논문 2016-53-9-12
자전거 교통 사고 현황 및 예측 분석
( Analysis and Prediction of Bicycle Traffic Accidents in Korea )
최 승 희*, 이 구 연**
( Seunghee Choi and Goo Yeon Lee
ⓒ)
요 약
국내의 자전거 이용 활성화 정책에 따라 자전거 노선 및 자전거 교통 인프라가 계속 확장되는 추세이다. 자전거 인구가 증 가함에 따라 해마다 자전거 교통사고도 증가하고 있다. 본 논문은 도로교통공단의 2007년부터 2014년까지의 자전거 교통사고 데이터를 분석하여 교통사고 현황에 대한 통계량을 제시하였다. 또한 기상청의 종관기상관측소 서울지점의 기상 정보를 활용 하여 서울지역의 일별 교통사고 발생 건수에 대한 회귀분석을 실시하였다. 그리고 의사결정 트리 분석 방법을 적용하여 교통 사고 정보의 교통사고 심각도를 분류 예측하였다. 이러한 기술 분석 및 예측 분석을 통해 향후 자전거 교통사고 예방을 위한 자전거 교통사고 데이터 수집 정책 및 사고 예방 대책 수립에 도움이 되고자 한다.
Abstract
According to the promoting policy for bicycle riding, the bicycle road infrastructure in Korea has been widely established. As the number of bicycle rider increases, bicycle traffic accidents also increase year after year. In this paper, we analyze bicycle traffic accident data from 2007 to 2014 which is provided by Road Traffic Authority and present statistical results of bicycle traffic accidents. And also regression analysis is applied to predict the number of daily traffic accidents in Seoul using ASOS(Automated Synoptic Observing System) climate data observed in the Seoul sector which are provided by Korea Meteorological Administration. In addition, decision tree analysis techniques are used to forecast the level of traffic accidents severity. In the analytic results of this research, we expect that it will be helpful to establish the collective policy of bicycle accident data and protective strategy in order to reduce the number of bicycle accidents.
Keywords : bicycle traffic accidents, bicycle, traffic accidents, descriptive analysis, predictive analysis
*
정회원, 강원대학교 컴퓨터정보통신공학과
(Department of Computer and Communications Engineering, Kangwon National University)
**
정회원, 강원대학교 컴퓨터정보통신공학과 교수 (Department of Computer and Communications Engineering, Kangwon National University)
ⓒ
Corresponding Author (E-mail : [email protected])
※ 이 논문은 2016년도 정부(미래창조과학부)의 재원 으로 정보통신기술진흥센터의 지원을 받아 수행된 연구임 (No.R0250-16-1002, SW융합 비즈니스 데이 터 분석 인력양성 사업)
Received ; March 2, 2016 Revised ; June 29, 2016 Accepted ; July 8, 2016
Ⅰ. 서 론
자전거 이용 활성화 정책에 따라 한국의 자전거 도로 노선 수는 2009년 4,647개소, 총 연장 11,387km에서 2014년 9,374개소, 19,717km로 각각 증가하였다[1]. 중앙
정부 및 여러 지방자치단체에서 지속적으로 자전거 교 통 인프라 및 관련 시설을 확충한 결과이며 향후에도 이런 추세는 계속될 전망이다.
그러나 이 같은 확장과 함께 자전거 교통사고 위험성 과 사망자 및 부상자도 같이 증가하고 있는 상황이다.
지난 5년간 자전거 승차 중 사망자는 1,466명으로 전체 교통사고 사망자의 5.7%를 차지했으며, 부상자는 58,775 명으로 전체 부상자의 3.4%를 차지한 것으로 나타났다.
특히 연령이 높을수록 자전거 승차 중 사망자의 구성비 가 크게 높아지고 있어 고령자에 대한 자전거 안전 교 육이 시급하다고 하겠다[2].
이렇듯이 일반 자동차 사고 및 이로 인한 사상자의 수에 비하여 자전거 사고 및 사상자의 수치는 무시할 수 없는 정도의 값을 보여주고 있으며, 이러한 수치는 시간이 지날수록 더욱 증가할 것으로 예상되고 있다.
그러므로 이를 방지하기 위한 체계적인 대책 및 연구가 필요한 상황으로, 현재 자전거 안전 승차 문화 확산, 자 동차와의 도로 공유 관련 규정 및 문화의 확립 등 다양 한 측면으로 여러 노력이 이루어지고 있다.
본 논문에서는 자전거 교통사고 예방의 방법으로 통 계적인 자전거 교통사고 데이터 분석에 초점을 맞추어 연구를 수행한다. 본 연구에서는 먼저 2007년부터 2014 년까지의 자전거 교통사고 데이터를 분석하여 교통사고 현황에 대한 통계량을 제시하고, 이어서 기계 학습 기 법 등을 적용하여 예측 분석 및 관련성 분석을 시도한다.
이를 통해 자전거 이용자의 안전 증진 및 사고 예방을 위한 제도 개선 방안 도출에 도움이 되도록 한다.
Ⅱ. 관련 연구
1. 데이터 분석 기법
가. 의사결정 트리
의사결정 트리(Decision tree)는 기계학습(Machine learning)의 대표적인 지도 학습(Supervised learning) 기법으로, 주어진 데이터를 분류(Classification)하기 위 한 목적으로 사용한다.
먼저 사전에 분류 값이 주어진 데이터 셋을 이용하여 의사결정 트리 모델을 생성한다. 그리고 생성한 의사결 정 트리 모델을 이용하여, 새롭게 분류하고자 하는 입 력 데이터에 대한 분류 예측을 실시할 수 있다.
나. 회귀 분석
회귀 분석(Regression analysis)은 독립변수와 종속 변수들 간의 관계성을 특정 함수의 형태로 표현하는 수 학적 모델링 방법이다. 데이터 분석 대상 데이터 셋으 로부터 함수적 회귀식을 생성하고, 이를 이용하여 종속 변수의 값을 예측할 수 있다. 로지스틱 회귀 분석(logistic regression Analysis)은 회귀 분석과는 다르게 종속 변 수가 범주형 데이터인 경우 적용 가능하다.
다. 컨퓨전 매트릭스
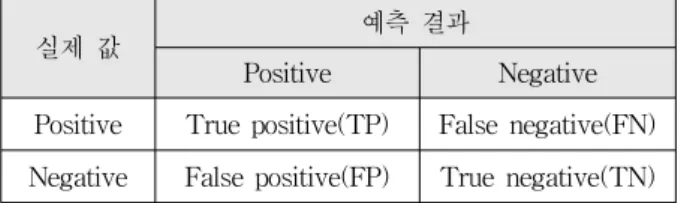
컨퓨전 매트릭스(Confusion matrix)는 표 1과 같이 분류 예측의 결과가 실제 값과 얼마나 잘 맞는지 성능 을 확인할 수 있는 교차분석표이다. 일반적으로 분류 값이 긍정(Positive)이거나 부정(Negative)인 경우의 이 진 예측의 경우를 설명한다.
실제 값 예측 결과
Positive Negative Positive True positive(TP) False negative(FN) Negative False positive(FP) True negative(TN)
표 1. 컨퓨전 매트릭스
Table1. The confusion matrix.
라. 평균 차이 검정
여러 집단 간에 차이가 있는지를 평균값을 이용하여 검정 하는 방법이다. 두 집단 간의 평균 차이 검정은 t-test를 이용하고, 세 개 이상의 집단 간의 검정은 분 산 분석(analysis of variance) 방법을 적용한다. 데이터 가 서로 다른 두 모집단을 가지는 경우에는 독립 표본 t-test를 실시하고, 하나의 모집단을 가지는 경우에는 paired t-test를 실시한다.
마. 카이제곱(Chi-Square) 검정
카이제곱 검정은 범주형 변수들 간의 연관성을 분석 하는 방법이다. 먼저 귀무가설을 토대로 기대 빈도를 계산한다. 그리고 대상 데이터 세트의 관찰 빈도가 통 계적으로 유의미한지를 분석한다. 카이제곱 검정 결과 에서 p값이 유의 수준보다 낮으면 귀무가설은 기각되 고, 반대로 유의 수준보다 높으면 귀무가설은 채택된다.
2. 자전거 교통사고 현황 분석
도로교통공단은 자전거사고 특성 분석을 중심으로 2014년판 교통사고 요인분석 단행본을 발간하여 자전거 교통사고 발생 요인별 상세한 분석 결과를 제시하고 있 다[2]. 또한 2013년 도로 형태별 분석 자료에 따르면 단 일로에서 교통사고가 56.4% 발생했으며, 교차로에서는 38.3%가 발생한 것으로 나타났으며, 도로 선형별로는 직선로에서 전체 자전거 사고의 91.7%가 발생해 가장 위험 비중이 높은 것으로 드러났다[3].
조현익은 부산광역시 자전거 사고 자료를 바탕으로 자전거 교통사고에 영향을 미치는 요인을 분석하고, 설 문조사를 통해 자전거 사고 영향 요인 및 자전거 이용 의 위험 요인을 분석하였다[4]. 또한 홍종선과 김명진은 자전거 사고 자료를 조건부 확률의 개념을 도입하여 통 계적으로 분석하고, 자전거 인구와 차종별 자동차 등록 대수 자료와 같이 분석하여 자전거 인구 대비 사고확률 그리고 자동차 등록 대비 사고 확률을 분석하였다[5].
항 목 설 명
관리번호 고유번호
발생지시군구 사고가 발생한 시군구 주소 발생 일시 사고 발생 년, 월, 일, 시
요일 사고 발생 요일
1당 정보*
차종, 성별, 나이, 인적 피해
차종 : 건설기계, 기타불명, 농기계, 보행자, 승용, 승합, 원동기, 이륜, 자전거, 특수, 화물
인적 피해 : 사망, 중상, 경상, 부상신고, 상해없음, 기타불명 2당 정보** 차종, 성별, 나이, 인적 피해
사고 유형 차대사람/차대차/차량단독/철길건널목, 충돌의 종류
법규 위반
과속, 교차로 운행방법 위반, 보행자 보호의 무 위반, 불법유턴, 신호위반, 안전거리 미 확보, 안전운전 불이행, 중앙선 침범, 직진 우회전 진행방해, 차로위반, 기타, 미분류 사망자 수 교통사고 발생시로부터 30일 이내에
사망한 사망자 수
중상자 수 교통사고로 인하여 3주 이상의 치료를 요하는 부상자 수
경상자 수 교통사고로 인하여 5일 이상 3주 미만의 치료를 요하는 부상자 수
부상신고자수 교통사고로 인하여 5일 미만의 치료를 요하는 부상자 수
주야 주간, 야간
기상상태 맑음, 안개, 흐림, 눈, 비, 기타
도로형태
교차로, 단일로, 미분류, 기타, 사고 위치(교 량, 교차로부근, 교차로안, 철길건널목, 터널, 횡단보도부근, 횡단보도상, 기타, 미분류) 사고 장소 사고 장소의 지명
사고 개요 사고 발생 상황에 대한 설명
3. 자전거 교통사고 예측 분석남창규는 전라남도 자전거 사고 자료를 사고 특성 분 석을 통해 자전거 사고 건수에 영향을 주는 변수를 선 정하여 사고예측모형을 개발하였고[6], 정석호는 산악자 전거 코스 정보와 산악자전거 라이더의 코스 난이도 정 보를 이용하여 산악자전거 사고 위험을 예측하기 위한 위험 모델 생성 방법을 제안하였다[7].
또한 조안 슐츠(Joan Schulz) 외는 센서 정보를 기반 으로 온톨로지(ontology)를 구축하여 이를 통해 자전거 사고를 예측하고 예방하기 위한 EWS 시스템을 제안하 였다[8].
기존 연구들은 특정 지역만의 제한된 교통사고 분석 을 시도하거나 전통적인 통계 기법만을 적용하여 현황 분석에만 머무르는 한계점을 보이고 있다. 본 논문에서 는 이러한 한계점을 극복하기 위하여 8년간의 자전거 교통사고 데이터를 활용하여 통계적 분석 이외의 기계 학습 알고리즘을 적용한 예측 분석을 시도하였다. 예측 분석 기법의 활용을 통해 향후 자전거 교통사고 발생 추세를 반영한 적절한 예방적 대응이 가능하기 때문이다.
Ⅲ. 자료 수집
1. 자전거 교통사고 데이터
본 논문의 데이터 분석 결과는 도로교통공단의 자전 거 교통사고 데이터를 토대로 작성되었다. 분석 대상 데이터는 2007년부터 2014년까지의 자전거 교통사고 데 이터로 총 98,369건의 도로교통공단 경찰DB 데이터이 다. 수집된 데이터의 속성 항목은 표 2와 같다.
표 2. 데이터 속성 항목
Table2. Data attributes table.
* 제1당사자 정보 : 당해 교통사고에 관계한 사람 가운데 과실이 가장 많은 사람
** 제2당사자 정보 : 사고관련자 중 당해사고와의 관련성이 제1당사자 다음으로 많은 사람
전국적으로 개별 자전거 교통사고 발생 건에 대하여 교통사고 발생 장소, 발생 시간, 교통사고 당사자 정보, 사망자 및 부상자 수, 도로 형태 및 법규 위반 정보 등 이 수집되어 구성되어 있다. 사상자 숫자를 제외하면 대부분 범주형 변수로 구성되어 있음을 알 수 있다.
2. 기상 정보 데이터
자전거 교통사고는 교통사고 당일의 기상 정보와 관 련성이 높을 것으로 판단되어 기상 정보를 수집하여 분 석하였다. 기상 정보는 기상청의 기상자료개방포털에서 제공하는 종관기상관측소 자료 중 2007년부터 2014년까 지의 자료를 활용하였다[9]. 종관기상관측소는 전국에 94 개소가 설치되어 운영되고 있으며, 수집된 데이터의 속 성 항목은 표 3과 같다.
표 3. 종관기상관측소 기상 정보
Table3. ASOS(Automated Synoptic Observing System) climate data.
항 목 설 명
지 점 관측소 지점 코드
일 시 기상 관측 년, 월, 일
평균기온 평균기온(°C)
일강수량 일강수량(mm)
평균 풍속 평균 풍속(m/s)
안개 계속시간 안개 계속시간(hr)
Item The first party The second party Value Rate Value Rate Male 73,246 79% 72,202 75%
Female 19,637 21% 24,631 25%
Sum 92,883 100% 96,833 100%
Ⅳ. 자전거 교통사고 현황 분석
1. 교통사고 발생 현황
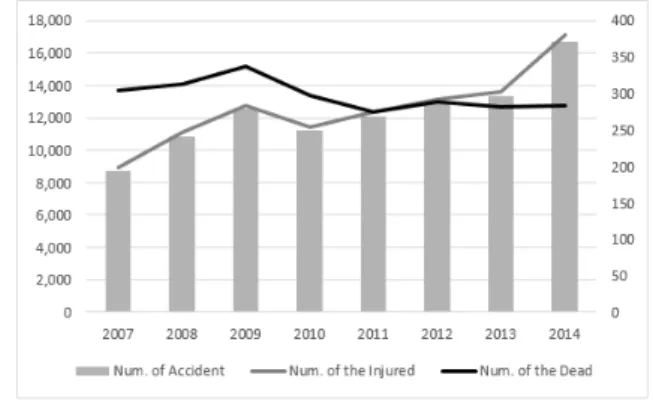
2007년부터 2014년까지 8년간 연도별 자전거 교통사 고 건수와 사망자 및 부상자 수*는 그림 1과 같으며, 전체 교통사고 누적 건수는 98,369건, 사망자 수 2,380 명, 부상자 수 100,446명이다.
그림 1. 연도별 교통사고 건수와 사망자 및 사상자 수 Fig. 1. The number of the accidents, the dead and the
injured.
자전거 교통사고 건수는 2007년 8,721건 대비 2014년 16,664건으로 두 배 가까이 증가했음을 알 수 있다. 다 행히 사망자 수는 약간 감소했으나 부상자 수가 8,887 명에서 17,133명으로 두 배 이상 증가한 것을 알 수 있다.
자전거 인구의 증가에 따라 교통사고 건수 및 사상자 수도 증가하는 추세로 이를 완화할 수 있는 실질적 대 책이 필요한 상황이다.
국가통계포털의 통계 정보에 따르면 2010년 기준 국 내의 자전거를 이용한 통근 및 통학 인구는 남성 326,777명, 여성 114,646명으로 각각 약 74%, 26%의 비 중을 차지하고 있다[10].
성별** 교통사고 비중을 1당사자 및 2당사자의 비율 로 살펴보면 표4와 같다. 자전거를 이용한 통근 및 통 학 인구에서의 성별 비중 추세를 반영하여 1당사자, 2 당사자 모두에서 남성이 75% 이상의 높은 비중을 차지 하고 있음을 알 수 있다.
표 4. 성별 비중
Table4. Rate by gender.
*부상자 수는 중상자 수, 경상자 수, 부상 신고자 수를 모두 합한 수치임
**확인되지 않은 성별 정보는 제외되었음
또한 지역별 교통사고 발생 건수를 오름차순 정렬하 여 표시하면 그림 2와 같다. 서울특별시 23,843건, 경기 도 16,065건으로 각각 1, 2위를 나타내고 있는데, 이는 전체 교통사고의 약 41%로 높은 비중을 차지한다. 지 역의 인구에 비례하여 많은 교통사고가 발생하고 있음 을 알 수 있으며, 특히 인구가 많은 서울특별시와 경기 도 지역의 자전거 교통사고 예방에 노력이 더욱 집중되 어야 할 것으로 생각된다.
그림 2. 지역별 교통사고 발생 건수 Fig. 2. The number of accidents by region.
2. 법규 위반 현황
자전거 교통사고 유발의 주요 원인이 교통 법규의 위 반이다. 법규 위반 내용을 법규 위반 건수가 많은 순서 대로 정렬하여 표시하면 그림 3과 같다.
그림 3. 교통 법규 위반 내용 Fig. 3. The status of traffic violations.
여러 가지 위반 내용 중에서 “안전운전불이행”이 67%나 차지하고 있어, 자전거 주행 시 반드시 안전 운 전할 수 있도록 사전 안내가 필요하다고 하겠다. 현재 수집된 데이터에서 “안전운전불이행”에 대한 세부 항목
은 확인할 수가 없어 추가 분석은 수행하지 못하였다.
향후 교통사고 데이터 수집 시 상세 위반 내용에 대한 정보 수집이 이루어진다면, 더욱 구체적인 교통사고 원 인 분석과 그에 따른 사전 예방 조치가 가능할 것이다.
안전 운전과 관련하여 초보 자전거 이용자는 자전거 안 전 운전 교육을 반드시 수강하고, 자전거 이용자 모두 가 안전모를 착용하는 등의 사전 예방 조치가 필요하다 고 하겠다.
Ⅴ. 자전거 교통사고 예측 분석 및 성능 평가
1. 서울의 일별 교통사고 발생 건수 예측
일별 자전거 교통사고 발생 건수 예측을 위해 종관기 상관측소의 기상 정보를 독립변수로 사용하여 회귀분석 을 실시하였다.
날씨 정보는 지역별로 달라지므로 자전거 교통사고 발생 건수가 가장 높은 서울 지역을 대상으로, 일별 서 울 지역의 기상 정보와 자전거 교통사고 발생건수를 하 나의 파일로 병합하여 회귀분석을 실시하였다.
회귀분석에 사용한 독립변수는 “평균기온”, “일강수 량”, “평균풍속” 정보이고, 종속변수는 교통사고 발생건 수이다. 기상 정보에서 “안개 계속시간”은 시간이 표시 된 경우가 많지 않아 독립변수에서 제외하였다.
회귀분석 모델 결과를 요약하면 표 5와 같다. 모델의 유의성 검정 결과 F=939, p=0.000으로 회귀모형이 유의 한 것으로 분석되었으나, 결정계수 약 0.39로 아래 모델 의 설명력 수준은 39%인 것으로 분석되었다.
결정계수 회귀모형의 유의성
R
2adj R
2F p-value
0.392 0.3914 939 0.000
표 5. 회귀 분석 모델의 요약
Table5. The model summary of regression analysis.
회귀분석 모델에서 도출된 회귀식은 다음과 같다.
Y = 4.330 + 0.300X1 + -0.083X2 + 0.137X3
(단, Y=교통사고 발생건수, X1=평균기온, X2=일강수 량, X3=평균풍속)
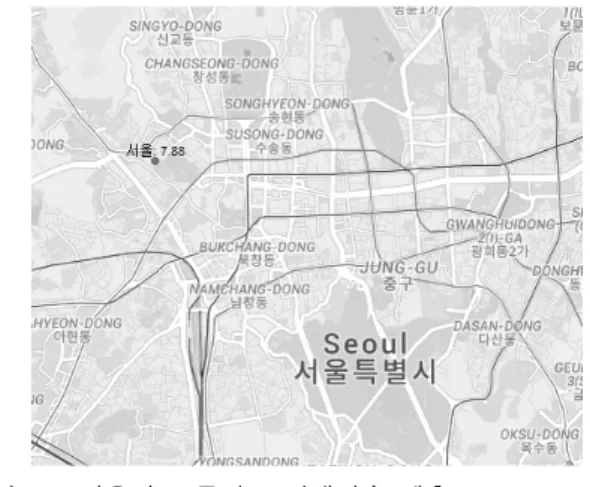
회귀식에 특정일의 기상 예측 정보를 평균기온=12, 일강수량=4, 평균풍속=2로 가정하여 각각 대입하면 약 7.88건의 교통사고 발생건수 예측 값을 구할 수 있다.
이렇게 구한 예측 값을 지도에서 서울 지역 관측소의 위치에 표시하면 그림 4와 같다. 교통사고 발생건수 예
측 결과와 지리 정보의 결합은 정보의 시각화를 통한 활용도를 높일 수 있을 것이다.
그림 4. 서울의 교통사고 발생건수 예측
Fig. 4. Prediction of the number of bicycle traffic accidents in Seoul.
2. 교통사고 심각도 분류 예측 및 성능 평가 자전거 교통사고 심각도 분류 예측을 위해 사상자와 중상자가 있는 경우를 “심각도 높음”, 나머지 경우를
“심각도 낮음”으로 분류하고, 예측 분석에 적절하게 데 이터 전처리를 실시하였다. 분류 예측의 독립 변수로는 1당사자 및 2당사자 운전자의 나이, 성별, 차량 정보를 사용*하고, 분류 예측 기법으로 의사결정 트리 방법을 적용하고 모델의 성능을 평가 하였다.
그림 5는 의사결정 트리 알고리즘 적용 후 도출한 의 사결정 트리 구성 결과이다. 여기에서 L은 심각도 낮음, H는 심각도 높음을 의미한다.
그림 5. 의사결정 트리 기법 적용 결과 Fig. 5. The result of decision tree method.
*사고 유형, 도로 형태, 위치 등의 정보도 있으나 해당 정보가 누락된 경우가 많고, 변수 척도도 부적절하여 대상에서 제외하였음
높은 심각도의 자전거 교통사고 유발 조건은 2당사 자 운전자의 나이가 55세 이상, 92세 미만이고 차종은 건설기계, 승용, 승합, 이륜, 특수, 화물인 경우로 분석 되었다. 즉, 위와 같은 조건의 운전자는 자전거 교통사 고 유발의 제1당사자는 아니지만 만약 사고가 발생한다 면 사상자나 중상자가 포함된 교통사고 당사자가 될 가 능성이 높아 운전 시 주의가 필요하다고 하겠다.
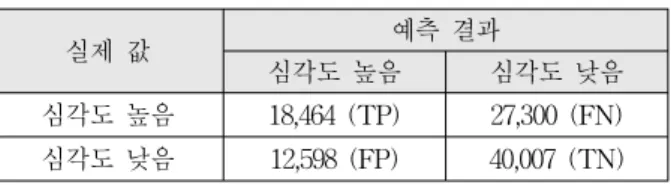
심각도 예측 모델의 성능 분석을 위하여 표 6과 같이 실제 심각도 수준과 예측 모델의 심각도 수준을 비교할 수 있는 컨퓨전 매트릭스를 도출하였다.
실제 값 예측 결과
심각도 높음 심각도 낮음
심각도 높음 18,464 (TP) 27,300 (FN) 심각도 낮음 12,598 (FP) 40,007 (TN)
표 6. 의사결정 트리 컨퓨전 매트릭스
Table6. The confusion matrix for decision tree.
이를 기반으로 정량적 성능 평가 지표인 모델의 정확 도(accuracy), 예측의 정밀도(precision) 및 재현도 (recall)를 산출하면 다음과 같다.
∙정확도 = (TP+TN) / (TP+FN+FP+TN)
= (58,471/ 98,369) * 100 = 59.4%
∙정밀도 = TP / (TP+FP)
= (18,464/31,062) * 100 = 59.4%
∙재현도 = TP / (TP+FN)
= (18,464/45,764) * 100 = 40.3%
정확도와 정밀도에서 59% 수준의 모델 성능으로 모 델의 성능이 그다지 높지 않은 편이다. 모델 성능을 높 이기 위해 추가로 기상 정보를 병합하여 분석을 시도하 였으나 효과적으로 모델 생성이 이루어지지 않았다.
현재로는 추가로 수집 가능한 정량적 자전거 교통사 고 데이터가 없고, 다른 자전거 교통 관련 데이터가 없 는 상황*으로 더 이상의 모델 성능 개선은 어려운 상 황이다.
3. 교통사고 사상자 수 및 심각도의 영향 요인 분석 자전거 교통사고 사상자 수에 1당사자 남녀 성별의 차이가 영향을 미치는지 확인하기 위해 두 집단 간의 평균 차이 검정을 실시하였다.
*일요신문, 자전거 인구 1000만 시대, 기초 통계자료 '전무', http://ilyo.co.kr/?ac=article_view&entry_id=89532
∙귀무 가설 : 성별 자전거 사상자 수는 동일할 것이다.
∙대립 가설 : 성별 자전거 사상자 수는 동일하지 않 을 것이다.
남녀 성별에 따른 자전거 교통사고 사상자 수의 기초 통계량은 표 7과 같다.
표 7. 1당사자 성별 사상자 수 기초 통계량
Table7. The statistics for the number of the dead by the first party's gender.
Item N Mean std. dev.
남성 73,246 1.05 0.28
여성 19,637 1.04 0.21
t-test를 적용한 성별 평균 차이 검정 결과는 표 8과 같다.
표 8. 1당사자 성별 사상자 수 평균 차이 검정 Table8. The mean difference test for the number of the
dead by the first party's gender.
Levene Test
a)Independent t-test
F p-value EV
b)T df p-value
105.88 0.000
c)assumed -5.2058 92,881 0.000
d)Not
assumed -6.0942 39,932 0.000
e) a) Levene's Test of Equality of Variances, b) Equal variances, c) 2.2e-16, d) 1.936e-07, e) 1.11e-09표 8과 같이 Levene 등분산이 가정되지 않으므로 등 분산이 가정되지 않은 경우를 적용하여 분석하였다.
T=-6.0942, df=39,932, p=0.000으로 유의수준 0.01하에서 귀무 가설이 기각되고, 대립 가설이 채택된다. 따라서 성별에 따라 사상자 수에 차이가 있음을 알 수 있다. 그 러나 평균 값의 차이는 0.01로 차이가 별로 크지 않아 성별에 따라 크게 두드러진 특징이 있다고 할 수는 없 을 것이다.
끝으로 1당사자 차량의 종류가 교통사고 심각도와 관련성이 있는지 확인하기 위하여 X2검정을 실시하였다.
1당사자 차종에서 비중이 매우 적은 “건설기계, 농기계, 특수, 기타 불명”은 분석 대상에서 제외하였다.
∙귀무 가설 : 1당사자 차량의 종류와 교통사고 심각 도는 관련성이 없다.
∙대립 가설 : 1당사자 차량의 종류와 교통사고 심각 도는 관련성이 있다.
X2검정 결과를 정리하면 표 9와 같다.
차종 정보 심각도 수준
차 종 항 목 높음 낮음 합 계
승용
Value 23,540 26,111 49,651 Rate 47.4% 52.6% 100%
EC* 23,165 26,486
승합
Value 2,807 2,146 4,953 Rate 56.7% 43.3% 100%
EC 2,311 2,642
원동기
Value 747 983 1,730
Rate 43.2% 56.8% 100%
EC 807 922
이륜
Value 1,344 1,547 2,891 Rate 46.5% 53.5% 100%
EC 1,349 1,542
자전거
Value 9,912 15,548 25,460 Rate 38.9% 61.1% 100%
EC 11,879 13,581
화물
Value 6,036 4,413 10,449 Rate 57.8% 42.2% 100%
EC 4,875 5,574
X2 data: X2= 1,348.1, df = 5, p=0.000(2.2e-16)
표 9. 차종에 따른 심각도 수준Table9. The level of severity by car type.
* Expected counts
가설 검정 결과 X2= 1,348.1, df = 5, p=0.000으로 유 의수준 0.01 하에서 귀무가설이 기각되었다. 따라서 차 량의 종류에 따라 교통사고 심각도는 다른 것으로 나타 났음을 알 수 있다.
분석 결과를 요약하면 1당사자 차량이 승합차나 화 물일 때 사망자나 중상자가 나올 가능성이 높으며, 승 용차, 원동기, 이륜차, 자전거인 경우 가능성이 떨어진 다고 할 수 있다. 위와 같은 결과는 4장 2절의 교통사고 심각도 분류에서 식별된 차종 중에서 승합과 화물의 경 우가 중복됨을 발견할 수 있다.
차량의 종류 중에서 교통량이 가장 많은 승용차의 경 우, 심각도 높음의 비율이 47.4%를 차지하고 있으므로 승용차 운전자의 주의가 필요하다고 하겠다.
Ⅵ. 결론 및 향후 연구
도로교통공단의 자전거 교통사고 데이터를 대상으로 연도별 교통사고 발생 건수, 사망자 및 사상자 수, 지역
별 교통사고 발생 건수, 교통 법규의 위반 현황 등의 교 통사고 현황 분석을 하였다.
또한 일별 자전거 교통사고 발생 건수 예측을 위해 종관기상관측소의 기상 정보 사용하여 회귀분석을 실시 하고, 교통사고 심각도 분류 예측 및 성능 평가를 수행 하였다. 그리고 두 집단 간의 평균 차이 검정을 통해 성 별이 교통사고 사상자 수에 영향을 미치는 것을 확인하 고, 차량의 종류가 교통사고 심각도와 관련성이 있음을 검정하였다.
예측 분석은 독립 변수가 양적 비율 척도일 때 정확 도나 유효성이 높지만 현재 자전거 교통사고 데이터는 명목 척도로 측정된 범주형 데이터가 많은 편이다. 또 한 현재 자전거 도로에서의 자전거 주행 속도, 자전거 운전자 수, 교통량 및 보행자 수 등 정량적 기초 통계량 이 매우 부족한 실정으로 상시 모니터링을 통한 자전거 교통량 측정을 위해 관련 데이터 수집 정책의 수립이 필요한 상황이다.
유럽의 경우 EU의 지원으로 자전거 정책의 효과성과 효율성 측정을 위해 24개국에서 BYPAD(Bicycle Policy Audit) 모델을 도입하여 적용하고 있다[11]. BYPAD는 계획, 실행, 모니터링의 동적 수행 절차를 가지는 9개 모듈로 구성된 자전거 정책 품질 관리 방법이다. 국내 에서도 이와 같은 자전거 정책에 대한 종합적 품질 관 리가 필요하다고 하겠다.
무엇보다도 자전거 교통과 관련한 다양한 기본 통계 자료가 구축되었을 때 여러 가지 데이터 분석 및 기계 학습 알고리즘 적용이 용이할 것이다. 이를 통한 분석 결과는 자전거 교통사고 예방이나 관련 정책 수립의 의 사결정에 실질적인 도움이 될 것으로 기대한다.
REFERENCES
[1] Statistics Korea, e-National Index, Departmental Index, “Bicycle Road Status‘, Available: http://
www.index.go.kr/potal/main/EachDtlPageDetail.do
?idx_cd=2854
[2] Road Traffic Authority, 2014 The factor analysis of traffic accident - characteristic analysis of bicycle traffic accident -, Samyoungmunwhasa, 2014.
[3] Ministry of the Interior, Infrastructure improvement plan based on the analysis of bicycle accident type(2013), [Online]. Available:
http://www.moi.go.kr/frt/bbs/type001/commonSele ctBoardArticle.do?bbsId=BBSMSTR_000000000012
&nttId=44900 (downloaded 2015, Oct.. 1)
저 자 소 개 최 승 희(정회원)
1989년 전북대학교 전산통계학과 졸업
1989년~2007년 다수 프로젝트의 소프트웨어 개발 및 개발 PM
2008년~2013년 STA테스팅컨설팅 컨설턴트 및 강사
2013년 강원대학교 컴퓨터정보통신공학과 졸업 (석사)
2016년 강원대학교 컴퓨터정보통신공학과 박사과 정 수료
<주관심분야 : 소프트웨어 공학, 데이터 사이언스, 소프트웨어 테스팅 및 품질>
이 구 연(정회원)
1986년 서울대학교(공학사-전자공 학)
1988년 한국과학기술원(공학석사- 전기 및 전자공학)
1993년 한국과학기술원(공학박사- 전기 및 전자공학)
1993년~1996년 디지콤 정보통신 연구소 1996년~1997년 삼성전자
1997년~현재 강원대학교 컴퓨터학부 컴퓨터정보 통신공학전공 교수
2004년 7월~2005년 2월 미국 Cornell 대학교 Visiting Professor
2010년 1월~2011년 1월 미국 Cornell 대학교 Visiting Professor
2012년 8월~2014년 2월 강원대학교 IT 대학 부학장
<주관심분야 : 데이터통신, 컴퓨터네트워크, 네트 워크 보안, 차세대 인터넷, 이동통신, 네트워크 성 능분석, ad-hoc network, wireless mesh network, network coding>
[4] H. Cho, “A study on the Influence factors of bicycle accident and the awareness of bicycle users about the risk of accidents”, Pusan National University, Master's thesis, 2014.
[5] C. Hong, and M. Kim, “Statistical analysis and its application of bicycle accidents”, Journal of the Korean data & information science society, Vol. 21, No.6, pp. 1081-1090, 2010.
[6] C. Nam, “Development of Accident Prediction Model and Suggestion of Safety Improvements on Bicycle Transportation”, Chonnam National University, Ph.D. Dissertation , 2013.
[7] S. Jung, “Building a Risk Model of Mountain Bike Accident based on Data Mining Technique”, Chungbuk National University, Master's thesis, 2011.
[8] J. Scholtz, A. Wendelborn, K. Maciunas, “Ontology layering in an early warning sensor (EWS) bicycle accident prevention system”, Proc. of the Connected Vehicles and Expo (ICCVE), 2014 International Conference, pp. 919-924, 2014.
[9] Korea Meteorological Administration, “Korea Climate Data Open Portal”, Available: https://
data.kma.go.kr (downloaded 2016, Apr., 26) [10] Statistics Korea, “Korean Statistical Information
Service”, Available: http://kosis.kr/statisticsList/
statisticsList_01List.jsp?vwcd=MT_ZTITLE&parm TabId=M_01_01
[11] BYPAD consortium, “BYPAD in one Minute”, Available:http://www.bypad.org/cms_site.phtml?id
=551&sprache=en