제31회 한글 및 한국어 정보처리 학술대회 논문집 (2019년)
문장 유사성 분석을 위한 한국어 패러프레이즈 말뭉치 및 구축 가이드라인
오교중1◦, 김현민2, 고보원1, 남제현1, 최호진1 한국과학기술원 전산학부1
주식회사 리비, 인공지능 솔루션팀2
{aomaru,bowon.ko,sammy25,hojinc}@kaist.ac.kr, [email protected]2
Korean Paraphrase Corpus and Building Guidelines for Sentence Similarity Analysis
Kyo-Joong Oh1◦, Hyunmin Kim2, Bowon Ko1, Jehyun Nam1, Ho-Jin Choi1 KAIST, School of Computing1
Leevi, AI Solutions2 요 약
최근 각 산업분야에서 대화 시스템과 챗봇 기술의 업무로의 도입이 활발해짐에 따라 한국어 패러프레이즈 기술에 대한 관심이 높아지고 있다. 기존에는 연구와 평가 목적으로 규모는 작아도 잘 정제된 평가셋을 만드는 것이 중요했으나, 최근에는 기계학습 기술의 발달로 학습을 위한 일정 수준의 품질을 보장하는 대량의 말뭉치를 빠르게 확보하는 방법이 중요해지고 있다. 본 논문에서는 현재 수행하고 있는 한국어 패러프레이즈 말뭉치 구축 경험과 방법에 대해 소개한다.
주제어: 말뭉치, 문장유사성분석, 패러프레이즈
1. 서론
최근 각 산업 분야에서 대화 시스템과 챗봇 기술의 업무로 의 도입이 활발해짐에 따라 한국어 패러프레이즈 인식 기술에 대한 관심이 높아지고 있다. 주로 상담 업무나 직원 교육, 내부 정보 검색 시스템에 활용되고 있으며, 간단한 질문에 대한 답 변을 자동으로 제공한다. 이를 통해 덜 중요한 민원이나 단순한 질문에대한 응답 업무를 줄여주고, 보다 복잡하고 전문성있는 상담에 집중할 수 있게 해준다. 대화 시스템과 챗봇 기술에서는 시스템의 성능을 평가하는 지표로 응답률과 정답률을 사용한 다. 여기서 응답률이란 전체 입력 문장에 대하여 얼마나 답변 을 제공하는지에 대한 지표이며, 정답률은 응답을 제공한 질문 중에서 정답인 비율을 뜻한다. 응답률을 향상시키기 위한 방 법으로는, 예상되는 질의 문장을 최대한 확보하여 답변 지식을 미리 구축하고, 입력된 질의에 대한 답을 제공할 수 있는 지식을 탐색하는 방법을 이용한다.
이를 위해 기존에는 자주하는질문(FAQs) 지식을 구축하고 질문의 변형 사례를 최대한 확보하여 검색에 사용하는 방법을 사용하고 있다. 이 방법은 응용 도메인과 시스템마다 별도의 질 문-답변 지식을 구축해야 하고, 다수의 변형 문장을 만들어서 답변 지식에 추가해야 한다. 따라서 질문의 변형을 모두 입력할 수 없을 뿐만 아니라, 답변을 제공할 수 있는 질문과 시나리오 의 종류와 답변의 유형이 한정되며, 시스템 구축 이후 지식을 추가하거나 삭제해야 할 때 관리상의 어려움이 존재한다. 이 같은 한계를 극복하기 위해 선행 연구에서는 기계학습 기반의 분류 모델을 사용하여 질의 문장의 도메인과 화행 분류 자질을 사용하여 답변을 찾는 방법[1]과, 문장 임베딩 자질을 이용한 유사성 분석 기술을 적용하여 표현상의 변형에도 의미적 유사 성을 가진 질문을 인식할 수 있는 방법[2]을 제안하고 있다.
이 같은 기계학습 기반의 방법을 응용 시스템에 적용하기 위해서는 학습과 평가를 위한 충분한 양의 말뭉치가 필요하 다. 기존에는 연구와 평가 목적으로 규모는 작아도 잘 정제된 평가셋을 만드는 것이 중요했으나, 최근에는 기계학습 기술의 발달로 모델 학습을 위한 일정 수준의 품질을 보장하는 대량의 말뭉치를 빠르게 확보하는 방법이 중요해 지고 있다. 그러나 현장에서 실제 개발을 하는 과정에서는 이를 위한 인력과 시간 투입이 어려운 실정이다. 본 논문에서는 그 동안 몇번의 실제 현장 개발 경험을 바탕으로 현재 수행하고 있는 한국어 패러프 레이즈 말뭉치 구축 경험과 방법에 대해 소개하고자 한다.
2. 상담 대화 기반 유사 문장 말뭉치
처음으로 실제 상담 데이터를 기반으로 질문-답변 사례 말 뭉치를 만드는 작업에 착수했다. 상담용 챗봇 시스템 사업을 수행하면서, 기업 내부에 상주하여 개인정보가 포함된 상담은 제외하고 익명화된 데이터를 제공받았다.
첫번째로 수행한 전처리 과정은 화자의 구분이다. 일부 시스 템에서는 화자 구분을 하지 않고 상담 데이터를 제공하였는데, 이는 질의-응답 쌍 데이터를 정제하고 추출하는데 반드시 필요 한 과정이다. 인사말이 자동으로 제공되는 시스템의 경우에는 대화의 시작이 대부분 시스템이 자동으로 생성하는 인사말로 시작하기 때문에, 이를 통해 대화 별 시작과 끝을 구분할 수 있 었다. 기본적으로 상담은 일대일로 이루어지는 대화이기 때문 에 시작 화자를 기준으로 차례로 번갈아 가며 화자가 변경되며, 상담 대화의 특성 상 일정 수준의 길이를 넘어가는 답변의 경우 에 상담원이 제공하는 답변인 경우가 많음을 발견할 수 있었다.
또한 질문이나 응답이 앞 문장에 이어지는지 분석하기 위해서 시스템마다 발화 시작자가 누구인지 파악해야 한다.
- 527 -
제31회 한글 및 한국어 정보처리 학술대회 논문집 (2019년)
먼저 형태소 분석을 통해 ”네”, ”아니요”, ”응”, ”아니” 등의 대꾸를 표현하는 감탄사들로 시작하는지를 보고 화자가 변경 되었음을 판단 할 수 있다. 일부 문장에서는 ”음”, ”아”, ”네”, ” 그렇군요” 등과 같은 단순 응대를 위한 표현이 있었는데, 이 단 계에서는 제거하지 않고 그대로 화자 주석을 달아 구분하였으 며 추후 정제 단계에서 제외하였다. 그리고 질문 다음 문장에서
” 란 말씀이시죠?”, ” 말이죠?” 와 같이 확인을 위한 서술어룰 포함하는 경우 상담원으로 인식하여 보정을 하는 작업을 추가 하였다. 응답 문장 다음에 확인에 해당하는 표현을 포함하는 경우, 고객으로 인식하여 보정을 진행하였다. 마지막으로 상담 대화의 특성 상 ”죄송합니다”, ”잠시만 기다려 주시겠습니까?”
와 같은 상담원이 자주 사용하는 표현들로 상담원을 유추해 낼 수 있었다. 이와 같은 형태소 기반의 표현 사전을 구성하고, 위 의 논리를 기반으로 화자를 구별하여 주석을 달아주는 모듈을 구현 할 수 있었으며, 이 모듈의 화자 인식 정확도는 97.3%로 실시간 대화 화자 인식 시스템에 활용하고 있다.
두번째로 수행한 전처리 과정은 발화된 질의과 응답의 인 식이다. 질의에 대한 분류를 수행하거나, 질문-답변 쌍 지식을 자동으로 추출하는 모듈을 만들기 위해서는 발화 질의를 인식 하는 것이 중요하다. 상담 대화는 대체로 인사말, 질의, 응답, 설명, 응대로 구성된다. 우리가 분석하는 대화 데이터는 대부분 구어체로 대화가이루어지기 때문에 응대에 해당하는 표현들이 많이 포함되어 있으며, 이 때문에 사용자의 질문이나 상담원의 답변이 끊기는 것을 발견할 수 있었다. 그 뿐만 아니라 상담 원의 응답과 추가 질의가 순서 상 섞이기 때문에, 질의 문장을 찾아내고 해당 질의에 대한 응답 문장을 찾아 정제하는 전처리 모듈이 필요했다. 또한 일부 시스템에서는 상담원마다 별도의 인사말이나 상담 전 내담자의 정보를 수집하는 멘트를 제공 하기도 하였기 때문에 상담 대화 중 질문의 대화가 시작되는 지점을 파악하는 것이 중요했다.
표 1. 질의 응답 문장 인식에 사용한 종결어미 표현
구분 종결어미
평서문 어미 -다/-는다-/-ㄴ다, -네 -구나/-는구나, -군/는군, -으마/-마 -을걸/-ㄹ걸, -을게/ㄹ게, -을래/-ㄹ래 -을라/-ㄹ라, -는단다/-ㄴ단다/-단다/-란다 의문문 어미 -으냐/-냐/-느냐, -으니/-니, -대, -담
-련, -으랴/-랴, -을쏘냐/-ㄹ쏘냐 명령문 어미 -아라/-어라/-여라, -으려무나/려무나
-으렴/-렴, -소서, -아/-어, -지 후종결어미 -고, -니까, -며, -면서
인용어미 -단다, -느냔다, -란다, -잔다, -대
서술어부를 구성하는 형태소의 패턴과 기호를 통해 질문을 인식하였다. 문장의 마지막 형태소가 종결어미 표 1에 해당하지 않는 경우 이어지는 문장으로 간주하였으며, 이어지는 문장에 서 ”아”, ”음”, ”네”, ”말씀하세요” 응 단순 응대에 해당하는 감탄사나 표현이 나오는 경우, 해당 표현을 제거함으로써 정제 된 질문과 답변 문장을 추출할 수 있었다.
위와 같은 전처리 구현하여 질의-응답 쌍 데이터를 자동으 로 추출하는 모듈을 구현하였다. 실제 질문으로 인식되었으나 이어지는 대화에서 상담원과 연결해야한다는 응답이나 저희는 관련 서비스를 제공하지 않는다는 답변은 제외하였다. 이를 통 해 금융권 상담 대화에 해당하는 질의 응답 말뭉치를 구축 할 수 있었으며, 현재 130만 쌍 규모의 원시 말뭉치를 확보하였 으며, 현재 12,000 쌍 규모의 정제 말뭉치를 구축하였다. 추후 추가 정제 작업과 검토 작업을 거쳐 원시 말뭉치를 학습용 정제 말뭉치로 정제할 예정이다.
3. 뉴스 기반 패러프레이즈 말뭉치 구축
지금까지 특정 응용 도메인을 위한 말뭉치 구축 경험에 대 하여 소개하였다. 추가적으로 [2]에서 구현한 문장 유사성 분석 기술을 상담용 챗봇 시스템 뿐만 아니라 추가 응용 도메인에 활용할수 있는 말뭉치를 만들고자 하였다. 주로 뉴스 기사에 달리는 댓글이나 리뷰를 분석하는 업무에서, 유사한 제목의 기 사를 수집하기 위해 구축되었다. 기존의 영문 패러프레이즈 말 뭉치 구현 사례의 경우, 사진이나 영상의 내용을 설명하는 자막 문장을 이용하여 구축(MSRvid)하거나, 이 방법과 같이 뉴스 기사에서 패러프레이즈 문장 쌍을 추출(MSRpar)하였다[3].
표 2. 유사성 점수 주석 가이드라인[4]
점수 설명
5점 문장의 의미가 완전히 동일함, 두 문장 안에 들어있는 정보의 양과
의미가 완전히 동일한 경우.
접사, 접속사가 일부 다를 수 있음 4점 중요한 상세사항이 같지만 중요하지 않은
상세사항이 다르거나 서술어 수준이 다른 경우.
3점 핵심 문장이 같지만
중요한 상세사항에 차이가 발생하는 경우.
2.4점 핵심 문장은 다르지만 핵심 대상이 같은 경우.
2점 핵심 대상이 다르지만 문장 구조가 유사하거나 1개 이상의 단어 구가 동일한 경우 1점 동일한 단어가 존재하는 경우 0점 동일한 단어가 하나도 존재하지 않는 경우
- 528 -
제31회 한글 및 한국어 정보처리 학술대회 논문집 (2019년)
먼저 정치, 경제, 사회, 생활/문화, IT/과학, 스포츠 6개 도 메인에 대하여, 본문의 내용이 10문장 이상 존재하는 10,000 개씩의 같은 숫자의 기사를 크롤링하였다. 그리고 머릿말과 꼬 릿말에 해당하는 내용을 제거하고, 오타와 띄어쓰기를 수정하 는 전처리를 수행하였다. 그리고 3단어 이상 15단어 이하의 단어 개수를 가진 단문 문장에 대하여 기존 모델로 임베딩하여 임베딩 벡터를 추출하고, 유사성 분석을 수행하였다.
도메인 별로 4000 쌍 정도의 원시 말뭉치를 추출하고 [4]에 소개한 태깅 가이드라인 표 2에 따라 주석 작업을 수행하였다.
그렇게 구축된 주석 말뭉치의 점수에 따른 데이터 통계를 보 고 균등 분포가 되도록 말뭉치를 정제하는 작업을 반복하면서 학습 및 평가 말뭉치를 확장하였다. 최종적으로 정제된 5,000쌍 의 패러프레이즈 관계를 같는 문장 쌍을 구축하였다. 점수마다 데이터의 개수 보고 균등 분포가 되도록 말뭉치를 정제하는 작 업을 반복하면서 학습 및 평가 말뭉치를 확장하였다. 이 과정을 통해 특정 키워드를 검색하여 나오는 기사들의 제목을 유사성 분석을 통해 주제 별로 묶을 수 있었으며, 이를 통해 대상이나 주제 별로 댓글이나 리뷰의 긍부정 정보를 추적할 수 있었다.
4. GLEU STS-B 번역 말뭉치
학습용 말뭉치와 별도로 기계학습 모델을 통해 학습된 성능 을 비교할 공통적인 평가셋이 필요하다. 추가적으로 General Language Understanding Evaluation (GLUE) bechmark의 Semantic Textual Similarity Benchmark(STS-B) 태스크 평 가셋[3]을 한국어로 번역하는 작업을 수행하였다. GLEU는 자 연어 이해 시스템에서 학습, 평가, 분석을 위해 공개하는 대표 평가셋으로로 자연어 처리 성능 테스트를 할 수 있는 영어 평가 셋으로써 누구나 다운 받아 활용할 수 있다. 이 데이터의 구성은 학습(5,748 문장 쌍), 검증(1,500 문장 쌍), 평가(1379 문장 쌍) 총 3개의 데이터 셋으로 구성되어있으며, 장르(자막, 뉴스), 제 작 연도, 출처, 문장 2개와 사람이 직접 만든 유사성 점수로 이루 어져 있다. 이 점수를 바탕으로 학습을 통해 구축한 유사성 분석 모델의 성능을 피어슨 스피어만 상관계수(Pearson-Spearman Correlation coefficient)로 측정할 수 있다. 현재 이 데이터의 한국어 번역 말뭉치가 없는 상황이었으며, 번역가를 고용하여 약 2달의 작업 기간을 거쳐 완성하였으며, 다음과 같은 번역 가이드라인을 세우고 번역 작업을 수행하였다.
1. 직역 보다는 한국어에서 자연스러운 표현으로 번역한다. A, An, The와 같은 관사의 경우 직역을 하지 않는다.
2. 두 문장의 표현이 너무 유사해 질 경우 직역 표현을 사용한 다. 예로 진행형, 수동태 등의 표현에 해당한다.
3. 여러 표현으로 번역이 될 수 있는 다의어의 경우 되도록이면 다른 표현 사용하여 번역한다. 예를 들어 ”연주하다(Play)”
와 같이 ”불다”, ”치다”, ”켜다” 등으로 번역할 수 있다.
4. 상하위 개념어가 존재하는 경우 의미를 보존하는 경우 해당 어휘를 사용하여 표현을 다양화한다.
5. 영어 원문에 오타가 있는 경우, 원문 그대로 둔다. 원문 데 이터의 경우 숫자가 제거되어 있는데 ”00”과 같은 표현으로 치환한다.
5. 결론
지금까지 한국어 문장 유사성 분석과 패러프레이즈 연구를 위한 말뭉치 구축 방법에 대해 이야기하였다. 처음에는 특정 응용 서비스나 시스템을 위한 학습용 말뭉치를 최대한 확보하 기 위해 집중하였으나, 추가적으로 뉴스 기사를 이용하여 여러 도메인에서 범용적으로 사용하기 위한 말뭉치를 만드는 작업 과 이미 잘 알려진 평가용 말뭉치의 번역도 수행하였다. 뉴스 기사 기반 말뭉치(5,000쌍)와 STS-B 번역 말뭉치(약 8,600쌍) 는 정제 과정을 거쳐 추후 관련 연구를 위해 공개 할 예정이다.
감사의 글
이 논문은 2019년도 정부(과학기술정보통신부)의 재원으로 정보통신기획평가원의 지원을 받아 수행된 연구임 (No.2013- 2-00131, 휴먼 지식증강 서비스를 위한 지능진화형 Wise QA 플랫폼 기술 개발)
참고문헌
[1] K. Oh, D. Lee, C. Park, H. Choi, Y. Jeong, S. Kwon, and S. Hong, “Out-of-domain detection based on sen- tence distance for dialogue system,” In Proc. of The 1st International Workshop on Dialog Systems (IWDS 2018) in The 5th International Conference on Big Data and Smart Computing (BigComp2018), pp. 673–676, 2018.
[2] K. Oh, S. Kwon, S. Park, and H. Choi, “Question under- standing based on sentence embedding on dialog systems for banking service,” In Proc. of The 6th IEEE Inter- national Conference on Big Data and Smart Computing (BigComp2019), pp. 266–268, 2019.
[3] D. Cer, M. Diab, E. Agirre, I. Lopez-Gazpio, and L. Spe- cia, “Semeval-2017 task 1: Semantic textual similarity multilingual and cross-lingual focused evaluation,” Pro- ceedings of the 10th International Workshop on Semantic Evaluation (SemEval 2017), 2017.
[4] B. Ko, K. Oh, J. Nam, and H. Choi, “Korean paraphrase corpus construction, semantic textual similarity annota- tion method,” In Proc. of The 3rd Asian Conference on Artificial Intelligence Technology (ACAIT 2019), p. 39, 2019.
- 529 -
제31회 한글 및 한국어 정보처리 학술대회 논문집 (2019년)
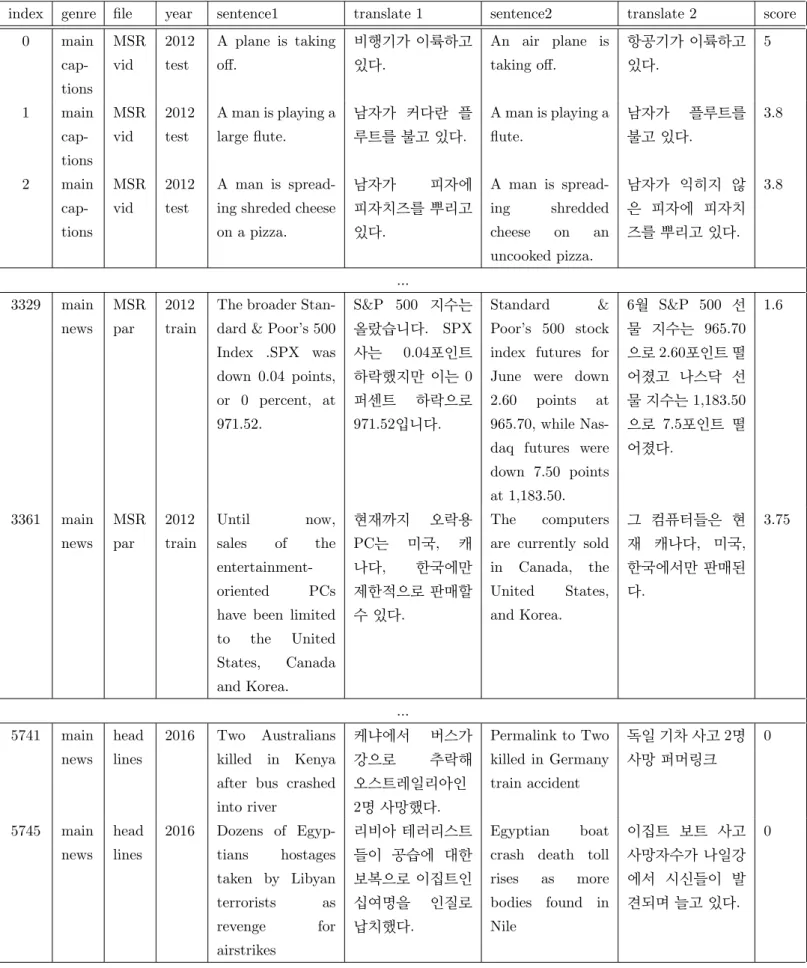
표 3. GLEU STS-B 번역 말뭉치 발췌
index genre file year sentence1 translate 1 sentence2 translate 2 score 0 main
cap- tions
MSR vid
2012 test
A plane is taking off.
비행기가 이륙하고 있다.
An air plane is taking off.
항공기가 이륙하고 있다.
5
1 main cap- tions
MSR vid
2012 test
A man is playing a large flute.
남자가 커다란 플 루트를 불고 있다.
A man is playing a flute.
남자가 플루트를 불고 있다.
3.8
2 main cap- tions
MSR vid
2012 test
A man is spread- ing shreded cheese on a pizza.
남자가 피자에
피자치즈를 뿌리고 있다.
A man is spread- ing shredded cheese on an uncooked pizza.
남자가 익히지 않 은 피자에 피자치 즈를 뿌리고 있다.
3.8
...
3329 main news
MSR par
2012 train
The broader Stan- dard & Poor’s 500 Index .SPX was down 0.04 points, or 0 percent, at 971.52.
S&P 500 지수는 올랐습니다. SPX 사는 0.04포인트 하락했지만 이는 0 퍼센트 하락으로 971.52입니다.
Standard &
Poor’s 500 stock index futures for June were down 2.60 points at 965.70, while Nas- daq futures were down 7.50 points at 1,183.50.
6월 S&P 500 선 물 지수는 965.70 으로 2.60포인트 떨 어졌고 나스닥 선 물 지수는 1,183.50 으로 7.5포인트 떨 어졌다.
1.6
3361 main news
MSR par
2012 train
Until now, sales of the entertainment- oriented PCs have been limited to the United States, Canada and Korea.
현재까지 오락용 PC는 미국, 캐 나다, 한국에만 제한적으로 판매할 수 있다.
The computers are currently sold in Canada, the United States, and Korea.
그 컴퓨터들은 현 재 캐나다, 미국, 한국에서만 판매된 다.
3.75
...
5741 main news
head lines
2016 Two Australians killed in Kenya after bus crashed into river
케냐에서 버스가
강으로 추락해
오스트레일리아인 2명 사망했다.
Permalink to Two killed in Germany train accident
독일 기차 사고 2명 사망 퍼머링크
0
5745 main news
head lines
2016 Dozens of Egyp- tians hostages taken by Libyan terrorists as revenge for airstrikes
리비아 테러리스트 들이 공습에 대한 보복으로 이집트인 십여명을 인질로 납치했다.
Egyptian boat crash death toll rises as more bodies found in Nile
이집트 보트 사고 사망자수가 나일강 에서 시신들이 발 견되며 늘고 있다.
0