2019, 30
(3)
,587–596
기계학습 기반의 대공장비 수리부속 수요예측모형 연구
기
ᆷ재동
1
·이한준2
1한국국방연구원·2한남대학교 글로벌IT경영학과
ᄌ ᅥ
ᆸᄉ ᅮ 2019ᄂ ᅧ ᆫ 3ᄋ ᅯ ᆯ 5ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2019ᄂ ᅧ ᆫ 4ᄋ ᅯ ᆯ 17ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2019ᄂ ᅧ ᆫ 4ᄋ ᅯ ᆯ 24ᄋ ᅵ ᆯ
요 약
ᄌ
ᅡ ᆼᄇ ᅵᄋ ᅴ ᄉ ᅮᄅ ᅵᄇ ᅮᄉ ᅩ ᆨ ᄉ ᅮᄋ ᅭᄋ ᅨᄎ ᅳ ᆨᄋ ᅳ ᆫ ᄀ ᅮ ᆨ ᄇ ᅡ ᆼ ᄋ ᅨᄉ ᅡ ᆫᄌ ᅵ ᆸᄒ ᅢ ᆼ ᄒ ᅭᄋ ᅲ ᆯᄉ ᅥ ᆼᄋ ᅦ ᄉ ᅡ ᆼᄃ ᅡ ᆼᄒ ᅡ ᆫ ᄋ ᅧ ᆼᄒ ᅣ ᆼᄋ ᅳ ᆯ ᄆ ᅵᄎ ᅵᄂ ᅳ ᆫ ᄀ ᅮ ᆫ ᄉ ᅮ ᄇ ᅮ ᆫ ᄋ ᅣᄋ ᅴ ᄆ ᅢᄋ ᅮ ᄌ ᅮ ᆼ ᄋ
ᅭᄒ ᅡ ᆫ ᄀ ᅪᄌ ᅦ ᄌ ᅮ ᆼ ᄒ ᅡᄂ ᅡᄋ ᅵᄃ ᅡ. ᄋ ᅵᄋ ᅦ ᄋ ᅮᄅ ᅵ ᄀ ᅮ ᆫ ᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄌ ᅡ ᆼᄇ ᅵ ᄌ ᅥ ᆼᄇ ᅵ ᄀ ᅪᄌ ᅥ ᆼᄋ ᅦᄉ ᅥ ᄇ ᅡ ᆯᄉ ᅢ ᆼᄒ ᅡᄂ ᅳ ᆫ ᄀ ᅪ ᆫᄅ ᅧ ᆫ ᄃ ᅦᄋ ᅵᄐ ᅥᄅ ᅳ ᆯ ᄌ ᅥ ᆼᄇ ᅩᄎ ᅦᄀ ᅨ ᄋ
ᅦ ᄎ ᅮ ᆨᄌ ᅥ ᆨᄒ ᅡᄋ ᅧ ᄉ ᅮᄋ ᅭᄋ ᅨᄎ ᅳ ᆨ ᄋ ᅦ ᄒ ᅪ ᆯᄋ ᅭ ᆼ ᄒ ᅡᄀ ᅩ ᄋ ᅵ ᆻᄃ ᅡ. ᄌ ᅵ ᄀ ᅳ ᆷ ᄁ ᅡᄌ ᅵᄋ ᅴ ᄋ ᅧ ᆫᄀ ᅮᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄉ ᅵᄀ ᅨᄋ ᅧ ᆯᄀ ᅵᄇ ᅥ ᆸᄋ ᅳ ᆯ ᄒ ᅪ ᆯᄋ ᅭ ᆼ ᄒ ᅡ ᆫ ᄉ ᅮᄅ ᅵᄇ ᅮᄉ ᅩ ᆨ ᄉ ᅮᄋ ᅭ ᄋ
ᅨᄎ ᅳ ᆨ ᄋ ᅵ ᄌ ᅮᄅ ᅲᄅ ᅳ ᆯ ᄋ ᅵᄅ ᅮᄋ ᅥ ᆻᄋ ᅳᄂ ᅡ ᄋ ᅨᄎ ᅳ ᆨ ᄌ ᅥ ᆼᄒ ᅪ ᆨ ᄃ ᅩᄀ ᅡ ᄂ ᅡ ᆽᄋ ᅡ ᄀ ᅢᄉ ᅥ ᆫᄋ ᅵ ᄋ ᅭᄀ ᅮᄃ ᅬᄀ ᅩ ᄋ ᅵ ᆻᄃ ᅡ. ᄋ ᅵᄋ ᅦ ᄇ ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄋ ᅮᄉ ᅥ ᆫ ᄋ ᅲ ᆨᄀ ᅮ ᆫ ᄌ
ᅡ ᆼᄇ ᅵᄌ ᅥ ᆼᄇ ᅵᄌ ᅥ ᆼᄇ ᅩᄎ ᅦᄀ ᅨᄋ ᅦᄉ ᅥ 17,451,247ᄀ ᅢᄋ ᅴ ᄌ ᅥ ᆼᄒ ᅧ ᆼ ᄆ ᅵ ᆾ ᄇ ᅵᄌ ᅥ ᆼᄒ ᅧ ᆼ ᄒ ᅡ ᆼᄆ ᅩ ᆨᄋ ᅳ ᆯ ᄑ ᅩᄒ ᅡ ᆷᄒ ᅡᄂ ᅳ ᆫ ᄐ ᅳ ᆨᄌ ᅥ ᆼ ᄃ ᅢᄀ ᅩ ᆼ ᄌ ᅡ ᆼᄇ ᅵ ᄌ ᅥ ᆼᄇ ᅵ ᄃ ᅦᄋ ᅵᄐ ᅥᄅ ᅳ ᆯ ᄉ
ᅮᄌ ᅵ ᆸᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄎ ᅬ ᄀ ᅳ ᆫ ᄇ ᅵ ᆨᄃ ᅦᄋ ᅵᄐ ᅥ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄀ ᅪ ᄒ ᅡ ᆷᄁ ᅦ ᄌ ᅮᄆ ᅩ ᆨ ᄇ ᅡ ᆮᄀ ᅩ ᄋ ᅵ ᆻᄂ ᅳ ᆫ ᄃ ᅦᄋ ᅵᄐ ᅥ ᄆ ᅡᄋ ᅵᄂ ᅵ ᆼ ᄆ ᅵ ᆾ ᄐ ᅦ ᆨᄉ ᅳᄐ ᅳ ᄆ ᅡᄋ ᅵᄂ ᅵ ᆼ ᄀ ᅵᄇ ᅥ ᆸᄋ ᅳ ᆯ ᄒ ᅪ ᆯᄋ ᅭ ᆼ ᄒ
ᅡᄋ ᅧ ᄉ ᅮᄅ ᅵᄇ ᅮᄉ ᅩ ᆨ ᄉ ᅮᄋ ᅭᄋ ᅨᄎ ᅳ ᆨ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆯ ᄌ ᅦᄋ ᅡ ᆫᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄌ ᅦᄋ ᅡ ᆫ ᄃ ᅬ ᆫ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆫ ᄀ ᅵᄌ ᅩ ᆫ ᄋ ᅴ ᄉ ᅵᄀ ᅨᄋ ᅧ ᆯᄀ ᅵᄇ ᅥ ᆸᄋ ᅦ ᄇ ᅵᄒ ᅢ ᄒ ᅣ ᆼᄉ ᅡ ᆼ ᄃ ᅬ ᆫ ᄋ ᅨᄎ ᅳ ᆨᄌ ᅥ ᆼ ᄒ ᅪ
ᆨ ᄃ ᅩᄅ ᅳ ᆯ ᄇ ᅩᄋ ᅵ ᆷᄋ ᅳ ᆯ ᄒ ᅪ ᆨ ᄋ ᅵ ᆫᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄃ ᅦᄋ ᅵᄐ ᅥ ᄆ ᅡᄋ ᅵᄂ ᅵ ᆼ, ᄉ ᅮᄅ ᅵᄇ ᅮᄉ ᅩ ᆨ, ᄉ ᅮᄋ ᅭᄋ ᅨᄎ ᅳ ᆨ, ᄉ ᅵᄀ ᅨᄋ ᅧ ᆯ ᄀ ᅵᄇ ᅥ ᆸ, ᄐ ᅦ ᆨᄉ ᅳᄐ ᅳ ᄆ ᅡᄋ ᅵᄂ ᅵ ᆼ.
1. 서론 ᄀ
ᅮ
ᆨ방예산에 대한 압박이 가중되는상황에서 국방 운영효율화는 국방 분야의 핵심 이슈 중 하나이다.
ᄐ ᅳ
ᆨ히, 군수 분야는 운영 방식에 따라 그 성과가 크게 달라질 수 있어 효율화 요구가 높은 분야이다. 군수 ᄇ
ᅮᆫ야의 여러 과업 중적정한 수리부속확보는장비가동률보장과 국방예산의 효율적 집행을위해 중요성 ᄋ
ᅵ 크다. 적정 수리부속 확보는정확한 수요예측으로부터 가능하며, 지금까지 수요예측정확도 제고를 ᄋ
ᅱ한 많은연구들이 진행되어왔다.
ᄀ
ᅵ존 문헌에서 수요예측방법은크게 정성적 방법과 정량적 방법으로 구분할 수 있다. 먼저 정성적 기 버
ᆸ은예측자들의 주관적인 판단이나 의견을 중심으로 예측하는방법으로서 인덱스 방법, 컨조인트 방법, ᄃ
ᅦᆯ파이 방법 등의 기법이 있다 (Kim과 Lee, 2017). 계량화된데이터를이용하는정량적 방법에는크게 ᄉ
ᅵ계열기법과 데이터 마이닝으로 분류할 수 있다 (Song과 Turner, 2006). 본연구에서는정량적 기법 ᄀ
ᅪ관련된수요예측 분야의 기존 문헌을토대로 논의를 진행하고자 한다.
ᄆ
ᅥᆫ저, 시계열 분석 기법은 일정기간 동안 변화하는변수를 분류하여 움직임을예측하는기법이다. 시 ᄀ
ᅨ열기법에는 다양한 종류가 있는데 지수평활법, ARIMA (auto-regressive integrated moving aver- age) 기법 등이 가장 대표적이다. 지수평활법은 단순지수평활법과 이중지수평활법 등으로 구분할 수 이
ᆻ다. 단순지수평활법은과거의 수요값으로 미래 예측을 할 때 최근 자료에 더 많은 가중치를부여하 ᄋ
ᅧ 예측하는방법이다 (Trigg와 Leach, 1967). 단순지수평활법은 일정한 변동만이 존재할 경우에는적 저
ᆯ한 예측치를제공하여 준다. 그러나 만일 추세에 따라서 시계열 자료가 변동이된다면 추세 조정 지수
1
(02455) ᄉ ᅥᄋ ᅮ ᆯᄐ ᅳ ᆨᄇ ᅧ ᆯᄉ ᅵ ᄃ ᅩ ᆼ ᄃ ᅢᄆ ᅮ ᆫ ᄀ ᅮ ᄒ ᅬᄀ ᅵᄅ ᅩ 37, ᄒ ᅡ ᆫᄀ ᅮ ᆨᄀ ᅮ ᆨ ᄇ ᅡ ᆼᄋ ᅧ ᆫᄀ ᅮᄋ ᅯ ᆫ ᄀ ᅮ ᆨ ᄇ ᅡ ᆼᄌ ᅡᄋ ᅯ ᆫᄋ ᅧ ᆫᄀ ᅮᄉ ᅦ ᆫᄐ ᅥ, ᄉ ᅥ ᆫᄋ ᅵ ᆷᄋ ᅧ ᆫᄀ ᅮᄋ ᅯ ᆫ.
2
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (34430) ᄃ ᅢᄌ ᅥ ᆫᄀ ᅪ ᆼᄋ ᅧ ᆨᄉ ᅵ ᄃ ᅢᄃ ᅥ ᆨᄀ ᅮ ᄒ ᅡ ᆫᄂ ᅡ ᆷᄅ ᅩ 70, ᄒ ᅡ ᆫᄂ ᅡ ᆷᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄀ ᅳ ᆯ ᄅ ᅩᄇ ᅥ ᆯITᄀ ᅧ ᆼᄋ ᅧ ᆼᄒ ᅡ ᆨᄀ ᅪ, ᄌ ᅩᄀ ᅭᄉ ᅮ.
E-mail: [email protected]
펴
ᆼ활법인 이중지수평활법 또는 홀트지수평활법을적용한다 (Holt, 1957). 또 다른대표적인 시계열기법 주
ᆼ하나인 ARIMA기법은 시계열 데이터의 과거치가 설명변수로 표현하는 AR (auto-regression)과정 ᄀ
ᅪ 과거관측치의 오차항들을설명변수로 표현하는 MA (moving-average)과정, 그리고 불안정적인 시 ᄀ
ᅨ열 자료의 평균과 분산의 차이를안정적인 시계열 자료로 변환하기 위한 과정으로서 차분을적용한 기 버
ᆸ이다. ARIMA 기법의 변형된기법으로서 계절적 변동 특성을고려한 SARIMA (seasonal ARIMA) ᄆ
ᅩ형이 제안되었는데 Goh와 Law (2002)에서는 SARIMA모형이 8개의 다른시계열기법 대비 우수한 서
ᆼ능을 보였으며 ARIMA 기법도 SARIMA 기법을 제외한 다른 시계열기법 보다 높은정확도를 보였 ᄃ
ᅡ. 그러나 Chatfield (2004)에서와 같이 하나의 수요예측방법이 보편적으로 모든경우 우월한 정확도 르
ᆯ보이는경우는없었다. Weatherford와 Kimes (2003)은 7가지 수요예측방법의 성능을비교분석하 ᄋ
ᅧ
ᆻ는데 대상별로 서로 다른방법의 수요예측정확도가 가장 높았다. 이는수요예측의 성능이 기법의 복 ᄌ
ᅡ
ᆸ성보다 과거 데이터의 적합한 특성을잘 반영하는정도에 따라 영향을받는것으로 해석된다.
ᄃ
ᅡ음으로 데이터마이닝은대규모 데이터에서 유용한 정보와관계를탐색하고 분석 및 모형화하여 지 시
ᆨ을 식별하는 일련의 과정으로 정의할 수 있다 (Berry와 Linoff, 1997; Lee, 2006; Lee와 Kim, 2014).
ᄃ
ᅦ이터 마이닝은의사결정나무 (decision tree), 베이지안넷 (Bayesian net), SVM (support vector ma- chine) 등다양한 종류가 있으며 각 기법의 성능을향상시키기 위한 여러 연구들이 진행되어왔다 (Choi ᄃ
ᅳᆼ, 2016). 의사결정나무란 의사결정 규칙을나무 구조로 도표화 하여관심대상이 되는 클래스를몇 개 ᄋ
ᅴ 작은 클래스로 분류하거나 예측을수행하는 분석 방법으로 알고리즘에 따라 여러 종류로 나눌수 있 ᄃ
ᅡ. CHAID (chi-square automatic interaction detection) 알고리즘은 통계적 접근방식으로 카이제곱 거
ᆷ정이나 F 검정을이용하여 다지분리 방법으로 분류하는알고리즘이다 (Kass, 1980). CART (classi- fication and regression tgree)알고리즘은지니 지수 (Gini index) 또는 분산의 감소량을활용한 두 개 ᄋ
ᅴ 자식 노드로 분류하여 의사결정나무를 형성하는 알고리즘이다 (Breiman, 2017). 의사결정나무 기 버
ᆸ은 지금까지 다양한 분야의 예측연구에활용되고 있다 (Law 등, 2004). 베이지안넷은 불확실한 환 겨
ᆼ하에서 지식을표현하고 결과를추론하고자 할 때 유용하게 쓰이는기법이다 (Cooper와 Herskovits, 1992). Bradford와 Paul (1990)에서는 베이지안넷을 이용하여 계절 유행상품에 대한 적정 재고 예측 ᄆ
ᅩ델을개발한 바 있다. 비선형 기법인 SVM은 2개의 범주를 분류하는이진 분류 기법으로 분리 기준이 ᄃ
ᅬ는최대 마진 분리 경계면 (maximum margin hyperplane)의 원리로 판단하는 분류 기법이다 (Vap- nik, 1979). Pai 등 (2006)에서는 ARIMA기법 대비 SVM 기반의관광객 수 수요예측연구가 우수한 서
ᆼ능을보인 바 있다.
ᄒ
ᅡᆫ편, 현재 군수 분야의 수리부속 수요예측방법은 육해공 각 군별로 시계열기법 중심으로 적용되고 이
ᆻ다. 육군의 적용기법은 품목별 회귀식의 기울기와 편차율로 3가지 (산술평균법, 이동평균법, 최소자 ᄉ
ᅳᆼ법) 기법으로 분류하여 예측하고 있다. 해군의 적용기법은연도별로 예측된그래프를 통해 품목관리 ᄌ
ᅡ들이 결정하는방식으로 8가지 (산술평균법, 이동평균법, 최소자승법, 가동이동평균법, 단순지수평활 버
ᆸ, 이중지수평활법, 홀트지수평활법, 원터지수평활법) 기법으로 예측하고 있다. 공군의 기법은 분기별 ᄃ
ᅦ이터로 X-1년도 수요예측 실시 후 X년도 실제 수요와 비교하여 수요예측정확도가 높은기법을적용 ᄒ
ᅡ는방법으로 5가지 (가중이동평균법, 선형이동평균법, 추세분석법, 단순지수평활법, 선형지수평활법) ᄀ
ᅵ법을적용하고 있다 (Kim과 Lee, 2017). Park과 Jeon (2008)은 월별 항공기 수리부속 중고장빈도 ᄀ
ᅡ 높은 50여개 부품을추출하여 ARIMA 기법을적용하였는데, 기존수요예측정확도보다 개선된 결과 르
ᆯ보였다. Moon (2012)은해군수리부속수요예측시 데이터 수요 데이터의 상관관계 분석을 통해 적 ᄒ
ᅡᆸ한 기법을적용함으로써 수요예측정확도를개선한 바 있다.
ᄋ ᅡ
ᇁ서 살펴본바와 같이 데이터 마이닝은다양한 분야에서 수요예측정확도 제고 가능성을보였다. 본 ᄋ
ᅧᆫ구에서는의사결정나무, 베이지안넷, SVM 등의 데이터 마이닝 기법을활용하여 수리부속수요예측 ᄆ
ᅩ형을제시하고 정확도 측면에서 기존시계열기법과 비교분석하고자 한다.
2. 수리부속 수요예측 모형 제안
2.1. 데이터 수집 ᄇ
ᅩᆫ 연구의 대상인 대공장비는 유사시 북한의 저고도 침투에 대한 대응책으로 개발한 단거리 대 ᄀ
ᅩ
ᆼ미사일 체계이다. 본 연구에서는 육군 장비정비정보체계의 정비테이블에서 대상 장비와 관련한 17,451,247개 트랜잭션 데이터를 수집하였다. 수집된 데이터는 Table 2.1에서와 같이 장비명, 정비 ᄂ
ᅡ
ᆯ짜, 소모 개수, 불출단위, 소모단위, 대당구성 수, 등에 대한 정보와 정비시 담당자가 기록하는정비내 ᄋ
ᅧ
ᆨ 등이 포함되어 있다.
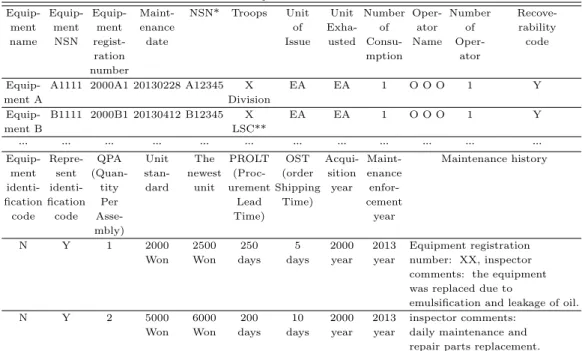
Table 2.1 Examples of the transaction data
Equip- Equip- Equip- Maint- NSN* Troops Unit Unit Number Oper- Number Recove-
ment ment ment enance of Exha- of ator of rability
name NSN regist- date Issue usted Consu- Name Oper- code
ration mption ator
number
Equip- A1111 2000A1 20130228 A12345 X EA EA 1 O O O 1 Y
ment A Division
Equip- B1111 2000B1 20130412 B12345 X EA EA 1 O O O 1 Y
ment B LSC**
… … … … … … … … … … … …
Equip- Repre- QPA Unit The PROLT OST Acqui- Maint- Maintenance history ment sent (Quan- stan- newest (Proc- (order sition enance
identi- identi- tity dard unit urement Shipping year enfor-
fication fication Per Lead Time) cement
code code Asse- Time) year
mbly)
N Y 1 2000 2500 250 5 2000 2013 Equipment registration
Won Won days days year year number: XX, inspector comments: the equipment was replaced due to
emulsification and leakage of oil.
N Y 2 5000 6000 200 10 2000 2013 inspector comments:
Won Won days days year year daily maintenance and repair parts replacement.
* NSN: national stock number, ** LSC: logistics support command
2.2. 변수 추출 ᄃ
ᅢ공장비의 수리부속 품목수는 총 1,014개이다. 이 과정에서 수리부속별로 2010년부터 2014년까지 5개년 간의 연도별 데이터로 정형 및 비정형 데이터로 나누어 변수를추출하였다. 정형 데이터는 Table 2.1에 나온항목외에 장비운영시간, 정비운영거리 및 연도별 소모 개수 등을추가로 추출하였다. 비정 혀
ᆼ 데이터는정비 내역에서 TF-IDF (term frequency-inverse document frequency)가 높은 50개의 단 ᄋ
ᅥ를 추출하였다. TF-IDF는전체 문서 대비 특정 문서 내의 단어별 출현 빈도로서, 각 단어의 중요도 ᄅ
ᅳᆯ 식별할 수 있는값으로활용된다 (Witten, 2005).
최종적으로활용한 변수는 Table 2.2와 같이 78개의 변수이다. 목표변수는 품목별 2015년 소요발생 ᄋ
ᅧ부 데이터로서 총 1,014개였다. 이 중 484개 품목은소요가 발생하였고, 530개 품목은 소요가 발생 ᄒ
ᅡ지 않았는데 밸런싱을위해 소요가 발생하지 않은 530개 품목 중 484개 품목을 5개 데이터셋 (data set)으로 무작위 추출하고 데이터셋당 968개 품목을 실험에활용하였다.
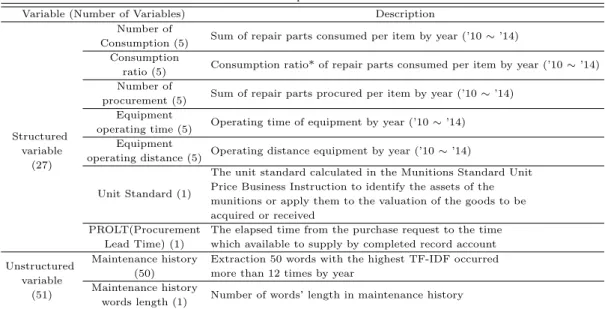
Table 2.2 Description of variables
Variable (Number of Variables) Description
Structured
Number of
Sum of repair parts consumed per item by year (’10 ∼ ’14)
variable
Consumption (5)
(27)
Consumption
Consumption ratio* of repair parts consumed per item by year (’10 ∼ ’14) ratio (5)
Number of
Sum of repair parts procured per item by year (’10 ∼ ’14) procurement (5)
Equipment
Operating time of equipment by year (’10 ∼ ’14) operating time (5)
Equipment
Operating distance equipment by year (’10 ∼ ’14) operating distance (5)
Unit Standard (1)
The unit standard calculated in the Munitions Standard Unit Price Business Instruction to identify the assets of the munitions or apply them to the valuation of the goods to be acquired or received
PROLT(Procurement The elapsed time from the purchase request to the time Lead Time) (1) which available to supply by completed record account Unstructured Maintenance history Extraction 50 words with the highest TF-IDF occurred
variable (50) more than 12 times by year (51) Maintenance history
Number of words’ length in maintenance history words length (1)
* Consumption ratio = Number of consumption / Number of procurement
2.3. 모형 수립 ᄇ
ᅩᆫ 연구에서는시계열기법과 데이터 마이닝을활용한 모형을비교하였다. 시계열기법은 가중이동평 규
ᆫ법, 단순이동평균법, 지수평활법, 최소자승법, 홀트기법의 5개 기법을적용하여 각 기법별 결과를 산 추
ᆯ하였다. 여기서 최적기법으로 선택 방법은각 기법별 MSE (mean squared error; 평균자승오차) 비 ᄀ
ᅭ를 통해 가장 낮은 MSE를갖는기법을최적기법으로 선택하여 차년도 수요 예측정확도를도출하였 ᄃ
ᅡ. 데이터 마이닝에서는대표적인 분류예측기법인 의사결정나무, 베이지안넷과 SVM을사용하였으며 저
ᆼ형 데이터 모형과 정형·비정형 데이터 모형을비교하였다.
부
ᆫ석도구로는두 가지 모형으로 결과를 도출하였다. 본 분석결과 중의사결정나무는 SPSS Answer Tree프로그램의 CHIAD 알고리즘을적용하여 분석을수행하였고, 나머지 기법은 Weka 3.6.10을사용 ᄒ
ᅡ였다. 보다 신뢰성 높은값을제시하기 위하여 5개의 데이터셋을대상으로 모형을구축하여 실험하였 ᄃ
ᅡ.
3. 실험결과
3.1. 모형 평가 보
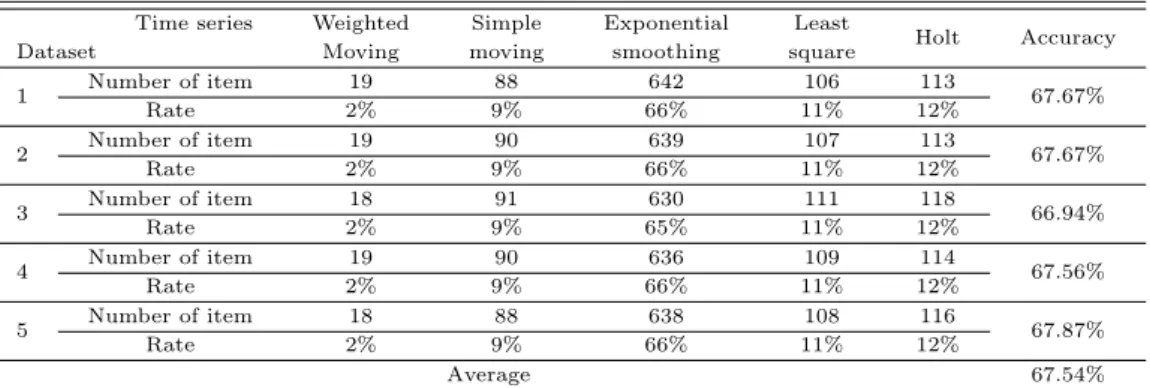
ᆫ 실험에서는시계열기법과 데이터 마이닝을 비교분석하였다. 시계열기법은 5개 (가중이동평균법, ᄃ
ᅡᆫ순이동평균법, 지수평활법, 최소자승법, 홀트기법)의 기법을적용하여 비교 평가하였다. Table 3.1에 ᄉ
ᅥ 보는바와 같이 가장 많이 선택된기법은지수평활법이었으며 5번째 데이터셋에서 67.87%의 정확도 ᄅ
ᅳᆯ나타냈다.
Table 3.1 Prediction accuracy of time series methods Time series Weighted Simple Exponential Least
Holt Accuracy
Dataset Moving moving smoothing square
1 Number of item 19 88 642 106 113
67.67%
Rate 2% 9% 66% 11% 12%
2 Number of item 19 90 639 107 113
67.67%
Rate 2% 9% 66% 11% 12%
3 Number of item 18 91 630 111 118
66.94%
Rate 2% 9% 65% 11% 12%
4 Number of item 19 90 636 109 114
67.56%
Rate 2% 9% 66% 11% 12%
5 Number of item 18 88 638 108 116
67.87%
Rate 2% 9% 66% 11% 12%
Average 67.54%
ᄃ
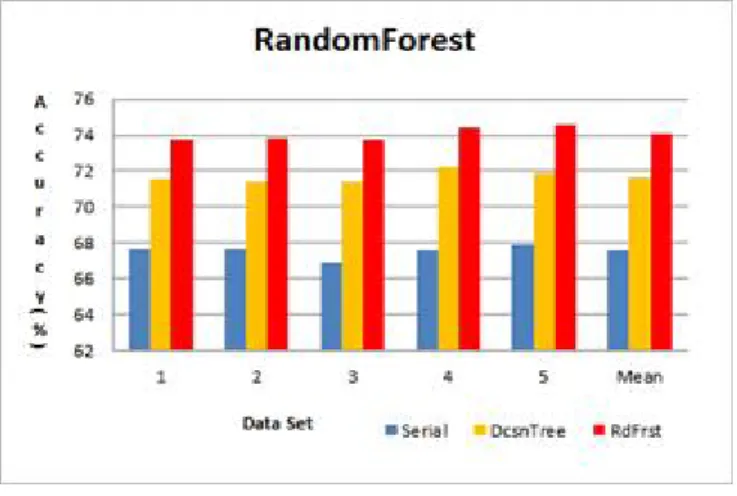
ᅦ이터 마이닝은 훈련셋 (training set)과 테스트셋 (test set)을 7:3의 비율로 나누어 10겹 교차 검증 (10-fold cross validation)방식을 사용하였다. 정확도를 기준으로 모형의 성능을 평가한 결과, Table 3.2 및 Figure 3.1에서 보는바와 같이 가장 높은 정확도는정형·비정형 데이터 모형에서 의사결정나무 ᄋ
ᅴ 4번째 데이터셋이 72.21%로 나타났다. 이 때의 컨퓨전 행렬 (confusion matrix)은 Table 3.3에서 보 느
ᆫ바와 같았다. 평균적으로는정형·비정형 데이터 모형 중의사결정나무가 71.69%으로 가장 우수한 예 ᄎ
ᅳᆨ정확도를나타냄을확인할 수 있었다.
Table 3.2 Prediction accuracy comparison of data mining models Dataset
1 2 3 4 5 Avg.
Method
Decision Structd only 66.94 67.36 66.63 67.36 65.29 66.72
Tree Structd & Unstructd 71.59 71.38 71.38 72.21 71.9 71.69
Bayesian Structd only 61.98 62.4 61.67 61.88 62.6 62.11
Structd & Unstructd 58.68 59.4 58.68 58.88 58.99 58.93
SVM Structd only 69.52 67.87 67.56 68.49 67.77 68.24
Structd & Unstructd 68.7 69.83 68.7 69.21 69.73 69.23
Table 3.3 Confusion matrix for decision tree model (Dataset 4) Predicted: Y Predicted: N Total
Actual: Y 348 136 484
Actual: N 133 351 484
Total 481 487 72.21%
Figure 3.1 Prediction accuracy comparison of data mining models
3.2. 분류규칙 ᄀ
ᅮ축한 모형 중가장 정확도가 우수했던 정형·비정형 데이터 모형 (4번째 데이터셋)의 의사결정나무 부
ᆫ류규칙은 Figure 3.2와 같이 나타났다. 이 규칙에서 노드 수는 19개이며 깊이는 4로 나타났다. 결 ᄀ
ᅪ에 따르면, 대상 대공장비 수리부속소요예측에 정형 데이터 중큰 영향력을 가진 변수는 직전 연도 ᄒ
ᅩᆨ은 4∼5년 전의 장비운영시간이었으며 비정형 데이터에서는정비내역의 문자길이 및 “이동정비”, “점 거
ᆷ” 등의 단어가 수요예측정확도에 영향력이 높다는것을확인할 수 있었다.
ᄀ
ᅲ칙의 예시를살펴보면 정비내역에 기재된내용의 길이가 47 단어 이상, 147 단어 미만인 경우이면 ᄉ
ᅥ 2011년과 2014년의 장비운영시간이 0일 때, 목표 연도의 수요가 발생할 것으로 예측하였다. 이러 ᄒ
ᅡᆫ 규칙들을 기반으로 수립된의사결정 모델은 본 연구의 데이터셋에 대해 72.21%의 정확도를보였으 ᄆ
ᅧ 기존시계열기법 대비 향상된 결과임을확인할 수 있었다.
Figure 3.2 Classification rules
3.3. 앙상블 기법 적용 결과 ᄋ
ᅨ측력의 제고를 위하여 본 연구에서는추가적으로 앙상블 기법을 적용해보았다. 정형과 비정형 데 ᄋ
ᅵ터를 모두 포함한 데이터셋에 대하여 랜덤포레스트 (random forest)기법 적용하였고, 그 결과 평균 74.07%의 예측정확도를얻을수 있었다. 이는 Table 3.4와 Figure 3.3에서 보는바와 같이 의사결정나 ᄆ
ᅮ기법 대비 평균 2%이상 향상된 성능이었으며 앙상블기법의 적용을 통한 성능향상을확인할 수 있 ᄋ
ᅥᆻ다. 다섯 번째 데이터셋에 대한 랜덤포레스트 기법 적용시 가장 높은정확도인 74.59%를얻을수 있 ᄋ
ᅥᆻ으며 이 때의 컨퓨전 행렬은 Table 3.5와 같이 나타났다.
Table 3.4 Prediction accuracy comparison of three models Dataset
1 2 3 4 5 Avg.
Method
Time series 67.67 67.67 66.94 67.56 67.87 67.54
Decision tree((Un)Structd) 71.59 71.38 71.38 72.21 71.9 71.69
Random forest((Un)Structd) 73.76 73.86 73.76 74.38 74.59 74.07
Figure 3.3 Prediction accuracy comparison of three models
Table 3.5 Confusion matrix for random forest model(Dataset 5) Predicted: Y Predicted: N Total
Actual: Y 327 157 484
Actual: N 89 395 484
Total 416 552 74.59%
4. 결론 및 향후 연구 보
ᆫ연구에서는지난 5개년의 육군대공장비 수리부속수요데이터를수집하고 정비내역과 같은비정형 ᄃ
ᅦ이터를포함한 다양한 정형 데이터 항목을추출하여 데이터 마이닝 기반의 수요예측모형을제안하였 ᄃ
ᅡ. 제안한 수요예측모형은기존의 시계열기법에 비해 향상된 정확도를나타냈다는점에서 의미를 갖 느
ᆫ다.
ᄉ
ᅮ요예측정확도 향상을위하여 수요 발생여부에 영향을미칠 수 있는기상 정보나 지역 특성 정보를 부
ᆫ석에활용하는방안을향후 연구에서 고려해볼수 있다. 또한 수리부속간 연관관계를 식별하여 이를 ᄉ
ᅮ요예측에활용하는것도 의미가 있을것으로 생각한다. 이외에도 본연구에서는단일 어절 단어를변 ᄉ
ᅮ로 활용하였는데 두 어절 이상의 단어를추가적인 변수로 활용하거나, 혹은 유의어 사전을활용하여 ᄃ
ᅡᆫ어의 의미를기반으로 텍스트 마이닝을적용한다면 보다 개선된수요예측정확도를얻을수 있을것으 ᄅ
ᅩ 기대한다.
References
Berry, M. J. and Linoff, G. (1997). Data mining techniques: For marketing, sales, and customer support , John Wiley & Sons, Inc.
Bradford, J. W. and Paul, K. S. (1990). A Bayesian approach to the two-period style-goods inventory problem with single replenishment and heterogeneous poisson demands. The Journal of the Operational Research Society, 41, 211-218.
Breiman, L. (2017). Classification and regression trees, Routledge.
Chatfield, C. (2004). The analysis of time series: An introduction, Chapman and Hall/CRC, London.
Choi, D., Choi, H. and Park, C. (2016). Classification of ratings in online reviews. Journal of the Korean Data & Information Science Society, 27, 845-854.
Cooper, G. F. and Herskovits, E. (1992). A Bayesian method for the induction of probabilistic networks from data. Machine Learning, 9, 309-347.
Goh, C. and Law, R. (2002). Modeling and forecasting tourism demand for arrivals with stochastic non- stationary seasonality and intervention. Tourism Management , 23, 499-510.
Holt, C. C. (1957). Forecasting trends and seasonals by exponentially weighted moving average, Carnegie Institute of Technology.
Kass, G. V. (1980). An exploratory technique for investigating large quantities of categorical data. Applied Statistics, 29, 119-127.
Kim, J. and Lee, H. (2017). A study on forecasting spare parts demand based on data-mining. Journal of Internet Computing and Services, 18, 121-129.
Law, R., Goh, C. and Pine, R. (2004). Modeling tourism demand. Journal of Travel & Tourism Marketing, 16, 61-69.
Lee, H. W. (2006). Data mining application in inbound call center. Journal of the Korean Data & Infor- mation Science Society, 17, 335-344.
Lee, J. and Kim, H. (2014). Identification of major risk factors association with respiratory diseases by data mining. Journal of the Korean Data & Information Science Society, 25, 373-384.
Moon, S. (2012). The impact of demand features on the performance of hierarchical forecasting: Case study for spare parts in the Navy. 29, 101-114.
Pai, P. F., Wei-Chiang, H., Ping-Teng, C. and Chen-Tung, C. (2006). The application of support vec- tor machines to forecast tourist arrivals in barbados: An empirical study. International Journal of Management , 23, 375-385.
Park, Y. J. and Jeon, G. (2008). A demand forecasting for aircraft spare parts using ARMIA. 34, 79-101.
Song, H. and Turner, L. (2006). Tourism demand forecasting, international handbook on the economics of tourism, Edward Elgar, Cheltenham.
Trigg, D. W. and Leach, A. G. (1967). Exponential smoothing with an adaptive response rate. Journal of the Operational Research Society, 18, 53-59.
Vapnik, V. (1979). Estimation of dependences based on empirical data, Nauka, Moscow.
Weatherford, L. R. and Kimes, S. E. (2003). A comparison of forecasting methods for hotel revenue man- agement. International Journal of Forecasting, 19, 401-415.
Witten, I. H. (2005). Text mining, CRC Press, Florida.
2019, 30
(3)
,587–596
A study on predictive model for forecasting anti-aircraft missile spare parts demand based on machine learning
Jaedong Kim
1
· Hanjun Lee2
1Korea Institute for Defense Analyses
2Linton School of Global Business, Hannam University
Received 5 March 2019, revised 17 April 2019, accepted 24 April 2019
Abstract
Spare parts demand forecasting is one of the most critical tasks in logistics, because it considerably affects the efficiency of defense budget execution. Although time series methods have been the most common approach in prior studies, there is still room for improvement in terms of the prediction accuracy. In this study, we gathered 17,451,247 component consumption data including structured and unstructured data from the Defense Logistics Integrated Information System. Using the data, we propose demand forecasting models based on data mining and text mining methods. The results show that our approach can improve the prediction performance compared to that of existing approaches.
Keywords: Data mining, demand forecasting, spare part, text mining, time series.
1
Associate research fellow, Center for Defense Resource Management, Korea Institute for Defense Anal- yses, 37, Hoegi-ro, Dongdaemun-gu, Seoul 02455, Korea.
2