2020, 31
(4)
,653–662
분위수 회귀모형을 이용한 한국프로야구 투수들의 연봉 결정요인 †
ᄋ ᅵ장택
1
1단국대학교 정보통계학과
ᄌ ᅥ
ᆸᄉ ᅮ 2019ᄂ ᅧ ᆫ 12ᄋ ᅯ ᆯ 23ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2020ᄂ ᅧ ᆫ 2ᄋ ᅯ ᆯ 14ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2020ᄂ ᅧ ᆫ 2ᄋ ᅯ ᆯ 24ᄋ ᅵ ᆯ
요 약
ᄇ
ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ 2010ᄂ ᅧ ᆫᄇ ᅮᄐ ᅥ 2018ᄂ ᅧ ᆫᄁ ᅡᄌ ᅵᄋ ᅴ ᄒ ᅡ ᆫᄀ ᅮ ᆨ ᄑ ᅳᄅ ᅩᄋ ᅣᄀ ᅮ ᄐ ᅮᄉ ᅮ ᄀ ᅵᄅ ᅩ ᆨᄋ ᅳ ᆯ ᄋ ᅵᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᄐ ᅮᄉ ᅮᄃ ᅳ ᆯ ᄋ ᅴ ᄋ ᅧ ᆫᄇ ᅩ ᆼᄋ ᅳ ᆯ ᄎ
ᅮᄌ ᅥ ᆼᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄌ ᅥ ᆼᄀ ᅲᄉ ᅥ ᆼᄀ ᅪ ᄋ ᅵᄉ ᅡ ᆼᄌ ᅥ ᆷᄋ ᅦ ᄏ ᅳᄀ ᅦ ᄋ ᅧ ᆼᄒ ᅣ ᆼᄋ ᅳ ᆯ ᄇ ᅡ ᆮᄌ ᅵ ᄋ ᅡ ᆭᄀ ᅩ ᄆ ᅩᄃ ᅳ ᆫ ᄇ ᅮ ᆫ ᄋ ᅱᄉ ᅮᄋ ᅦᄉ ᅥ ᄃ ᅩ ᆨᄅ ᅵ ᆸᄇ ᅧ ᆫᄉ ᅮᄃ ᅳ ᆯ ᄋ ᅴ ᄇ ᅧ ᆫᄒ ᅪᄋ ᅦ ᄃ ᅢᄒ ᅢ ᄌ ᅥ
ᆼᄆ ᅵ ᆯᄒ ᅡ ᆫ ᄀ ᅧ ᆯᄀ ᅪᄅ ᅳ ᆯ ᄋ ᅡ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄂ ᅳ ᆫ ᄇ ᅮ ᆫ ᄋ ᅱᄉ ᅮ ᄒ ᅬᄀ ᅱᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅳ ᆯ ᄉ ᅡᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᆻᄋ ᅳᄆ ᅧ ᄀ ᅮᄎ ᅦᄌ ᅥ ᆨᄋ ᅳᄅ ᅩ ᄇ ᅮ ᆫ ᄋ ᅱᄉ ᅮᄋ ᅴ ᄇ ᅧ ᆫᄒ ᅪᄋ ᅦ ᄄ ᅡᄅ ᅳ ᆫ ᄂ ᅡᄋ ᅵ, ᄀ ᅧ
ᆼᄒ ᅥ ᆷ, ᄋ ᅧ ᆫᄃ ᅩ, ᄌ ᅡᄋ ᅲᄀ ᅨᄋ ᅣ ᆨ ᄋ ᅧᄇ ᅮ, ᄉ ᅳ ᆼ ᄅ ᅵ ᄒ ᅬ ᆺ ᄉ ᅮ, ᄃ ᅢᄎ ᅦᄉ ᅥ ᆫᄉ ᅮ ᄃ ᅢᄇ ᅵ ᄉ ᅳ ᆼ ᄅ ᅵᄀ ᅵᄋ ᅧᄃ ᅩ, ᄀ ᅧ ᆼᄀ ᅵ ᄒ ᅬ ᆺ ᄉ ᅮ, ᄉ ᅦᄋ ᅵᄇ ᅳ ᄒ ᅬ ᆺ ᄉ ᅮ, ᄉ ᅥ ᆫᄇ ᅡ ᆯᄎ ᅮ ᆯ ᄌ ᅡ ᆼ ᄒ ᅬ
ᆺ ᄉ ᅮ, ᄉ ᅩᄉ ᅩ ᆨ ᄐ ᅵ ᆷᄋ ᅵ ᄉ ᅡ ᆷᄉ ᅥ ᆼᄋ ᅵ ᆫ ᄋ ᅧᄇ ᅮᄋ ᅴ ᄎ ᅮᄌ ᅥ ᆼᄃ ᅬ ᆫ ᄇ ᅮ ᆫ ᄋ ᅱᄉ ᅮ ᄒ ᅬᄀ ᅱᄒ ᅭᄀ ᅪᄅ ᅳ ᆯ ᄀ ᅳᄅ ᅵ ᆷᄋ ᅳᄅ ᅩ ᄌ ᅦᄉ ᅵᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄀ ᅧ ᆯᄅ ᅩ ᆫᄌ ᅥ ᆨᄋ ᅳᄅ ᅩ ᄇ ᅮ ᆫ ᄋ ᅱᄉ ᅮ ᄒ
ᅬᄀ ᅱᄆ ᅩᄒ ᅧ ᆼᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄌ ᅥ ᆨᄒ ᅡ ᆸᄃ ᅩ ᄀ ᅥ ᆷᄌ ᅥ ᆼᄋ ᅵ ᄉ ᅥ ᆼᄅ ᅵ ᆸᄒ ᅡᄀ ᅩ ᄉ ᅡᄇ ᅮ ᆫ ᄋ ᅱᄉ ᅮᄋ ᅦ ᄄ ᅡᄅ ᅡ ᄀ ᅨᄉ ᅮᄃ ᅳ ᆯ ᄋ ᅴ ᄎ ᅡᄋ ᅵᄀ ᅡ ᄋ ᅵ ᆻᄋ ᅳ ᆷᄋ ᅳ ᆯ ᄋ ᅡ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄋ ᅥ ᆻᄋ ᅳᄆ ᅧ ᄋ ᅧ ᆫ ᄇ
ᅩ
ᆼ ᄋ ᅨᄎ ᅳ ᆨ ᄋ ᅦᄂ ᅳ ᆫ ᄎ ᅬᄉ ᅩᄌ ᅥ ᆯᄃ ᅢᄑ ᅧ ᆫᄎ ᅡ ᄒ ᅬᄀ ᅱᄆ ᅩᄒ ᅧ ᆼᄋ ᅵ ᄎ ᅬᄉ ᅩᄌ ᅦᄀ ᅩ ᆸ ᄒ ᅬᄀ ᅱᄆ ᅩᄒ ᅧ ᆼᄇ ᅩᄃ ᅡ ᄋ ᅧ ᆫᄇ ᅩ ᆼ ᄋ ᅵ ᄂ ᅡ ᆽᄋ ᅳ ᆫ ᄐ ᅮᄉ ᅮᄃ ᅳ ᆯ ᄋ ᅦᄀ ᅦ ᄃ ᅥ ᄒ ᅭᄋ ᅲ ᆯᄌ ᅥ ᆨᄋ ᅳᄅ ᅩ ᄂ
ᅡᄐ ᅡᄂ ᅡ ᆻᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄇ ᅮ ᆫ ᄋ ᅱᄉ ᅮ ᄒ ᅬᄀ ᅱ, ᄌ ᅥ ᆨᄒ ᅡ ᆸᄃ ᅩ ᄀ ᅥ ᆷᄌ ᅥ ᆼ, ᄐ ᅮᄉ ᅮᄋ ᅧ ᆫᄇ ᅩ ᆼ, ᄒ ᅡ ᆫᄀ ᅮ ᆨ ᄑ ᅳᄅ ᅩᄋ ᅣᄀ ᅮ.
1. 서론 ᄒ
ᅡᆫ국프로야구 (Korean Baseball Organization; KBO)에서 투수의 비중은매우 크기 때문에 투수의 ᄋ
ᅧᆫ봉은언론과 학계에서 상당한 주목을받는다. 선수와 경영진 사이에서 타협이 이뤄지는연봉은선수 ᄋ
ᅴ 과거 성과와 미래의 잠재력을기반으로 한다. 그러나 구단의 경제적 형편도 고려해야 하고 객관적인 ᄉ
ᅥᆫ수의 평가도 쉬운 일은아니므로 능력이 비슷한 다른 선수들의 연봉에 대한 평가를 참고하는감각이 피
ᆯ요하다. 그러므로 구단과 선수들 사이에 서로가 수긍하는 객관적인 수행능력 평가는 필요하다고 할 ᄉ
ᅮ 있으며 이런 이유로 선수들의 경기력 결과와 연봉간의관계연구는 중요한 의미가 있다.
ᄆ
ᅵ국프로야구 (Major League Baseball; MLB)에서는 1990년대부터 오늘날에 이르기까지 많은 연 ᄀ
ᅮ자가 MLB의 연봉에 대한 모형을 개발했는데, 종속변수로 연봉이나 로그를 취한 로그 연봉을 사용 ᄒ
ᅡ고, 투수 기록을이용한 새로운 측도, 나이의 제곱과 같은비선형효과의 고려, MLB 경력 등을포함 ᄒ
ᅡᆫ 다양한 독립변수들을사용하였으며 (Lackritz, 1990; Marburger, 1994; Hoagin과 Velleman, 1995;
Bollinger와 Hotchkiss, 2003; Hakes와 Sauer, 2006; Hills와 Gregory, 2014) 또한, 최근에는 컴퓨터 화
ᆫ경이 매우 좋아지면서 경기력과 연봉사이의관계를 인공 신경망과 접목한 결과도 발표되었다 (Chao ᄃ
ᅳᆼ, 2013). 한편 KBO 투수들의 연봉에관한 연구들은연봉과 투수 기록과의 회귀모형을제안한 Lee와 Kang (2001),여러 가지 투수 기록들을이용하여 주성분회귀분석을 실시한 Kim (2002), 데이터마이닝
†
ᄋ ᅵ ᄋ ᅧ ᆫᄀ ᅮᄂ ᅳ ᆫ 2020ᄒ ᅡ ᆨᄂ ᅧ ᆫᄃ ᅩ ᄃ ᅡ ᆫᄀ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄃ ᅢᄒ ᅡ ᆨᄋ ᅧ ᆫᄀ ᅮᄇ ᅵ ᄌ ᅵᄋ ᅯ ᆫ ᄋ ᅳᄅ ᅩ ᄋ ᅧ ᆫᄀ ᅮᄃ ᅬᄋ ᅥ ᆻᄋ ᅳ ᆷ.
1
(16890) ᄀ ᅧ ᆼᄀ ᅵᄃ ᅩ ᄋ ᅭ ᆼᄋ ᅵ ᆫᄉ ᅵ ᄌ ᅮ ᆨᄌ ᅥ ᆫᄃ ᅩ ᆼ 126ᄇ ᅥ ᆫᄌ ᅵ, ᄃ ᅡ ᆫᄀ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄌ ᅥ ᆼᄇ ᅩᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄀ ᅭᄉ ᅮ.
E-mail: [email protected]
ᄀ
ᅵ법을적용하여 KBO 선수들의 연봉에관한 분석을다룬 Oh와 Lee (2003), 세이버메트릭스 측도들을 ᄋ
ᅵ용하여 투수의 기록과 연봉과의관계를 분석한 Kim (2013), 한국프로야구에서 투수연봉에 영향을주 ᄂ
ᅳᆫ요인을모형화를 통해 설명한 Lee (2017) 등이 있다.
이
ᆯ반적으로 스포츠 선수들의 연봉데이터는왜도가 크고 이상점이 많고 정규분포를따르지도 않는다.
ᄋ
ᅵ런 현상은해외뿐만 아니라 국내에도 발생하는보편적인 현상이며 이 경우 최소제곱회귀분석은 좋은 ᄇ
ᅡᆼ법이 되지 못하기 때문에 대안으로 본연구에서는선형 분위수회귀 (linear quantile regression)를고 ᄅ
ᅧ하였다. Koenker와 Bassett (1978)에 의해 제안된 분위수 회귀분석은 종속변수의 조건부 분포에 대 ᄒ
ᅡᆫ 정보를자세하게 제공하고, 이상점이나 오차 분포에 민감하게 반응하지 않는로버스트성을가지는장 ᄌ
ᅥᆷ이 있으며 주어진 분포 안에서 다양한 백분위수 위치에서 종속변수를추정할 수 있다. 하지만 분위수 ᄒ
ᅬ귀분석을사용하는것이 바람직하려면 데이터의 크기가 충분히 커야 하며, 종속변수가 분산이 같지 않 ᄋ
ᅳ
ᆫ이분산 데이터이며, 독립변수의 종속변수에 대한 효과가 구간별로 달라야 하는데 MLB의 경우를살 ᄑ
ᅧ보더라도 이런 조건들을만족한다고 할 수 있겠다 (Wiseman 등, 2010).
ᄇ
ᅮᆫ위수 회귀분석에관한 연구들을 살펴보면 해외 연구 중스포츠 선수들의 연봉에관한 연구로 미국 ᄒ
ᅡ키리그 선수들의 연봉 분석 (Vincent와 Eastman, 2009), 미국프로야구 선수들의 연봉 분석 (Wise- man과 Chatterjee, 2010), 미국프로야구 선수들의 연봉차별에 대한 분석 (Holmes, 2011) 등이 있으며, ᄀ
ᅮ
ᆨ내 연구로는비대칭 라플라스 분포를이용한 분위수 회귀모형을추정한 Park (2009), 분위수 회귀를 ᄋ
ᅵ용하여 한국의 세대 간 경제적 이동성을연구한 Richey와 Jeong (2014), 다변량 분위수 회귀나무 모 혀
ᆼ을연구한 Kim 등 (2017)이 있다. 본 논문은다음과 같이 구성된다. 2절에서는데이터의 구성 및 분 ᄉ
ᅥᆨ에 사용한 여러 가지 변수들을살펴보고 선형 분위수회귀 이론을간략하게 설명하였으며 사용된 통계 ᄑ
ᅢ키지를언급하였다. 3절에서는추정된 분위수 회귀모형을 설명하고, 분위수 회귀그림을이용하여 분 ᄋ
ᅱ수의 변화에 따른 독립변수 효과를설명하고, 최소제곱회귀모형과 비교하였다. 끝으로 4절에서는 본 ᄋ
ᅧᆫ구의 결론을제시하였다.
2. 자료수집 및 분석방법
2.1. 데이터의 구성
Lee (2017)의 연구방법을 계속 사용하여 데이터는 한국프로야구 기록 사이트인 스탯티즈 (http:
//www.statiz.co.kr)의 2010년부터 2018년 사이의 연봉데이터를 이용하였으며, 분석대상은 모두 1034명의 경기결과이다. 구체적으로 조사된 선수들은 KIA 111명, LG 122명, NC 57명, SK 118명, 넥 세
ᆫ 98명, 두산 114명, 롯데 108명, 삼성 131명, 한화 121명, 그리고 KT 54명으로 분석대상 선수들이 가 ᄌ
ᅡᆼ 많이 속한 팀은삼성, LG의 순서로 나타났다.
2.2. 분석에 사용된 변수 ᄋ
ᅧᆫ구에서 고려한 설명변수들은연도, 팀, 경기횟수, 선발출장횟수, 승리횟수, 패배횟수, 세이브횟 ᄉ
ᅮ, 투구이닝 수, 자유계약선수 여부, 출생연도, 프로야구 시작연도, 나이, 경험 연수, 평균자책점, 수 ᄇ
ᅵ무관 평균자책점, 이닝 당 안타 및 볼넷 허용률, 대체선수 대비 승리기여도 (WAR)이며, 반응변수 ᄅ
ᅩ는 기본단위가 만원인 연봉에 로그를취한 로그 연봉을사용하였다. 사용된 변수들의 타당성은 Lee (2017)에서 최소제곱 회귀모형을사용하는경우에 변수선택을 통해 유의한 변수로 채택된변수들이며, ᄂ
ᅡ이는해당연도-출생연도, 경험은해당연도-입단연도, 연도는간편 계산을위해 해당연도-2010으로 계 ᄉ
ᅡᆫ하고 자유계약 여부는해당연도에 자유계약 건이 있으면 1, 없으면 0, 팀은소속 팀이 삼성이면 1, 아 ᄂ
ᅵ면 0을사용하였다.
2.3. 선형 분위수회귀 ᄌ
ᅩ
ᆼ속변수의 조건부 평균이 아닌 조건부 분위를 중심으로 계수를추정하는 분위수 회귀는다음과 같이 ᄋ
ᅣ
ᆨ술된다 (Kim과 Park, 2013; Park, 2009). 표본분위수의 개념을회귀식에 적용하기 위해 Koenker와 Bassett (1978)에 의해 제안된모형은다음과 같은위치모형 (location model)이며,
yi= β + ϵi. ᄋ
ᅵ 경우 yi는연속확률분포함수 F 를갖는 독립이고 동일한 분포를갖는확률변수이며, τ 번째 표본분 ᄋ
ᅱ수는다음 식을최소화하는해가된다.
minβ∈R n
X
i=1
ρτ(yi− β),
ᄋ
ᅧ기서 τ ∈ (0, 1)이며, ρτ(a)은 a < 0이면 a(τ − 1) 아니면 aτ 로 정의되는선형손실함수 (linear loss function)이다. 이 표본추정량의 개념을 선형회귀추정에 적용하기 위하여 다음과 같은 모형을 가정한 ᄃ
ᅡ. 식에서 ϵi는 0에 대해 대칭인 연속확률분포함수 F 를갖는 독립이고 동일한 분포를갖는확률변수이 ᄆ
ᅧ β는 p × 1모수벡터이다.
yi= x′iβ + ϵi. ᄉ
ᅥᆫ형회귀모형에 대한 최소제곱회귀 (ordinary least squares; OLS)는 다음 식을 최소화하는 β를 구 ᄒ
ᅡᆫ다.
β∈Rminp
n
X
i=1
(yi− x′iβ)2.
ᄋ
ᅵ제 비슷한 방법으로 앞에서 설명한 표본분위수의 개념을선형회귀모형에확장하여 분위수 선형회귀 ᄎ
ᅮ정량을 끌어낼 수 있는데 독립변수 x가 주어질 때 y의 τ 번째 조건부 분위수 함수 (conditional quan- tile function)를 Qy(τ |x) = x′βτ로 정의하면 선형 분위수회귀 추정치는표본분위수의 최소화 식에 포 ᄒ
ᅡᆷ된상수 β대신 x′iβ로 대체한 다음 식의 최소화 문제를만족시키는해로부터 구해진다.
β∈Rminp
n
X
i=1
ρτ(yi− x′iβ).
ᄋ
ᅧ러 가지 τ 의 값 중에서 τ = 0.5인 경우에는다음 식의 최소화 문제를만족하는해로 구해지며, 이때 ᄋ
ᅴ 분위수 회귀추정을최소절대편차 (least absolute deviation; LAD) 회귀 또는 중위수 회귀라고 부른 ᄃ
ᅡ.
min
β∈Rp n
X
i=1
|yi− x′iβ|.
ᄎ
ᅬ소제곱회귀모형은회귀계수의 추정 시에 최소제곱법을사용하지만 분위수 회귀모형에서는최소절 ᄃ
ᅢ편차 손실함수에서 사용되는선형계획법을사용하는데, 선형계획법 문제는 복잡할 수는 있지만, 데이 ᄐ
ᅥ 개수가 너무 많지 않으면 심각한 계산 문제는발생하지 않는다. 최소제곱회귀분석에서는설명변수 ᄋ
ᅴ 변동에 의한 반응변수의 변동을평균수준에서만 설명하는것이지만 분위수 회귀분석에서는 같은 설 며
ᆼ변수라 할지라도 각 분위수 별로 미치는영향력이 다름을확인할 수 있고, 모든 분위수에서의 변동을 서
ᆯ명하는것이 가능하며, 이는 곧반응변수의 전체 분포에 대한 정보를 제공하는것과 동일하다. 한편 부
ᆫ위수 회귀모형에서 모형의 유연성을위하여 선형의 가정을완화하여 비선형 분위수 회귀모형을사용 ᄒ
ᅡᆯ 수 있다. 비선형 분위수 회귀모형의 추정을위해 다양한 비모수적 추정법들이 제안되었는데, 전반적 ᄋ
ᅵᆫ 개요는 Kim 등 (2016)과 Geraci (2019)을 통하여 알 수 있다.
2.4. 사용된 통계패키지 보
ᆫ연구에서는 분위수 회귀분석을수행하기 위해 R 소프트웨어의 quantreg와 Qtools 패키지를사용 ᄒ
ᅡ였다. Qtools와 quantreg 패키지에 대한 자세한 설명은 R프로그램 내에서확인하거나 인터넷 검색 으
ᆯ 통해 매뉴얼을 숙지할 수 있다. 본연구에서 사용된함수들은구체적으로 Qtools의 적합도검정을위 ᄒ
ᅡᆫ GOFTest, quantreg의 사분위수에 대한 기울기의 동일성 여부를위한 anova, 최소제곱회귀를위한 lm, 분위수회귀를위한 rq, 절편과 독립변수들에 대하여 분위수 0.1부터 0.9까지의 계수 추정치의 변화 르
ᆯ그래프로 보여주는 plot과 같다.
3. 투수연봉을 위한 분위수 회귀모형
3.1. 분석 및 결과
2010년부터 2018년까지 투수들의 연봉데이터를이용하여 고려한 구체적인 회귀모형은다음과 같다.
y = β0+ β1x1+ β2x2+ β3x3+ β4x4+ β5x5+ β6x6+ β7x7+ β8x8+ β9x9+ β10x10+ ϵ, ᄋ
ᅧ기서 y는로그 연봉, x1은나이, x2는경험, x3은연도, x4는자유계약 여부, x5는 승리횟수, x6은대 ᄎ
ᅦ선수 대비 승리기여도, x7은게임횟수, x8은세이브횟수, x9는선발출장 횟수, x10은소속 팀이 삼 서
ᆼ 여부를의미한다. Lee (2017)의 연구 결과와 약간 다른것은 3년간의 데이터가 보충되면서 소속 팀 ᄋ
ᅵ 한화 여부를확인했던 변수는유의수준 0.1에서도 더는유의하지 않았다.
Figure 3.1 Histogram for salary and log salary
Figure 3.1의 연봉 (왼쪽)은정규분포가 아닌 왜도가 매우큰오른쪽으로 꼬리가 긴 분포이다. 그래서 ᄇ
ᅩ통정규성의 문제를해결하기 위하여 로그 변환을사용한 로그 연봉 (오른쪽)도 정규분포라고 하기는 ᄆ
ᅮᆫ제가 있다고 할 수 있겠다. 또한, 치우친 데이터의 경우는 분포의 특징을파악할 수 있는 τ 번째 분위 ᄉ
ᅮ의 예측이 더 중요하고 의미가 있으며, 보통많이 사용하는 τ = 0.25, 0.5, 0.75는각각 연봉의 제1사분 ᄋ
ᅱ수, 중앙값, 제3사분위수의 예측을 나타낸다. 또한, 최소제곱회귀분석을이용하는 경우에 종속변수 ᄋ
ᅦ 대한 이상점을스튜던트 제외잔차의 절대값이 2를초과하는데이터라고 판정하면 58개가 되었다. 따 ᄅ
ᅡ서 보편화한 자료 분석의관점에서 보면 투수연봉데이터는 종속변수에 대한 너무 많은이상점을가진 ᄃ
ᅡ고 할 수 있다. 실제로 연봉에 대한 이상점이 많은이유는외국인인 경우는 특수하므로 제외하더라도 ᄉ
ᅳ타 선수 또는자유계약이 있는선수들이 대부분의 선수들보다 월등하게 연봉이 많기 때문이다.
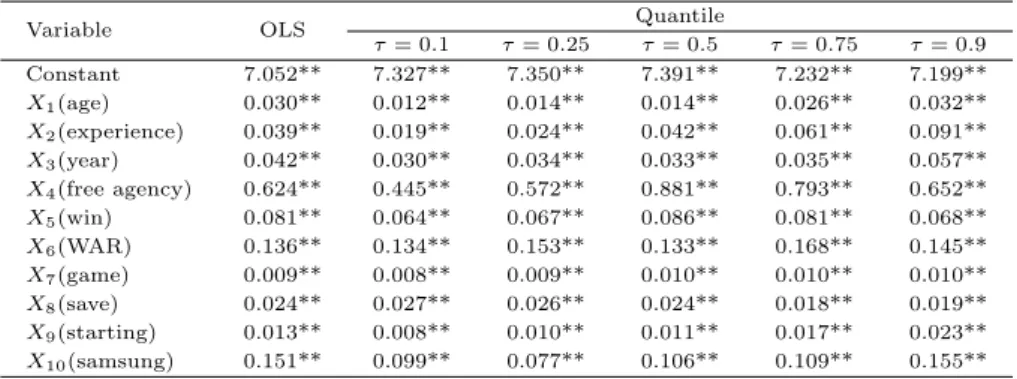
Table 3.1은한국프로야구 투수들의 연봉자료가 독립변수 x1부터 x10까지의 10개의 독립변수를 사 ᄋ
ᅭ
ᆼ한 분위수 회귀모형에 적합한지를검정한 적합도 검정의 결과이다. 분위수 선형회귀모형은적합하다 느
ᆫ귀무가설에 대해 대부분의 분위수의 값에 대하여 유의확률이 커서 분위수 회귀모형이 적합한 것으로 ᄇ
ᅩᆯ수 있으며, 가장 작은유의확률 0.02인 경우에도 유의수준 1%를사용하면 분위수 회귀모형은적합하 ᄃ
ᅡ고 할 수 있겠다. 이 경우, 만일 적합도 검정의 유의확률이 너무 작으면 분위수 회귀모형을이용하여 부
ᆫ석하는것이 별 의미가 없다는해석을할 수 있다.
Table 3.1 Goodness of fit test for quantile regression Quantile Test statistic p-value
0.1 2e-04 0.32
0.25 3e-04 0.02
0.5 4e-04 0.11
0.75 3e-04 0.70
0.9 2e-04 0.17
Table 3.2는세 가지 사분위수 0.25, 0.5, 0.75에 대한 기울기의 동일성 여부를검정한 결과인데 유의 ᄉ
ᅮ준 1%에서 네 가지 귀무가설이 모두 기각되어서 분위수 회귀분석 수행에 대한 타당성이 있다고 할 수 이
ᆻ다.
Table 3.2 Test that the slopes are the same at more quantiles
Hypothesis p - value
H
0: β
0.25= β
0.503.3e-13 H
0: β
0.25= β
0.752.2e-16 H
0: β
0.50= β
0.752.7e-10 H
0: β
0.25= β
0.50= β
0.752.2e-16
Table 3.3은한국프로야구 투수들의 연봉을회귀모형으로 추정한 결과인데 앞 절에서 언급한 10개의 ᄇ
ᅧᆫ수를 설명변수로 사용하였다. OLS 회귀 결과는 10개의 변수 모두 유의수준 1%에서 유의하게 나왔 ᄃ
ᅡ. 그리고 분위수 값의 변화에 따른회귀계수들을살펴보면 먼저 나이의 경우는 분위수가 커질수록계 ᄉ
ᅮ는조금씩 증가하며 모든 분위수에서 유의수준 1%에서 유의했다. 경험은모든 분위수에서 연봉에 양 ᄋ
ᅴ 영향을 주며 같은 경험치라도 분위수의 값이 증가함에 따라 연봉 증가분이 더 커지는 것으로 나타 ᄂ
ᅡ
ᆻ다. 연도에 대한 계수 추정치의 변화 역시 모든 분위수에서 연봉에 양의 영향을미치고 자유계약 건 ᄋ
ᅦ 대해서는 분위수가 0.5, 0.75에서는유의수준 1%에서 유의하게 나타났으며, 분위수가 0.1인 경우에 느
ᆫ유의하지 않은것으로 나타났다. 승리횟수는 분위수 0.5, 0.75에서 회귀계수의 크기가 크며 나머지 ᄇ
ᅮᆫ위수는비슷한 회귀계수를가지는것으로 나타났다. 또한 세이버메트릭스 지수인 대체선수 대비 승리
Table 3.3 Coefficient estimates for the 10th, 25th, 50th, 75th, 90th quantile regression
Variable OLS Quantile
τ = 0.1 τ = 0.25 τ = 0.5 τ = 0.75 τ = 0.9
Constant 7.052** 7.327** 7.350** 7.391** 7.232** 7.199**
X
1(age) 0.030** 0.012** 0.014** 0.014** 0.026** 0.032**
X
2(experience) 0.039** 0.019** 0.024** 0.042** 0.061** 0.091**
X
3(year) 0.042** 0.030** 0.034** 0.033** 0.035** 0.057**
X
4(free agency) 0.624** 0.445** 0.572** 0.881** 0.793** 0.652**
X
5(win) 0.081** 0.064** 0.067** 0.086** 0.081** 0.068**
X
6(WAR) 0.136** 0.134** 0.153** 0.133** 0.168** 0.145**
X
7(game) 0.009** 0.008** 0.009** 0.010** 0.010** 0.010**
X
8(save) 0.024** 0.027** 0.026** 0.024** 0.018** 0.019**
X
9(starting) 0.013** 0.008** 0.010** 0.011** 0.017** 0.023**
X
10(samsung) 0.151** 0.099** 0.077** 0.106** 0.109** 0.155**
∗p < 0.05, ∗ ∗p < 0.01
ᄀ
ᅵ여도 (WAR)은모든 분위수에 대해 유의수준 1%에서 유의하게 나타났으며 크기도 비슷했다. 출전한 겨
ᆼ기횟수나 세이브 수는모두 유의수준 1%에서 유의하게 나타났으며 계수의 크기도 비슷했다. 야구에 ᄉ
ᅥ 선발출장 횟수의 중요성은예나 지금이나 강조되는데 분위수 값이 증가할수록 계수 추정치는더 커 ᄌ
ᅵᆫ다. 이 사실로부터 고액연봉을받는투수일수록선발투수로서 출장횟수의 가치를더 인정받는다고 할 ᄉ
ᅮ 있다. 마지막으로 삼성 구단의 경제적 여력에 대한 회귀계수를보면 분위수 0.1와 0.5에서는유의수 ᄌ
ᅮᆫ 1%에서 유의하고 분위수 0.25, 0.9에서는유의수준 5%에서 유의하지만 분위수 0.75에서는유의하지 ᄋ
ᅡ
ᆭ게 나타났다.
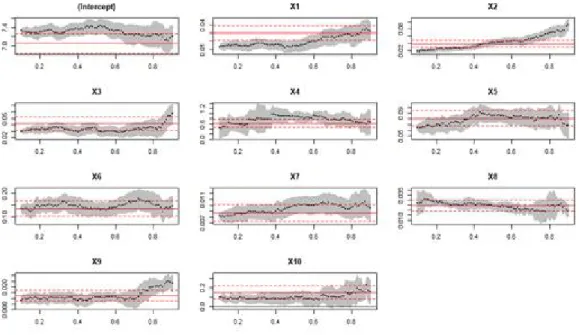
Figure 3.2는 절편과 10개의 독립변수에 대하여 분위수 0.1부터 0.9까지 0.01의 간격으로 구한 계 ᄉ
ᅮ 추정치의 변화를그래프로 보여준다. 그래프에서 회색 음영 처리된 부분은 분위수 회귀분석 결과에 ᄃ
ᅢ한 95% 신뢰구간이며, 수평으로 그은 실선과 점선은각각 최소제곱 추정치와 95% 신뢰구간을나타 ᄂ
ᅢᆫ다. 변수 X1은 τ = 0.4부터 서서히 증가하며, X2는 τ = 0.1인 경우부터 서서히 증가한다. X3은 τ = 0.8까지 비슷한 계수 값을갖다가 그다음부터 가파른 기울기를갖는다. X4와 X5는 τ = 0.1에서 τ = 0.4까지완만하게 증가하다가 그다음부터는조금씩 계수가 감소한다. X6는 분위수의 변화에 따라 ᄌ
ᅳ
ᆼ가하다 감소하고 다시 증가하다 감소하는모습을보이며, X7은대략 분위수가 0.7까지완만하게 증가 ᄒ
ᅡ다가 멈추는양상을보이며, X8은 분위수의 값이 증가함에 따라완만하게 감소하다가 τ = 0.8에서 반 ᄃ
ᅳ
ᆼ하다 다시 감소하는모습을보인다. X9와 X10은 τ = 0.7까지 비슷한 계수 값을갖다가 그 후 기울기 ᄀ
ᅡ 커지는데 X9가 좀더 강하게 증가한다.
3.2. 모형 평가
OLS추정량과 LAD 추정량의 효율성을비교하기 위하여 일반적으로 많이 사용하는모형의 선택기준 ᄋ
ᅵᆫ 평균제곱오차의 제곱근 (root mean square error; RMSE)와 평균절대편차 (mean absolute devia- tion; MAD)를사용하였다. RMSE와 MAD는값이 작을수록바람직하며, 정의는다음과 같다.
RM SE = v u u t
n
X
i=1
( ˆyi− yi)2/n , M AD =
n
X
i=1
| ˆyi− yi|/n.
시
ᆨ에서 ˆyi는 i번째 선수의 로그 연봉 추정량, yi는 i번째 선수의 로그 연봉, n은 전체 선수의 수를 ᄀ
ᅡ
ᆨ각 의미한다. 그리고 Table 3.4는 OLS 모형과 τ = 0.5인 경우인 LAD 모형에 대한 로그 연봉의
Figure 3.2 Visualizing sequences of quantile regressions
RMSE와 MAD 값을보여준다.
Table 3.4 RMSE and MAD of two models
Model log(salary) log(salary) ≤ 8.5 log(salary) ≥ 9.5
RMSE MAD RMSE MAD RMSE MAD
OLS 0.462 0.337 0.296 0.231 0.679 0.515
LAD 0.473 0.327 0.233 0.174 0.747 0.567
ᄌ
ᅥᆫ체 데이터 세트를이용하여 구한 로그 연봉의 OLS 모형과 LAD 모형을비교하면 RMSE 측면에 ᄉ
ᅥ는 OLS 모형, MAD 측면에서는 LAD모형이 약간 우수하나 거의 비슷한 효율성을보인다. 하지만 ᄅ
ᅩ그 연봉이 특정 구간에 속하면 두 가지 측도 측면에서 같은 방향성을보이는데, 로그 연봉이 8.5 이 ᄒ
ᅡ이면 LAD, 로그 연봉이 9.5 이상이면 OLS가 우수함을알 수 있다. Table 3.4는 좀더 자세한 비교 르
ᆯ위해 로그 연봉과 예측된로그 연봉의 차에 절대값을취한 절대연봉차이 (absolute salary difference;
ASD)를이용하여 ASD(LAD)가 ASD(OLS)보다 작은비율을구한 것이다.
Table 3.5 Percentage of ASD (LAD) less than ASD (OLS)
log salary Frequency ASD(LAD)<ASD(OLS) Percentage
log(salary) ≤ 8 126 98 77.8%
8 < log(salary) ≤ 8.5 269 215 80.0%
8.5 < log(salary) ≤ 9 211 119 56.3%
9 < log(salary) ≤ 9.5 162 78 48.1%
9.5 < log(salary) ≤ 10 121 50 41.1%
10 < log(salary) 145 41 28.2%
Table 3.4에서 알 수 있듯이 1034명의 투수 중 LAD모형이 본인 연봉을 좀더 잘 예측한 선수들은모 ᄃ
ᅮ 601명으로 전체 인원의 58.1%이며 반면 OLS 모형이 더 적당한 경우는 41.9%이다. 그리고 로그 연 ᄇ
ᅩ
ᆼ이 9 이하인 선수들은 LAD모형, 로그 연봉이 9를초과하는선수들은 OLS모형이 더 설명력이 뛰어 ᄂ
ᅡ ᆻ다.
4. 결론 보
ᆫ연구에서는한국프로야구 투수들의 연봉을 분위수 회귀모형을이용하여 설명하였다. OLS 회귀모 혀
ᆼ에서는반응변수의 분포를정규분포로 가정하고 오차항의 분산도 등분산이라고 가정하지만, 이 가정 ᄃ
ᅳ
ᆯ이 유효하지 않으면 OLS 회귀모형에서는효율성이 떨어진다. 반면, 분위수 회귀모형은오차항의 분 ᄑ
ᅩ를가정하지 않으며 이상점에 덜 민감하게 반응한다. 또한, 투수들의 연봉에 영향을주는변수들에 대 ᄒ
ᅢ OLS 회귀는모든선수에게 같은정도의 영향을 준다고 가정하지만 분위수 회귀는선수들의 수준에 ᄄ
ᅡ라 다른정도의 영향을 준다고 가정한다. 이런 이유로 보면 분위수 회귀는프로야구 투수들의 연봉 분 ᄉ
ᅥᆨ에 적당하다고 간주된다.
부
ᆫ위수 분석 결과는로그 연봉에 대해 OLS 회귀모형에서는나이, 경험, 연도, 자유계약 여부, 승리의 ᄉ
ᅮ, WAR, 경기 횟수, 세이브횟수, 선발출장 횟수, 소속 팀이 삼성인 여부와 같은 10개의 설명변수가 ᄆ
ᅩ두 유의수준 1%에서 유의하게 나타났다. 반면에 분위수 회귀모형에서는자유계약 여부와 소속 팀이 ᄉ
ᅡ
ᆷ성인 여부를 제외한 변수들은 모두 유의수준 1%에서 유의하게 나타났으며, 고려된분위수 값 10%, 25%, 50%, 75%, 90%에 대해 회귀계수의 대소 여부로 모형의 차이를 알 수 있었다. 분위수 회귀에서 ᄌ
ᅡ유계약 여부와 소속 팀이 삼성인 여부가 유의하지 않은 분위수가 나타난 이유는자유계약에 해당하는 ᄉ
ᅥᆫ수는극소수이고 팀이 삼성이면 영향이큰선수들에게만 투자가 많이된다고 생각할 수 있다. 분위수 ᄋ
ᅴ 변화에 따른 독립변수들의 효과를살펴보면, 나이인 경우는 분위수 0.4부터 서서히 증가하고 경험은 ᄂ
ᅡ이와는상관없이 선형으로 증가했다. 또한, 연도는 분위수 0.8부터 효과가 가파르게 증가하였으며, 승 ᄅ
ᅵ의 수는 분위수 0.4까지완만하게 증가하다 그다음부터는조금씩 하락하는모습을보였으며 선발 출 ᄌ
ᅡᆼ횟수는 분위수 0.7부터 급하게 기울기가 증가하는사실을확인할 수 있었다.
OLS 회귀보다 훨씬 정교한 분석기법인 분위수 회귀는 OLS 회귀보다 큰규모의 데이터가 필요하며 ᄄ
ᅩ 계산과정도 훨씬 복잡하다. 하지만 빅데이터 시대의 도래와 컴퓨터 산업의 눈부신 발전으로 이런 문 ᄌ
ᅦ들이 분위수 회귀모형을사용하는데 이제는걸림돌이 되지는않는다. 본연구에서는 Lee (2017)에서 ᄉ
ᅡ용했던 변수를기반으로 선택된 OLS 회귀모형의 독립변수를 분위수 회귀모형에서도 계속사용하였 느
ᆫ데, 구장 효과, 투수들의 인기도, 누적된투수 기록 등과 같은다양한 변수들을보강한 분위수 회귀분 ᄉ
ᅥ
ᆨ을 수행하거나 분위수 회귀모형에서의 변수선택, 군집분석을 이용한 투수들의 경기력과 분위수 연봉 ᄋ
ᅴ관계 등을고려하면 프로야구 투수들의 경기력과 연봉에 대한 더욱정밀한 결과를얻을수 있을것이 ᄆ
ᅧ 이 부분은향후 연구과제로 남겨둔다.
References
Bollinger, C. and Hotchkiss, J. (2003). The upside potential of hiring risky workers: Evidence from the baseball industry. Journal of Labor Economics, 21, 923-944.
Chao, K. H., Chen, C. Y. and Li, C. S. (2013). A preliminary study of business intelligence in sports: A performance-salary model of player via artificial neural network. International Journal of Electronic Business Management , 11, 13-22.
Geraci, M. (2019). Modelling and estimation of nonlinear quantile regression with clustered data. Compu-
tational Statistics and Data Analysis, 136, 30-46.
Hakes, J. and Sauer, R. (2006). An economic evaluation of the moneyball hypothesis. The Journal of Economic Perspectives, 20, 173-186.
Hills, C. and and Gregory, M. (2014). Professional baseball pitchers’ performance and its effect on salary,https://www.overleaf.com/articles/professional-baseball-pitchers-performance-and- its-effect-on-salary/xndsqqqnrynm\#share
Hoaglin, D. and Velleman, P. (1995). A critical look at some analyses of major league baseball salaries.
The American Statistician, 49, 277-285.
Holmes, P. (2011). New evidence of salary discrimination in major league baseball. Labour Economics, 18, 320-331.
Kim, E. S. (2002). The relationship of game performance and annual salary for Korean professional baseball pitchers. Journal of Korean Sociology of Sport , 15, 95-104.
Kim, J. O., Cho, H. J. and Bang, S. W. (2016). Penalized quantile regression tree. The Korean Journal of Applied Statistics, 29, 1361-1371.
Kim, J. O., Cho, H. J. and Bang, S. W. (2017). Multivariate quantile regression tree. Journal of the Korean Data & Information Science Society, 28, 533-545.
Kim, M. J. and Park, B. J. (2013). Quantile regression approach using R statistical software: Analyzing the effect of non-economic factors on life expectancy at birth. Journal of Industrial Economics and Trade, 37, 33-58.
Kim, Y. H. (2013). A study of determinants of Korean baseball pitchers salary, Unpublished Master Thesis, Sogang University, Seoul.
Koenker, R. and Bassett, G. (1978). Regression quantiles. Econometrica, 46, 33-50.
Lackritz, J. (1990). Salary evaluation for professional baseball players. The American Statistician, 44, 4-8.
Lee, J. T. (2017). Analysis of factors affecting Korean professional baseball pitcher salaries. Journal of the Korean Data & Information Science Society, 28, 317-326.
Lee, J. Y. and Kang, H. M. (2001). The relationship between annual salary and performance of Korean professional baseball pitchers. Journal of Korean Sociology of Sport , 14, 115-124.
Marburger, D. (1994). Bargaining power and the structure of salaries in major league baseball. Managerial and Decision Economics, 15, 433-441.
Oh, K. M. and Lee, J. T. (2003). A model study on salaries of korean pro baseball players using data mining. Journal of Korean Sociology of Sport , 16, 295-309.
Park, H. J. (2009). Quantile regression using asymmetric Laplace distribution. Journal of the Korean Data
& Information Science Society, 20, 1093-1101.
Richey, J. and Jeong, K. H. (2014). Intergenerational economic mobility in Korea using a quantile regression analysis. Journal of the Korean Data & Information Science Society, 25, 715-725.
Vincent, C. and Eastman, B. (2009). Determinants of pay in the NHL: A quantile regression approach.
Journal of Sports Economics, 10, 256-277.
Wiseman, F. and Chatterjee, S. (2010). Negotiating salaries through quantile regression. Journal of Quan-
titative Analysis in Sports, 4, 7.
2020, 31
(4)
,653–662
Salary determinant of Korean professional baseball pitchers using quantile regression †
Jangtaek Lee
1
1Department of Statistics, Dankook University
Received 23 December 2019, revised 14 February 2020, accepted 24 February 2020
Abstract
In this study, Korean professional baseball pitchers’ annual salaries were estimated using pitcher records 2010 to 2018 season. A quantile regression which is more robust to normality and to outliers than least squares regression was used to obtain precise results for effect changes of independent variables in all quartiles. Also, regression quantile plot shows changes of coefficient for age, experience, year, free agent, total wins, wins above replacement, total games, total saves, total starting pitches, and fact that team is Samsung or not when quantile varies continuously. The goodness of fit test for the quantile regression model was satisfied, and the coefficients were different according to quartiles in quantile regression model. Also, the least absolute deviation regression was more effective than ordinary least squares regression for pitchers with lower salaries.
Keywords: Goodness of fit test, Korean professional baseball, pitcher salary, quantile regression.
†
The present research was conducted by the research fund of Dankook University in 2020.
1