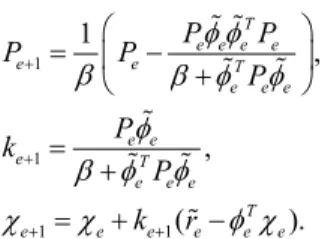접촉 작업을 위한 로봇의 스킬 학습 전략
Robot Skill Learning Strategy for Contact Task
김 병 찬1, 강 병 덕2, 박 신 석3, 강 성 철4
Kim Byungchan1, Kang Byungduk2, Park Shinsuk3, Kang Sungchul4
Abstract 본 논문에서는 인간 운동 제어 이론과 기계학습을 기반으로 하여 로봇의 접촉 작업 수 행을 위한 새로운 운동 학습 전략을 제시하였다. 성공적인 접촉 작업 수행을 위한 본 연구의 전 략은 강화학습 기법을 통하여 최적의 작업 수행을 위한 임피던스 매개 변수를 찾는 것이다. 본 연구에서는 최적의 임피던스 매개 변수를 결정하기 위하여 Recursive Least-Square (RLS) 필터 기반 episodic Natural Actor-Critic 알고리즘이 적용되었다. 본 논문에서는 제안한 전략의 효용성을 증명하 기 위해 동역학 시뮬레이션을 수행하였고, 그 결과를 통하여 접촉작업에서의 작업 최적화 및 환 경이 가지는 불확실성에 대한 적응성을 보여 주었다.
Keywords : Impedance Control, Reinforcement Learning, Stiffness Ellipse, Contact Task
1. 서 론
현대의 로봇은 공장 자동화 환경과 같은 영역에서 이미 뛰어난 성능을 발휘해 왔다. 그러나, 로봇이 인간이 살아가는 공간과 같은 복잡한 환경에서 접촉작업(Contact Task)을 수행할 시에는 인간에 비해 아직 낮은 작업 성능을 보인다. 이는 인간이 뛰어난 적응 및 학습 능력을 이용하여 불확정한 동적 환경에 대하여 대처하기 때문이다. 이러한 맥락에서, 본 연구는 인간의 운동 제어 전략을 로봇 제어에 활용하여 로봇의 접촉 작업 수행을 위한 전략을 제시한다.
인간 운동 제어 이론의 한 종류인 평형점(Equilibrium Point) 제어 이론은 운동 제어에 대한 기틀을 제공해 준다[1]. 평형점 제어 이론에서는 팔의 근육 및 신경 제어 회로가 “스프링” 효과를 가지게 된다. 이 때, 중추신경계(CNS: Central Nervous System)는 팔의 끝점 위치에 대한 일련의 평형점을 생성하게 되는데, 신경- 근육 시스템의 스프링 효과로 인하여 평형 자세가
생성하는 경로를 따라 팔을 움직이게 된다[2]. 이러한 스프링 효과는 근육의 “강성,” 혹은 보다 일반적으로
“임피던스(Impedance),” 로 해석되는데, 이러한 요소는 팔의 동적 특성을 결정하는데 중요한 역할을 한다[3]. 따라서, 로봇의 임피던스 매개 변수를 조절함으로써 로봇과 접촉환경간의 상호작용을 효과적으로 제어할 수 있다.
과거에 생체 모방형 학습에 대한 몇 가지 연구들이 진행되어왔다. Cohen 등은 접촉작업에 대하여 Associate Search Network기반의 임피던스 학습 전략을 제시하였다[4]. 이 연구에서 제시한 기법은 로봇 팔의 Wall-Following 작업에서 힘/위치 추적에 효과적임을 보여주었다. 또 다른 연구로는 Izawa 등의 예를 들 수 있다[5]. 이들의 연구에서는 강화학습을 이용하여 근골격계를 모방한 로봇 팔 모델의 움직임 학습을 수행하였다. 그러나 이러한 연구들은 단순한 접촉/비접촉 작업 문제에 국한되었다는 한계점을 보여주었다.
또한, 접촉작업에 대하여 인공신경망을 이용하여 로봇의 임피던스를 학습하는 전략을 제시한 연구가 진행되었다[6,7]. 이 중에서 주목할 만한 연구는 Tsuji 등에 의해 진행되었는데[7], 이 연구에서는 영상 정보를 이용하여 실시간 가상 임피던스를 학습하는 기법이 제시되었다. [7]에서 보여준 실시간 학습 기법은 실시간 학습이라는 장점에도 불구하고, 인공신경망 기반 연산이
※ 이 연구는 산업자원부 지원으로 수행하는 21 세기 프론티어 연구개발사업(인간기능 생활지원 지능로봇 기술개발사업)의 일환으로 수행되었습니다.
1 KIST 인지로봇연구단 위촉연구원 ([email protected]) 2 현대중공업 ([email protected])
3 고려대학교 기계공학과 부교수 ([email protected]) 4 KIST 인지로봇연구단 책임연구원 ([email protected])
가지는 한계인 많은 계산량의 요구 및 국소 최적(Local optimum)으로 빠지기 쉽다는 단점을 가지고 있다.
본 논문에서는 평형점 제어 이론 기반의 로봇 접촉 작업 학습 전략을 제시하였다. 본 연구의 목표는, 로봇이 강화학습 (Reinforcement Learning)을 사용하여 작업을 반복적으로 수행하여 적절한 행동을 찾아내는 것이다. 강화학습은 기계학습의 한 종류로서, 개체가 불확실한 환경에서 최대 보상값을 획득하기 위한 일련의 정책을 수립함으로써 최적 행동을 찾아내는 기법을 말한다[8]. 본 연구에서는 RLS 필터 기반의 episodic Natural Actor-Critic (eNAC) 알고리즘을 제시하였다. eNAC 알고리즘은 Peters 등에 의하여 제시되었으며, 로봇과 같은 다차원의 연속된 상태/행동 시스템에 대한 학습에서 뛰어난 성능을 보여주었다[9]. 본 연구에서는 학습 알고리즘의 연산량을 줄이기 위하여 박주영 등 이 제안한 바 있는 RLS 필터를 결합한 형태의 알고리즘을 응용하였다[10]. 그리고, 본 논문에서는 제시한 학습 전략의 효과를 보여주기 위하여 문 열기 작업을 접촉작업의 예로 선정하여 학습 시뮬레이션을 수행하였다.
2. 임피던스-기반 제어
로봇 팔의 물리적 특성으로서의 임피던스는 작업 공간에서 로봇과 환경이 동역학적 상호작용을 하는데 있어서 매우 중요한 요소이다. 주목할 점은 임피던스 제어가 평형점 제어 이론과 유사한 방식을 가진다는 것이다. 사람이 팔 근육의 강성 값을 변화시키면서 주어진 작업을 수행하는 것처럼, 임피던스 제어에서는 임피던스 매개 변수를 작업 환경에 맞추어 조절한다.
그러므로 본 연구에서는 로봇 힘 제어 기법의 하나인 임피던스 제어 기법을 기반으로 접촉작업의 제어틀을 설정한다.
접촉작업에 대한 제어식은 아래와 같이 정의된다[11].
( )
T
C C
J ⎡ ⎤
= − ⎣ + ⎦
T q K x B x&% % , (1)
xd
x x:= −
~ , (2)
식 (1)에서 J(q) 는 머니퓰레이터의 자코비안 행렬이다.
또한, 식 (2)에서 머니퓰레이터 끝단의 현재 위치와 목표 위치의 차이는 변위 벡터
x%
로 정의된다. 식 (1)에서의 행렬 KC 와 BC 는 각각 직교 좌표 상에 정의된 강성(Stiffness) 행렬 및 댐핑(Damping) 행렬이다.본 연구에서는 댐핑 행렬은 Joint 좌표 상에 정의된
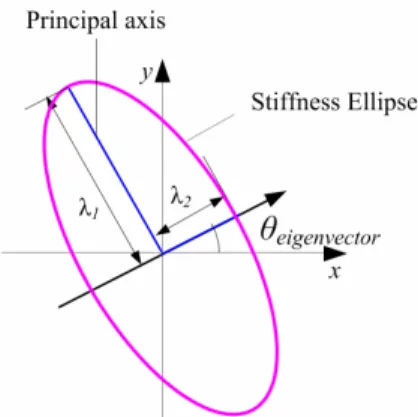
그림 1. A graphical representation of the end-effector’s stiffness in Cartesian space. The principal axes length λi and relative angle θ represents the magnitude and orientation of the end-effectors stiffness, respectively.
강성 행렬에 비례한다고 가정하였다. 또한, Joint 댐핑 행렬 및 Joint 강성 행렬의 비는 시간 상수인 τ = BJ/KJ
로 나타낼 수 있다. 시간 상수 τ는 Flash와 Won에 의하여 수행된 사람의 팔에 대한 연구에 따라 0.05 로 설정하였다[12].
2절 링크 머니퓰레이터를 이용한 임피던스 제어에서 는 다음과 같이 2 × 2 크기의 강성 행렬이 정의된다.
11 12
21 22
C
K K
K K K
⎡ ⎤
= ⎢ ⎥
⎣ ⎦ . (3) 행렬 KC에 대한 SVD를 수행하면, 다음과 같은 결과를 얻을 수 있다.
T
KC = ΣV V , (4) 여기서, 수직 행렬 V및 대각 행렬 Σ는 각각 강성 행렬 KC의 고유벡터 및 고유치로 구성되어 있다. 이러한 행렬들의 성질은 그림 1에서와 같이 타원의 형태로 표현될 수 있다. 그러므로 타원의 특성은 작업 말단에서의 강성 특성을 반영한다고 할 수 있으며, 강성 행렬의 값들은 타원의 세 가지 특성인 강성의 크기(타원의 면적), 형태(장축과 단축의 비율), 그리고 방향(주축의 방향)을 설정함으로써 결정될 수 있다. 이 세가지 요소를 결정하는 것이 강성 행렬을 계획하는 방법이 된다. 본 연구에서는 타원의 면적을 고정하는 것으로 하여 제어 매개 변수를 타원의 형태 및 방향으로 설정하였다. 그러므로 이 두 가지 독립 변수를 설정하여 강성타원을 이용한 임피던스 제어를 수행할 수 있게 된다.
임피던스 제어를 위하여 또 하나 결정해야 하는 요소 는 목표 경로를 설정하는 것이다. 본 연구에서는 머니 퓰레이터의 부드러운 움직임을 위하여 최소-저크(Jerk) 속도 구배를 가지는 작업 말단의 목표 경로를 설정하였 다[13]. 작업 공간상에서의 작업 말단 경로는 시작점 xi
과 도착점 xf 을 설정 할 때 다음과 같다.
3 4 5
( ) i ( f i)(10( ) 15( ) 6( ) )
f f f
t t t
x t x x x
t t t
= + − − + (5)
위 식에서 t는 현재 시간이고, tf는 도달 시간이 된다.
3. 운동 학습 전략 3.1 작업 개요
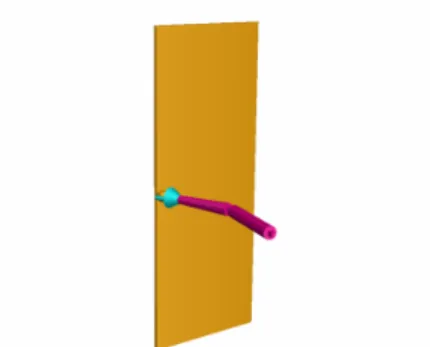
서론에서 말한 바와 같이, 본 연구에서 수행한 작업의 목표는 2절 링크 머니퓰레이터를 이용하여 목표 지수를 극대화 하는 임피던스 제어 계획을 학습을 통하여 찾아내는 것이다. 그림 2에는 문 열기 작업에 대한 시뮬레이션 모델이 제시되어 있다. 이러한 모델은 실제로는 2차원 공간에서 구속되어 있으므로 그림 3과 같이 나타낼 수 있다.
본 문 열기 작업에서는 다음과 같은 가정이 전제 되었다. 첫 째, 로봇이 문의 폭을 알지 못하기에, 로봇의 작업 수행 시에 예측하지 못한 실수를 저지를 수 있다.
예를 들면, 문 손잡이를 잡을 때 과도한 힘을 주게 되는 경우가 있을 수 있다. 둘 째, 문의 경첩은 스프링-댐퍼 효과를 가지며 이를 로봇이 알지 못한다.
이러한 환경에 대한 불확실성을 극복하기 위해, 다음과 같은 조건이 고려되어야 한다.
1) 문을 여는 도중에 문 손잡이에 과도한 간섭력이
거리지말아야한다.
2) 정해진시간내에문을열어야한다.
위에서 제시한 조건 아래, 본 연구에서는 다음과 같은 두 가지 작업 목표를 설정하였다.
1) 간섭력최소화: 작업수행간의안전성을답보 2) 작업간 위치 오차 최소: 위치 오차를 줄이는 동시에
부드러운움직임구사
이러한 목표 설정를 통하여 다음과 같이 작업 목표를 수식화 할 수 있다.
( ) ( )
1 1 lateral 2 2 rms
PI=w κ −
∑
F +w κ −∑
Error , (6)그림 2. Simulation model of open-door task using two-link manipulator.
식 (6)에서, wi 은 가중치이며, κi은 첫 작업 수행 시의 작업 목표 수치이다. 본 연구에서는 힘과 위치 오차의 단위 및 학습 과정에 끼치는 영향력을 고려하여 가중치를 결정하였다. 이러한 문제 정의를 통하여 문 열기 작업은 학습을 통하여 작업 목표에 대한 최적화 문제로 재정의 될 수 있다.
표 1. 시뮬레이션 모델의 물리적 수치 Length(mm) Mass(Kg) Inertia(Kg·m2)
Link 1 400 8.0 0.64
Link 2 400 3.7 0.296
Door 600 10.0 1.8
3.2 학습 기법 3.2.1 강화 학습
강화학습은 의사 결정자인 에이전트(Agent)와 외부 환경과의 상호작용으로 크게 구성된다. 이러한 상호작용 과정에서, 에이전트는 분절된 시간 t동안 행동 at를 선택하게 되고, 선택된 행동에 따라 다음 상태인 st로 전환되면서 행동에 대한 보상값인 rt를 받게 된다.
에이전트는 각각의 상태에서의 행동을 결정하는 정책 π(s, a)을 조절함으로써 보상값 rt를 최대화 하려고 노력한다.
강화학습은 이후에 받게 되는 보상값 혹은 예상되는 반환값의 전체합을 최대화 하는 것을 목적으로 한다.
T개의 상태로 구성되는 한 작업 수행 동안의 보상값의 할인합이 예측되는 반환값의 전체합 형태로 널리 쓰이며, 이는 다음과 같다.
1 0
T k
t t k
k
R γ r+ +
=
=
∑
⋅ , 10
( ) T k t k t
k
V s Eπ π γ r+ + s s
=
⎧ ⎫
= ⎨ ⋅ = ⎬
⎩
∑
⎭. (7) 식 (7)에서, γ (0≤γ≤1) 는 할인률이며, Vπ(s) 는가치함수로서, 예측되는 보상합을 나타낸다.
강화학습에서 가치함수의 갱신 규칙은 다음과 같이 정의된다.
(
1)
( )t ( )t t ( )t ( )t
V s ←V s +α r+ ⋅γV s+ −V s , (8)
여기서, rt+ ⋅γV s( )t+1 −V s( )t 항목은 Temporal Difference (TD) 오차이며, 상태 st에서의 행동이 좋은지 나쁜지를 판별하는 중요한 역할을 한다. 이러한 갱신 규칙은 수렴할 때까지 가치 함수 Vπ(s)를 최대화하기 위하여 반복된다.
3.2.2 RLS-based episodic Natural Actor-Critic
어떠한 학습 알고리즘을 사용할 것인가를 결정하기 위해서는 먼저 학습할 작업에 대한 정의가 설정되어야 한다. 본 연구에서 설정한 문 열기 작업은 다음과 같은 두 가지 조건이 있다. 첫 째, 본 작업은 일련의 상태로 구성되어 있다. 고로, 한 과정(한 에피소드)가 끝나게 되 면 상태전이가 끝나게 되고, 다시 초기 상태에서 에피 소드가 시작되게 된다. 두 번째, 본 작업은 분절된 (Discrete) 상태가 아닌 연속된(Continuous) 상태/행동 문 제로 정의된다. 이러한 다차원의 연속된 상태/행동 문제 는 분절된 상태/행동 문제보다 풀기 어려운 문제이기에, Natural Actor-Critic (NAC)과 같이 이러한 문제를 해결할 수 있는 효과적인 기법을 도입해야 한다[9]. 그러나, NAC 은 다차원 역행렬을 구하기 위해 많은 계산량 부담을 가지기 때문에, 박주영 등은 RLS 필터를 이용하여 역행 렬을 재귀적으로 연산하는 수정된 NAC 알고리즘을 제 안한 바 있다[10]. 하지만 이 알고리즘은 무한으로 반복 되어 종결 상태가 없는 작업(Non-episodic task)에 맞게 구성되어 있으므로, 본 연구에서 다루고 있는 것과 같 은 에피소딕 작업에 바로 적용되기 힘들다. 그리하여 본 논문에서는 Peters의 논문에서 제시된 episodic NAC 알고리즘을 기반으로 하여 RLS 필터를 접목시킨 새로 운 알고리즘을 유도하였고, 이를 “RLS-based eNAC algorithm”라 부르기로 한다.
The RLS-based eNAC algorithm 는 Actor 와 Critic라는 두 개의 분리된 메모리 구조로 분리되어 구성된다. Actor 구조에서는 각 상태에서의 행동을 결정하게 되고, Critic 구조에서는 Actor 구조에서 선택한 행동에 대하여 좋고 나쁜지를 비판하게 된다. Actor 구조에서 정책은 다음과 같이 π(a|s) =p(a|s,θ)로 구성되며, 정책 매개 변수 θ 는 아래와 같은 갱신률에 의하여 반복적으로 갱신된다.
( )
θJ
θ← + ∇θ α θ . (9)
이 식에서, ∇θJ( )θ 목적함수의 기울기이다. Peters 등의 연구에서, 목적함수의 기울기는 Amari 에 의하여 연구된 Natural Gradient Method로부터 유도된다[14]. 이 연구로부터 다음과 같이 보다 간단한 갱신률을 설정 할 수 있다:
( )
J w
θ← + ∇θ α θ θ ≈ +θ α . (10)
이 식에서 α(0≤α≤1) 는 학습률이다. 본 연구에서는, 정책 매개 변수를 갱신하는 과정에서 TD 오차를 최소화 하기 위하여 최소-제곱법을 이용한 TD-Q(λ) 알고리즘을 Critic 구조에 적용하였다. 식 (8)에 제시된 가치 함수 갱신률에 따라, 가치 함수는 두 개의 Critic 정보 벡터인 양립 가능 함수 근사자
( , )t t log ( t t)T t
A s aπ = ∇θ π a s w 및 가치 함수 Vπ(s)1의 합으로 근사된다.
한 에피소드 동안 진행된 모든 상태 단계의 정보를 종합하면, 다음과 같은 식으로 정리될 수 있다.
0 0
[ log ( ) ,1][ , ] N ( , )
N t T T T T i
t t i i
t i
a s r
γ θ π γ
= =
∇ =
∑
w v∑
s a . (11)식 (11)에서, 벡터 w는 식 (10)의 Actor 매개 변수를 갱신시키고, 벡터 v는 가치 함수를 근사화 시키는데 쓰인다. 이러한 과정을 거쳐, 식 (11)를 최소 제곱 문제로 다룰 수 있게 된다.
식 (11)을
0 [ log ( ) , 1]T
N t T
t t
t θ a s
φ%=
∑
=γ ∇ π , χ= w v[ T, T T] , 그리고0 ( , )
N i
i i
r%=
∑
i= γ rs a 로 명시하면, 식 (11)은 아래와 같이 표현할 수 있다.A b-1
χ= , (12)
여기서 b= %%φr, 그리고 A= % % 이다. 이러한 방법을 φφT 통하여, 해 벡터 χ 는 모든 에피소드들을 통하여 축적된 정보를 한번에 풀어 구할 수 있게 된다.
첫 번째 에피소드가 끝나게 되면, Critic 정보 행렬인 A, b, χ 는 다음과 같이 갱신되게 된다.
0 0 0
A ≈δI+φ φ% % , T P0≈A0−1. (13)
식 (13)에서, 양의 스칼라 상수인 δ를 가진 추가 단위 행렬 δI가 초기에 덧붙여지는데, 이는 행렬의 가역성을
1 본 유도과정에 대한 보다 자세한 설명은 [9] 참조
보장하기 위함이다. 두 번째 에피소드에 대한 Critic 갱신부터는, 역행렬 A는 다음과 같은 RLS 알고리즘에 의하여 구할 수 있다[15]:
1
1
1 1
1 ,
,
( ).
T e e e e
e e T
e e e
e e
e T
e e e
T
e e e e e e
P P
P P
P k P
P k r
φ φ
β β φ φ
φ β φ φ
χ χ φ χ
+
+
+ +
⎛ ⎞
= ⎜⎝ − + ⎟⎠
= +
= + −
% %
% %
%
% %
%
(14)
식 (14)에서, β (0≤β≤1) 는 망각 인자로써, 과거 정보를 축적하는 과정속에서 감쇠 작용의 역할을 한다. 표 2 에서는 RLS-based episodic Natural Actor-Critic 알고리즘의 전체 과정을 보여준다.
3.2.3 확률적 행동 선택
정책 π는 각 상태에서 주어지는 행동인 강성 타원에 대한 형태와 방향의 변화율을 계획한다. 고로, 한 에피소드 과정 동안 강성 타원의 매개 변수들은 정책에 의하여 변화되게 된다. 따라서, 본 학습 알고리즘의 최종 목표는 에피소드 동안의 최적 강성 타원 궤도를 찾는 것으로 정리될 수 있다.
본 연구에서, 정책 π는 가우시안 밀도 함수의 형태를 가진다. 그러므로 Critic 구조의 양립 가능 함수 근사자
log (a st t)T
θ π
∇ 는 아래와 같은 확률적 정책 모델 에
표 2. RLS-based Natural Actor-Critic 알고리즘 Initialize each parameter vector:
0,A ,b ,st
θ θ= =0 =0 =0 for each episode, Run simulator:
for each step,
Take action at, from stochastic policy π, then, observe next state st+1, reward rt. end
Update Critic structure:
if first update,
Update critic information matrices, following the initial update rule in (13).
else
Update critic information matrices,
following the recursive least-squares update rule in (14).
end
Update Actor structure:
Update policy parameter vector following the rule in (10).
repeat until converge
의하여 유도 가능하며, 유도 과정은 Kimura의 연구를 참조하였다[16].
2 2
1 ( )
( ) ( , ) exp( )
2 2
a s Ν a a μ
π μ σ
σ π σ
= = − − . (15)
확률적 행동 선택은 가우시안 밀도 함수의 조건에 따라 결정되므로, 식 (15)의 평균 μ 및 표준 편차 σ 를 결정함으로써 행동 선택을 조절할 수 있다. 이러한 변수들을 다음과 같이 나타낸다.
,
T act t act act t
μ =ξ ω s , 0.001 1
1 exp( )
act act
act
σ ξ
η
⎛ ⎞
= % ⎜⎝ + + − ⎟⎠. (16)
본 식에서, 평균 μ는 Actor 매개변수 벡터 ω 와 각각의 상태에서의 상태 벡터 st 의 내적으로 구해지며, 표준 편차 σ는 시그모이드(Sigmoid) 함수의 형태를 가지며, 또 다른 Actor 매개 변수인 η 에 의하여 결정된다. 각각의 식들은 계수 ξ 및 ξ%에 의하여 스케일 값이 조정된다. 상태 벡터 st=[x x x x1 12& &1 2 ]T 는 5×1의 길이를 가지며, 로봇의 관절값 및 속도를 요소로 가진다. 2장에 명시되어 있듯이, 정책 π는 2개의 행동을 결정한다. 따라서, Actor 매개 변수 벡터 w=[ωT, ηT]T 는 10개의 평균 관련 요소 및 2개의 표준 편차 관련 요소를 가지며, 총 12×1 의 길이를 가진다.
4. 시뮬레이션 4.1 시뮬레이션 모델링
2절 링크 머니퓰레이터에 대한 시뮬레이션 모델은 그림 3에 나타나 있다. 이에 대한 동역학 시뮬레- 이터는 MSC.ADAMS2005를 이용하여 구성하였고, 제어 알고리즘은 Matlab/Simulink(Mathworks, Inc.) 을 이용하여 구현하였다.
학습과 관련된 매개 변수들은 α = 0.005, β = 0.99, γ = 0.99로 설정하였다. 또한, 안정성을 위하여 각 상태에서의 행동 변화율은 방향에 대하여 [-10, 10](degree), 그리고 형태에 대하여 [-1,1](ratio)로 제한하였다. 강성 타원의 초기치는 방향에 대하여 0º, 그리고 형태에 대하여 1:4 비율로 설정하였다.
이러한 수치를 초기값으로 하여 강성타원은 각 상태에서의 정책 행동에 따라 변화된다.
4.2 시뮬레이션 결과
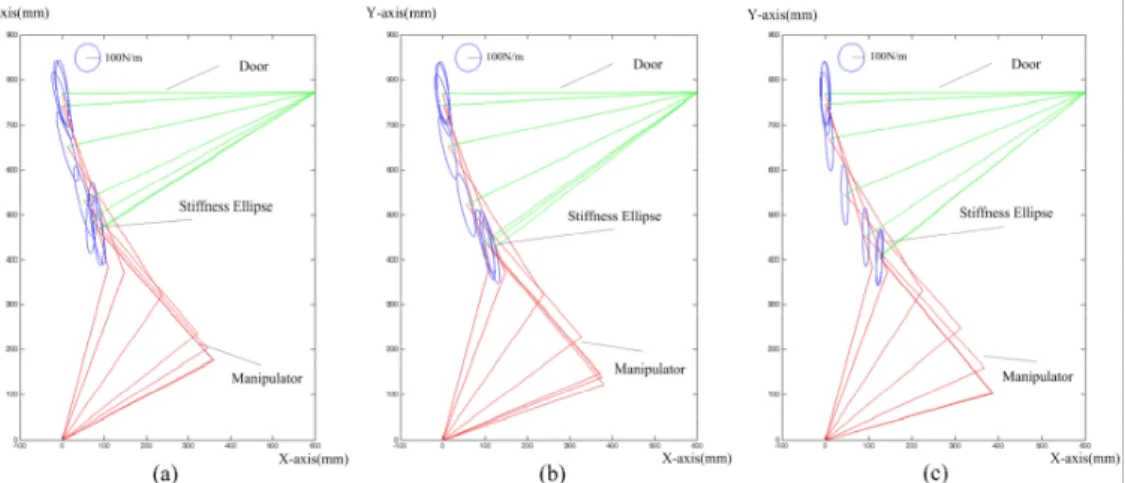
본 연구에서는 그림 4에서 나타난 바와 같은 3개의 다른 목표 경로를 이용하여 시뮬레이션을 수행하였다.
그림 3. Schematic model of the task. The manipulator’s end- effector is connected with door knob by revolute joint hinge. The door hinge has joint spring-damper.
3개의 목표 경로는 문 손잡이 위치에 대한 센서 오차를 반영한 불확실성을 부과하기 위하여 설정되었다. 그림 4에서 명시된 “Under-steering”/“Over-steering” 및 “Exact- steering”에서의 각도 차이는 5 º 이다.
그림 5는 각각의 목표 경로에 대하여 강성 타원을 학습한 결과이다. 강성 타원은 정책에 따른 행동에 의하여 상태 전이가 일어나는 과정속에서 이의 형태 및 방향이 변화되게 된다. 그림의 결과는 총 200회의 학습 반복을 거친 후 얻어졌다. 결과로부터 알 수 있듯이, 다음과 같은 해석을 내릴 수 있다. 즉, 문 손잡이 궤적 방향에 대한 강성의 증가는 목표 궤적에 대한 위치 오차를 줄이기 위함이고, 목표 방향에 대하여 수직
그림 4. A representation of virtual trajectory. (dotted line:
actual door knob’s trajectory )
방향에 대한 강성의 감소는 문 손잡이에서 발생하는 각각의 다른 목표 궤적에 대하여 강성 타원은 비슷한 경향성을 가지게 된다. 대략적으로, 타원의 주축은 문 손잡이 경로의 접선 방향을 향하고 있으며, 타원의 형태는 보다 날카로워진다. 이러한 경향성을 관찰한 바, 간섭력을 줄이기 위함이다.
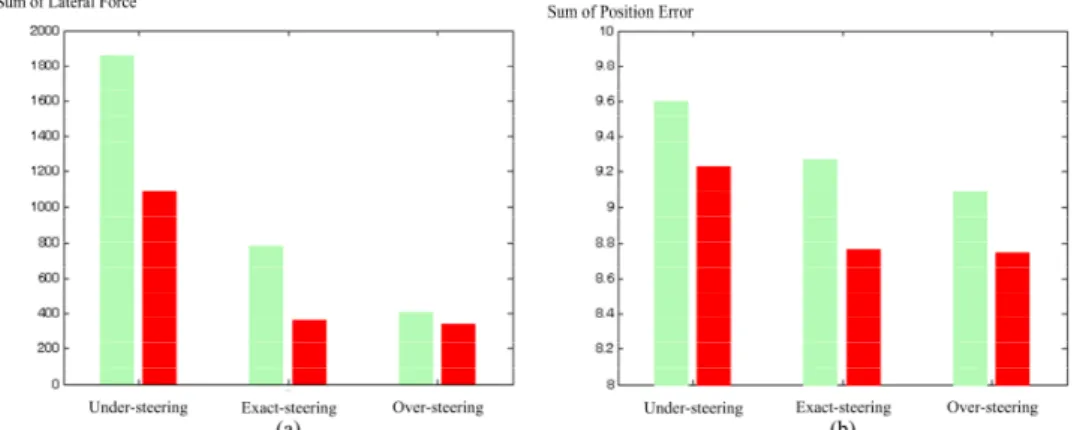
그림 6에서는 작업 목표에 대한 학습 결과를 보여준다. 이를 통하여 각각의 작업 목표는 학습 이후 뚜렷이 감소함을 알 수 있다. 위치 오차 및 간섭력에 대한 작업 목표수치에서, “Exact-steering” 및 “Over- steering” 경우가 가장 뛰어난 작업 성능을 보여주었다.
이에 반하여, “Under-steering”의 경우에서는 두 가지 항목 모두에서 가장 나쁜 성능을 보여주었다. 이는
“Under-steering”의 조건을 가질 때 가장 나쁜 작업 조건이 됨을 의미한다. 하지만, 본 연구에서 제시한 학습 전략을 통하여, “Under-steering”의 경우에 있어서도 작업 성능이 크게 개선됨을 알 수 있다.
그림 5. Stiffness ellipse trajectory. (a) Under-steering. (b) Exact Steering. (c) Over-steering
5. 결 론
불확실한 환경에서의 접촉 작업 수행능력은 인간이 거주하는 공간에서의 로봇 작업이 보편화됨에 따라 점점 그 중요성을 증가시키고 있다. 본 연구에서는 접촉 작업의 수행에 있어서 임피던스 학습 전략을 제시하였다. 여기서 우리는 문 열기 작업에 대한 작업 성능을 제안한 학습 기법을 통하여 향상됨을 보여주었다. 또한, 문의 크기에 대한 불확정성 속에서도 적응성을 가짐을 보여주었다. 이러한 전략을 통하여 다양한 접촉 작업 수행이 필요한 서비스 로봇을 위한 행동 스킬을 학습시킬 수 있을 것이다.
[1] T. Flash, “The Control of Hand Equilibrium Trajectories in Multi-Joint Arm Movement,” Biol. Cybern. vol. 57, pp.
257-274, 1987.
[2] S. Park and T. B. Sheridan, “Enhanced Human-Machine Interface in Braking,” IEEE Trans. Sys. Man, and Cyber., - Part A: Sys., and Humans, vol. 34, no. 5, pp. 615-629, 2004.
[3] N. Hogan, “Impedance control: An approach to manipulation: Part I. Theory, Part II. Implementaion, Part III. Application,” ASME J. Dynamic Syst. Measurement Control, vol. 107, pp. 12-24, 1985.
[4] M. Cohen and T. Flash, “Learning Impedance Parameters for Robot control using Associative Search Network,”
IEEE Trans. Robot. Automat., vol. 7, no. 3, pp. 382-390, 1991.
[5] J. Izawa, T. Kondo, and K. Ito, “Biological Robot Arm Motion through Reinforcement Learning,” In Proc. of IEEE Int . Conf. on Robotics and Automat., vol. 4, pp.
3398-3403, 2002.
[6] S. Jung, S. B. Yim and T. C. Hsia, “Experimental Studies of Neural Network Impedance Force Control of Robot Manipulator,” In Proc. of IEEE Int . Conf. on Robotics and Automat., pp. 3453-3458, 2001.
[7] T. Tsuji, M. Terauchi, and Y. Tanaka, “Online Learning of Virtual Impedance Parameters in Non-Contact Impedance Control Using Neural Networks,” IEEE Trans. Sys. Man, and Cyber., - Part B: Cyber., vol. 34, no. 5, pp. 2112-2118, 2004.
[8] R. S. Sutton and A. G. Barto, Reinforcement learning: An Introduction, MIT Press, 1998.
[9] J. Peters, S. Vijaykumar, and S. Schaal, “Reinforcement Learning for Humanoid robotics,” In IEEE Int. Conf. on Humanoid robots, 2003.
[10] J. Park, J. Kim, and D. Kang, “An RLS-Based Natural Actor-Critic Algorithm for Locomotion of a Two-Linked Robot Arm,” In Proc. of Int. Conf. CIS, Part I, LNAI, vol.
3801, pp. 65-72, 2005.
[11] H. Asada and J-J. E. Slotine, Robot Analysis and Control, John Wiley & Sons, Inc., 1986.
[12] J. Won, “The Control of Constrained and Partially Constrained Arm Movement,” S. M. Thesis, Dep. Of Mechanical Engineering, MIT, Cambridge, MA, 1993.
[13] T. Flash and N. Hogan, “The Coordination of Arm Movements: An Experimentally Confirmed Mathematical Model,” J.of Neurosci., vol. 5, n. 7, pp. 1688-1703, 1985.
[14] S. Amari, “Natural Gradient Works Efficiently in Learning,” Neural Computation, vol. 10, 1998.
[15] T. K. Moon and W. C. Stirling, Mathematical Methods and Algorithm for Signal Processing, Prentice Hall, Upper Saddle River, NJ, 2000.
[16] H. Kimura and S. Kobayashi “An Analysis of Actor/Critic Algorithms using Eligibility Traces: Reinforcement Learning with Imperfect Value Functions,” In Proc. of Int.
Conf. on Machine Learning, pp. 278-286, 1998.
그림 6. The learning result of performance indices. (a) Sum of position error.
(b) Sum of lateral force. (blue bar: lightgreen learning, red bar: after learning).
참 고 문 헌
강 성 철 1989 서울대학교 기계설계학
과 (공학사)
1991 서울대학교 기계설계학 과 (공학석사)
1998 서울대학교 기계설계학 과 (공학박사)
2002 일본기계기술연구소 (Post Doc.)
1991~현재 KIST 인지로봇연구단 책임연구원 관심분야 : Dependable 매니퓰레이션, 위험작업-용 필드
서비스 로봇, Haptic, Tactile Interface 박 신 석 1989 서울대학교 기계설계학
과 (공학사)
1991 서울대학교 기계설계학 과 (공학석사)
1999 MIT 기계공학과 (공학 박사)
2000 Nissan Motor Co. (방문연구원) 2002 Harvard Univ. (Post Doc.) 2004 Keio Univ. (방문교수)
2004~현재 고려대학교 기계공학과 부교수
관심분야 : Surgical Robotics, Biomimetic Robotics, Human- Machine Interface
강 병 덕
2006 고려대학교 기계공학과 (공학사)
2008 고려대학교 기계공학과 (공학석사)
2008~현재 현대중공업 근무 관심분야 : Human-Machine Interface, 로봇 머니-퓰레이터
김 병 찬
2005 고려대학교 기계공학과 (공학사)
2007 고려대학교 기계공학과 (공학석사)
2008~현재 KIST 인지로봇연 구단 위촉연구원 관심분야 : Machine Learning, Biomimetic Robotics