1)
1. 서 론
-스텝 시간차 학습은 몬테카를로 방법과 1-스텝 시간차 학습을 결합한 것으로, -스텝까지 관찰된 누적 보상과 번 째 스텝에서 기대되는 행동 가치가 결합된 값을 학습의 업데 이트 타겟으로 활용한다. 의 값을 적절하게 선택할 경우 -스텝 시간차 학습은 강화 학습의 성능을 높일 수 있어 1-스 텝 시간차 학습보다 좋을 수 있다[1,14]. 그러나 -스텝 시간 차 학습은 의 값이 커질수록 행동 가치의 분산이 높아져 환 경에 맞는 적절한 의 값을 찾기가 어렵다[22]. 최근 연구에서는 -스텝 시간차 학습의 변형을 제안했다 ※ 이 논문은 정부(교육부)의 재원으로 한국연구재단의 지원을 받아 수행된 기초연구사업임(No. 2018R1A6A1A03025526 및 No. NRF-2020R1I1A 3065610).† 준 회 원 : 한국기술교육대학교 컴퓨터공학과 미래융합공학전공 석사 †† 준 회 원 : 한국기술교육대학교 컴퓨터공학과 미래융합공학전공 박사과정 ††† 종신회원 : 한국기술교육대학교 컴퓨터공학과 교수
Manuscript Received : December 10, 2020 Accepted : February 20, 2021
* Corresponding Author : Youn-Hee Han([email protected])
[3-5]. 하지만 학습의 가속화를 위한 최적의 값을 찾는 방법 에 대한 논의는 없었다. 또 다른 연구에서는 TD()를 제안하였 는데, 이는 -스텝 시간차 학습에서 적절한 의 값을 찾기가 어 렵기 때문에 모든 -스텝 누적 보상을 활용하여 학습의 업데이 트 타겟을 계산하는 알고리즘이다[2,6,7]. 이 알고리즘은 라는 하이퍼-파라미터를 사용하여 모든 -스텝 누적 보상에 가중치 를 다르게 주어 평균을 계산한다. 하지만 적절한 값을 정해야 하는 문제와 몬테카를로 방법과 같이 에피소드가 종료되어야 누 적 보상을 계산할 수 있다는 문제가 있다. 본 논문에서는 -스텝 시간차 학습에서 최적의 을 선택 해야 하는 문제를 해결하기 위해, 이라는 새로운 -스텝 업데이트 타겟을 제안한다. 은 모든 -스텝 누적 보상의 최댓값과 평균으로 구성된다. 또한, 을 적용한 -스텝 Q-learning 알고리즘과 DQN 알고리즘 을 제안하고 다양한 환경에서 실험을 진행하여 제안하는 방 식의 성능을 검증한다. 본 논문의 2장에서는 강화 학습의 기본 개념과 실험에서 사
Max-Mean N-step Temporal-Difference Learning Using Multi-Step Return
Gyu-Young Hwang
†⋅Ju-Bong Kim
††⋅Joo-Seong Heo
††⋅Youn-Hee Han
†††ABSTRACT
-step TD learning is a combination of Monte Carlo method and one-step TD learning. If appropriate is selected, -step TD learning is known as an algorithm that performs better than Monte Carlo method and 1-step TD learning, but it is difficult to select the best values of . In order to solve the difficulty of selecting the values of in -step TD learning, in this paper, using the characteristic that overestimation of can improve the performance of initial learning and that all -step returns have similar values for ≈ ,
we propose a new learning target, which is composed of the maximum and the mean of all k-step returns for ≤ ≤ . Finally, in OpenAI Gym's Atari game environment, we compare the proposed algorithm with -step TD learning and proved that the proposed algorithm is superior to -step TD learning algorithm.
Keywords : Reinforcement Learning, Q-learning, DQN, -step Temporal-Difference Learning
멀티-스텝 누적 보상을 활용한 Max-Mean N-Step 시간차 학습
황 규 영
†⋅김 주 봉
††⋅허 주 성
††⋅한 연 희
†††요 약
-스텝 시간차 학습은 몬테카를로 방법과 1-스텝 시간차 학습을 결합한 것으로, 적절한 을 선택할 경우 몬테카를로 방법과 1-스텝 시간차 학습보다 성능이 좋은 알고리즘으로 알려져 있지만 최적의 을 선택하는 것에 어려움이 있다. -스텝 시간차 학습에서 값 선택의 어려움을 해소하기 위해, 본 논문에서는 의 과대평가가 초기 학습의 성능을 높일 수 있다는 특징과 ≈ 경우, 모든 -스텝 누적 보상이 비슷한 값을 가진다는 성질을 이용하여 ≤ ≤ 에 대한 모든 -스텝 누적 보상의 최댓값과 평균으로 구성된 새로운 학습 타겟인 을 제안한다. 마지막으로 OpenAI Gym의 Atari 게임 환경에서 -스텝 시간차 학습과의 성능 비교 평가를 진행하여 본 논문에서 제안하는 알고리즘이 -스텝 시간차 학습 알고리즘보다 성능이 우수하다는 것을 입증한다.키워드 : 강화 학습, Q-learning, DQN, -스텝 시간차 학습 Vol.10, No.5 pp.155~162
ISSN: 2287-5891 (Print), ISSN 2734-049X (Online)
https://doi.org/10.3745/KTCCS.2021.10.5.155
※ This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/ licenses/by-nc/3.0/) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
용된 강화 학습의 여러 알고리즘을 설명하고, 간단한 그리드 월 드 환경을 구성하여 실험을 통해 기존 -스텝 시간차 학습 알고 리즘의 문제점을 살펴보며 연구 동기를 밝힌다. 3장에서는 기존 -스텝 시간차 학습 알고리즘의 문제점을 개선한 알고리즘을 제안한다. 4장은 먼저 실험 환경을 소개하고 기존 -스텝 시간 차 학습 알고리즘과 본 논문에서 제안하는 알고리즘을 비교하는 실험을 진행한다. 마지막으로 5장에서 결론을 제시한다.
2. 관련 연구
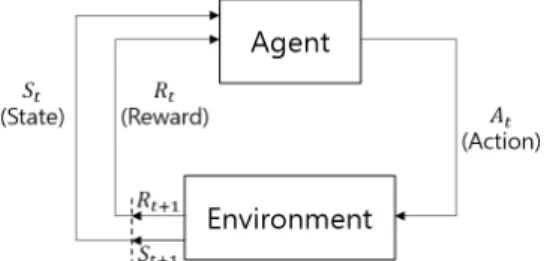
2.1 강화 학습 강화 학습(Reinforcement learning)은 머신 러닝의 한 분야로, 에이전트가 환경과 상호작용하며 시행착오를 거쳐 원하는 목표를 달성하기 위해 행동하는 법을 배우는 것이다. 강화 학습의 구성 요소로는 환경(Environment), 에이전트 (Agent), 그리고 환경과 에이전트의 상호작용으로 얻는 상태 (State), 행동(Action), 보상(Reward) 등 5가지가 있다.Fig. 1은 환경과 에이전트의 상호작용 흐름을 보여준다. 타임 스텝 에서, 에이전트는 상태 에서 정책(Policy) 에 의해 행동 를 선택하고 다음 상태 로 전환되며 보상 을 받는다. 여기서 정책 는 각 상태에서 어떤 행동을 취 할 것인가를 나타내는 확률밀도함수로 정의된다. 다음 상태 와 보상 은 에이전트에게 전달되어 이 과정을 다시 반복한다. 이 순환 과정은 에피소드가 종료될 때까지 계속되 며, 강화 학습의 최종 목표는 환경으로부터 받는 누적 보상을 최대화하는 최적 정책(Optimal Policy) 를 찾는 것이다. 타임 스텝 이후부터 받은 누적 보상 는 Equation (1) 과 같으며 완전 누적 보상(Complete Return)이라고도 한 다. ∈는 감가율(Discount Factor)이고 는 에피소드 종료 시점의 타임 스텝을 나타낸다. 감가율 는 최근에 받은 보상에 더 큰 가중치를 주고, →∞일 때 누적 보상 의 값 이 수렴하도록 돕는 역할을 한다. ⋯ (1) 에이전트가 시점에 어떤 상태 에서 시작해 정책 를 따라 행동하며 받는 누적 보상 의 기댓값을 상태 가치 함수
(State-Value Function) 라고 하며 다음과 같이 정의한다.
(2)
그리고, 에이전트가 시점에 어떤 상태 에서 행동 를 선
택하고 그 후 정책 를 따라 행동하며 받는 누적 보상 의
기댓값을 행동 가치 함수(Action-Value Function)
라고 하며 다음과 같이 정의한다. (3) 강화 학습 문제를 해결하는 방법으로는 크게 가치 기반 (Value-based) 강화 학습과 정책 기반(Policy-based) 강화 학 습이 있다. 본 논문에서는 가치 기반 강화 학습을 다룬다. 가치 기반 강화 학습에서 최적 정책 를 구하는 방법은 최적의 행동 가치 함수 를 추정한 후, 각 상태 에서 행동 가치 값이 최대인 행동을 선택하는 것이다. 이는 다음과 같이 표현된다. argmax (4) 에이전트가 학습을 진행할 때 탐욕적(Greedy) 행동 즉, argmax로만 행동을 선택한다면 에이전트가 잘못된 방 향으로 학습하여 국소 최적해(Local Optimum)에 빠질 가능 성이 크다. 이 문제를 해결하는 방법으로 -그리디( -greedy) 정책이 있다. 에이전트가 의 확률로 랜덤하게 행 동하거나 의 확률로 argmax인 행동을 하는 것이 다. -그리디 정책은 에이전트가 지속적으로 탐험하여 최적 정책을 찾도록 돕는다. 값은 에이전트의 학습이 진행될수록 점차 낮아져 탐험 빈도를 떨어뜨리는 것이 일반적이다. 2.2 -스텝 시간차 학습 최적의 행동 가치 함수 를 추정하는 방법으로는 몬테카를
로 방법(Monte Carlo Method)과 시간차 학습(Temporal-
Difference Learning)이 있다[1]. 몬테카를로 방법과 1-스 텝 시간차 학습은 행동 가치 함수 를 업데이트할 때 타겟 값을 설정하는 측면에서 차이가 있다. 몬테카를로 방법은 타임 스텝 부터 에피소드의 종료 시점 까지의 누적 보상 를 의 업데이트 타겟 값으로 사용한 다. 이는 Equation (1)과 같으며 에피소드의 종료 시점까지 를 나타내는 의미로 완전 누적 보상이라고도 한다. 반면, 1-스텝 시간차 학습에서 의 업데이트 타겟은 다음 과 같은 수식을 이용해 계산하고 로 표기한다. 이는 1-스텝 누적 보상(1-step return)이라 한다. (5) 1-스텝 누적 보상은 에이전트가 타임 스텝 에서 행동을 수행하고 다음 상태 로 전환되며 받은 보상 과 그
이후에 받을 보상에 대해서는 행동 가치 함수 로 예측한 값을 사용해 계산한다. 따라서 1-스텝 시간차 학습은 타임 스텝마다 를 업데이트할 수 있지만, 몬테카를로 방법은 타겟을 구하기 위해 에피소드의 종료 시점까지 가야 한다는 차이점이 있다. 이러한 이 유로 에피소드가 종료되지 않는 환경이나 에피소드의 길이가 긴 경우에는 몬테카를로 방법이 적합하지 않다. 1-스텝 누적 보상을 타겟으로 하는 의 업데이트 수식은 다음과 같으며, 는 학습률(Learning Rate)을 나타낸다. (6) 또한, 2-스텝 시간차 학습에서 의 업데이트 타겟은 다음 과 같다. (7) -스텝 시간차 학습은 몬테카를로 방법과 1-스텝 시간차 학습을 결합한 것으로 의 값을 적절하게 선택할 경우 강화 학습의 성능을 높일 수 있다[14]. ≥ ≤ 에 대하 여 -스텝 누적 보상(-step return)은 다음과 같이 정의된다. ⋯ (8) -스텝 누적 보상은 -스텝 이후의 누적 보상에 대해서는 행동 가치 함수 를 이용하여 값을 추정하기 때문에 완전 누 적 보상의 근삿값으로 볼 수 있다. 일 경우, 를 초 과하는 모든 항은 0으로 간주하며, -스텝 누적 보상은 완전 누적 보상과 같다. -스텝 시간차 학습에서 의 업데이트 수식은 다음과 같다. (9) 한편, TD() 알고리즘은 하이퍼-파라미터 를 기반으로 모든 -스텝 누적 보상에 가중치를 주어 평균을 계산하고 학 습의 업데이트 타겟으로 사용한다[1]. 이를 -누적 보상( -return)이라 하고 다음과 같이 정의한다.
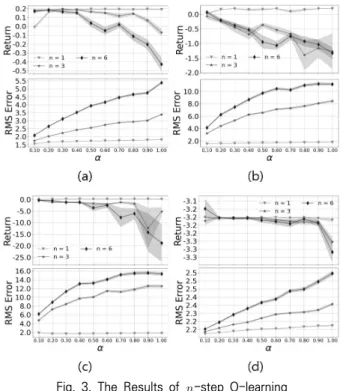
(10) -누적 보상은 에피소드의 종료 시점인 에 도달해야 계 산할 수 있다. 만약 이면, -누적 보상은 1-스텝 누적 보상인 와 같다. 그리고 이면, -누적 보상은 몬 테카를로 방법과 같은 완전 누적 보상인 와 같다. 일 때, 1-스텝 누적 보상의 가중치는 이고, 2-스텝 누적 보상의 가중치는 가 된다. 다른 누적 보상의 가중치는 동일한 방법으로 계산되며 모든 가중치의 합은 1이 된다. -스텝 시간차 학습과 마찬가지로 TD() 알고리즘 또한 적절한 값을 정해야 하는 문제가 있다[15]. 2.3 Q-learning 강화 학습에서 정책을 업데이트하는 방법으로는 온-폴리 시(on-policy) 알고리즘과 오프-폴리시(off-policy) 알고리 즘이 있다. 온-폴리시 알고리즘은 에이전트가 행동할 때 사 용하는 정책(행동 정책)과 학습하기 위해 타겟을 계산할 때 사용하는 정책(타겟 정책)이 같은 것을 말하고, 오프-폴리시 알고리즘은 행동 정책과 타겟 정책이 다른 것을 말한다. 오프 -폴리시 알고리즘의 장점은 행동 정책과 타겟 정책을 분리했 기 때문에 에이전트의 탐험을 위한 행동 정책으로는 -그리 디 정책을 사용하면서, 학습할 때는 그리디 정책을 사용하여 최적 정책을 배울 수 있다. Q-learning은 오프-폴리시 강화 학습 알고리즘으로, Q-learning의 1-스텝 누적 보상 수식은 다음과 같다[8,17]. max (11) -스텝 시간차 학습을 Q-learning에 적용하면, ≥ ≤ 에 대하여 -스텝 누적 보상은 다음과 같이 정의 된다[21,23]. ⋯ max (12) 2.4 -스텝 시간차 학습의 파라미터 민감성 이번 장에서는 몇 가지 실험 결과를 통해 연구 동기를 밝 힌다. 실험은 Fig. 2에 나타낸 네 가지의 × 그리드월드 환 경에서 진행하였다. 각각의 환경은 트랩이나 구덩이의 개수, 보상의 크기가 다르다. 에이전트는 동, 서, 남, 북 4가지의 행동을 취할 수 있고 벽과 맞닿아있는 상태에서 벽 쪽으로 가는 행동을 취할 때는 상태변화가 없다. 매 타임 스텝마다 –0.1의 보상을 받고, ‘S’ 에서 출발해 목표 ‘G’에 도달하면 1.0의 보상을 받으며 에피 소드는 종료된다. Fig. 2의 (b) 환경은 트랩 ‘T’에 도달하면 –3.0, (c) 환경은 트랩 ‘T’에 도달하면 –6.0의 보상을 받는다. (d) 환경에서는 구덩이 ‘H’에 도달하면 –3.0의 보상을 받으며 에피소드가 종료된다. Fig. 3은 네 가지의 × 그리드월드 환경(Fig. 2)에서의 다양한 과 학습률 에 대한 -스텝 Q-learning의 실험 결과이다. Fig. 3 (a), (b), (c), (d)의 실험 환경은 Fig. 2의 (a),
(b), (c), (d) 각각에 대응된다. 에이전트의 행동을 추론할 때 는 -그리디 정책을 사용하였고 값은 매 타임 스텝마다 점 진적으로 감소시켰다. 200 에피소드가 끝나면 학습을 종료하 였고, 이 과정을 100번 진행하였다. 그래프의 Return은 마 지막 에피소드에 받은 누적 보상을 나타내며, RMS Error는 다이나믹 프로그래밍(Dynamic Programming)으로 구한 행동 가치 의 true value와 강화 학습 -스텝 Q-learning 알고리즘으로 구한 행동 가치 의 평균 제곱근 편차(RMSE) 를 나타낸다. 는 학습률을 의미한다. 그래프의 결과는 100 번 진행하며 얻은 값들의 평균과 표준편차를 표시한 것이다.
Fig. 3에 나타난 결과와 같이, RMSE는 과 에 비례하여 증가하는 반면, Return은 과 가 변경됨에 따라 결과가 크 게 달라진다. 과 가 작을 때는 에이전트의 정책이 느리게 수렴 하면서 많은 상태를 방문하며 대부분의 행동 가치 값을 업데이 트하지만, 과 가 클 때는 최적 정책이 아닌 잘못된 정책으로 빠르게 수렴하면서 일부의 값만 업데이트되어 RMSE가 커 지는 것으로 생각된다. Table 1은 ⋯ 중 2개의 값 과 에 대한 실험 결과이며, Return이 가장 높을 때의 과 가장 낮을 때의 을 나타낸다. Table 1에 나타난 결과와 같이 은 실험 환경과 학습률 의 변화에 민감하여 최적과 최악의 을 찾는 것이 어렵다. 따라서 -스텝 시간차 학습의 성능은 파 라미터에 민감하다는 것을 알 수 있다[16]. 2.5 -스텝 시간차 학습의 편향-분산 트레이드오프 Equation (12)의 Q-learning -스텝 누적 보상은 다음 의 2가지로 분리하여 볼 수 있다.
(13) max (14) Equation (13)은 에이전트가 환경과 상호작용하며 받은 실 제 보상을 의미하며, Equation (14)는 에이전트가 받은 보상이 아닌 행동 가치 함수 를 사용하여 누적 보상을 추정한 값이다. 의 값이 커지면 -스텝 누적 보상에서 Equation (13)의 비중이 높아지며 Equation (14)의 비중은 낮아진다. 에이전 트는 환경을 탐험하기 위해 확률적으로 행동하기 때문에 같은 상태에 존재하더라도 다른 행동을 취하며 다른 보상을 받을 수 있다. 따라서 이 커지면 확률적으로 행동하며 받은 보상 의 비중이 커지므로 -스텝 누적 보상의 분산이 커지게 된다. 이와 반대로 의 값이 작아지면 -스텝 누적 보상에서 Equation (13)의 비중은 낮아지며 Equation (14)의 비중은 높아진다. 의 값이 1인 경우를 예로 들면, 1-스텝 누적 보상을 계산할 때 에 이전트가 받은 실제 보상은 단 하나만 사용되며 이후의 누적 보 상에 대해서는 에서의 행동 가치 함수 로 계산하기 때문에 Equation (14)의 비중이 높아지는 것이다. 행동 가치 함수 는 학습 중인 에이전트가 받을 누적 보상을 추정한 값이기 때문에 실제 값과는 차이가 있고 이로 인해 편향이 발생하게 된다. 따라서 -스텝 시간차 학습 알고리즘은 이 커지면 -스 텝 누적 보상의 분산이 커지고 이 작아지면 편향이 발생하 는 편향-분산 트레이드오프 문제가 있다[21,22].3. Max-Mean -스텝 시간차 학습
2장에서 -스텝 시간차 학습이 환경과 하이퍼-파라미터에 민감하여 적절한 을 선택하는 것이 어렵다는 문제를 밝혔 다. 본 장에서는 기존 -스텝 시간차 학습 알고리즘에서 적 절한 을 선택해야 하는 문제를 해결하기 위해, ≤ ≤ 에 대한 모든 -스텝 누적 보상의 최댓값과 평균으로 구성된 이라는 새로운 -스텝 업데이트 타겟을 제안한다. 3.1 멀티-스텝 누적 보상의 최댓값과 평균 본 논문에서 제안하는 방법은 -스텝 누적 보상에 기초하 여 가장 좋은 업데이트 타겟을 결정하는 것에서 시작된다. Q-learning 알고리즘의 학습 타겟인 1-스텝 누적 보상의 Equation (11)을 보면 max 가 사용된다. 의 max를 취하는 것은 실제 값보다 과대평가되어 편향이 발 생해 문제를 야기할 수 있지만, Qingfeng Lan은 의 과대 평가가 항상 해로운 것은 아니며 학습 성능을 향상시킬 수도 있다고 하였다[24]. 강화 학습 환경에서는 에이전트가 탐험을 통해 의미 있는 경험을 빠르게 배우는 것이 중요하기 때문에, 만약 높은 보상을 받을 수 있는 상태-행동(State-Action)에 대한 값이 과대평가되어 있다면 에이전트가 해당 영역을 탐 Experiment best worst best worst
(a) 3 1 3 6
(b) 6 3 1 3
(c) 1 3 1 6
(d) 6 3 1 3
Table 1. The Best and Worst for four Types of Gridworld
Fig. 2. Four Types of × Gridworld
험하도록 장려하여 학습에 이점을 줄 수 있기 때문이다. 이러한 이유로, ≤ ≤ 에 대한 모든 -스텝 누적 보상 중에서 최댓값은 편향이 크지 않은 학습 초기에 좋은 업데이 트 타겟으로 활용될 수 있다. 이 최댓값을 라 하고 다음 과 같이 정의한다. max ≤ ≤ (15) 만약 모든 상태와 행동에 대한 최적의 행동 가치 함수 를 찾았다면, ≤ ≤ 에 대한 모든 -스텝 누적 보상 는 같은 값을 가진다. Theorem 1. Q-learning에서 만약≈이면, ≈ ≈⋯≈ proof. 벨만 최적 방정식에 의해, 최적의 행동 가치 함수 는 다음과 같이 정의할 수 있다[20]. max max ⋯ ⋯ max 그리고 Equation (12)에 따라서, ⋯ 은 다음과 같이 쓸 수 있다. max max ⋯ ⋯ max 만약 ≈이면, 모든 에 대해 max ≈max 가 성립하며 행동 는 최적 정책에 의해 argmax 로 정해지므로 다음과 같이 쓸 수 있다. ≈ max ≈ max ⋯ ≈ ⋯ max
∴
벨만 최적 방정식에 의해, ≈ ≈⋯≈ ■ Corollary 1.1. Q-learning에서 만약≈이면, ≈ ≈⋯≈ ≈ Corollary 1.1에 따라, 아래와 같은 수식을 얻을 수 있다.
≈ (16) Equation (16)으로부터, 학습이 충분히 이루어졌을 때 ≤ ≤ 에 대한 모든 -스텝 누적 보상의 평균이 Q-learning의 좋은 학습 타겟으로 활용될 수 있음을 알 수 있다. 이 평균을 이라 하고 다음과 같이 정의한다.
≤ ≤ (17) 3.2 3.1에서 살펴본 바와 같이 는 학습 초기에 좋은 업데 이트 타겟으로 활용될 수 있지만, 학습이 진행되며 과대평가 편 향 문제가 발생할 위험이 있다[11]. 반면, 은 학습이 충분 히 이루어졌을 때 좋은 업데이트 타겟으로 쓰일 수 있다. 따라 서, 와 을 결합한 새로운 학습 타겟인 을 제안하며, 다음과 같이 정의한다. ≤ ≤ (18) Equation (18)에서, 는 와 의 비율을 결정하는 파라미터이다. 본 논문은 파라미터 를 Equation (19)로 대체 하였다. max max min ≤ ≤ (19) 학습 초기에는 max 와 min 의 값이 차이가 나기 때문에 에서 의 비율이 높지만, 학습이 진행되며 max 와 min 의 차이가 줄어들면 의 비율은 낮아지고 의 비율이 높아지게 된다. 3.3 을 적용한 -스텝 Q-learning 알고리즘 본 논문에서 제안하는 새로운 학습 타겟인 을 적용 한 -스텝 Q-learning 알고리즘의 의사코드(Pseudo-code)는 Algorithm 1과 같다. 는 분모가 0이 되는 것을 방지하기 위한 매우 작은 양의 상수를 나타낸다. 12번째 줄부터 18번째 줄 까지는 에피소드가 종료될 때까지 에이전트가 상태 에서 행동 를 선택하고 보상 을 받으며 다음 상태 로 넘어가 는 것을 나타낸다. 22번째 줄부터는 를 업데이트하는 과정 을 보여준다. ≤ ≤ 에 대한 모든 -스텝 누적 보상을 계 산한 뒤, 이의 최댓값과 평균을 이용하여 학습 타겟인 을 계산한다. 학습 타겟과 현재 와의 차이를 이용 하여 학습률 만큼 를 업데이트한다.4. 실 험
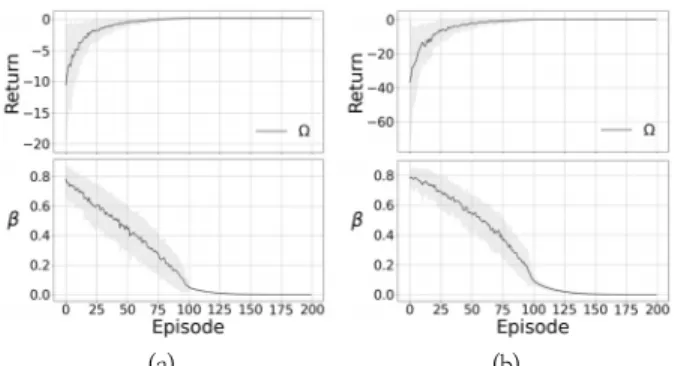
4.1 학습 정도에 따른 값 변화 실험 Fig. 4는 두 가지의 × 그리드월드 환경(Fig. 2)에서 학 습 정도에 따른 에서 와 의 비율을 결정 하는 파라미터 값의 변화에 대한 실험 결과이다. Fig. 4 (a), (b)의 실험 환경은 Fig. 2의 (a), (b) 각각에 대응된다. 200 에피소드가 끝나면 학습을 종료하였고, 이 과정을 100번 진 행하였다. 그래프에 나타낸 값은 해당 에피소드에서 매 타 임 스텝마다 계산한 값들의 평균을 의미한다. 실험 결과를 통해 학습 초반에 높았던 값이 학습이 진행되면서 점점 낮 아지는 것을 볼 수 있다. 4.2 의 성능 평가 본 논문의 실험 목적은 -스텝 시간차 학습에서 적절한 을 선택해야 하는 문제를 해결하기 위해 제안하는 새로운 학 습 타겟인 의 성능을 평가하는 것이다. 따라서 실험은 기존 -스텝 시간차 학습 알고리즘과의 비교 평가를 진행한다. 본 논문의 실험은 Nature DQN[9, 10]과 이의 확장 알고리즘인 Double DQN[12,13], Dueling DQN[18], Prioritized
Experience Replay[19] 알고리즘을 통합한 기법 위에 기존 -스텝 시간차 학습과 제안하는 방법을 구현하여 비교 실험 을 진행하였다[16]. 기존 -스텝 시간차 학습 알고리즘에서 ={1, 3, 6} 3가지에 대 해서 실험을 진행하였다. 본 논문에서 제안하는 의 ≤ ≤ 에서의 은 기존 -스텝 시간차 학습 알고리즘에 서 6까지 실험하였으므로 동일하게 6으로 설정하였다.
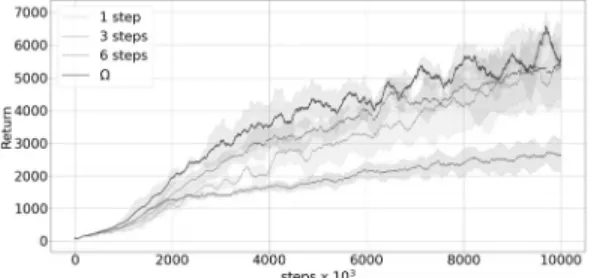
실험은 OpenAI Gym의 Atari 게임 중 ‘Pong’, ‘Enduro’,
‘Seaquest’, ‘Freeway’ 4개 환경에서 진행하였다[25]. 실험 결과는 Fig. 5와 같으며 데이터는 100개에 대한 이동평균 (Moving Average)을 나타낸다. 실험은 1-스텝, 3-스텝, 6-스텝, 모두 각각 3번씩 측정하였으며, 3번 측정한 것의 평 균과 표준편차를 그래프에 나타내었다. 그래프의 가로축은 강화 학습 환경에서의 타임 스텝 를 나타내며, 세로축은 에 이전트가 한 에피소드의 시작부터 끝날 때까지 받은 누적 보 상을 의미한다. Return은 매 1000타임 스텝마다 측정하였으 며 직전 100개 에피소드에서 받은 누적 보상의 평균을 의미 한다. 따라서 그래프가 가로축 대비 세로축이 빠르게 올라가 는 것은 에이전트가 학습을 빠른 시간 내에 배우고 있다는 것 을 의미하기 때문에 좋은 성능을 낸 것이라고 볼 수 있다. Fig. 5의 실험 결과로부터 본 논문에서 제안하는 알고리즘 이 기존 -스텝 시간차 학습 알고리즘보다 전반적인 학습 성 능이 우수하다는 것을 알 수 있다. 학습 초반 모든 실험 환경 에서 제안하는 알고리즘의 성능이 우수한 것을 보아 학습 초 기에 가 좋은 타겟이라는 것을 알 수 있고, 학습이 진행 되며 성능이 떨어지지 않는 것을 보아 이 과대평가 문제를 방지하였다고 볼 수 있다. 또한 Fig. 5-2나 Fig. 5-4의 결과와 같이 기존 -스텝 시간차 학습 알고리즘의 성능이 1-스텝 시간 차 학습보다 떨어지는 경우에도 본 논문에서 제안하는 알고리즘 의 성능이 좋다는 것을 알 수 있다. 따라서 이 -스 텝 시간차 학습에서 을 선택해야 하는 문제를 해결하는 새 로운 학습 타겟으로 적절하다고 생각한다.
5. 결 론
-스텝 시간차 학습은 적절한 을 선택할 경우 1-스텝 시 간차 학습보다 성능이 좋은 알고리즘으로 알려져 있다. 하지 만, -스텝 시간차 학습은 강화 학습 환경의 변화에 따라 최적 의 이 바뀌는 파라미터 민감성의 문제가 있다. 또한, -스텝 시 간차 학습의 타겟 값인 -스텝 누적 보상은 의 값이 커지면 분산이 높아지고, 의 값이 작아지면 편향이 커지는 편향-분산 (a) (b)트레이드오프 문제가 있다. 따라서 -스텝 시간차 학습 알고리 즘은 하이퍼-파라미터 을 선택하기 어려운 문제가 있다. 본 논문에서는 ≤ ≤ 에 대한 모든 -스텝 누적 보상의 최댓값과 평균으로 구성된 이라는 새로운 -스텝 업데이트 타겟을 제안하고, 을 적용한 -스텝 Q-learning 알고리즘을 제안한다.
실험은 Nature DQN과 이의 확장 알고리즘인 Double
DQN, Dueling DQN, Prioritized replay buffer 알고리즘
들을 통합한 기법 위에서 기존 -스텝 시간차 학습과 제안하 는 알고리즘의 성능 비교 평가를 진행하였다. OpenAI Gym 의 Atari 게임 환경에서의 실험 결과 본 논문에서 제안하는 알고리즘이 기존 -스텝 시간차 학습 알고리즘보다 성능이 우수하다는 것을 입증하였다. 본 논문에서 제안하는 은 ≤ ≤ 에 대한 모든 -스텝 누적 보상의 최댓값과 평균으로 구성되기 때문에 범 위를 지정하는 이 하이퍼-파라미터라고 볼 수 있다. 하지 만, 기존 -스텝 시간차 학습에서도 최적의 을 찾기 위해서 1-스텝부터 몇 스텝까지 실험을 할지 결정해야 하는 문제는 동일하며, 지정된 범위 내의 모든 값을 전부 실험하여 적절한 값을 찾아야 하는 문제가 있다. 본 논문에서 제안하는 알고 리즘은 기존 -스텝 시간차 학습 알고리즘에서 을 선택하 는 문제를 해결하였고 -스텝 시간차 학습이 1-스텝 시간차 학습보다 낮은 성능을 보이는 환경에서도 제안하는 알고리즘 의 성능이 우수한 것을 보였다.
References
[1] R. S. Sutton, “Learning to Predict by the Methods of Temporal Differences,” Machine Learning, Vol.3, No.1,
pp.9–44, 1988.
[2] H. Seijen and R. Sutton, “True Online TD(
),” InProceed-ings of the 31st International Conference on Machine Learning, vol. 32 of Proceedings of Machine Learning
Research, pp.692–700. PMLR, Bejing, China, 2014.
[3] K. D. Asis, J. Hernandez-Garcia, G. Holland, et al., “Multi- Step Reinforcement Learning: A Unifying Algorithm,” In Association for the Advancement of Artificial Intelligence, 2018.
[4] S. L. Chen, H. Z. Wu, X. L. Han, and L. Xiao, “Multi-Step Truncated Q Learning Algorithm,” In 2005 International Conference on Machine Learning and Cybernetics, Vol.1,
pp.194–198. 2005.
[5] K. De Asis and R. Sutton, “Per-decision Multi-step Temporal Difference Learning with Control Variates,” arXiv:1807.01830, 2018.
[6] A. R. Mahmood, H. Yu, and R. Sutton, “Multi-step Off- policy Learning without Importance Sampling Ratios,” arXiv: 1702.03006, 2017.
[7] L. Yang, M. Shi, Q. Zheng, W. Meng, and G. Pan, “A Unified Approach for Multi-step Temporal-Difference Learning with Eligibility Traces in Reinforcement Learning,” In Proceedings of the Twenty-Seventh International Joint
Conference on Artificial Intelligence, IJCAI-18, pp.2984–
2990, 2018.
[8] C. J. C. H. Watkins and P. Dayan, “Q-learning,” Machine
Learning, Vol.8, No.3, pp.279–292, 1992.
[9] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing Atari with Deep Reinforcement Learning,” Cite arXiv:1312. 5602Comment: NIPS Deep Learning Workshop 2013.
Fig. 5-1. OpenAI Gym Atari-Pong Fig. 5-3. OpenAI Gym Atari-Seaquest Environment
[10] V. Mnih, et al., “Human-level Control through Deep Rein-forcement Learning,” Nature, Vol.518, pp.529-533, 2015. [11] S. Thrun A. and Schwartz, “Issues in using function approx-imation for reinforcement learning,” In Proceedings of the Fourth Connectionist Models Summer School, Erlbaum, 1993.
[12] H. van Hasselt, “Double Q-learning,” In Advances in Neural
Information Processing Systems, Vol.23, pp.2613–2621, 2010.
[13] H. van Hasselt, A. Guez, and D. Silver, “Deep Reinforcement Learning with Double Q-learning,” In Association for the Advancement of Artificial Intelligence, 2016.
[14] R. S. Sutton and A. G. Barto, “Reinforcement Learning: An Introduction,” The MIT Press, Second Edn., 2018. [15] J. Peng and R. J. Williams, “Incremental Multi-Step
Q-Learning,” Machine Learning, Vol.22, No.1, pp.283–290,
1996.
[16] M. Hessel, et al., “Rainbow: Combining Improvements in Deep Reinforcement Learning,” In Association for the
Advancement of Artificial Intelligence, pp.3215–3222, AAAI
Press, 2018.
[17] C. J. C. H. Watkins, “Learning from delayed rewards,” (Doctoral dissertation, Cambridge University).
[18] Z. Wang, T. Schaul, M. Hessel, H. Hasselt, M. Lanctot, and N. Freitas, “Dueling Network Architectures for Deep Reinforcement Learning,” In Proceedings of The 33rd International Conference on Machine Learning, in PMLR 48:1995-2003, 2016.
[19] T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized Experience Replay,” 2015. Cite arXiv:1511.05952Comment: Published at ICLR 2016.
[20] S. J. Bradtke and M. O. Duff, “Reinforcement learning methods for continuous-time Markov decision problems,” In Proceedings of the 7th International Conference on Neural Information Processing Systems, MIT Press,
Cambridge, MA, USA, pp.393–400, 1994.
[21] J. Hernandez-Garcia and R. Sutton, “Understanding Multi- Step Deep Reinforcement Learning: A Systematic Study of the DQN Target,” 2019. Cite arXiv:1901.07510Comment: NIPS Deep Learning Workshop 2018.
[22] M. J. Kearns and S. P. Singh, “Bias-variance error bounds for temporal difference updates,” In Proceedings of the Thirteenth Annual Conference on Computational Learning
Theory, pp.142–147. San Francisco, CA, USA, 2000.
[23] D. Horgan, J. Quan, D. Budden, G. Barth-Maron, M. Hessel, H. Hasselt, and D. Silver, “Distributed prioritized experience replay,” 2018. Cite arXiv:1803. 00933Comment: Published at ICLR 2018.
[24] Q. Lan, Y. Pan, A. Fyshe, M. White, “Maxmin Q-learning: Controlling the Estimation Bias of Q-learning,” 2020. Cite arXiv:2002.06487Comment: Published at ICLR 2020.
[25] OpenAI. OpenAI Gym Docs [Internet], https://gym.openai. com/docs/. Accessed: 2020-11-20.
황 규 영
https://orcid.org/0000-0002-5014-8826 e-mail : [email protected] 2019년 한국기술교육대학교 컴퓨터공학부 (학사) 2021년 한국기술교육대학교 컴퓨터공학과 미래융합공학전공(석사) 2021년~현 재 (주)인투와이즈 연구원 관심분야 : 강화 학습, 딥러닝김 주 봉
https://orcid.org/0000-0001-6406-3092 e-mail : [email protected] 2017년 한국기술교육대학교 컴퓨터공학부 (학사) 2019년 한국기술교육대학교 컴퓨터공학과 (석사) 2019년~현 재 한국기술교육대학교 컴퓨터공학과 미래융합공학전공 박사과정 관심분야 : 강화 학습, 다중 에이전트 강화 학습, 딥러닝허 주 성
https://orcid.org/0000-0002-2486-9515 e-mail : [email protected] 2016년 한국기술교육대학교 컴퓨터공학부 (학사) 2019년 한국기술교육대학교 컴퓨터공학과 (석사) 2019년~현 재 한국기술교육대학교 컴퓨터공학과 미래융합공학전공 박사과정 관심분야 : 강화 학습, 딥러닝, 금융데이터 분석한 연 희
https://orcid.org/0000-0002-5835-7972 e-mail : [email protected] 1998년 고려대학교 컴퓨터학과(석사) 2002년 고려대학교 컴퓨터학과(박사) 2002년~2006년 삼성종합기술원 전문연구원2013년~2014년 SUNY at Albany, Department of Computer Science 방문교수
2006년~현 재 한국기술교육대학교 컴퓨터공학부 교수 관심분야 : 사물인터넷, 기계 학습, 강화 학습