레파지토리 및 프로세스 기반의 데이터 전환 자동화 도구 *
허 민 석**, 김 동 수***, 김 희 완****
목 차
요약1. 서론 2. 관련 연구 2.1 데이터 전환 2.2 데이터 전환 방법
2.3 데이터 전환시 주요 수행 Task 2.4 기존 데이터 전환방법의 문제점 2.5 개선 데이터 전환 방안
3. 데이터 전환 자동화 도구 설계 및 구현 3.1 데이터 전환 레파지토리 3.2 데이터 전환 자동화 도구 설계 3.3 자동화 도구의 구현
4. 자동화 도구 검증
4.1 자동화 도구의 프로젝트 적용 4.2 자동화 도구의 적용 효과 5. 결론
참고문헌 Abstract
요약
ㄴ
데이터를 운영하는 운영시스템은 비지니스의 변경, 고객 요구와 IT 기술의 발달로 정보시스템 재구축 프로젝트는 주기적으로 발생하고 있다. 이 과정에서 기업의 자산인 데이터의 정합성과 무결성을 보장하는 데이터 전환은 중요하다.
데이터 전환의 목표는 현재의 데이터베이스 시스템 운영 환경을 이해하고, 사용 중인 DBMS의 특성을 파악하여, 최적의 데이터베이스 구조를 유지하며, 신 시스템이 최상의 성능을 발휘하도록 해야 한다. 기존 정보시스템에 존재하는 축적된 과거자료를 추출하여 새로운 정보시스템의 개선된 테이블로 옮기는 과정을 말한다. 데이터 전환은 사전에 설계/계획된 규칙에 따라 최종 목적 테이블로 전환하는 전체 과정이다. 따라서, 기존 정보시스템에서 사용하고 있는 데이터를 차세대 시스템 구축 사업에서도 사용할 수 있도록 데이터의 이행은 무엇보다도 중요하다. 본 논문에서는 차세대 시스템 통합 프로젝트 중 중요한 부분인 데이터 전환을 위한 자동화 도구를 설계하였다. 본 연구에서 기존 데이터 전환 방식의 문제점을 분석하여 데이터 전환을 위한 개선방안을 제시하고, 레파지토리와 프로세스 기반의 효율적인 데이터 전환 자동화 도구를 제안하고 실제 차세대 프로젝트의 적용사례를 통해 그 효율성을 검증하였다.
표제어: 데이터 정합성, 데이터 전환, 레파지토리, 프로세스, 자동화 도구
접수일(2020년 4월 6일), 수정일(1차:2020년 6월 3일), 게재확정일 (2020년 6월 10일)
* This paper was supported by the Fund of the Sahmyook University in 2019.
** 제 1저자, ㈜씨에스리컨설팅 수석컨설턴트, [email protected]
*** 건국대학교 정보통신대학원 초빙교수, [email protected]
**** 교신저자, 삼육대학교 컴퓨터공학부 교수, [email protected]
1. 서론
오늘날 데이터의 중요성은 그 어느 때보다도 더욱 부각되고 있다. 이러한 현실은 최근 급격하게 발전하 고 있는 빅 데이터, 4차 혁명, 공공데이터, 데이터 분 석 같은 IT 흐름과도 무관치 않으며, 기업의 데이터 는 곧 자산과 동일시되고 있다. 이러한 데이터를 운 영하는 운영시스템은 기술의 발전과 비지니스의 변경 과 고객 Needs와 IT 기술이 날로 발전함에 따라 정 보시스템 재구축 프로젝트는 5년 ~ 10년 주기로 계 속 발생하고 있다. 이 과정 중 기업의 자산인 데이터 의 정합성과 무결성을 보장하는 데이터 전환은 더욱 중요하다고 할 수 있다. 이러한 기업의 자산인 데이 터를 효율적으로 관리 및 사용하기 위한 정보시스템 이 지속적으로 발전하고 있으며, 기존 정보시스템을 개선하기 위한 차세대 시스템 통합 구축 작업도 꾸준 히 진행 중이다.
본 논문에서는 차세대 시스템 통합 프로젝트 중 중 요한 부분이 데이터 전환(이행)이며, 본 연구를 통해 기존 데이터 전환 방식의 문제점을 분석하여, 생산성 과 효율성은 높이고 Human Error를 최소화 할 수 있는 레파지토리와 프로세스 기반의 데이터 전환 전 용 통합 솔루션을 통한 자동화 방안을 제안하고 실제 적용사례를 통해 그 효율성을 검증하였다.
2. 관련 연구
2.1 데이터 전환
데이터 전환은 기존 시스템에 존재하는 데이터, 즉 구) 정보시스템 혹은 그 외의 방법으로 축적된 과거 자료를 추출(Extracting) 하여 새로운 시스템 (ex. 차 세대 시스템, 신규 시스템 등)의 개선된 테이블로 옮 기는 과정을 말한다. 데이터 전환 담당자는 사전에 설계/계획된 규칙(Mapping, 변환 Rule)에 따라 최종
목적 테이블로 전환하는 전체 과정을 말한다(Korea Database Agency, 2015a; Data Streams, 2017).
데이터 전환의 목표는 현재의 데이터베이스 시스 템 운영 환경을 이해하고, 사용 중인 DBMS의 특성 을 파악하여, 최적의 데이터베이스 구조를 유지하며, 신 시스템이 최상의 성능을 발휘하도록 하는 것이다 (Shin, 2014). Enterprise Strategy Group(ESG)에 따르면, 기업들은 매년 필요로 하는 모든 생산 데이 터의 25%를 전환해야 하는 상황이며 기업 내 데이 터 관리자는 기업들이 보다 다양한 데이터 소스를 수 집하여 분석하고자 하는 욕구가 증가할수록 데이터 전환의 사용자 욕구 충족, 서비스 증대, 비용절감, 응 용프로그램 등 가용성 측면에서 보다 전략적인 관점 으로 적절히 접근해야 하는 의무를 갖는다고 한다 (Data Streams, 2017).
2.2 데이터 전환 방법
아래와 같이 데이터 전환 관련 다양한 방법이 있으 며, 전환 방식별 장단점을 기술한다.
2.2.1 File Export/Import
Source DB에서 테이블에 데이터를 Flat File로 Download 받은 후 Target DB로 Upload 하며, 이때 Redo Log에 기록이 남지 않게 되므로 적재시에 추가 적인 성능 비용이 발생하지 않게 된다. 다만, 1 : 1 전환과 같은 매핑 Rule이 복잡하지 않은 경우에 사용 하며 전환룰이 복잡한 경우에는 사용하기가 어려우 며, 대용량 데이터 전환시에도 전환 소요시간으로 인 하여 사용하기 어렵다 (Kimball Caserta, 2004;
Ralph Kimball and Margy Ross, 2015; Kwon, 2007).
2.2.2 프로그램언어와 SQL
Java, C#과 같은 프로그래밍 언어와 SQL을 이용 하여 전환하며, 해당 프로그래밍 언어 숙련자의 경우
구현하기 쉬우나 소규모형 데이터전환에 적합하며, 대규모 데이터 전환의 경우 관리 대상 테이블이 많고 복잡하므로 프로그램 구현 및 절차형 SQL로 데이터 전환 속도가 느린 단점이 있다.
2.2.3 Stored Procedure
DB Link를 이용하여 다수의 데이터를 집합형 Batch 쿼리 수행으로 인한 속도 향상되지만, 집합형 쿼리의 특성상 All or Nothing 으로 인하여 데이터 전환 중 에러 발생시 처음부터 재실행해야 하는 단점 이 있으므로, 사전 N차에 걸치 데이터 전환 리허설을 통해 오류 발생가능건에 대한 처리가 필요하다.
2.2.4 ETL 솔루션 이용
ETL은 솔루션 사용에 난이도가 있음으로 인하여 초기학습비용이 많이 소요되고, 복잡한 전환 Rule을 매핑하기 쉽지 않은 단점이 있는 반면 데이터 전환설 계가 그대로 전환 프로그램으로 생성등의 공정의 자 동화로 대규모 데이터 전환시에 효율적이다(Ralph Kimbll and M argy Ross, 2015; Korea Database Agency, 2017a).
공통적으로 ETL 솔루션을 이용한 방식을 제외하 고 데이터 전환 설계와 전환 프로그램간의 형상관리 가 주요 관리요소이다.
2.3 데이터 전환시 주요 수행 Task
데이터 전환의 경우에도 일반 개발과정과 같이 분 석, 설계, 구현, 테스트(검증) 단계를 수행하며 추가적 으로 성능관리, 순서제어와 같은 공정이 수행된다.
2.3.1 분석
분석단계에서는 업무 분석, AS-IS vs. TO-BE 테 이블, 컬럼 구조에 대한 분석뿐만 아니라 데이터 전 환 환경에 대한 아키텍처 분석이 수행되어야 한다.
가령 가용서버구성등과 같은 인프라 환경과 DBMS
종류 및 버전 그리고 한글코드와 같은 요소도 주요 분석대상이다.
2.3.2 설계
데이터 전환을 위해서는 AS-IS 뿐만 아니라 TO-BE에 대한 업무를 기반으로 테이블, 컬럼구조에 대하서도 파악하여 테이블 수준 및 컬럼 수준의 매핑 설계를 수행한다. 매핑설계시 컬럼간 매핑, 전환 Rule, 클린징 Rule과 같은 데이터 값들을 변경하기 위한 SQL Rule도 관리되어야 한다. 또한, 전환서버 구성, 전환 스테이징 서버, 네트워크 환경, 용량산정, 데이터 적재 방안, 이기종 DBMS간 데이터 연계 방 안 등과 같은 전환을 위한 최적의 인프라 구성 아키 텍처를 설계한다.
2.3.3 구현
설계 단계에서의 매핑설계, 전환 Rule과 검증단계 의 클린징 Rule을 토대로 SQL을 구현한다.
2.3.4 검증
구현된 SQL을 실제 수행하여 전환 프로그램이 오 류없이 정상적으로 실행되도록 구현되었는지, 전환된 데이터의 값이 이상유무를 검증한다. 검증시 AS-IS vs. TO-BE 테이블간 데이터의 정합성과 테이블간의 데이터 무결성을 중점저적으로 검증하고 AS-IS 오류 데이터를 클린징한다. 부모 자식 테이블간의 참조무 결성과 전환된 데이터의 Key가 Unique 한지 개체 무결성을 검증하며 날짜, 금액등의 도메인에 대해 데 이터 정합성을 검증한다 (Korea Database Agency, 2012; Nho, J.K., 2014; Ko et al, 2011).
2.3.5 형상관리
데이터 전환 매핑설계를 한후에도 데이터 모델은 계속 변경되게 된다. 이때 모델러와 전환팀간에 커뮤 니케이션을 통해 변경된 ERD를 전환매핑설계에 반영 해야 하지만 현실적으로 모델변경을 사전 인지하여
매핑설계가 반영되지 못하고 전환 프로그램 실행 중 에러가 발생했을 때 전환매핑룰을 변경 반영한다. 데 이터 모델 변경으로 인한 형상관리 외에 전환매핑 설계와 전환프로그램간의 형상관리가 주요관리대상 이다. 일반적으로 프로젝트 후반부로 갈수록 전환 매 핑설계는 관리되지 않고, 전환 프로그램 즉 SQL에 전환Rule을 관리하게 되어 형상 불일치가 발생하게 된다.
2.3.6 진척관리
업무 프로그램의 경우 WEB Page 본수 혹은 Windows Application 본수를 토대로 개발 진척율을 관리한다. 데이터 전환의 경우 전환설계의 경우 AS-IS, TO-BE의 테이블 매핑 및 컬럼 매핑설계의 진척율을 관리하고 전환구현의 경우 T0-BE Target 테이블별 전환 프로그램 구현 진척율로 산정한다.
2.3.7 리포트 추출
데이터 전환 관련 리포트의 경우 설계, 검증, 이행 단계에서의 리포트가 있으며 설계 단계에서는 AS-IS vs. TO-BE 테이블 매핑, 컬럼 매핑설계서가 있으며, 검증단계에서는 데이터 클린징 결과서, 실행 이행 단 계에서는 데이터 전환 결과서가 있다. 데이터 전환 결과서에는 전환 Taget 테이블의 실제 전환 소요시 간, 데이터 검증 결과, 데이터 클린징 결과 및 데이터 전환이 있다.
2.3.8 성능관리
Down Time내 전환하기 위해 전환 프로그램 즉 SQL의 튜닝을 통해 최적화하고, 전환 프로그램을 병 렬 Processing과 DB Session을 병렬수행 하도록하 여 전환 실행시간을 최적화 한다(Ralph Kimball and Margy Ross, 2015).
2.3.9 순서제어
TO-BE Target 테이블 전환순서가 정렬되어야 한
다. 예를들어 Master 테이블을 먼저실행하고 Parent Child 관계의 경우 Parent 테이블이 먼저 실행되어야 한다.
2.4 기존 데이터 전환방법의 문제점
기존의 전통적인 매핑설계 작업에는 Excel을 이용 했는데, 테이블 매핑, 컬럼매핑, 코드매핑을 하나의 엑셀로 관리하는 방식이다. 전환설계자가 Excel을 이 용하여 매핑정의서를 작성하면 전환개발자는 매핑정 의서를 토대로 전환 프로그램을 작성한다. 엑셀을 이 용한 작업 방법은 모델변경과 매핑변경에 따라 변경 되는 매핑 정의서의 1) 변경관리 및 2) 매핑정의 집 계에 어려움이 있으며, 3) 모수의 누락, 4) 표준화되 지 않은 전환로직 기술 등의 문제점이 발생할 가능성 이 있다(Korea Database Agency, 2017b;Korea Database Agency, 2015b).
아래 Tab. 2-1.은 성공적인 데이터 전환의 핵심요 소를 나열하였으며, 커스터마이징 가능한 데이터 전 환 전용 솔루션의 유무가 큰 비중을 차지하고 있다.
2.5 개선 데이터 전환 방안
기존 Excel Document를 이용한 전통적인 방법과 표준화되지 않은 문서기반의 전환방식에서 아래와 같 이 Repository, Process, 데이터 전환 전용 솔루션을 기반으로 한 개선 방안을 도출하였다.
2.5.1 Repository 기반의 매핑설계, Source DB/Target DB 메타 관리
Repository를 통해 메타시스템과 연계하여 매핑설 계/변환Rule/코드매핑과 같은 전환을 위한 주요 데이 터를 관리하여, 기존 Excel Document 관리 방식에 서 발생할 수 있는 정보배포, 문서간 불일치, 다양한 관점에서의 리포트 추출 등 여러 가지 문제점을 개선 할 수 있다(Korea Database Agency, 2017b; Korea
Database Agency, 2015b).
2.5.2 데이터 전환 프로세스 기반 전환
경험에 의한 업무 전개가 아닌 프로젝트 중 축적된 지식을 토대로 분석, 설계, 구현, 검증, 이행 등 각 단 계별 필수 수행 Task와 필수 산출물 위주의 데이터 전환 프로세스를 수립 및 프로젝트 관계자와 커뮤니
케이션 용도로 사용하고 전환 담당자들이 누락 없이 전체공정을 수행하며 관리/감독하기 위한 주요 가이 드로 사용된다.
2.5.3 데이터 전환 솔루션 기반 전환
Repository 구축과 체계적 전환 Process를 구축 하더라도 실제 수행은 사람이 수행하므로 방법론대로 진행하지 않거나, 누락 혹은 잘못 사용될 수 있다. 이 런 문제를 보완키 위해 Repository와 정형화된 데이 터 전환 Process 뿐만 아니라 더 나아가 프로젝트 환경별 커스터마이징 가능한 데이터 전환 전문 솔루 션이 필요하며, 이를 통해 생산성과 효율성을 증대하 고 오류를 최소화하여 데이터 전환 품질의 결과를 향 상시킬 수 있다(Korea Database Agency, 2015b).
3. 데이터 전환 자동화 도구 설계 및 구현
3.1 데이터 전환 레파지토리
3.1.1 데이터 전환 아키텍처 구성
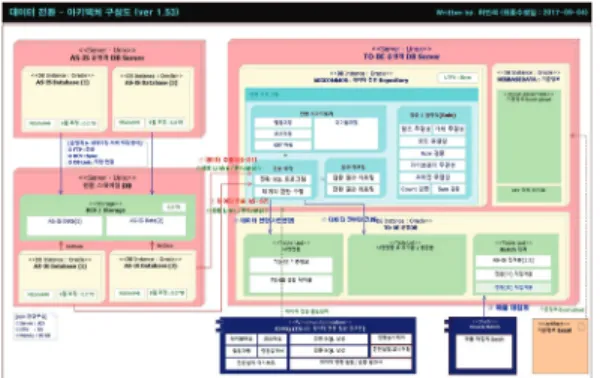
성공적인 데이터 전환 프로젝트를 위한 방안 중 Repository 기반의 커스터마이징 가능한 데이터전환 솔루션이 필요하며, 따라서 아래의 데이터 전환 Repository 및 인프라 데이터 전환 아키텍처 구성을 도식화 하였으며, 몇 차례 프로젝트 실제 수행시 아 래의 아키텍처를 이용하여 최적의 데이터 전환을 수 행하였다(Kimball Caserta, 2004; Bill Inmon et al, 2010).
데이터 전환 아키텍처는 크게 AS-IS 운영계, AS-IS 운영 데이터 적재를 위한 AS-IS 스테이징 DB 서버, TO-BE 운영계 및 전환 구현 및 테스트를 위한 전환계가 구성되며 TO-BE운영계 와 전환계에 전환 Repository와 Data Dictionary Repository가 위치하게 된다.
핵심 요소 핵심 성공요소 상세 설명 견고한 모델링
시간에 쫓겨 대충 마무리한 모델은 어플리케 이션뿐만 아니라 데이터 전환에 심각한 문제 를 유발한다.
컨설턴트 전환
전환 컨설턴트는 확고한 논리와 검증된 사례 를 통해 모델러, 업무개발자, 시스템 관리자 등의 이해와 동의를 얻어내야 한다.
커스터마이징 가능한 전환
솔루션
프로젝트 환경에 맞게 전환 솔루션의 기능을 수정하거나 추가할 필요가 있다. 모델링 도 구의 경우 API를 제공해 모델링 자동화 기능 을 지원하는 것처럼 전환 솔루션 역시 커스터 마이징이 가능해야 한다.
개발자와 좋은 팀리더
데이터 전환은 서버의 한정된 자원을 집중적 으로 사용하여 개발자간에 자원 사용에 대한 경합이 발생하고 상호 갈등의 원인이 된다.
팀 리더는 팀원들의 갈등을 미연에 방지하여 야 한다.
Repository 기반의 매핑
설계
매핑 설계서를 Reposiotry에 등록할 수 있도 록 정규화하고, 메타시스템에서 등록 관리하 면 편리하게 관리할 수 있다. 소스 모델과 소스 코드를 Repository에 등록하면 매핑설 계서 작성을 위한 기본 정보와 연계해 관리할 수 있다.
매핑정의서와 프로그램간의 전환
무결성
매핑 정의서와 전환 프로그램 간의 무결성을 유지하기 위한 방법은 매핑 정의서 수정시 전환 프로그램을 자동 재생성 하는 것이다.
일반 상용 전환 도구는 단순한 매핑일 경우 매핑결과를 통해 SQL을 자동 생성해 준다.
매핑 정의서가 전환로직을 완벽하게 정의하 여야 한다.
표준화된 전환로직 표현
전환 프로그램 생성시 표준 SQL 표기법이 아닌 경우 잘못된 구현으로 전환 프로그램에 오류가 발생하게 된다. 그러므로 전환 로직 을 정확하게 정의할 수 있는 매핑정의서 작성 법이 있고 이를 활용하여 SQL을 자동 생성해 주는 솔루션이 있다면 매핑정의서와 전환프 로그램간의 무결성을 보장할 수 있다.
Tab. 2-1 Key factors for successful data conversion[6][9].
1) AS-IS 운영계
현재 운영되고 있는 AS-IS 운영 DB Server 이며, 일반적으로 TO-BE Target DB에서 바로 접속하기 보다 전환 스테이징 DB에 데이터 적재 후에 TO-BE D에서 접근하게 된다.
2) 전환 스테이징 DB Server
전환 프로그램 구현 및 전환리허설시 AS-IS 운영 DB에 연결하여 수행할시 현재 운영중인 AS-IS 서비 스에 문제가 발생하게 되므로 AS-IS의 DBMS 환경 과 DBMS 종류, DBMS 버전을 동일하게 하여 별도 스테이징 DB를 구축하고 이후 전환 프로그램 구현 및 전환리허설, Open 당일에도 스테이징 DB와 Remote DB 연결후 작업을 수행한다. 또한, AS-IS 데이터의 빠른 적재를 위해 Disk 복제, BCV 등과 같 은 별도의 솔루션을 사용하기도 한다(Kimball Caserta, 2004; Bill Inmon et al, 2010).
3) TO-BE 전환계/TO-BE 운영계 DB Server TO-BE 전환계와 TO-BE 운영계에 전환 Repository가 위치하게 되고 크게 전환시 Target 될 TO-BE DB 스키마와 전환 Repository로 구성되어 있다.
4) 데이터 전환 Repository 관리 정보
데이터 전환 Repository에서 관리되어야 할 정보 는 크게 테이블 매핑, 컬럼매핑, 코드매핑과 같은 매 핑설계정보, 전환 SQL을 Stroed Procedure로 컴파 일된 전환 프로그램, 전환 수행 결과, AS-IS/TO-BE 비교 검증결과, 데이터 전환을 위한 AS-IS/TO-BE DB 환경과 같은 환경설정 정보 그리고 AS-IS/
TO-BE DB 구조와 연계하기 위한 Data Dictionary 정보로 구분되어 있다(Korea Database Agency, 2017b).
3.1.2 데이터 전환 Repository ERD
다음은 데이터 전환 Repository에서 관리할 테이 블에 대한 ERD이며, 크게 AS-IS Data Dictionary, TO-BE Data Dictionary, 테이블매핑설계, 컬럼매핑 설계, 데이터 전환 환경설정, 데이터 전환 검증 엔터 티로 구성되어 있다.
Fig. 3-2 Repository ERD of data conversion
3.2 데이터 전환 자동화 도구의 설계
데이터 전환 프로젝트시 최소 5회 이상의 전환 통 합테스트 및 전환 리허설 작업을 진행하게 되는데, 이 작업을 수작업으로 진행한다면, 엄청난 시간과 비 용 그리고 Human Error와 같은 많은 오류가 발생할 위험이 있다(Park, 2014).
Fig. 3-1 Architecture configuration by repository
현행 시스템인 프로그램과 데이터베이스 정보를 분석하여 프로그램 언어나 데이터베이스 종류와 버전 에 따라 차이 부분을 Mapping Repository에 저장된 자료를 토대로 전환 프로그램이 생성되어 데이터 전 환하게 된다(Park, 2014).
아래 Fig. 3-3에서는 자동화 도구를 활용할 때 데 이터 전환 프로세스를 도식화하였다.
Fig. 3-3 Data conversion automation process[13].
3.3 자동화 도구의 구현
3.3.1 매핑 데이터 관리
데이터 전환 Repository의 매핑설계 내용을 조회 수정할 수 있으며, 매핑설계를 위한 별도의 Excel Document는 불필요하여 관리문서의 축소로 인하여 관리 Effort 또한 많이 경감 되었다.
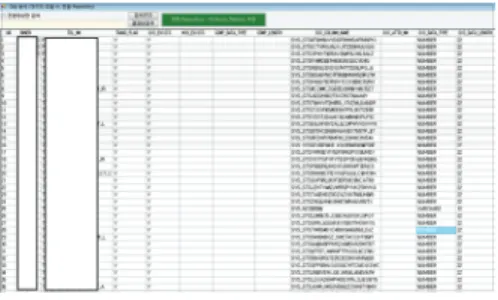
Fig. 3-4 Coulmn Mapping Design
Fig. 3-4는 AS-IS 와 TO-BE 테이블간의 매핑설 계를 하는 화면으로 테이블간 매핑을 설정하고, JOIN 테이블이 필요한 경우 간 JOIN Method를 설정하며, Filter 조건인 WHERE 구문, Group by 구문, Order by 절을 입력할 수 있으며, N:1 전환을 고려한 UNION ALL과 전환성능을 위하여 HINT구문을 입력 할 수 있도록 하였다.
3.3.2 표준화 SQL 형식의 매핑 Rule 관리 전환설계자마다 표준화되지 않은 매핑Rule 관리로 인하여 실제 구현시 매핑규칙을 이용하여 SQL로 변 경하는 추가적인 작업이 필요하지만, 매핑설계시부터 Fig. 3-5와 같이 SQL로 입력관리시 전환프로그램 자 동생성시 바로 사용될 수 있다.
Fig. 3-5 Mapping Rules by SQL
3.3.3 설계/구현 형상관리, 자동 프로그램 구현 데이터전환 Repository에 저장된 테이블매핑/컬럼 매핑/코드매핑 설계 데이터와 Meta Repository에 저 장된 Data Dictionary를 이용하여 전환프로그램을 자동생성한다. 이를 통해 전환프로그램이 표준화되
Fig. 3-6 Automatic generation of data conversion SQL program
고, 매핑설계와 전환프로그램간의 불일치를 방지하고 전환프로그램 구현시간을 줄였다.
3.3.4 전환 자동 집계
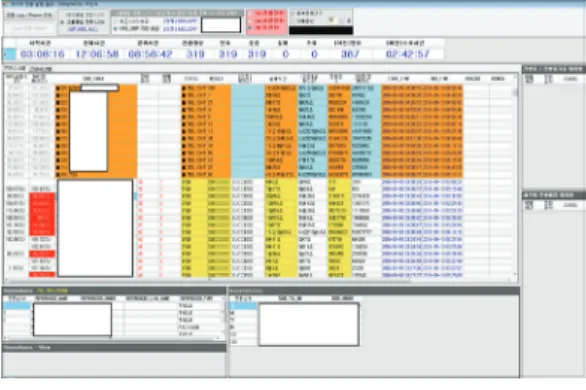
데이터전환 Repository의 매핑결과와 Data Dictionary를 비교하여 컬럼 매핑/설계 진척율을 대 시보드 형태로 보여주어 프로젝트의 상태를 직관적으 로 확인할 수 있다.
Fig. 3-7 Data conversion progress dashboard
3.3.5 DB 구조 설계 변경시 매핑설계 반영 데이터 모델 변경 프로젝트 진행시 DB 구조는 빈 번히 변경된다. 이때, 변경된 DB구조로 인해 전환 매 핑설계와 불일치가 발생하며, 이로인해 전환 프로그 램에 오류가 발생하므로 DB 구조 Data Dictionary와 매핑설계를 비교하여 갭분석 조회 후 매핑설계를 변 경할 수 있게 해야 한다.
Fig. 3-8 Gap analysis between data dictionary and mapping design
3.3.6 TO-BE, AS-IS 기준 매핑설계 관리 데이터 전환 Repostiroy, Meta Dictionary를 이용 하여 데이터 추출시 기준이 되는 드라이빙 테이블과 JOIN이 되는 테이블의 순서 조정과 조건변경으로 TO-BE 기준 뿐만 AS-IS 기준 매핑설계 모두 추출 가능하다.
Fig. 3-9 Column mapping management of TO-BE / AS-IS
3.3.7 데이터 전환대상 모수 관리
TO-BE 기준, AS-IS 기준 데이터 전환 전체 모수 는 Data Dictionary를 기준으로 하며, 아래 화면과 같이 전환대상 여부/전환 방식/사전전환 대상 여부와 변동분 체크 일자 기간/선오픈 대상 여부를 일괄 관 리하여 모수 누락이 없도록 한다.
Fig. 3-10 Data Dictionary table list and conversion target / method setting
3.3.8 데이터 전환 수행 대시보드
프로젝트 오픈 당일에는 시스템이행을 위한 사전 N차 리허설을 통해 수립된 시스템 이행 시나리오에 의하여 단계별 수행한다.
Fig. 3-11 Dashboard for performing data conversion
데이터 전환의 경우 시스템 이행 시간 중 가장 중요하 고 오랜시간이 소요되므로, 소요시간 뿐만 아니라 잔여 시간까지 예측이 가능해야 한다. 잔여시간의 경우 전환 리허설 시간을 통해 예측하며, 현재 진행시간과 비교 후 아래 화면과 같이 보여주며, 전환 완료된 테이블 및 전환 예정 테이블 까지 조회 가능하다.
4. 자동화 도구 검증
4.1 자동화 도구의 프로젝트 적용
레파지토리 및 프로세스 기반의 자동화 도구를 적 용한 사례이다. 아래 프로젝트들은 소규모가 아닌 대 규모로서 본 연구과제의 자동화 솔루션을 중대형 프 로젝트에서 사용할 수 있으며, 그 결과를 검증받았다.
A사는 AS-IS DB 데이터 모델 개선에 따라서 데 이터 전환 프로젝트에 적용하였다. 데이터의 용량은 9TB의 대용량의 데이터들로 자동화 도구의 전환분석 /설계, 구현, 검증, 전환 모니터링 등을 통하여 제안
한 자동화 도구를 활용하였다. 적용 결과 Meta Repository /전환 Repository 연계 및 자동화 솔루 션을 이용하여 전환에 소요되는 시간이 대폭 감소하 였으며, Human Error 방지할 수 있었다. Excel Document 필요 없었으며, 전환 프로그램 자동 및 검 증 프로그램 자동 구현하였고, 각종 프로젝트 리포트 를 자동으로 추출하였다. 오픈 당일에는 데이터 전환 대시보드로 이전 리허설 대비 수행시간을 비교할 수 있었으며, 효율적인 데이터 전환을 수행하였다.
B 기관은 차세대 물류통합 프로젝트에 적용하였 다. AS-IS DB 데이터 모델 개선과 함께 N개 시스템 의 데이터를 통합하는 데이터 전환에 적용하였다.
Oracle 과 Altibase로 구성되어 있는 5개의 시스템에 연결되어 있는 6TB 용량의 데이터를 개선된 데이터 모델에 전환하였다. 자동화 도구의 전환분석/설계, 구 현, 전환 리포팅 등을 활용하였으며, 전환 자동화 술 루션을 통한 5개 시스템에 대한 AS-IS 기준 매핑을 통하여 데이터의 정합성이 증가되었으며, Excel Document 불필요하였고, 5개의 AS-IS DB 전환시 모수 관리를 효율적으로 할 수 있었으며, 전환 프로 그램 자동 구현을 이용하여 전환에 소요되는 노력이 대폭 감소하였다.
C사는 차세대 유통 프로젝트에 적용하였다. 솔루 션 to 솔루션 업그레이드로 이기종 DBMS 통합과 함 께 데이터 모델 변경으로 인한 데이터 전환에 동시에 적용하였다. Oracle 9i/MSSQL Server 2005 데이터 베이스의 1TB의 데이터를 EPAS (PostgreSQL 오라 클 호환 상용버전) 데이터베이스로 전환하는 프로젝 트였다. 자동화 도구의 전환분석/설계, 전환구현, 전 체 모수관리 등을 활용하였다. Meta Repository/전 환 Repository 및 전환 자동화 솔루션을 이용하여 전 환 노력이 대폭 감소하였고, 작업 누락 방지 및 AS-IS 기준 전환 모수 관리와 TO-BE 기준 전환 모수 관리가 용이하였으며, AS-IS vs. TO-BE 분석 및 매핑설계 자동화를 통하여 효율적으로 데이터 전 환할 수 있었다.
4.2 자동화 도구 적용 효과
전통적인 데이터 전환 방식과 레파지토리를 이용 한 자동화된 데이터 전환 방식의 적용효과를 분석하 였다(Korea Database Agency, 2015b; Korea Database Agency, 2017b; Shin, 2014).
매핑 데이터 관리에서는 전환 Repository를 통한 중앙집중 관리가 가능하고, Meta Repository와의 연 계를 통한 매핑 정합성이 증가하였다. 형상관리 측면 에서는 Repository 데이터를 이용하여 전환 프로그 램이 자동생성 되어 데이터의 불일치 를 줄였으며, 전환 프로그램도 전환 Repository, Meta Repository 에 저장된 데이터를 이용하여 자동구현이 가능하여 전환 노력이 대폭 감소하였다. 집계 전환에서도 전환 Repository 데이터를 집계쿼리 실행으로 단시간내 정확하게 추출할 수 있으며, 전환 Repository에서 매 핑 변경시 Trigger를 이용한 자동으로 매핑설계 이력 관리가 가능하게 되었다. 전환 Repository 데이터를 참조하여 검증 프로그램 자동생성이 가능하여 업무규 칙(Biz Rule) 검증도 Rule Repository에 저장하여 관 리 가능하게 되었다.
5. 결론
본 논문에서는 차세대 시스템 통합 프로젝트 중 중 요한 부분인 데이터 전환에서 기존 데이터 전환 방식 의 문제점을 분석하여, 생산성과 효율성은 높이는 Repository와 프로세스 기반의 데이터 전환 전용 데 이터 전화 자동화 도구를 통한 자동화 방안을 제안하 고 실제 적용사례를 통해 그 효율성을 검증하였다.
기존 데이터 전환 방식의 문제점은 Excel Document 매핑설계와 별도의 SQL 구현으로 인한 생산성, 효율 성의 저하 및 높은 Human Error 발생가능성 및 다 량의 공수를 투입하여야 한다. 또한, 데이터 전환 자 동화 도구를 대체할 수 있는 ETL 솔루션을 사용하는
방안이 있으나, 차세대 프로젝트 데이터 전환 용도가 아니라 DataMart, Datawarehouse 구축용으로 인하여 사용법에 대한 숙지가 필요하고, 솔루션 사용 프로세 스가 데이터 전환에 최적화 되지 않음으로 인한 추가 시간 투입 그리고 고가인 단점이 있다.
이러한 문제를 해결하기 위해서는 본 논문에서 제 안한 데이터 전환 자동화 도구는 Excel Document가 아닌 전환 Repository에서 매핑설계 데이터를 관리 및 Meta 시스템과 연계하여, 분석/매핑설계/전환프로 그램 자동구현/검증/수행/전환모니터링과 같은 필수 적으로 수행해야 할 데이터 전환 프로세스를 수립한 후, Repository와 전환 프로세스를 기반으로 프로젝 트마다 커스터마이징 가능하도록 구현하였으며, 다수 의 대규모 프로젝트에 도입하여 성공적인 프로젝트를 완료하여 효율성과 생산성을 검증하였다.
향후에는 대용량 데이터 전환에 대한 연구와 더 나 아가 빅데이터 솔루션에 대한 전환 방안에 대한 자동 화 도구로의 확장이 필요할 것이다.
References
[1] Bill Inmon, Claudia Imhoff, Ryan Sousa (2010), Corporate Information Factory, Ji&Sun (빌인먼/클라우디아임호프/리안소사 (2010), 한상훈/신전수/이원희/이지면 (번역) , 뺷기업정보공장뺸, 서울 : 지앤선)
[2] Data Streams(2017), Data migration, data migration issues (데이터스트림즈, 뺷데이터 마 이그레이션, 데이터 마이그레이션 문제점뺸: 데이 터스트림즈) http://datastreams.co.kr/consulting -service/data-migration/
[3] Kimball Caserta, 뺷The Data Warehouse ETL Toolkit뺸, USA : WILEY, 2004 https://www.
talend.com
[4] Ko, J.H., Kim, D.S. and Kim, S.B.(2011),“Data
Quality Diagnosis Method in Information System Audit,”Proceeding of Fall Conference of Korea IT Service Society, pp.417-420 (고 재환, 김동수, 김상복(2011), ”정보시스템 감리시 데이터 품질진단 방안“, 2011 한국IT서비스학회 추계학술대회 pp. 417-420)
[5] Korea Database Agency(2012), Data Quality Guidelines (Revision) (한국데이터베이스진흥 원(2012), 뺷데이터 품질 가이드라인뺸(개정판), 서 울 : 한국데이터베이스진흥원)
[6] Korea Database Agency(2015), Data Industry White Paper (한국데이터베이스진흥원(2015), 뺷데이터산업 백서뺸, 서울 : 한국데이터베이스진 흥원)
[7] Korea Database Agency(2015), Data Industry Status Survey Result Report (한국데이터베이 스진흥원(2015), 뺷데이터산업 현황 조사 결과보 고서뺸, 서울 : 한국데이터베이스진흥원) [8] Korea Database Agency(2016), Data Industry
White Paper (한국데이터베이스진흥원(2016), 뺷데이터산업 백서뺸, 서울 : 한국데이터베이스진 흥원)
[9] Korea Database Agency(2017), Data Industry White Paper (한국데이터베이스진흥원(2017), 뺷데이터산업 백서뺸, 서울 : 한국데이터베이스진 흥원)
[10] Korea Database Agency(2017), Data Analysis Guidelines (Revision) (한국데이터 베이스진흥원(2017), 뺷데이터 분석 가이드라인뺸
(개정판), 서울 : 한국데이터베이스진흥원) [11] Kwon, S.Y.(2007), Data migration method
and required time, Korea Database Agency (권순용(2007), 뺷데이터 마이그레이션 방법과 소요시간뺸: 한국데이터진흥원) http://www.
dbguide.net
[12] Nho, J.K.(2014), The role of DA for a successful build the next generation of systems, Encore (노준기(2014), 뺷성공적인 차 세대 시스템 구축을 위한 DA의 역할뺸: 엔코아) http://www.dator.co.kr/encore/textyle/15 42745
[13] Park, S.H.(2014), Successful Migration Strategy with Automation Tools, Meta Mining (박성희(2014), 뺷자동화 도구를 활용한 성공적인 마이그레이션 전략뺸: 서울 : 메타마이 닝)
[14] Ralph Kimball and Margy Ross(2015), Data Warehouse Toolkit(Revision), BJPUBLIC (랄프킴벌/마기로스, LGCNS 빅데이터사업부, 뺷데이터 웨어하우스 툴킷뺸(개정판), 서울 : BJPUBLIC)
[15] Shin, S.H.(2014), Design and consistency verification of science and technology information content data migration model, Korea Institute of Science and Technology Information (신성호외7명(2014), 뺷과학기술 정보콘텐츠 데이터마이그레이션 모델 설계 및 정합성 검증뺸, 서울 : 한국과학기술정보연구원)
Min Seok, Heo([email protected])
Min Seok Heo received the MS degree in the Graduate School of Information Communication from Konkuk University in 2018. His major is information system audit. He has been a senior consultant in the Department of Consulting at CSLee Consulting since 2013. His current research interests include information system audit, cyber security, security management, and security consulting.
Dong Soo, Kim([email protected])
Dong Soo Kim received the bachelor’s degree in the Department of Computer Science from Kwanwoon University in 1981. He received the Ph.D.
degree in the Management Information System from Kookmin University in 2005. He has three Certificate as a Professional Engineer(P.E.) in Information Systems Management, Computer Application System, and Computer Communications from Korean Ministry of Science and Technology. He is a chief consultant in the department of Information System Auidt at KISAC company and an invited professor in the Graduate School of Information Communication at Konkuk University. His current research interests include u-city audit, e-business, and information system audit.
Hee Wan, Kim([email protected])
Hee Wan Kim has been a professor in the Department of Computer Engineering at Shamyook since 1996. Hereceived the Ph.D. degree in the Department of Computer Engineering from Sungkyunkwan University in 2002.
He has two Certificate as a Professional Engineer(P.E.) in Information Systems
Management and Chief Information System from Korean Ministry of Science
and Technology. His current research interests include database, information
system audit, database security, and software engineering.
*
Data Conversion Automation Tool based on Repository and Processes
Min Seok, Heo*, Dong Soo, Kim**, Hee Wan, Kim***
ABSTRACT
ㄴ
This study was performed to derive a modern service management model reflecting the philosophy of the new business administration. Service management as the modern business administration should be faithful to the spirit of modernity. In addition, service management must be faithful to the essence of service in service economy era. And since modern management is to manage organizations those are the central organizations of human society, it must be managed according to the common principles of the world.
Management that satisfies these three management philosophy conditions is defined as modern service management. In this study, we analyzed that the existing service management framework does not meet these standards of modern management and derived an improved modern service management model. The modern service management model must be a management model that reflects the essence of intangible goods called service, it must be a management framework that reflects the modern spirit, and it must be a management model that reflects the common principles of the world required by the central organization of the modern economic society. Therefore, this study analyzed the modern spirit in addition to the service essence and the common principle of the world analyzed in the previous study, and presented a modern service management model with these three requirements. Also, examples of modern service management were presented. This study is a conceptual model, and analytical research is needed to demonstrate that this management model can consistently produce excellent management performance by strengthening empirical studies in the future.
Keywords: data consistency, data conversion, repository, process, automation tool
![Tab. 2-1 Key factors for successful data conversion[6][9].](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5263101.632092/5.834.91.408.180.823/tab-key-factors-for-successful-data-conversion.webp)
![Fig. 3-3 Data conversion automation process[13].](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5263101.632092/7.834.92.398.346.520/fig-data-conversion-automation-process.webp)