학 술 논 문
61
선형-비선형 특징추출에 의한
비정상 심전도 신호의 랜덤포레스트 기반 분류
김혜진·김병남·장원석·유선국
연세대학교 의과대학 의학공학교실
Random Forest based Abnormal ECG Dichotomization using Linear and Nonlinear Feature Extraction
Hye-Jin Kim, Byeong-Nam Kim, Won-Seuk Jang and Sun K. Yoo
Department of Medical Engineering, Yonsei University College of Medicine (Manuscript received 15 October 2015; revised 22 March 2016; accepted 23 March 2016)
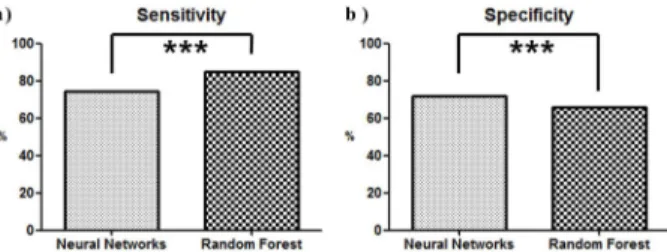
Abstract: This paper presented a method for random forest based the arrhythmia classification using both heart rate (HR) and heart rate variability (HRV) features. We analyzed the MIT-BIH arrhythmia database which contains half- hour ECG recorded from 48 subjects. This study included not only the linear features but also non-linear features for the improvement of classification performance. We classified abnormal ECG using mean_NN (mean of heart rate), SD1/SD2 (geometrical feature of poincare HRV plot), SE (spectral entropy), pNN100 (percentage of a heart rate longer than 100 ms) affecting accurate classification among combined of linear and nonlinear features. We compared our proposed method with Neural Networks to evaluate the accuracy of the algorithm. When we used the features extracted from the HRV as an input variable for classifier, random forest used only the most contributed variable for classification unlike the neural networks. The characteristics of random forest enable the dimensionality reduction of the input variables, increase a efficiency of classifier and can be obtained faster, 11.1% higher accuracy than the neural networks.
Key words: Electrocardiogram (ECG), Linear feature, Nonlinear feature, Spectral Entropy, Dichotomization
I. 서 론
우리나라의 3대 주요 사망 원인중의 하나는 심장 질환이 다. 심장 질환에 의한 사망률이 증가함에 따라 심장질환에 대한 연구를 비롯하여 진단의 정확성을 높일 수 있는 알고 리즘 개발이 필요하다. 심장질환 중에서도 두드러지게 나타 나는 원인은 부정맥으로 심장 박동이 정상보다 빠르거나 느 려 규칙적이지 않은 상태이다. 이러한 심장질환을 진단하는 방법으로 심전도가 사용된다. 심전도는 심장의 전기적 활동
을 측정하는 것으로 비정상적인 리듬을 측정하고 진단하는 가장 좋은 방법이다. 심전도 신호에서 획득한 심박수변이도 는 심장질환을 예측하는데 좋은 지표가 되기 때문에 부정맥 을 진단하는 방법으로 이용되고 있다[1].
심장관련 질환을 자동적으로 진단하기 위한 방법으로 퍼 지이론이나 신경망, SVM 등의 분류기가 주로 사용되었다 [2,3]. 이전에는 시간 영역 분석 방법과 주파수 영역 분석 방 법을 사용하여 선형분석을 이용하여 연구가 진행되었다[4- 6]. 하지만 심혈관계는 선형적으로 표현하기에는 너무 복잡 하므로 비선형 분석 방법이 유용할 것으로 제안되었고, Owis 가 심전도 신호를 이용한 부정맥 검출을 위해 비선형 분석 방법이 의미가 있음을 밝혀냈다[7,8].
본 논문에서는 부정맥을 검출하기 위하여 심박수변이도를 사용하였고 기존의 선형 분석 방법과 비선형 분석 방법을
Corresponding Author : Sun K. YooDepartment of Medical Engineering, Yonsei University College of Medicine
TEL: +82-2228-1919, E-mail : [email protected]
본 연구는 연세대학교 의과대학 교내연구비(6-2014-0010) 의 지원 에 의하여 이루어진 연구로서, 관계부처에 감사드립니다.
62
이용하여 특징을 추출하였다. 선행 연구에서 사용된 신경망 이나 SVM을 이용한 분류기는 변수 선정 과정을 거치지 않 아 최적화된 분류 모델이라 하기 어려우며, 데이터의 수가 많아지면 학습 시간이 길어진다는 단점이 있다[9]. 특히나 신경망의 경우 트레이닝데이터에 과대적합(Overfitting) 되 거나 분류 결과 지역 최소점에 빠질 수 있으며, 분류 과정 을 알 수 없어 결과 해석이 불가하다[10]. 반면, 랜덤포레스 트는 기존의 분류기와 달리 정확도에 영향을 미치는 변수를 평가하여 중요도가 높은 입력 변수를 선택적으로 사용함으 로써, 모든 변수들을 사용하는 분류기보다 학습 속도가 빨 라 분류 과정이 효율적이다[11]. 분류 정확도에 부정적인 영 향을 미치는 입력변수는 분류과정에서 제외되므로 상대적으 로 높은 분류 정확도를 가지게 된다. 따라서 본 논문에서는 랜덤포레스트를 사용하여 부정맥 분류기의 정확도를 향상시 키는 것을 목적으로 한다.
II. 연구 방법
1. 신호 전처리
부정맥 분류기의 성능평가를 위해 MIT-BIH 부정맥 데 이터베이스를 사용하였다. MIT-BIH 부정맥 데이터베이스 는 Beth Israel 병원의 부정맥 연구소에서 1975년과 1979 년 사이에 수행한 연구로부터 얻어진 4,000개 이상의 장시 간 홀터 기록이다[12]. 이 중 임의로 선택된 23명의 기록과 임상적으로 중요한 증상을 가진 25명의 기록을 포함하여 총 48명 피험자의 데이터베이스를 구성하였다.
심박수변이도를 이용한 비선형 특징을 추출하기 위해서 R 피크(peak) 값을 정확히 추출하는 것이 중요하다. Pan과 Tompkins 가 개발한 실시간 QRS 검출 알고리즘을 이용하 여 R피크를 검출한 후, R-R 간격이 32개 포함된 심박수변 이도 구간을 만들었다[13]. 한 사람당 적게는 40개, 많게는 100개 이상의 구간을 가지고 있으며 모든 구간의 수는 총 3,420 개이다. 정상 심전도의 R-peak 지점은 모두 검출하였 으나 전체 심전도 중에서 15% 에 해당하는 부정맥 심전도 는 정확한 검출이 되지 않아 MIT-BIH에서 제공하는 Annotation 을 참고하여 R-peak 지점을 검출하였다.
2. 선형 분석 방법을 이용한 특징 추출
32 개의 R-R간격으로 이루어진 심박수변이도 구간으로부 터 선형 분석 방법을 이용하여 부정맥을 분류하기 위한 특 징을 추출하였다. mean_NN은 R-R 간격의 평균값으로 심 박동의 정도를 나타낸다. SDNN은 전체 R-R 간격의 표준 편차를 나타낸다. SDNN의 감소는 좌심실의 이상과 관련이 있고, 좌심실 빈맥이나 갑작스러운 심정지 등을 예측할 수 있다[14]. RMSSD는 단기간의 심박변이를 나타내며 스트
레스와 같은 질환과 연관되어 값이 커지면 부교감신경의 활 동이 활성화되었다는 것을 의미한다[15]. SDSD는 R-R 간격 차이의 표준편차를 나타낸다. NN5, NN10, NN50, NN100 은 연속적인 R-R 간격의 쌍이 각각 5 ms, 10 ms, 50 ms, 100 ms 이상 차이가 나는 것을 말한다[16]. pNN5, pNN10, pNN50, pNN100 은 전체의 R-R 간격에 대해 NN5, NN10, NN50, NN100 값들의 비율(%)이며 값이 작을수록 건강한 상태를 의미한다.
3. 비선형 분석 방법을 이용한 특징 추출
심박수변이도의 비선형 분석 방법으로 스펙트럼 엔트로피 와 푸앵카레 그래프를 이용하였다. 스펙트럼 엔트로피는 심 박수변이도와 같이 예측하기 어려운 시계열 신호를 정량화 하기 위해 사용되는 분석 방법이다[17]. 스펙트럼 엔트로피 값은 먼저 푸리에 변환 후 스펙트럼 파워를 계산한다. 모든 주파수에 대해 정규화 한 뒤, 식 1을 이용하여 스펙트럼에 대한 확률 밀도 함수 값을 추정한다[18].
(1)
여기서 p
i는 주파수 f
i에 상응하는 확률 밀도함수이며, S(f
k) 는 같은 주파수 요소에 대한 스펙트럼 에너지이다. 그 리고 n은 FFT의 주파수 성분 총 개수이다. 스펙트럼 엔트 로피의 정의는 식 2와 같다.
(2)
다음으로, 푸앵카레 그래프를 통하여 심박수변이도의 비 선형 특징을 추출하였다. 푸앵카레 그래프는 연속적인 R-R 간격의 상관관계를 그래프로 표현하는 방법이다. 푸앵카레 그래프에서 x축은 n번째의 R-R간격인 RR
n값이며, y축은 n+1 번째의 R-R간격인 RR
n+1값, SD1과 SD2는 푸앵카레 타원에서 얻을 수 있는 파라미터이다[19]. SD1은 y = −x로 투영시킨 직선의 표준편차이고 SD2는 y = x로 투영시킨 직 선의 표준편차이다. SD1은 식 3으로 인접한 R-R 간격 차 이의 표준편차인 SDSD 값을 이용해서 계산하였고, SD2는 R-R 간격의 표준편차인 SDNN과 SDSD 값으로 계산하여 식 4와 같다[20]. 이때 p1과 p2는 식 5로부터 구할 수 있다.
(3)
(4) p
iS f ( ) S f
i( )
kk 1=
∑
nfor 1 i n ≤ ≤
=
H p
ii 1=