제31회 한글 및 한국어 정보처리 학술대회 논문집 (2019년)
Sentence BERT 임베딩을 이용한 과편향 뉴스 판별
임정우◦1, 황태선1, 오동석2, 양기수1, 임희석1 고려대학교 컴퓨터학과1
Human-inspired 복합지능연구센터2
[email protected] ,{hts920928,inow3555,willow,limhseok}@korea.ac.kr
Hypernews Detection using Sentence BERT Embedding
Jungwoo Lim◦1, Taesun Whang1, Dongsuk Oh2, Kisu Yang1, Heuiseok Lim1 Computer Science and Engineering, Korea University1
Human-inspired AI & Computing Research Center2 요 약
과편향 뉴스 판별(hyperpartisan news detection)은 뉴스 기사가 특정 인물 또는 정당에 편향되었는지 판단하는 task 이다. 이를 위해 feature-based ELMo + CNN 모델이 제안되었으나, 이는 문서 임베딩이 아닌 단어 임베딩의 평균 을 사용한다는 한계가 존재한다. 따라서 본 논문에서는 feature-based 접근법을 따르며 Sentence-BERT(SentBERT) 의 문서 임베딩을 이용한 feature-based SentBERT 기반의 과편향 뉴스 판별 모델을 제안한다. 제안 모델의 효과를 입증하기 위해 ELMO, BERT, SBERT와 CNN, BiLSTM을 적용한 비교 실험을 진행하였고, 기존 state-of-the-art 모델보다 f1-score 기준 1.3%p 높은 성능을 보였다.
주제어: 과편향 뉴스 판별, Sentence BERT, 문장 임베딩
1. 서론
과편향 (hyperpartisan) 뉴스는 주어진 기사 내용이 비논리 적이거나, 특정한 사람이나 정당에 편향되어 있는 뉴스이다.
최근 가짜 뉴스, 과편향 뉴스들이 폭발적으로 증가함에 따라, 뉴스를 접하는 대중들이 균형된 시각을 가지기 어려워졌고 이 러한 뉴스에 대한 자동 분류의 필요성이 증가하였다 [1]. 따 라서 자연어 처리 분야 내에서는 가짜뉴스, 과편향 뉴스를 분 류하려는 연구가 활발히 진행되고 있으며, knowledge-based 방식[2, 3, 4]과 style-based 방식[5] 등의 다양한 연구들이 제 안되었다. 기존의 다양한 연구들의 경우 딥러닝을 기반으로 한 방법[6]이 부족하였으나, 최근 SemEval 2019 Shared Task 41 [7]에서 과편향 뉴스 분류에 대한 task가 shared task로 진행 되면서 다양한 딥러닝 기반의 모델들이 제안되었다. 본 task에 참가한 총 42팀 중 가장 좋은 성능을 기록했던 Jiang et al. [8]의 연구의 경우, pre-trained된 ELMo를 통해 얻은 기사의 각 문장 임베딩을 CNN의 입력으로 넣어 모델을 구성하여 좋은 성능을 보여주었다. 그 뒤를 이은 Hanawa et al. [9]의 경우, BERT 임베딩을 포함한 여러 feature들을 생성하여 선형 분류 모델을 구성하였다. 최근 OpenAI GPT [10], BERT [11]와 같은 문맥 정보를 이해한 언어 모델들이 등장하면서 question answering, sentence classification 등의 task에 대해 좋은 성능을 거두고 있음에 따라 해당 모델들을 이용한 연구들 또한 진행되었으나, 괄목할 만한 성과를 내지 못하였다 [12, 13].
문맥 정보를 이해하는 pre-trained된 언어 모델 representa- tion을 적용하는 방식은 대부분 feature-based, fine-tuning 두
1https://pan.webis.de/semeval19/semeval19-web/
가지로 분류된다 [11]. 과편향 판별 task에서 좋은 성능을 낸 모델들은 fine-tuning 방식이 아닌 feature-based 방법을 기반 으로 한 모델들이 대부분이었다. 그 이유는 task에서 주어진 기사의 길이가 길어, feature-based 방식으로는 담을 수 있는 정보를 fine-tuning 방식으로는 담을 수 없었던 이유라고 분석 된다. 이러한 실험적 근거로, BERT 를 fine-tuning하는 방식이 아니라 feature-based 방식으로 사용하는 것이 해당 task에 더 적합할 수도 있다고 상정했다.
BERT의 문장 임베딩을 feature-based 방식으로 이용한 연구 와 실험은 이전에도 존재하였는데, 대부분 BERT output layer 의 값들을 평균 내거나 [CLS] token 만을 이용하여 고정된 사 이즈의 문장 임베딩을 추출하는 방법들을 사용했다 [14, 15, 9].
하지만 feature-based BERT 임베딩의 경우 문장을 표현하는 데에 많은 한계가 존재하였으며, 과편향 판별 task에서 좋은 성 능을 보이지 못하였다. 이러한 한계를 극복하기 위해, 본 연구에 서는 BERT를 feature-based 방식으로 사용 가능한 SentBERT [16] 모델을 통해 뉴스 기사의 문장 임베딩을 구성하였고, con- volutional neural networks (CNN)과 bidirectional long short term memory (BiLSTM) 분류기를 통해 학습을 진행하였다.
2. 모델
본 연구에서는 기존의 BERT 임베딩 대신, pre-trained BERT로부터 의미적으로 유의한 문장 임베딩을 추출할 수 있도 록 수정된 모델인 SentBERT 를 사용한다. SentBERT를 통해 추출된 문장 임베딩은 코사인 유사도를 통해 비교가 가능하 다[16]. 이 모델은 고정된 사이즈의 문장 임베딩을 얻기 위해 다음과 같이 학습된다. 먼저 BERT output 벡터의 평균값을
- 388 -
제31회 한글 및 한국어 정보처리 학술대회 논문집 (2019년)
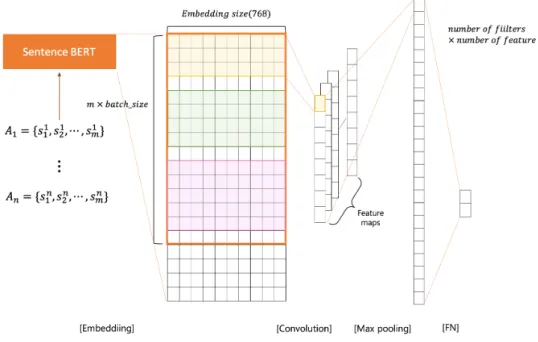
그림 1. SentBERT + CNN 모델 구조
구한 뒤, 생성된 문장 임베딩의 의미적 유의성을 코사인 유사 도로 계산한 후, 그에 따라 siamese network 혹은 triplet net- work가 임베딩의 weight를 업데이트 시킨다. 이에 따라 산출된 임베딩은 기존의 BERT 임베딩과 다르게 의미적으로 유사한 문장들은 벡터 스페이스 안에서 그 거리가 가까워지게 되고, 기존의 BERT 임베딩보다 의미적 정보를 잘 담을 수 있는 장 점이 있다.
본 연구에서는 pre-trained 된 SentBERT 를 사용하여 위의 임베딩을 추출하였고 CNN 분류기의 input으로 설정하였다.
input의 기사는 An= {sn1, sn2, · · ·snm} 으로 표현되며 n은 기사 의 개수, m은 최대 문장 개수이다. 각 배치별로 기사들이 각각 다른 문장 개수를 가지고 있으므로 문장이 가장 많은 기사를 기준으로 나머지 기사들을 padding 처리 해주었다. CNN 모 델은 필터 크기 [3, 4, 5]로 설정하였으며, 각 필터의 차원수는 768로 동일하다. optizer는 Adam optimizer를 사용하였으며, learning rate은 3e-5이다. 또한 loss function으로는 weighted cross-entropy loss를 썼고, dropout은 0.2로 설정하였다. 모델 의 구조는 다음 그림1에서 참고할 수 있다.
3. 실험
3.1 데이터 셋
2019년 SemEval Shared Task 4에서는 by-article 데이터를 xml형태로 학습 데이터 셋만 제공하였다. 평가 데이터 셋은 현재 제공하고 있지 않아 평가 데이터 셋을 학습 셋의 일부를 사용하여 만들었다. 또한, 과편향 뉴스와 비 과편향 뉴스의 비 율이 일정하도록 학습과 평가 셋을 재구성하였다. 최종적으로 기존에 공개된 645개의 데이터 셋 중 학습 셋은 총 432개, 평가
셋은 총 213개로 구성하였다.
3.2 데이터 전처리
본 연구의 데이터는 한 뉴스 기사에 여러 문장이 들어가 있는 형태이기에 CNN의 입력으로 들어갈 수 있도록 따로 전처리를 진행하였다. 먼저 기사 내의 각각 문장들을 Sentence BERT 에 입력하여 768차원인 각각의 문장 임베딩을 추출하였다. 그 다음, 추출된 임베딩을 다시 뉴스 기사 별로 묶어 기사 하나당 여러 개의 문장 임베딩 시퀀스를 가지도록 구성하였다.
3.3 실험 결과
본 연구는 따로 평가 셋을 제공하지 않는 워크샵 특성상, by-article 의 트레이닝 데이터로 실험을 진행하였으며, 임의로 학습 데이터와 평가 데이터 셋을 분리하였다. 해당 데이터로 실험을 진행한 결과는 표 1과 같다.
Model Acc. Prec. Recall F1 BERT BiLSTM 0.658 0.645 0.647 0.646
CNN 0.629 0.627 0.633 0.630 ELMo BiLSTM 0.798 0.788 0.780 0.784 CNN [8] 0.806 0.801 0.775 0.788 SentBERT BiLSTM 0.810 0.797 0.802 0.800 CNN 0.810 0.797 0.805 0.801 표 1. BERT, ELMO, SentBERT의 성능 평가 결과. 모든 결과 는 10번의 실험결과를 평균 낸 것임
표 1에서 볼 수 있듯이, BERT 임베딩을 feature-based 방식 으로 이용하게 된다면 분류기에 상관없이 다른 모델들에 비해
- 389 -
제31회 한글 및 한국어 정보처리 학술대회 논문집 (2019년)
매우 성능이 떨어진다. 기존의 제일 좋은 성능을 보였던 ELMo + CNN 모델은 본 연구에서 자체적으로 구현 및 평가를 진행 하였으며, 실제로 본 연구의 데이터 셋을 적용하여 실험한 결과 기존 연구에서 제시한 성능과 유사한 성능을 보였다. ELMo 임 베딩과 CNN, BiLSTM 분류기를 사용한 모델들이 약 79.8%, 80.6%의 정확도 (accuracy)를 보인 반면, SentBERT는 두 분류 기에 대하여 81%라는 가장 높은 정확도를 기록하였다. 이같은 결과는 기존의 feature-based로 사용하기 힘든 BERT 임베딩을 SentBERT 임베딩으로 대체하게 된다면, 기존의 ELMo 임베 딩을 사용한 모델들보다 더 좋은 성과를 낼 수 있다는 점을 보여준다.
4. 결론
본 연구는 과편향 뉴스 판별 task를 feature-based 접근법으 로 해결하기 위해, SentBERT 임베딩을 사용하였다. 제안 모 델의 효과를 입증하기 위해 ELMO, BERT, SBERT와 CNN, BiLSTM을 적용한 비교 실험을 진행하였고, 기존 state-of-the- art 모델보다 f1-score 기준 1.3%p 높은 성능을 보였다. 본 연구 에서 제안하는 모델은 과편향 뉴스 판별 task 에서 좋은 성능을 보인 모델들의 양상을 분석 후, SentBERT라는 feature-based 방식을 적용한 결과라고 할 수 있다. 향후 제안된 모델을 CNN, LSTM 이외의 다른 분류 모델을 사용하게 된다면 더 좋은 성 능을 낼 수 있을 것이다.
5. 감사의 글
본 연구는 과학기술정보통신부 및 정보통신기술진흥센터의 대학ICT연구센터지원사업의 연구결과로 수행되었음 (IITP- 2018-0-01405). 이 논문은 2017년도 정부(미래창조과학부) 의 재원으로 한국연구재단의 지원을 받아 수행된 연구임 (No.NRF-2017M3C4A7068189).
참고문헌
[1] K. Shu, A. Sliva, S. Wang, J. Tang, and H. Liu, “Fake news detection on social media: A data mining perspec- tive,” ACM SIGKDD Explorations Newsletter, Vol. 19, No. 1, pp. 22–36, 2017.
[2] Y. Wu, P. K. Agarwal, C. Li, J. Yang, and C. Yu, “To- ward computational fact-checking,” Proceedings of the VLDB Endowment, Vol. 7, No. 7, pp. 589–600, 2014.
[3] B. Shi and T. Weninger, “Fact checking in heteroge- neous information networks,” Proceedings of the 25th International Conference Companion on World Wide Web, pp. 101–102, 2016.
[4] N. Lee, C.-S. Wu, and P. Fung, “Improving large-scale fact-checking using decomposable attention models and
lexical tagging,” Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp.
1133–1138, 2018.
[5] W. Y. Wang, “” liar, liar pants on fire”: A new bench- mark dataset for fake news detection,” arXiv preprint arXiv:1705.00648, 2017.
[6] B. D. Horne and S. Adali, “This just in: Fake news packs a lot in title, uses simpler, repetitive content in text body, more similar to satire than real news,” Eleventh International AAAI Conference on Web and Social Me- dia, 2017.
[7] J. Kiesel, M. Mestre, R. Shukla, E. Vincent, P. Adineh, D. Corney, B. Stein, and M. Potthast, “SemEval-2019 task 4: Hyperpartisan news detection,” Proceedings of the 13th International Workshop on Semantic Evalua- tion, pp. 829–839, 2019.
[8] Y. Jiang, J. Petrak, X. Song, K. Bontcheva, and D. May- nard, “Team bertha von suttner at semeval-2019 task 4:
Hyperpartisan news detection using elmo sentence rep- resentation convolutional network,” Proceedings of the 13th International Workshop on Semantic Evaluation, pp. 840–844, 2019.
[9] K. Hanawa, S. Sasaki, H. Ouchi, J. Suzuki, and K. Inui,
“The sally smedley hyperpartisan news detector at SemEval-2019 task 4,” Proceedings of the 13th Inter- national Workshop on Semantic Evaluation, pp. 1057–
1061, 2019.
[10] A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training.”
[11] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova,
“Bert: Pre-training of deep bidirectional transform- ers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
[12] N. Lee, Z. Liu, and P. Fung, “Team yeon-zi at semeval- 2019 task 4: Hyperpartisan news detection by de-noising weakly-labeled data,” Proceedings of the 13th Interna- tional Workshop on Semantic Evaluation, pp. 1052–
1056, 2019.
[13] Z. Ning, Y. Lin, and R. Zhong, “Team peter-parker at SemEval-2019 task 4: BERT-based method in hyperpartisan news detection,” Proceedings of the 13th International Workshop on Semantic Evaluation,
- 390 -
제31회 한글 및 한국어 정보처리 학술대회 논문집 (2019년)
pp. 1037–1040, Jun. 2019. [Online]. Available: https:
//www.aclweb.org/anthology/S19-2181
[14] H. A. M. Hassan, G. Sansonetti, F. Gasparetti, A. Mi- carelli, and J. Beel, “Bert, elmo, use and infersent sen- tence encoders: The panacea for research-paper recom- mendation?” 2019.
[15] D. Miller, “Leveraging bert for extractive text summa- rization on lectures,” arXiv preprint arXiv:1906.04165, 2019.
[16] N. Reimers and I. Gurevych, “Sentence-bert: Sen- tence embeddings using siamese bert-networks,” arXiv preprint arXiv:1908.10084, 2019.