 해볼 수 있다. 한편 관측치가 적었던 철원 지역의 경우 예측 성능이 현저하게 낮았는데, 이것이 데이터의 문 제인지 활용한 방법의 한계인지에 대해서는 추가적인 연구가 필요하며 데이터의 불균형 혹은 데이터품질 등 의 문제들에 해결 방안을 모색해야 한다.
적 요
토양수분은 농업에서 필수적인 자원으로 이의 변화 와 부족을 예측함으로써 관리되어왔다. 최근 현장에서 의 적용 용이성과 다양한 지역에 대한 일반화 가능성 이 뛰어난 통계 및 기계학습 알고리즘을 활용한 토양 수분 예측 연구가 활발히 진행되고 있다. 하지만 국내 에서 생성되는 데이터를 이용한 연구들은 부족한 실정 이다. 이에 본 연구는 1) 국내 공공기상 데이터만으로 충분한 성능을 내는 토양수분 예측 모델을 만들 수 있는지, 2) 어떠한 기계학습 모델이 국내에서 생산되 는 데이터와 토양환경에서 가장 높은 예측 성능을 보 이는지, 3) 단일 기계학습 모델을 이용해 다양한 지역 에 적용 가능한지를 확인해보려 한다. 본 연구에서 Support Vector Machines (SVM), Random Forest (RF), Extremely Randomized Trees (ET), Gradient Boosting Machines (GBM), and Deep Feedforward Network (DFN) 알고리즘과 종관기상관측 자료, 농업 기상관측자료를 활용하여 안동, 보성, 철원, 순천 지역 의 토양 수분을 예측하는 모델을 만들었다. 그 결과, GBM을 이용한 모델이 R2 : 0.96, Root Mean Squared Error(RMSE) : 1.8로 가장 낮은 예측 오차를 보였다.
또한 GBM을 사용한 모델이 가장 낮은 지역간 예측 오차 분산을 보여 가장 일반화하기에 적절한 모델로 확인되었다.
감사의 글
이 논문은 농림축산식품부의 재원으로 농림식품기 술기획평가원 노지스마트팜사업의 지원을 받아 연구 되었음(117012-3).
REFERENCES
Allen, R. G., L. S. Pereira, D. Raes, and M. Smith, 1998: Crop evapotranspiration-guidelines for computing crop water requirements-FAO Irrigation and drainage paper 56. Food and Agriculture Organization of the United Nations, Rome, 1-15.
Breiman, L, 2001: Random forests. Machine learning
45(1), 5-32.
Cai, Y., W. Zheng, X. Zhang, L. Zhangzhong, and X. Xue, 2019: Research on soil moisture prediction model based on deep learning. PloS One 14(4).
Choi, K. M., S. H. Kim, M. Son, and J. Kim, 2008:
Soil moisture modelling at the mopsoil of a hillslope in the Gwangneung National Arboretum using a transfer function. Korean Journal of Agricultural
and Forest Meteorology 10(2), 35-46. (in Korean
with English abstract)Choi, S. W., S. J. Lee, J. Kim, B. L. Lee, K. R.
Kim, and B. C. Choi, 2015: Agrometeorological observation environment and periodic report of korea meteorological administration: current status and suggestions. Korean Journal of Agricultural and
Forest Meteorology 17(2), 144-155. (in Korean
with English abstract)Cisty, M., F. Cyprich, and V. Soldanova, 2018:
Prediction of soil moisture data by various regression techniques. Proceedings of International Multidisciplinary
Scientific GeoConference, Surveying Geology and
mining Ecology Management, Sofia, 383-389.Drucker, H., C. J. Burges, L. Kaufman, A. J. Smola, and V. Vapnik, 1997: Support vector regression machines. Advances in Neural Information Processing
Systems 9, 155-161.
Friedman, J. H., 2001: Greedy function approximation:
a gradient boosting machine. Annals of Statistics
29(5), 1189-1232.
Geurts, P., D. Ernst, and L. Wehenkel, 2006: Extremely randomized trees. Machine Learning 63(1), 3-42.
Gill, M. K., T. Asefa, M. W. Kemblowski, and M.
McKee, 2006: Soil moisture prediction using support vector machines. Journal of the American Water
Resources Association 42(4), 1033-1046.
Goodfellow, I., Y. Bengio, and A. Courville, 2016:
Deep Learning. MIT press, 1-26.
He, K., X. Zhang, S. Ren, and J. Sun, 2015: Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. Proceedings of the IEEE
international conference on computer vision, Institute
of Electrical and Electronics Engineers, Santiago,1026-1034.
https://data.kma.go.kr/data/grnd/selectAsosRltmList.do?
pgmNo=72 (2019. 12. 09)
https://data.kma.go.kr/data/grnd/selectAsosRltmList.do?
pgmNo=36 (2019. 12. 09)
Kingma, D. P., and J. Ba, 2014: Adam: a Method for Stochastic Optimization. Proceedings of Third
International Conference for Learning Representations,
San Diego.Kohavi, R., 1995: A study of cross-validation and bootstrap for accuracy estimation and model selection.
Ijcai 14(2), 1137-1145.
Laio, F., A. Porporato, L. Ridolfi, and I. Rodriguez- Iturbe, 2001: Plants in water-controlled ecosystems:
active role in hydrologic processes and response to water stress: II. Probabilistic soil moisture dynamics.
Advances in Water Resources 24(7), 707-723.
Natekin, A., and A. Knoll, 2013: Gradient boosting machines, a tutorial. Frontiers in Neurorobotics 7, 21pp.
National Center for Atmospheric Research, 2004: Community
Land Model version 3.0 (CLM3. 0) developer’s guide. U. S. Department of Energy.
National Weather Service, 1976: Catchment modeling
and initial parameter estimation for the National Weather Service river forecast system. Office of
Hydrology.Nielsen, D., 2016: Tree boosting with XGBoost-why does XGBoost win “every” machine learning competition? NTNU Norwegian University of Science and Technology.
Oleson, K. W., Y. Dai, G. Bonan, M. Bosilovich, R.
Dickinson, P. Dirmeyer, F. Hoffman, P. Houser, G. Y. Niu, P. Thornton, M. Vertenstein, Z. L.
Yang, and X. Zeng, 2004: Technical description of the Community Land Model (CLM). NCAR Technical Note NCAR/TN-461+STR.
Pavlenko, T, 2003: On feature selection, curse-of- dimensionality and error probability in discriminant analysis. Journal of Statistical Planning and Inference
115(2), 565-584.
Prakash, S., A. Sharma, and S. S. Sahu, 2018: Soil Moisture Prediction Using Machine Learning. Proceedings
of 2018 Second International Conference on Inventive Communication and Computational Technologies,
Coimbatore, Institue of Electrical and Electronics Engineers, 1-6.Shin, Y., B. P. Mohanty, and A. V. Ines, 2018:
Development of non-parametric evolutionary algorithm for predicting soil moisture dynamics. Journal of
Hydrology 564, 208-221.
Song, J., D. Wang, N. Liu, L. Cheng, L. Du, and K. Zhang, 2008: Soil moisture prediction with feature selection using a neural network. Proceedings
of 2008 Digital Image Computing: Techniques and Applications, Canberra, Institue of Electrical and
Electronics Engineers, 130-136.Van Dam, J. C., J. Huygen, J. G. Wesseling, R. A.
Feddes, P. Kabat, P. E. V. Van Walsum, P.
Groenendijk, and C. A. Van Diepen, 1997: Theory
of SWAP version 2.0; Simulation of water flow, solute transport and plant growth in the soil-water- atmosphere-plant environment, TD45.HM/10.97, DLO Winand Staring Centre, Wageningen.
Vapnik, V., S. E. Golowich, and A. J. Smola, 1997:
Support vector method for function approximation, regression estimation and signal processing. Advances