논문 2014-51-4-9
2x2 서브블록에서 최소/최대값을 이용한 가역 정보은닉기법 연구
( Reversible Data Hiding Method Based on Min/Max in 2x2 Sub-blocks )
김 우 진*, 김 평 한*, 이 준 호**, 정 기 현***, 유 기 영**
( Woo-Jin Kim, Pyung-Han Kim, Joon-Ho Lee, Ki-Hyun Jung, and Kee-Young Yoo
ⓒ)
요 약
본 논문에서는 하나의 서브블럭내에서 픽셀값정렬과 예측오차확장기법을 확장한 새로운 가역 정보은닉기법을 제안한다. 각 2x2 서브블록에서 최소값 그룹과 최대값 그룹으로 나누고, 최소값 그룹에서는 제일 작은 값에 비밀자료를 숨기고, 최대값 그룹 에서는 제일 큰 값에 비밀자료를 숨긴다. 제안한 알고리즘은 평균 13,900 비트의 삽입용량을 가지는데 이 결과는 31.39dB의 시 각적인 왜곡을 유지하면서 기존 알고리즘보다 4,553 비트 더 많이 숨길 수 있음을 실험을 통해서 보여주고 있다.
Abstract
A novel reversible data hiding method using pixel value ordering and prediction error expansion in the sub-block is resented in this paper. For each non-overlapping 2x2 sub-block, we divide into two groups. In the min group, the lowest value is changed to embed a secret bit and the highest value is changed in the max group. The experimental results show that the proposed method achieves a good visual quality and high capacity. The proposed method can embed 13,900 bits on average, it is higher 4,553 bits than the previous method and the visual quality is maintained 31.39dB on average.
Keywords: Information Hiding(정보은닉), Steganography(스테가노그래피), Watermarking(워터마킹), Reversible Data Hiding(가역정보은닉)
Ⅰ. 서 론
유/무선 상에서 정보은닉(Information Hiding, Data Hiding), 또는 디지털 워터마킹(Digital Watermarking) 은 완전한 디지털 정보와 개인이나 단체의 지적재산권
* 정회원, 경북대학교 컴퓨터공학부
(School of Computer Science and Engineering, Kyungpook National University)
** 정회원, 국방과학연구소
(Agency of Defense Development)
*** 정회원, 영진전문대학 컴퓨터정보계열 (School of Computer Information, Yeungjin College)
ⓒ Corresponding Author(E-mail: [email protected]) 접수일자: 2014년2월28일, 수정일자: 2014년3월6일 수정완료: 2014년4월3일
과 저작권의 보호를 위해 사용이 증가되고 있다[1~15]. 이러한 정보은닉기법 중에서 가역 정보은닉(Reversible Data Hiding)기법은 삽입된 비밀자료를 다시 추출 할 수 있을 뿐만 아니라, 원본자료 또한 온전하게 복원할 수 있다. 최근에는 비밀자료를 추출함과 동시에 원본자 료 또한 복원시킬 수 있다는 점에서 가역 정보은닉기법 들이 각광을 받고 있는 추세이다[2].
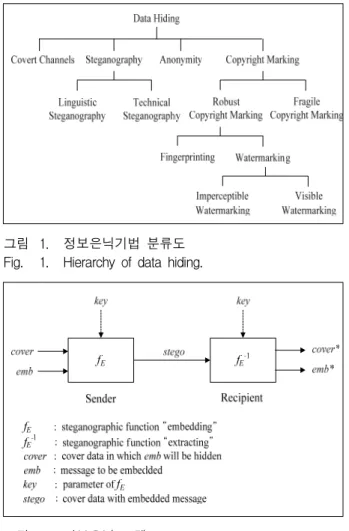
정보은닉(Data Hiding)기법은 분류 기준에 따라서 다 양하게 나눌 수 있으나, 그림 1에서 보는 바와 같이 크 게 비밀 통로를 통한 정보은닉기법, 스테가노그래피 기 술을 이용한 정보은닉기법, 익명성을 추구하는 정보은 닉기법, 저작권 정보를 숨기기 위한 정보은닉기법 등으 로 분류할 수 있다[3].
일반적으로 군사영상이나 의료영상 또는 보존되어야
그림 1. 정보은닉기법 분류도 Fig. 1. Hierarchy of data hiding.
그림 2. 정보은닉 모델 Fig. 2. Data hiding model.
할 예술 작품과 같이 영상의 왜곡에 민감한 영상들이 있는데, 이러한 영상들은 비밀자료를 삽입함으로써 원 본 영상이 왜곡되는 것을 허용하지 않는다. 결과적으로 가역 정보은닉기법은 삽입된 비밀자료의 추출 이후에도 비밀자료 삽입 이전의 원래 영상의 상태로 완벽하게 복 구할 수 있음을 의미한다[4].
가역 정보은닉기법은 그림 2에서 보는 바와 같이 비 밀자료를 숨겨서 보내는 송신자(Sender)와 숨겨진 결과 를 받아서 처리하는 수신자(Recipient) 입장에서 비밀자 료만 추출할 수 있느냐, 비밀자료와 원본 자료를 모두 복원할 수 있느냐에 따라서 가역 정보은닉기법과 정보 은닉기법으로 나눌 수도 있다[5].
최근에 제안되고 있는 많은 가역 정보은닉기법들이 HS(Histogram Shifting), DE(Difference Expansion), 그리고 예측오차확장(Prediction Error Expansion)에 기 반을 둔 알고리즘이 많이 소개되고 있다. Tian이 제안 한 가역 정보은닉기법은 DE에 기반을 두고 있으며[6],
Alattar이 제안한 기법은 인접한 픽셀 벡터들의 차이값 확장을 통하여 각각의 비트들을 삽입하고 있다[7]. Al-Qershi 등은 2D-DE 기법을 사용하여 미리 정의된 한계값을 사용하는 대신에 영상의 특징에 의존한 한계 값을 사용하였는데, 이는 비밀자료를 숨길 수 있는 용 량을 증가시킬 수 있도록 하였다[8]. Luo 등은 비밀자료 를 숨기기 위한 데이터를 숨기기 위한 차이값에 대한 HS와 다단계 시프팅을 위한 블록의 픽셀들간의 높은 연관성에 기반을 두고 있다[9]. Zhao 등도 많은 비밀자 료를 숨기기 위하여 다중 히스토그램 수정 방법을 사용 하고 있다[10]. Thodi와 Rodriguez는 예측오차확장을 사 용한 가역 정보은닉기법을 제안하였다[11]. Hu 등은 오 버플로우 로케이션 맵을 감소시킴으로써, 향상된 가역 정보은닉기법을 제안하였다[12].
최근에 Li 등이 제안한 가역 정보은닉기법은 픽셀값 정렬과 예측오차확장을 사용한다[14]. 각각의 서브블록에 대하여 두 번째로 큰 값과 작은 값에 대하여 최대값과 최소값을 예측하기 위하여 사용되었다. 이후 비밀자료 를 삽입하기 위하여 예측오차확장이 사용되었다.
본 논문에서는 2 x 2 크기의 서브블록에서 기존에 비 밀자료를 한 비트만 숨길 수 있는 제한을 개선하여 두 비트의 비밀자료를 숨길 수 있는 기법을 제안한다. 먼 저 네 개의 픽셀값을 오름차순으로 정렬하고 두 개의 그룹을 나눈다. 각각의 그룹에 비밀자료를 한 비트씩 숨길 수 있는 알고리즘을 제안함으로써 숨길 수 있는 용량을 늘리고자 한다.
본 논문은 아래와 같이 구성되어 있다. 제Ⅱ장에서는 제안하고자 하는 기법과 관련된 정보은닉기법을 살펴보 고, Ⅲ장에서 제안방법에 대해서 상세하게 설명한다. 제 안된 방법에 대한 실험결과를 Ⅳ장에서 다루고, 마지막 으로 Ⅴ장에서 결론을 맺는다.
Ⅱ. 관련 연구
본 장에서는 제안된 방법과 관련되는 기존 방법 중에 서 예측오차확장(PEE)기법과 픽셀값정렬(PVO)과 예측 오차확장기법 두 가지를 사용한 알고리즘에 대해서 살 펴본다.
1. 예측오차확장(PEE) 기법
예측오차확장기법은 원본 이미지의 각 서브블럭에
그림 3. 2 x 2 픽셀값 구성 블록 예제 Fig. 3. Example of 2 x 2 sub-block.
대하여 한 비트의 비밀자료를 숨기게 된다. 먼저 비밀 자료를 숨기기 위한 과정을 살펴보면 아래와 같다.
그림 3과 같이 픽셀값이 주어졌다고 가정하고
순서쌍을 이룬다고 하면, 값을 둘러싸고 있는 3개의 이웃한 픽셀값 , , 값을 이용하여 새로 운 값을 계산한다.
max
min i f ≤ min
i f ≥ max
(1)
다음으로 예측값 ′는 다음식과 같이 계산된다.
′ × ⌊
⌋ (2)
예측값 ′와 픽셀값 를 이용하여 예측오차값
′와 같으며, 숨길 비트값을 라고 두면, 확장 예측오차값 ′ × 와 같으며, 새로운 픽셀값
′ ′ ′로 주어지게 된다. 결과적으로 새로운 픽셀 값은 ′ ′ ′ ′ 순서쌍을 이루게 된다.
다음으로 위의 과정을 통하여 만들어진 결과로부터 비밀자료와 원본픽셀을 복원하는 방법을 살펴보면, 먼 저 비밀자료는 ′ 에 의해서 간단하게 추출 가능하다. 다음으로 원본픽셀을 복원하는 과정을 살펴 보면 아래와 같다. 먼저 변수 는 아래식과 같이 계산 된다.
max′′
min′′ i f ′ ≤ min′′
i f ′ ≥ max′′
′ ′ ′ (3)
다음으로 예측값 ′는 (2)식과 같은 방법으로 아래 식 (4)와 같이 구해진다.′ × ⌊
⌋ (4)
예측오차값 ′ ′ ′로 구해지며, 원본픽셀은 수 식 (5)에 의해서 복원된다.
′ ⌊
′ ⌋ (5)
2. 픽셀값정렬(PVO)과 예측오차확장기법
픽셀값정렬(PVO)과 예측오차확장(PEE)에 기반한 가 역 정보은닉기법은 먼저 하나의 서브블럭에 대해서 오 름차순 정렬을 수행한다. 주어진 그림 3에서 오름차순 정렬로 순서쌍이 만들어졌다고 가정하 면, 예측오차 이 계산되어진다. 다음으로
′는 아래 수식 (6)과 같이 구해진다.
′
i f i f
i f ≻
(6)
최종적으로 비밀값을 숨기기 위하여 최대값 가 선 택되는데, 새로 생성된 값을 아래 수식 (7)과 같이 구해 지고, 원래 위치대로 저장되게 된다.
′
i f i f
i f ≻
(7)
다음으로 수신자측에서 수신받은 픽셀값에 대해서 오름차순 정렬로 ′ ′′′ 순서쌍으로 만들어 졌다고 가정하면, 예측오차 ′ ′이 계산되어 진다. 만약 이면 해당 서브블럭은 비밀비트를 숨 기고 있지 않고, 원본픽셀값도 동일하다. 만약
≤ ≤ 이면 숨겨진 비밀비트는 로 구해 지고, 원본픽셀값 ′ 에 의해 구해진다. 마지 막으로 ≻ 이면 비밀비트는 숨겨지지 않았고, 원본 픽셀값 ′ 에 의해서 계산된다. 나머지 픽셀 값은 그대로 유지된다.
Ⅲ. 제안 방법
본 논문에서는 예측오차확장(PEE)기법과 픽셀값정렬 (PVO)기법을 활용하고, 기존방법보다 더 많은 비밀자 료를 숨길 수 있는 알고리즘을 제안한다. 본 장에서는 먼저 송신자측에서 원본자료에 비밀자료를 숨기는 자료 은닉 알고리즘에 대해서 자세하게 다루고, 다음으로 수 신자측에서 원본자료를 복원함과 동시에 비밀자료를 추
출할 수 있는 알고리즘을 살펴보고자 한다.
1. 자료은닉 알고리즘
먼저 하나의 서브블럭에 대해서 오름차순 정렬을 수 행한다. 임의로 주어진 네 개의 값에 대하여
로 정렬되었다고 하면, 두 개의 서브 그 룹 , 으로 나눈다. 다음으로 첫 번째 서브그룹 에 대하여 m in 값을 구한 다. 구해진 값은 아래 수식 (8)에 의해서 ′m in값을 구 하게 된다.
′
min
min
min
i f
min i f
min
min i f
min≺
(8)
최종적으로 첫 번째 서브그룹에서 새로운 픽셀값은 최소값을 변경하게 되며, ′ ′m in에 의해 새 로운 픽셀값이 구해진다.
다음으로 두 번째 서브그룹 에 대하여
m ax 값을 구한다. 구해진 값은 아래 수식 (9)에 의해서 ′m ax값을 구하게 된다.
′
max
max
max
i f
max i f
max
max i f
max≻
(9)
최종적으로 두 번째 서브그룹에서 새로운 픽셀값은 최대값을 변경하게 되며, ′ ′m ax에 의해 새 로운 픽셀값이 구해진다. 이러한 과정으로 구해진 픽셀 값은 오름차순 정렬 이전에 위치한 곳으로 배치되게 된 다. 최소값 그룹에서 발생할 수 있는 언더플로우 (Underflow) 문제와 최대값 그룹에서 발생할 수 있는 오버플로우(Overflow) 문제는 원본이미지에 대한 전처 리를 통해서 사전에 비트값을 조정하여 방지한다.
2. 자료 추출 및 원본 복원 알고리즘
수신자측에 수신된 픽셀값에 대해서 먼저 오름차순 정렬을 수행한다. 정렬된 픽셀값이 ′ ′ 라 는 순서로 주어지면, 두 개의 서브그룹 ′ ,
′ 으로 나누어진다. 먼저 첫 번째 서브그룹
′ 에 대하여 ′m in ′ 값을 구하고, 이 결과에 따라서 숨긴 비트값과 원본픽셀을 구하게 된다.
만약 ′m in 이면 숨긴 비트값이 존재하지 않고 원 본픽셀도 변경되지 않았음을 의미하게 되므로 변함이 없게 된다. 만약 ′m in∈ 이면 숨긴 비트값 은 ′ 에 의해서 구해지고, 원본픽셀은
′ 값이 된다. 마지막으로 ′m in≺ 조건 을 만족하면 한 비트 시프트가 수행되었으므로 비밀비 트는 숨기지 않았으며, 원본픽셀은 ′ 로 구 해지게 된다.
다음으로 두 번째 서브그룹 ′ 에 대하여
′m ax ′ 값을 구하고, 이 결과에 따라서 첫 번 째 서브그룹과 유사한 방법으로 숨긴 비트값과 원본픽 셀을 구하게 된다. 만약 ′m ax 이면 숨긴 비트값이 존재하지 않고 원본픽셀도 변경되지 않았다. 만약
′m ax∈ 이면 숨긴 비트값은 ′m ax 에 의해서 구해지고, 원본픽셀은 ′ 값이 된다.
마지막으로 ′m ax≻ 이면 시프트 연산이 수행되었으 므로 원본픽셀은 ′ 로 구해지고 비밀비트는 숨어있지 않게 된다. 최종적으로 정렬되기 전 단계로 픽셀값이 저장되면 원본자료를 그대로 복원가능하게 되 는 것이다.
Ⅳ. 실험 결과
본 논문의 실험에서는 그림 4에서 보는 바와 같이 512 x 512 이미지를 원본 이미지로 사용하고, 비밀자료
(a) Airplane (b) Boat (c) House
(d) Island (e) Lena (f) Peppers 그림 4. 실험에 사용된 원본 이미지
Fig. 4. Cover images.
는 랜덤함수를 사용하여 생성하였다.
일반적인 성능평가로는 크게 비밀자료를 숨길 수 있 는 삽입용량(Capacity)과 원본이미지와 비밀자료를 숨 긴 후의 결과 이미지인 스테고 이미지와의 왜곡 정도를 측정하게 된다. 사람의 육안으로 왜곡을 확인할 수 있 다면 공격자에게 공유된 이미지 내에 비밀자료가 숨겨 져 있다는 것이 노출될 수 있기 때문에 왜곡 측정은 매 우 중요하다. 이러한 왜곡 측정은 수식 (10)과 같이
값을 많이 사용한다. 일반적으로 30 이상을 유지하면 사람의 육안으로 구별하기 힘들게 된다. 여기 서 는 평균제곱오차를 나타낸다.
×log
(10)
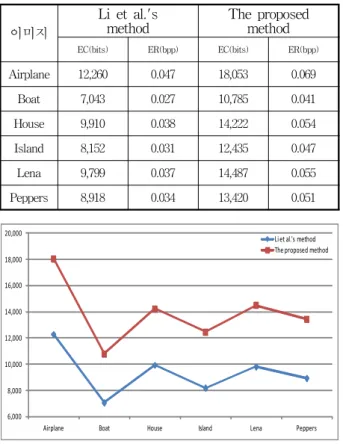
표 1은 제안한 알고리즘에 대해서 숨길 수 있는 삽입 용량을 비교한 것으로 평균 13,900비트를 숨길 수 있었 고 이는 기존방법보다 EC = 4,553비트와 ER = 0.017만 큼 더 숨길 수 있었다.
이미지
Li et al.'s
method The proposed method
EC(bits) ER(bpp) EC(bits) ER(bpp)
Airplane 12,260 0.047 18,053 0.069
Boat 7,043 0.027 10,785 0.041
House 9,910 0.038 14,222 0.054
Island 8,152 0.031 12,435 0.047
Lena 9,799 0.037 14,487 0.055
Peppers 8,918 0.034 13,420 0.051
표 1. 숨길 수 있는 삽입용량 비교 Table 1. Comparison of embedding capacity.
6,000 8,000 10,000 12,000 14,000 16,000 18,000 20,000
Airplane Boat House Island Lena Peppers
Li et al.'s method The proposed method
그림 5. 이미지별 삽입용량 비교 그래프
Fig. 5. Comparison graph of capacity for test images.
(a) 31.15dB (b) 30.39dB (c) 30.67dB
(d) 30.28dB (e) 33.32dB (f) 32.54dB
그림 6. 정보은닉 결과에 대한 스테고 이미지 Fig. 6. Stego-images after embedding secret data.
30.00 32.00 34.00 36.00 38.00 40.00 42.00 44.00 46.00 48.00
1,000 3,000 5,000 7,000 9,000 11,000 13,000 15,000
그림 7. 삽입용량별 PSNR 비교 (Lena)
Fig. 7. PSNR per embedding capacity on Lena image.
그림 5는 각 이미지별로 숨길 수 있는 비밀자료량, 즉 삽입용량에 대해서 비교한 그래프로 삽입용량이 평 균 33% 향상되었음을 보여주고 있다.
그림 6은 비밀자료를 숨긴 결과로 생성된 스테고 이 미지를 보여주고 있는 것으로 평균 값이 31.39
를 유지하고 있으므로 사람의 육안으로 왜곡을 식별 하기 힘든 결과를 얻을 수 있었다.
그림 7은 Lena 이미지에 대해서 삽입용량별 이미지 왜곡을 보여주는 값을 비교한 그래프로 이미지 왜곡 정도를 보여주기 위한 것으로 삽입용량이 1,600비 트일 때, 값은 46.85를 나타내었으며, 14,400 비트를 숨길 경우 값은 33.35를 유지하였다.
결과적으로 살펴보면, 제안한 알고리즘이 감소 를 최소로 유지하면서 더 많은 삽입용량을 가지고 있음 을 알 수 있다.
Ⅴ. 결 론
본 논문에서는 예측오차확장(PEE)기법과 픽셀값정렬 (PVO)기법을 사용하고, 2 x 2 서브블록에 대하여 두 개의 서브그룹을 생성함으로써 숨길 수 있는 비밀자료 의 삽입용량을 늘리는 기법을 제안하였다. 먼저 네 개 의 픽셀값을 오름차순으로 정렬하고 두 개의 서브그룹 은 최소값 그룹과 최대값 그룹을 이루며, 최대 한 비트 씩 숨길 수 있었다. 또한 네 개의 픽셀값에 대해서 비밀 자료 삽입 후에도 정렬 순서가 변경되지 않으므로 수신 자측에서는 비밀자료와 원본자료를 모두 추출할 수 있 는 가역 정보은닉기법을 만족하고 있다.
본 논문의 실험결과를 따르면, 숨길 수 있는 평균 삽 입용량은 13,900비트로 평균 4,553비트를 더 숨길 수 있 었다. 이는 평균 33%를 더 숨길 수 있는 양으로, 이때 평균 값은 31.39 를 유지하고 있었다.
REFERENCES
[1] J.Y. Hsiao, K.F. Chan, and J. M. Chang, Block-based reversible data embedding, Signal Processing 89, pp. 556-569, 2009.
[2] D.C. Lou, M.C. Hu, and J.L. Liu, Multiple layer data hiding scheme for medical images, Computer Standard & Interfaces 31, pp. 329-335, 2009.
[3] B. Pfizmann. “Information Hiding Terminology.”
Proc. First International Information Hiding Workshop. LNCS 1174. pp. 347-350. 1996.
[4] W.L. Tai, C.M. Yeh, and C.C. Chang, Reversible data hiding based on histogram modification of pixel differences, IEEE Transactions on Circuits and Systems for Video Technology, Vol. 19, No.
6, pp. 906-910, 2009.
[5] J. Zollner. H. Federrath. H. Klimant. A.
Pfitzmann. R Piotraschke. A. Westfeld. G.
Wicke. G. Wolf. “Modeling the Security of Steganographic Systems.” 2nd Workshop on Information Hiding. pp. 345-355. 1988
[6] J. Tian, Reversible data embedding using a difference expansion, IEEE Transactions on Circuits and Systems for Video Technology 13(8), pp. 890-896, 2003.
[7] A.M. Alattar, Reversible watermark using the difference expansion of a generalized integer transform, IEEE Transactions on Image
Processing 13(8) (2004) 1147-1156
[8] O.M. Al-Qershi and B.E. Khoo, Two-dimensional difference expansion (2D-DE) scheme with a characteristics-based threshold, Signal Processing 93, pp. 154-162, 2013.
[9] Z. Ni, Y.Q. Shi, N. Ansari, and W. Su, Reversible data hiding, Proc. of International Symposium on Circuits and Systems, Vol. 2, pp.
912-915, 2003.
[9] H. Luo, F.X. Yu, H. Chen, Z.L. Huang, H. Li, and P.H. Wang, Reversible data hiding based on block median preservation, Information Sciences 181, pp. 308-328, 2011.
[10] Z. Zhao, H. Luo, Z.M. Lu, and J.S. Pan, Reversible data hiding based on multilevel histogram modification and sequential recovery, AEU - International Journal of Electronics and Communications 65(10), pp. 814-826, 2011.
[11] D.M. Thodi and J.J. Rodriguez, Expansion embedding techniques for reversible watermarking, IEEE Transactions on Image Processing 16(3), pp. 721-730, 2007.
[12] Y. Hu, H.K. Lee, and J. Li, DE-based reversible data hiding with improved over-flow location map, IEEE Transactions on Circuits and Systems for Video Technology 19(2), pp.
250-260, 2009.
[13] K.H. Jung, K.Y. Yoo, Data hiding using image interpolation, Computer Standards & Interfaces 31(2), pp. 465-470, 2009.
[14] X. Li, J. Li, B. Li, and B. Yang, High-fidelity reversible data hiding scheme based on pixel-value-ordering and prediction-error expansion, Signal Porcessing 93, pp. 198-205, 2013.
[15] K.H. Jung, K.Y. Yoo, Data hiding based on two-stage referencing for two-colour images, The Imaging Science Journal 61, pp. 475-483, 2013.
저 자 소 개 김 우 진(정회원)
1983년 경북대학교 전자공학과 전 자계산기전공(학사).
1989년 경북대학교 전자공학과 전 산전공(공학석사).
1999년 경북대학교 컴퓨터공학과 (박사수료).
1990년∼1991년 마산대학교 컴퓨터공학부 전임강사.
1991년∼현재 영진전문대학 컴퓨터정보계열 교수
<주관심분야 : 정보보호, 데이터베이스>
김 평 한(정회원)
2013년 대구대학교 정보통신대학 전산공학전공(학사).
2013년∼현재 경북대학교 컴퓨터 공학부 석사과정
<주관심분야 : 암호학, 정보보호, 스테가노그래피>
이 준 호(정회원)
1996년 경북대학교 전자공학과 (공학사).
1998년 경북대학교 전자공학과 (공학석사).
1998년∼현재 국방과학연구소 선임연구원
<주관심분야 : 정보보호, 스테가노그래피, 함정전 투체계, 체계공학>
정 기 현(정회원)
1995년 경북대학교 컴퓨터공학과 (공학사).
1997년 경북대학교 컴퓨터공학과 (공학석사).
2007년 경북대학교 컴퓨터공학과 (공학박사).
1997년∼2003년 국방과학연구소 선임연구원 2003년∼현재 영진전문대학 컴퓨터정보계열 교수
<주관심분야 : 정보보호, 디지털 워터마킹, 디지 털 포렌식, 스테가노그래피, 게임/모바일프로그래 밍>
유 기 영(정회원)-교신저자 1976년 경북대학교 수학교육과 (이학사).
1978년 한국과학기술원 컴퓨터 공학과 (공학석사).
1992년 미국 뉴욕 Rensselaer Polytechnic Institute 컴퓨터과학과 (공학박사).
1978년∼현재 경북대학교 컴퓨터공학과 교수 1997년∼1998년 한국정보과학회 영남지부장 1999년∼현재 한국정보과학회 영남지부장 1999년∼현재 한국정보과학회 이사
2006년∼현재 제12대 한국정보보호학회 부회장
<주관심분야 : 암호학, 정보보호, 네트워크보안, 스테가노그래피>