딥러닝을 이용한 풍력 발전량 예측
최정곤ㆍ최효상*
Prediction of Wind Power Generation using Deep Learnning
Jeong-Gon ChoiㆍHyo-Sang Choi* 요 약
본 연구는 풍력발전의 합리적인 운영 계획과 에너지 저장창치의 용량산정을 위한 풍력 발전량을 예측한다. 예측을 위해 물리적 접근법과 통계적 접근법을 결합하여 풍력 발전량의 예측 방법을 제시하고 풍력 발전의 요 인을 분석하여 변수를 선정한다. 선정된 변수들의 과거 데이터를 수집하여 딥러닝을 이용해 풍력 발전량을 예 측한다. 사용된 모델은 Bidirectional LSTM(:Long short term memory)과 CNN(:Convolution neural network) 알고리즘을 결합한 하이브리드 모델을 구성하였으며, 예측 성능 비교를 위해 MLP 알고리즘으로 이루어진 모 델과 오차를 비교하여, 예측 성능을 평가하고 그 결과를 제시한다.
ABSTRACT
This study predicts the amount of wind power generation for rational operation plan of wind power generation and capacity calculation of ESS. For forecasting, we present a method of predicting wind power generation by combining a physical approach and a statistical approach. The factors of wind power generation are analyzed and variables are selected. By collecting historical data of the selected variables, the amount of wind power generation is predicted using deep learning. The model used is a hybrid model that combines a bidirectional long short term memory (LSTM) and a convolution neural network (CNN) algorithm. To compare the prediction performance, this model is compared with the model and the error which consist of the MLP(:Multi Layer Perceptron) algorithm, The results is presented to evaluate the prediction performance.
키워드
Wind power, prediction, LSTM(:Long short term memory), CNN(:Cellular neural network), Artificial intelligence 풍력발전, 예측, 머신 러닝, 다중 퍼셉트론, 재귀 신경망, 중기 단기 기억, 인공지능, 전력량
조선대학교([email protected]) *교신저자: 조선대학교 전기공학과 ㆍ접 수 일 : 2021. 02. 27 ㆍ수정완료일 : 2021. 03. 23
ㆍReceived : Feb. 27, 2021, Revised : Mar. 23, 2021, Accepted : Apr. 17, 2021 ㆍCorresponding Author : Hyo-Sang Choi
Chosun University, Electrical Engineering. Email : [email protected]
Ⅰ. 서 론
태양광 발전과 풍력 발전으로 대표되고 있는 신재 생 에너지는 반영구적으로 사용할 수 있으며, 점차 고 갈 되어가는 화석 에너지의 대체 에너지로 관심이 높 다. 화석 에너지는 지구 온난화와 미세먼지 방출 등 많은 문제점이 많지만, 신재생 에너지는 일부 환경적 인 문제가 있다고 지적되고 있지만 아직까지 큰 문제 가 없는 친환경 에너지로 각광 받고 있다. 전 세계적 으로 신재생 에너지는 태양열, 수력 그리고 풍력 에너 지가 대표적으로 연구되고 있고, 발전소가 점차 확대 되고 있다. 우리나라는 재생에너지 확대, 보급 정책인 http://dx.doi.org/10.13067/JKIECS.2021.16.2.329"재생 에너지 3020 이행계획"을 진행하고 있다. 이 정 책은 신재생 에너지 발전 비중을 20% 이상으로 늘리 고, 풍력발전의 경우 2030년까지 전체 설비 용량의 6.2%를 목표로 하고 있다[1]. 풍력 발전은 바람에 의해 발전이 되기 때문에 태양 열에 비해 발전 시간에 제약을 받지 않는다. 풍력 발 전은 공해를 일으키지 않으며, 전력 소비량이 가장 많 은 시간대에 발전량이 많다. 하지만 풍속과 풍향이 일 정한 패턴을 갖고 있지 않아 불안정하게 발전되며, 이 는 계통의 무효 전력을 생성하는 등 전력 품질 저하 에 관련하여 많은 문제들을 갖고 있다. 또한 발전력이 예상보다 크면 잉여 전력이 생겨서 낭비되는 전력으 로 분류되어 경제적으로 문제를 갖고 있다. 이를 해결 하기 위해 ESS(:Energy storage system) 기술이 대두 되고 있다. ESS 기술은 에너지를 저장하여 수요자가 필요한 시점에만 공급하는 장치로 계통의 신뢰성을 높일 수 있다. 또한 풍력 발전의 잉여 전력을 저장하 여 전력이 필요한 시점에 공급할 수 있어 잉여 전력 이 낭비되지 않는다. ESS 기술은 풍력발전의 운영의 안정성과 신뢰도를 높일 수 있지만, ESS 기술은 기술 과 비용의 한계가 있기 때문에 풍력 발전량을 예측하 여 경제적인 이득을 최대한 취해야 한다. 풍력 발전량 의 예측 종류는 시간 단위에 따라 3가지로 분류할 수 있다. 시간 단위가 가장 큰 Long term은 월 단위로 풍력 발전을 예측하며 네트워크의 유지 및 관리가 목 적이다. 두 번째, Short term은 일 단위로 예측하며, 풍력 발전의 품질과 합리적인 운영 계획이 목적이다. 세 번째, Immediate short term은 시간 단위로 예측 하며, 실시간 전력 운영 관리 및 풍력 발전기의 터빈 상태 확인 등을 목적으로 하고 있다[2]. 표 1은 시간 단위에 따른 풍력 발전량의 종류를 나타낸다. 풍력 예측은 물리적 접근법과 통계적 접근법이 있 다[3]. 물리적 접근법은 풍력 발전량과 변수들 간의 상관관계를 분석하여 수학 함수로 풍력 발전의 예측 을 접근한다. 일반적으로 지역 기상청에서 입수해 풍 력발전소에서 풍력 터빈으로 변환되는 풍속이 풍력으 로 전환된다[4]. 통계적 접근법은 풍력 발전과 변수들 간의 상관관계를 고려하지 않고, 방대한 양의 과거 데 이터를 기반으로 하며 신경망, 신경 퍼지 네트워크와 같은 시계열 분석 접근법을 포함한다[5].
Criteria Range Aim
Long term Month Maintance of Electric power
network
Short term Day
Quality of wind power generation and rational plan
operation
Immediate
short term hours Real-time power management 표 1. 시간 단위에 따른 풍력 발전량 예측의 종류 Table 1. Type of wind power generation prediction by
time unit 본 연구는 물리적 접근법과 통계적 접근법을 결합 하여 예측 방법을 시도한다. 기상조건을 고려하여 방 대한 양의 온도, 압력, 공기 밀도 데이터를 사용해 딥 러닝 기법으로 풍력 발전량 예측을 한다. 풍력 발전 예측은 딥러닝과 연관하여 많은 선행 연 구들이 진행되었다. 대표적으로 [6]은 풍력 발전 월간 예측을 정규 크리깅을 이용하여 예측 발전량과 풍력 발전량의 유사성 및 상관관계가 높음을 확인하였다. [7]은 타 지역의 발전 데이터를 사용하여 풍력 발전량 을 예측하였으며, 사용된 변수는 발전량, 풍향, 풍속이 다. [6]은 월간 예측을 하였기 때문에 네트워크의 유 지 관리의 목적에 사용될 수 있지만 풍력 발전의 품 질과 합리적인 계획을 할 때는 사용될 수 없다. [7]은 풍속과 풍향은 지역과 지역 간 영향을 주고받는다. 타 지역이라도 같은 제주도 지역이면 영향이 매우 크기 때문에 타 지역의 풍력 발전 예측에는 한계점이 있다. 또한 지금까지의 대부분의 풍력 발전의 발전량 예측 에 대한 연구는 하나의 딥러닝 알고리즘을 적용한 경 우가 대부분이다. 단일 인공지능 알고리즘의 경우 발 전량 예측 정도가 낮아 이에 대한 개선이 요구된다. 이에 본 논문은 풍력 발전의 품질과 합리적인 운영 관리를 위해 일간 풍력 발전을 예측을 위해 딥러닝 알고리즘을 2개로 구성하여 히이브리드 형태로 구성 한 후 발전량을 예측하였으며, 입력 데이터는 풍력, 풍향, 공기 밀도를 사용하여 예측한다.
Ⅱ. 풍력 발전의 특성 및 요인 분석
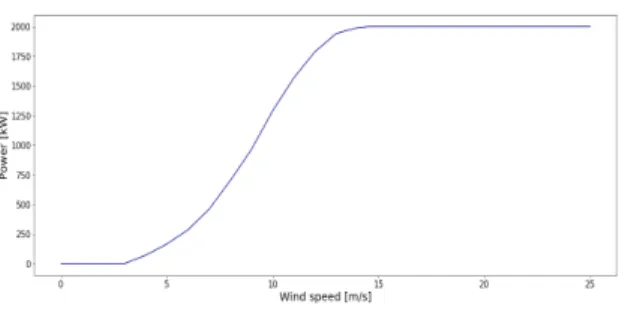
2.1 풍력 발전 대관령은 태백산맥을 중심으로 해발 900m 이상의 고산지대이자 바람이 많고 풍속과 풍향이 일정하다. 또한 대관령 풍력발전소는 국내 최대 규모의 98MW 급 풍력발전단지로써 Vestas의 V80/2000을 사용하고 있다. 대관령에는 총 49기의 풍력발전기가 설치되어 있으며, 1기당 2MW이고, 터빈 Hub의 높이는 78m이 다. 표 2는 V80/2000의 data sheet를 나타낸다[11]. 본 논문에서는 대관령에 설치한 풍력발전소의 발전량 예 측을 수행한다. 그림 1은 대관령 풍력 발전기의 풍력에 따른 발전 그래프인 전력 곡선 그래프를 나타낸다. 픙력 발전기의 시동풍속은 4m/s, 정격 풍속은 15m/s, 종단 풍속은 25m/s이며, 최고 발전량은 2000kW이다. V80/2000으로 발전한 대관령 풍력발전소의 총 발 전량을 데이터로 취득하였으며 2018년부터 2019년 까 지 일별 풍력 발전량으로 취득하였다. 그림 2는 대관 령 풍력발전소에서 취득한 풍력발전량을 나타낸다. Parameter Data Rated power 2,000 [kW] Cut-in wind speed 4.0 [m/s]Rated wind speed 16 [m/s] Cut-out wind speed 25 [m/s] Operating temperature -20 to 40 [°C]
Rotor diameter 80 [m] Rotor swept area 5,027 [m
] Operational interval 10.8 to 19.1 [rpm]
Blade length 39 [m] Electrical frequency 50/60 [Hz]
표 2. V80/2000의 데이터시트 Table 2. Data sheet of V80/2000
그림 1. 대관령 발전기의 파워 곡선 그래프 Fig. 1 Power curve graph of Daegwallyeong wind power
plant
그림 2 대관령 풍력발전소의 발전량 Fig. 2 Power generation of Daegwallyeong Wind Power
Plant 2.2 변수 풍력 발전량 예측에 사용된 변수는 풍속, 풍향 그 리고 공기밀도이다. 풍력 발전에 있어서 풍속과 풍향 은 반드시 필요한 요소이다. 풍속과 풍향은 종관기상 관측장비(ASOS)로 측정되었으며, 실측 위치는 남동 쪽으로 풍력 발전소와 이격거리는 2.64km 만큼 위치 하고 있다[12]. 풍력 에너지는 일반적으로 에너지 밀도로 평가한 다. 에너지 밀도는 공기의 이동에너지이며 공기의 이 동에너지는 공기 밀도에 비례한다[13]. 공기의 이동에 너지에 관한 공기밀도와 풍속의 관계식 (1)과 같이 정리할 수 있다. Eai r Wm (1) 여기서,
는 공기밀도,
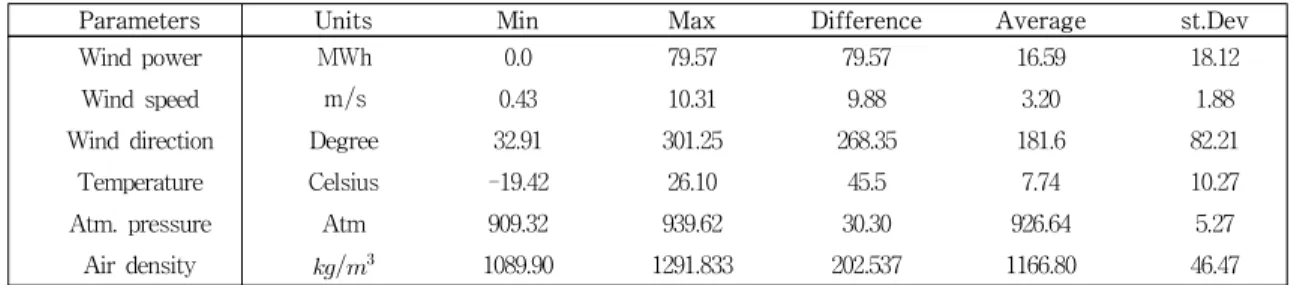
는 풍속을 나타내며, 공기밀 도는 현지 기압에 비례하고 기온에 반비례한다.Parameters Units Min Max Difference Average st.Dev
Wind power MWh 0.0 79.57 79.57 16.59 18.12
Wind speed ms 0.43 10.31 9.88 3.20 1.88
Wind direction Degree 32.91 301.25 268.35 181.6 82.21 Temperature Celsius -19.42 26.10 45.5 7.74 10.27 Atm. pressure Atm 909.32 939.62 30.30 926.64 5.27
Air density 1089.90 1291.833 202.537 1166.80 46.47 표 3. 취득한 데이터의 통계 분석표
Table 3. Statistical analysis of acquired data
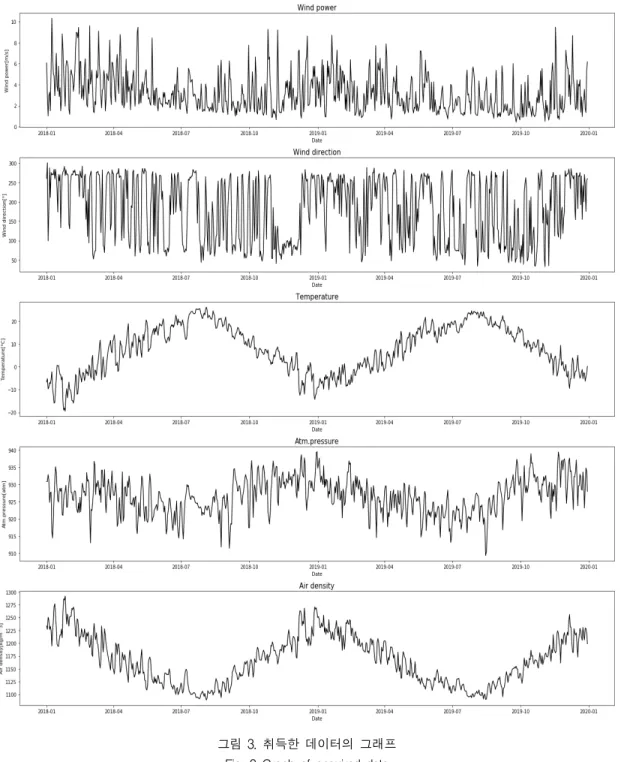
공기밀도에 관한 기압과 기온의 관계는 식(2)과 나 타낼 수 있다[14] kgm (2) 여기서 는 현지 기압, 는 기온을 나타낸다. 우리는 공기밀도를 계산하기 위해 기상 관측소에서 현지 기압과 기온을 취득하였다. 기온의 특징은 4계절이 뚜렷하며 1월이 가장 낮고 8월이 가장 높으며, 봄철에는 기온이 빠르게 상승하 고, 여름철 이후에는 하강하며 겨울에는 영점 이하로 기온이 떨어지는 계절 변화의 주기적 특성을 나타낸 다. 기압은 여름철과 겨울철에 따라 달라지며 겨울철 은 남고 북저, 여름철은 서고동저형으로 패턴이 측정 되며 한국의 동쪽으로 위치하는 대관령은 겨울철은 고기압, 여름철은 저기압의 형태로 나타난다. 그림 3 은 취득한 풍속, 풍향, 현지 기압, 기온과 현지 기압과 기온을 식 (2)에 적용한 공기밀도를 나타낸다. 2.4 취득 데이터의 분석 표 3은 취득한 데이터의 통계적 분석표를 나타낸 다. Units는 데이터의 단위를 나타내고, Min은 최솟 값, Max는 최댓값, Difference는 최대값과 최솟값의 차이, Average는 평균, st.Dev는 표준편차를 나타낸 다. 취득한 데이터는 모두 하루 평균을 나타내며 하루 단위로 하루 단위로 구성하고 있다.
Ⅲ. 입력 변수의 사전처리 및 모델 구성
3.1 입력 변수의 사전 처리 모델을 학습할 때는 입력 변수들 간의 스케일이 심 하게 차이나는 문제를 피하기 위해 정규화를 적용할 필요가 있다. 모델의 학습 성능을 높이기 위해 각 입 력변수마다 정규화(Normalization)를 적용하여 입력 변수간의 최대 최소값을 0과 1로 통일하였다. 식(3)은 정규화를 나타낸다. m i n m ax m ax m i n m i n (3) 여기서
는 변수를 나타내며 m i n은 의 최솟값을 나타내고, m ax는 의 최댓값을 나타낸다. 3.2 모델 구성 본 논문에 구성된 모델은 Bidirectional LSTM과 CNN 알고리즘을 융합한 하이브리드 모델을 구성하였 다. Bidirectional LSTM 알고리즘은 양방향 LSTM 알 고리즘이며 LSTM 알고리즘은 RNN(:Recurrent neural network)에서 파생된 알고리즘으로 전체적인 계산 과정은 RNN 알고리즘과 비슷하다. RNN의 은 닉층과 다르게 LSTM 은닉층은 Input gate, Output gate, Foreget gate라는 세 가지 게이트로 구성하며, Input gate와 Output gate는 은닉층의 입력과 출력을 담당하며, Forget gate는 과거 값이 현재 예측에 영향 을 미치지 않는다고 판단되면 0값으로 잊혀버리는 역 할을 한다. 그림4는 LSTM 알고리즘의 기본 구조를 나타낸다.그림 3. 취득한 데이터의 그래프 Fig. 3 Graph of acquired data
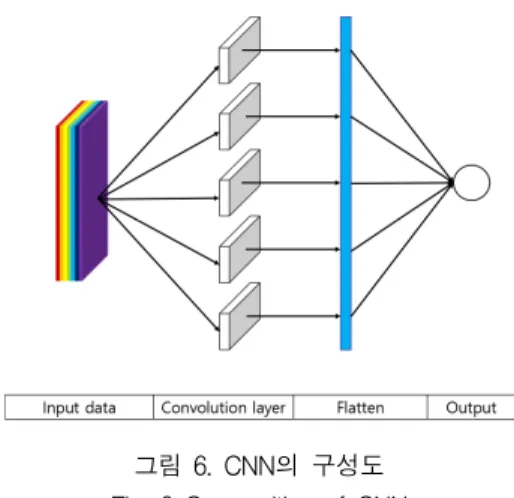
그림 4. LSTM 알고리즘의 구성도 Fig. 4 Construction diagram of LSTM algorithm LSTM 알고리즘은 입력 순서를 시계열 방향으로 처리하기 때문에 시계열의 정방향 의존성이 매우 높 은 경향을 보이는 한계가 있다. 이러한 한계점을 해결 하기 위해 Bidirectional LSTM을 사용한다. Bidirectional LSTM은 정방향(Forward)으로 계산하 는 LSTM 계산 순서를 역방향(Backward) 계산을 추 가하여 정방향 의존성을 억제시킨다. 그림 5는 Bidirectional LSTM의 구성도를 나타낸다. 그림 5. Bidirectional LSTM의 구성도 Fig. 5 Composition of Bidirectional LSTM CNN 알고리즘은 2차원 데이터의 훈련이 용이하고 적은 매개변수라는 장점이 있으며, 연결선의 가중치와 편차항은 MLP(Multi layer perceptron)와 유사한 계 산 과정을 거친다. 그림 6는 CNN의 구성도를 나타낸 다. 그림 6. CNN의 구성도 Fig. 6 Composition of CNN CNN은 다수의 층으로 구성된 특징을 추출하는 부 분과 추출된 특징을 사용하여 예측하는 작업을 담당 하는 부분으로 구성된다. 특징을 추출하는 역할을 하 는 부분에서는 컨볼루션 연산이 수행된다. 그 후 추출 된 특징을 MLP 등의 알고리즘을 사용하여 연산을 수 행한다. 본 연구는 풍력, 풍향, 공기밀도를 입력변수로 사용 하여 풍력발전량을 예측하였으며 Bidirectional LSTM 과 CNN 알고리즘으로 구성하여 하이브리드 모델을 구현하였다. 각 알고리즘의 은닉층은 2개의 층으로 구 성하였고 각 층마다 20개의 노드를 구성하였다. 마지 막 출력 값은 0보다 작은 값은 0으로 치환하기 위해 Relu 함수를 적용하였다. 그림 7은 본 논문에 사용된 모델의 구성도를 나타낸다. 그림 7. 하이브리드 모델의 구성도 Fig. 7 The composition of hybrid model
모델의 성능 비교를 위해 MLP 알고리즘으로 구성 된 모델을 구현하였다. 그림 8은 MLP 모델의 구성도 를 나타낸다.
그림 8. MLP 모델의 구성도 Fig. 8 The composition of MLP model
MLP 모델은 은닉층을 2개의 층으로 구성하였고 각 층마다 20개의 노드를 구성하였다. 또한 과적합을 피하기 위해 각 은닉층마다 40% 의 Drop-out을 적용 하였으며, 마지막 출력 값은 Relu 함수를 적용하였다. 본 논문은 대관령 풍력발전 단지의 일일 평균 풍력 발전량을 예측하기 위해 일 평균 풍력발전량과 기상 데이터를 csv 파일로 취득하였다. 모델의 학습 성능 을 높이기 위해 입력 변수를 정규화 하였으며, 예측 성능을 평가하기 위해 학습, 시험 데이터를 7:3으로 분리하였다. 그림 9는 풍력 발전량의 학습, 시험 데이 터를 나타내며 파란색 그래프는 학습 그래프를 나타 내고, 주황색 그래프는 시험 데이터를 나타낸다. 그림 9. 풍력 발전량의 학습, 시험 데이터 Fig. 9 Learning, test data of wind power generation
오차를 측정하기 위해 RMSE(:Root Mean Square Error)와 MAPE(:Mean Absolute Percentage Error)를 사용한다. 식(4-5)는 RMSE와 MAPE를 나타낸다. R MSE
MAPE
(4) (5) 여기서 은 자료의 수, 는 실측값, 는 예측값 을 의미한다.Ⅳ. 예측 결과
모델의 성능을 평가하기 위해 본 논문에 제시한 하 이브리드 모델을 MLP(Multi layer perceptron) 모델 과 비교하였다. 표 4는 시험 데이터로 예측한 하이브 리드 모델과 MLP 모델의 RMSE(Root mean square error)와 MAPE(Mean absolute percentage error)를 나타낸다.MLP Hybrid
RMSE 9.543 8.706
MAPE 6.158 5.487
표 4. 하이브리드 모델과 MLP 모델의 오차 비교 Table 4. Comparison of error between hybrid model
and MLP model 예측 결과 하이브리드 모델은 RMSE는 8.706이고, MAE는 5.487로 측정되었다. MLP 모델에 비해 RMSE는 0.837, MAE는 0.671만큼 오차가 낮게 측정 되어 예측 성능이 MLP 모델 보다 뛰어나다는 것을 알 수 있다. 그림 10은 학습 데이터의 예측값과 풍력 발전량을 나타낸다. 파란색 그래프는 모델의 예측값을 나타내 고, 빨간색 그래프는 풍력 발전량을 나타낸다.
그림 10. 학습 데이터의 예측값과 풍력 발전량 Fig. 10 Prediction of learning data and wind power
generation
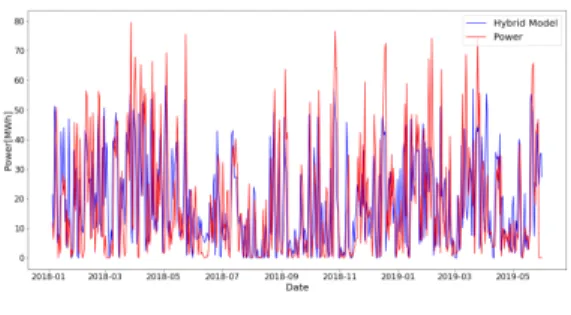
그림 11은 시험 데이터의 예측값과 풍력 발전량을 나타낸다. 파란색 그래프는 모델의 예측값을 나타내 고, 빨간색 그래프는 풍력 발전량을 나타낸다.
그림 11. 시험 데이터의 예측값과 풍력 발전량 Fig. 11 Prediction of test data and wind power
generation 그림 12는 시험 데이터의 하이브리드 모델과 MLP 모델의 예측 그래프를 나타낸다. 파란색 그래프는 하 이브리드 모델의 예측값, 빨간색 그래프는 MLP 모델 의 예측값을 나타낸다. 그림 12. 하이브리드 모델과 MLP 모델의 시험 데이터 예측값
Fig. 12 Test data prediction of hybrid model and MLP model
Ⅴ. 결론
본 논문은 물리적 접근법과 통계적 접근법을 결합 하여 풍력 발전량 예측을 제시한다. 풍력 발전의 요인 들을 분석하고 변수들을 선정하고, 선정된 변수들의 과거 데이터를 수집하여 딥러닝을 이용해 풍력 발전 량을 예측하였다. 사용된 모델은 Bidirectional LSTM 과 CNN 알고리즘을 결합한 하이브리드 모델을 구성 하였으며 예측 성능 비교를 위해 MLP 알고리즘으로 이루어진 모델과 오차를 비교하였다. 예측 결과 하이 브리드 모델은 RMSE는 8.706이고, MAE는 5.487로 측정되었으며, MLP 모델에 비해 RMSE는 RMSE는 0.837, MAE는 0.671만큼 오차가 낮게 측정 되어 하이 브리드 모델의 예측 성능이 더 뛰어났다.References
[1] Y. Lee, H. Kim, Y. Park, S. Park, J. Park, and Y. Kang, “Direction for the Mid- and Long-Term Development for Expanding Renewable Energy and Responding to Future Environmental Changes: Current Status and Direction of Onshore Wind Power,” Korea
environment institute report, 2020, pp. 1-101.
[2] Z. Dongmei, Z. Yuchen, and Z. Xu, "Research on wind power forecasting in wind farms,"
2011 IEEE Power Engineering and Automation Conference. vol. 13, no. 5, 2011.
[3] X. Wang, P. Guo, and X Huang, "A review of wind power forecasting models," Energy
procedia 12, 2011, pp. 770-778.
[4] M. Lange and U. Focken, "New developments in wind energy forecasting," IEEE power and
energy society general meeting-conversion and delivery of electrical energy in the 21st century,
vol. 13, no. 2, 2008, pp. 1-8.
[5] G. Giebel, R. Brownsword, G. Kariniotakis, M. Denhard, and C. Draxl, “The state-of-the-art in short-term prediction of wind power: A
literature overview,” ANEMOS. plus, 2011.
of the wind power prediction system using ordinary kriging,” J. Korean institute of illuminating and electrical installation engineers, vol.
30, no. 7, 2016, pp. 60-68.
[7] N. Son, Y. Kim, S. Kim, and D. Ahn, “ Study of Multi-variate Short-term wind power forecasting model based on SVR,” J. Korean
institute of next generation computing, vol. 13, no.
1, 2017, pp. 54-64.
[8] H. Byun, J. Ryu, and D. Kim, “The study of the wind resource and energy yield assessment for the wind park development,”
The Korean society for new and renewable energy,
vol. 1, no. 2, 2005, pp. 19-25.
[9] S. Pal and S. Mitra, "Multilayer perceptron, fuzzy sets, classifiaction," Transactions on
neural networks. IEEE, vol. 3, 1992, pp.
683-697.
[10] N. Srivastava, G. Hinton, and A. Krizhevsky “Dropout: a simple way to prevent neural networks from overfitting,” The Journal of
Machine Learning Research, vol. 15, no. 1, 2014,
pp. 1929-1958.
저자 소개
최정곤(Jeong-Gon Choi)
1996년 한양대학교 전기공학과 (공학사) 2013년 한양대학교대학원 전기공 학과 (공학석사) 1995년~2001년 한국전력공사 2001년~현재 한국전력거래소 정보기술처 ※ 관심분야 : AI and Machine Learning, Policy etc.최효상(Hyo Sang Choi)
1989년 전북대학교 전기공학과 (공학사) 1994년 전북대학교대학원 전기공 학과 (공학석사) 2000년 전북대학교대학원 전기공학과 (공학박사) 현재 조선대학교 전기공학과 교수