논문 2012-50-6-26
3차원 객체 복원을 위한
정규 상관도 기반 다중 시점 배경 차분 기법
( Normalized Cross Correlation-based
Multiview background Subtraction for 3D Object Reconstruction )
팽 경 현*, 황 성 수*, 김 희 동*, 김 수 정*, 유 지 성*, 김 성 대***
( Kyunghyun Paeng, Sung Soo Hwang, Hee-Dong Kim, Sujung Kim, Jisung Yoo, and Seong Dae Kim
ⓒ)
요 약
본 논문에서는 배경과 객체의 색상이 유사한 상황에서 강인한 정규 상관도(Normalized Cross Correlation) 기반 다중 시점 배경 차분 기법을 제안한다. 인위적으로 배경을 구성한 경우가 아닐 경우, 다중 시점 영상의 배경 영상에서 객체로 인해 가려 지게 되는 영역들은 서로 다른 색상을 가지고 있을 확률이 높다. 그러나 객체의 등장으로 인해 이러한 영역들은 서로 유사한 색상을 가지게 된다. 이에 기반하여 본 논문은 GoNCC(Graph of Normalized Cross Correlation)을 제안한다. GoNCC는 임의 시점 영상의 한 화소와 에피폴라 제약조건 관계에 있는 인접 영상 내 화소와 해당 화소와의 정규 상관도 값의 분포를 의미한 다. 제안하는 다중 시점 배경 차분 기법은 현재 영상의 GoNCC와 배경 영상의 GoNCC를 비교함으로써 이루어진다. 계산량을 줄이기 위해 다중 시점 배경 차분 기법을 모든 화소에 적용하지 않고 간단한 단일 시점 배경 차분 기법으로 판단하기 어려운 영역에 대해서만 제안 방법을 수행한다. 실험 결과 단순한 단일 시점 배경 차분 기법에 비하여 매우 우수한 성능을 보였고, 기 존의 다중 시점 배경 차분 기법에 비해서도 보다 정확하게 객체 영역을 검출하는 것을 확인하였다.
Abstract
In this paper, we propose a normalized cross correlation(NCC)-based multiview background subtraction method which is robust when an object and background have similar color. When the background of the capturing environment is not artificially composed, the regions in the background images which would be occluded by an object tends to have difference colors. The colors of those regions, however, becomes similar when an object enters the capturing environment. Based on this assumption, this paper proposes a concept of GoNCC(Graph of Normalized Cross Correlation). GoNCC is the distribution of NCC between a pixel in an image and pixels related by epipolar constraints with the pixel. The proposed multiview background subtraction method is performed by comparing GoNCC of the current images with the background images. To reduce computational complexity, we perform multiview background subtraction only to the pixels undetermined by single view background subtraction. Experimental results show that the proposed method is more robust to color similarity between an object and background than a single-view background subtraction method and a previous multiview background subtraction method.
Keywords: 3D object reconstruction, foreground extraction, multiview background subtraction
* 학생회원, ** 정회원, 한국과학기술원 전기 및 전자공학과 (Dept. of Electrical Engineering, KAIST)
※ 이 논문은 2011년도 정부(교육과학기술부)의 재원으로 한국연구재단의 지원을 받아 수행된 연구임 (No.2011-0016298).
ⓒ Corresponding Author(E-mail: [email protected]) 접수일자 2013년2월23일, 수정완료일 2013년5월21일
Ⅰ. 서 론
최근 3차원 영상에 대한 관심이 증가함에 따라 다중 시점 영상 기반 3차원 객체 복원 기법에 대한 연구가 활발히 진행되고 있다[1∼2]. 다중 시점 영상 기반 3차원 객체 복원 기법이란 서로 다른 시점을 가진 여러 개의 카메라들을 이용하여 객체를 촬영한 뒤, 촬영된 영상들 과 각 카메라들의 촬영 정보들을 이용하여 해당 객체에 대한 3차원 정보를 추정하는 기법을 말한다. 이러한 기 법들을 이용하면 실제 존재하는 객체에 대한 3차원 정 보를 손쉽게 획득할 수 있기 때문에 적은 비용으로도 보다 현실감 있는 3차원 콘텐츠를 제작할 수 있다는 장 점이 있다.
다중 시점 영상 기반 3차원 객체 복원에 있어서는 Shape-from-Silhouette(SFS)이 널리 사용되고 있다.
SFS는 복원하고자 하는 객체의 다중 시점 실루엣과 각 실루엣 영상의 카메라 정보를 통해 해당 객체의 3차원 복원을 수행하는 기법이다[3]. SFS를 통한 객체 복원은 해당 객체의 실루엣을 3차원 공간에 역투영한 후 이를 통해 생성된 3차원 뿔(cone)들의 교집합을 계산하며, 이 러한 과정으로 계산된 3차원 객체를 해당 객체의 비주 얼 헐(visual hull)이라고 한다. 특정 객체의 비주얼 헐 은 해당 객체의 대략적인 형태를 반영하기 때문에 이것 만을 이용하여 해당 객체의 3차원 정보로서 활용되기도 하고, 종종 정교한 객체 복원과정의 초기 정보로서 활 용되기도 한다[4]. 그러므로 SFS를 활용한 3차원 객체 복원을 위해서는 복원하고자 하는 객체의 다중 시점 실 루엣 영상을 정확하게 추출하는 과정이 필수적이라고 할 수 있다.
다중 시점 영상에서 실루엣 영상 추출을 수행하기 위 해 제안된 기법들은 크게 1) 단일 시점 배경 차분을 통 한 객체 추출 기법, 2) 다중 시점의 정보를 사용한 객체 추출 기법[10∼12]으로 나눌 수 있다. 단일 시점 배경 차분 기법은 객체가 영상 내에 존재하지 않는 기간 동안 각 시점에서 촬영된 배경 영상들에 대한 정보를 획득하여 저장해 두고, 실제 객체가 존재하는 3차원 장면에 대한 다중 시점 영상들을 획득하여 대응되는 시점 영상들 간 의 밝기 및 색상 변화 등을 검출하여 객체들을 배경으 로부터 분리해내는 매우 단순한 방법이다[5]. 이에 반해 다중 시점 객체 추출 기법은 각 영상 내 객체 추출을 동시에 수행한다. 이러한 기법은 추출된 객체 영역을
통해 3차원 객체를 복원하는 과정과 이를 통해 복원된 객체를 활용하여 다시 객체 영역을 추정하는 반복 수행 과정을 통해 객체를 추출한다[10∼12].
기존에 제안된 다수의 3차원 객체 복원 기법들에서 는 주로 단일 시점 배경 차분 기법을 활용하여 객체를 추출하였다[6∼9]. 그 이유는 단일 시점 배경 차분 기법 만으로도 객체들을 잘 분리해낼 수 있을 정도로 객체들 의 색상과 매우 상이한 색상을 가진 인위적인 배경을 사용하였기 때문이다. 그러나 단일 시점 배경 차분 기 법은 원천적으로 배경과 전경의 색상이 유사할 경우 정 확한 객체 추출이 어렵다는 단점을 가지고 있다.
본 논문에서는 이러한 단점을 계산량 증가를 최소화 하면서 극복하고자 하였다. 이를 위해 기존의 다중 시 점 객체 추출 기법과 유사하게 인접 시점 영상을 활용 하는 방안을 제안하였다. 기존의 다중 시점 객체 추출 기법은 계산량이 많은 3차원 객체 복원 과정을 반복 수 행하여 단일 시점 객체 추출에 비해 많은 계산량을 필 요로 하였다. 제안 기법은 이러한 기법과 달리 본 논문 에서는 계산량이 적은 것으로 알려진 배경 차분 기법을 다중 시점 영상에 적용하여 단일 시점 배경 차분 기법 의 단점을 해결하였다.
그림 1은 본 논문에서 제안하는 다중 시점 배경 차분 기법의 개념을 나타낸 것이다. 그림 1과 같이 총 3개의 카메라를 통해 하나의 객체를 촬영한다고 가정하자. 인 위적으로 배경을 구성한 경우가 아닐 경우, 배경 영상 에서 객체로 인하여 가려지게 되는 영역들의 색상 유사 도는 매우 낮을 가능성이 높다. 그러나 객체가 있는 영 상들에서 이러한 가려진 영역에서의 색상은 유사할 가 능성이 높다. 이 점에 착안하여, 제안 기법에서는 단일 시점 배경 차분 기법만으로 배경인지 객체인지를 판별 하기 어려운 영역에서 인접시점 영상에서 해당 영역 간 의 색상 유사도를 관측하여 객체 영역 진위를 판단한 다. 이러한 과정을 통해 제안 기법은 단일 시점 배경 차 분 기법이 가지는 단점을 개선한다.
위의 가정에 근거하여 제안 기법은 다중 시점 영상에 대해 각 시점 마다 단일 시점 배경 학습을 수행한다. 아 울러 인접 시점 영상 간 색상의 유사도 분포를 계산하 는 다중 시점 배경 학습을 수행한다. 인접 시점 영상 간 색상의 유사도를 측정하기 위해서는 조명 변화에 강인 한 것으로 알려진 정규 상관도 (Normalized Cross Correlation)를 활용한 GoNCC(Graph of Normalized
그림 1. 객체의 유무에 따른 영상에서의 차이
Fig. 1. Difference in the presence or absence of object.
Cross Correlation)을 제안하였다. GoNCC는 특정 시점 영상의 한 화소와 에피폴라 제약조건 관계에 있는 인접 영상 내 화소와 해당 화소와의 정규 상관도 (Normalized Cross Correlation)값의 분포를 의미한다.
제안 기법은 GoNCC에 기반을 둔 학습 정보를 통해 다 중 시점 배경 차분 기법을 수행함으로써, 단일 시점 배 경 차분 기법으로 판별이 어려운 영역에 대해 객체 추 출의 정확도를 높였다.
한편 제안 기법과 유사한 접근 기법이 M. Toyoura et al.[13]에 의해 제안되었다. 그러나 제안 기법은 기존 기법과 달리 인위적인 배경 구성을 필요로 하지 않으며 반복적인 3차원 객체 복원 연산을 수행하지 않는 점에 서 차별성을 지닌다.
제안 기법은 단일 시점 배경 차분 기법 및 M.
Toyoura et al.[13]이 제안한 다중 시점 배경 차분 기법 에 비해 물체와 객체의 색상이 유사한 상황에서 정확한 객체 추출을 수행할 수 있다. 또한 M. Toyoura et al.[13]
의 기법 및 기타 다중 시점 객체 추출 기법과 달리 많 은 계산량을 요구하는 3차원 객체 복원을 반복적으로 수행하지 않는다. 마지막으로 인위적인 배경 구성이 아 닌 자연적인 배경에서 활용이 가능하므로, 제안 기법을 통해 다중 시점 영상 기반 3차원 콘텐츠 제작을 보다 용이하게 할 수 있을 것이다.
본 논문의 구성은 다음과 같다. Ⅱ장에서는 제안하는 기법의 개요와 GoNCC에 대해서 설명하고, Ⅲ장에서
GoNCC를 활용한 배경 학습 기법, Ⅳ장에서는 전경 추 출 기법, Ⅴ장에서는 제안 기법을 적용한 결과를 분석 한다. Ⅵ장에서 결론을 맺는다.
Ⅱ. 제안 기법의 개요
1. 개요
3차원 복원을 위하여 사용되는 카메라들은 총 N개이 며, 카메라 교정(camera calibration)과 영상 보정(image rectification) 과정은 이미 객체 추출 과정 이전에 수행 되었고, 촬영 중 카메라의 이동 및 배경의 변화가 없다 고 가정한다. 또한 입력 영상의 색상은 YCbCr색상 좌표 계로 표현되었다고 가정한다.
그림 2는 본 논문에서 제안하는 기법의 개요를 나타 낸 것이다. 제안 기법은 총 3단계의 과정을 통하여 객 체를 추출하며 각 단계는 1) 단일 시점 및 다중 시점 배경 학습 단계, 2) 단일 시점 배경 차분 단계, 그리고 3) 다중 시점 배경 차분 단계로 구성되어 있다.
단일 시점 및 다중 시점 배경 학습 단계에서는 객체 존재 영역(Object Existence Region) 들의 계산하고, 각 시점에 대한 배경영상 정보를 추정하고, 객체 존재 가 능 영역에서의 GoNCC를 측정한다. 일반적으로 SFS를 활용하여 3차원 복원을 할 때에는 복원하고자 하는 객 체가 어떠한 카메라에서도 온전하게 투영되어야 한다.
이러한 가정을 통해 객체가 존재할 수 있는 객체 존재
그림 2. 제안하는 기법의 개요
Fig. 2. An overview of the proposed algorithm.
가능 영역을 계산한 후, 그 영역 내에서만 배경 학습 및 객체 추출을 수행하여 연산량을 줄인다. 단일 시점 배 경 학습은 각 화소 당 촬영 초기 Cb, Cr성분의 평균으 로, 다중 시점 배경 학습은 각 화소 당 GoNCC로 이루 어진다.
단일 시점 및 다중 시점 배경 차분 단계에서는 각 시 점 영상에 대해 단일 시점 배경 차분 기법을 수행하며, 이를 통하여 확연히 구분되는 객체 존재 영역을 추출한 다. 단일 시점 배경 차분 기법을 통해 판별이 어려운 미 확정 영역에 대해서는 각 시점 영상의 인접 시점 영상 들을 이용한 다중 시점 배경 차분 기법으로 객체 영역 을 추출한다.
2. GoNCC의 정의
본 논문에서는 다중 시점 배경 학습을 위해 GoNCC 를 제안한다. GoNCC는 각 화소마다 계산되며, 이는 에 피폴라 제약조건 관계에 있는 인접 영상 내 화소와 해 당 화소와의 정규 상관도 값으로 이루어진다. 각 화소 와 에피폴라 제약조건 관계에 있는 화소 간의 정규 상 관도를 모두 학습하는 이유는 다음과 같다. 첫째, 출현 할 객체가 촬영 공간 내 어디에나 위치할 수 있기 때문 이며, 둘째, 해당 화소와 정확하게 대응되는 인접 영상 내 화소를 찾는 것은 쉽지 않기 때문이다. 따라서 에피 폴라 제약 조건 관계에 있는 화소의 전반적인 정규 상 관도 차이의 분석을 통해 객체의 출현 유무를 판단하는
것이 보다 적은 오차를 발생시킨다.
삼차원 장면 S를 k번째 카메라 로 촬영한 컬러 영상을 이라고 하고, 이 영상의 성분을
, 성분을 , 성분을
라고 하자. 그리고 카메라 와 공간적으 로 인접한 카메라들의 집합을 라고 하자. 이때 카메라 로 촬영한 영상의 위치에 있는 화소에 대한 GoNCC는 인접한 카메라에 대하여 정의되며, 만 약 ∈이라면 해당 카메라에 대한 GoNCC를
라고 표시하고 수식 (1) 같이 정의 한다.
≡
(1)
여기서 은 두 화소 간의 정규 상관도를 의미하고,
는 영상 에서 화소 에 대응하 는 에서의 에피폴라 선위에 있는 한 점을 뜻한다. 정규 상관도의 계산은 해당 화소를 중심으로 하여 × 마스크 내부의 화소 값을 참조하여 이루어 졌다. 또한 본 논문에서는 카메라 의 principal axis 를 기준으로 좌, 우에 위치하는 카메라를 카메라 에 인접한 카메라로 정의하여 각 화소마다 좌, 우 시점에 대한 2개의 GoNCC를 획득하게 된다.
III. 단일 시점 및 다중 시점 배경 학습
1. 객체 존재 영역 설정
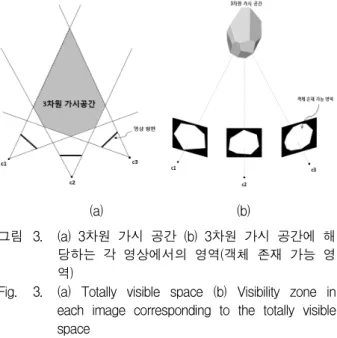
이 단계에서는 먼저 배경 학습 및 객체 추출 과정에 필요한 연산 량 줄이기 위하여 W. Lee et al.[12] 이 제 안한 방법을 이용하여 각 시점 영상들에서의 객체 존재 가능 영역을 설정한다. 이를 위해 먼저 모든 카메라의 영상 평면을 3차원 공간에 역투영시킨 후, 이들의 교집 합을 구하여 모든 카메라에서 관찰되는 3차원 공간을 계산한다. 이러한 공간을 본 논문에서는 3차원 가시 공 간(Totally Visible Space)이라고 명명한다.
복원 대상 객체가 어떠한 카메라에서도 온전하게 투 영되었다고 가정하면, 객체는 3차원 가시 공간 영역 내 부에 존재하여야 한다. 따라서 3차원 가시 공간 영역을 각 카메라로 투영하여 그림 3과 같이 각 영상별로 객체 존재 영역을 설정한다. 추후 수행되는 모든 연산은 각 영상의 객체 존재 가능 영역 내부에서만 수행된다.
(a) (b)
그림 3. (a) 3차원 가시 공간 (b) 3차원 가시 공간에 해 당하는 각 영상에서의 영역(객체 존재 가능 영 역)
Fig. 3. (a) Totally visible space (b) Visibility zone in each image corresponding to the totally visible space
2. 단일 시점 배경 학습
단일 시점 배경 학습은 화소 단위로 이루어지며, 조 명의 변화 등으로 발생되는 밝기의 변화에 대한 영향을 최소화하기 위해 YCbCr색상 공간에서 Y성분은 제외하 고 Cb와 Cr성분에 대해서만 배경 학습을 수행하였다.
배경 영상에 대한 정보를 얻기 위하여 개의 프레임 영상들을 이용하여 이들의 평균값들을 이용하여 배경 영상에 대한 학습을 하였다. 객체는 없고 배경만 있는
장면을 번째 카메라 로 촬영한 영상 들 중 번째 영상의 성분을
, 성분을
라고 하자. 촬영 중 카메라의 이동이나 배경의 변화가 없다고 가정하고 학습된 배경영상
와
는 수식 (2)와 같이 계산 된다.
(2)
3. 다중 시점 배경 학습
카메라 교정이 끝난 다중 시점 간에는 에피폴라 제약 조건이 존재하게 된다[14]. 따라서 3차원 공간상의 한 영 역이 특정 시점의 영상에 투영된 경우, 해당 영역에 대 응되는 영역은 인접 영상 내 에피폴라 라인 상에 존재 하게 된다. 또한 앞서 언급한 바와 같이 배경 영상간에 는 밝기 값의 상관도가 낮으나, 객체의 등장으로 인해 인접 시점 영상 간 밝기 값의 상관도가 높아지게 된다.
이러한 특성을 활용하여 에피폴라 제약 조건 관계에 있 는 인접 영상 내 화소간의 상관도, 즉, GoNCC를 객체 등장 이전에 계산한다. 이때 GoNCC의 계산은 각 화소 마다 이루어지며, 이미 언급한 바와 같이 객체 존재 가 능 영역 이외의 영역에 속하는 화소의 GoNCC는 계산 하지 않는다. 이후 객체 추출 단계에서는 사전에 계산 된 GoNCC를 객체의 등장으로 인해 변화하는 GoNCC 와 비교하여 객체 추출을 수행한다.
각 화소 당 GoNCC를 모두 저장하게 될 경우, 객체 촬영에 사용되는 카메라 수 및 영상의 해상도의 증가에 따라 GoNCC를 저장하기 위해 필요한 저장 공간이 기 하급수적으로 증가하게 된다. 과도한 메모리의 사용을 줄이기 위해서 본 논문에서는 정규 상관도 계산을 위해 각 영상 당 영상의 색상 정보 및 각 화소를 중심으로 하여 정규 상관도 계산에 사용되는 마스크 내부에 존재 하는 화소에 대한 평균과 분산 값을 저장하였다. 저장 된 데이터는 객체 검출 과정에서 배경 화소에 대한 GoNCC 값이 필요할 때 활용된다.
Ⅳ. 전경 추출 기법
1. 단일 시점 배경 차분
배경 학습을 수행 한 후, 영상 내 객체가 출현하게 되면, 각 시점 영상 당 단일 시점 배경 차분 기법을 먼 저 수행한다. 이를 위해 Cb, Cr채널에 대해서 학습된 배 경 영상과 현재 영상간의 색상 값 차이의 절대 값을 계 산한다. 이를 통해 생성된 차분 영상에 대해 임계화 작 업을 수행한다. 배경 영상과 현재 영상과의 색상 값의 차이가 사전에 정의한 문턱치 값을 초과할 경우 해당 영역을 객체로 판단하며, 이때 문턱치의 값을 충분히 크게 설정하여 색상 값의 변화가 큰 영역만을 확실한 객체 영역으로 추출한다. 또한 각 채널에 대해 모두 문 턱치 값을 초과할 경우에 한하여만 확실한 객체영역으 로 판단한다. 하나의 채널이라도 차분 영상의 값이 문 턱치 값 이하일 경우, 단일 시점 배경 차분으로는 판단 이 어려운 미확정 영역으로 설정한다.
2. 다중 시점 배경 차분
다중 시점 배경 차분 기법은 단일 시점 배경 차분 기 법만으로 오인식하기 쉬운 미확정 영역에 대해 적용된 다. 이를 위해 미확정 영역에 속하는 화소에 대해서 각 화소별 학습된 GoNCC와 현재 영상에서의 GoNCC의 차이를 비교한다. 카메라 로 촬영한 영상 내 좌표 값 이 인 화소의 현재 시점의 GoNCC의 i번째 성분 을 , 그리고 해당 화소의 학습된 GoNCC의 i번 째 성분이 라고 하자. 그러면 두 GoNCC간 의 차이 값
은 수식 (3)을 통해 계산된다.
max
(3)
여기서 는 다음과 같다.
i f
i f ≤
(4)
수식 (4)에서 확인할 수 있듯이 값은
가
보다 클 경우에만 계산된다. 이는 그림 1을 통해 설명할 수 있다. 그림 1의 왼쪽 영상에서 보는 것과 같이, 배경 학습 단계에서는 객체가 등장하 게 될 영역에서 서로 다른 밝기 값을 띄고 있을 확률이 높다. 그러므로 학습 단계에서 객체가 등장하게 될 영 역의 GoNCC의 값이 낮다. 그러나 이러한 영역들은 객 체의 등장으로 인해 유사한 밝기 값을 가지게 되므로 GoNCC의 값은 높아지게 된다. 즉, GoNCC의 성분 중 에서 그 값이 낮았다가 높아지는 경우, 객체가 존재할 확률이 높다. 이러한 가정에 기반을 두어 객체 영역이 라면
가
보다 클 것이라 판단하여 이러한 경우에 대해서만
를 계산한다.
또한 수식 (4)에서 확인할 수 있듯이 가
보다 큰 성분의 개수로 나누어 주는 정규화 과정을 거치게 된다. 또한 본 논문에서는 각 카메라 당 2대의 카메라를 해당 카메라의 공간적으로 인접한 카메 라로 정의하여 각 화소마다 2개의 GoNCC를 획득하게 된다. 따라서 최종적인
는 2개의 GoNCC를 통 해 획득한 값의 평균을 취하였으며 그 결과 0에서 1사 이의 값을 가지게 된다.
수식 (3)과 수식 (4)를 통해 계산된
는 실험 적으로 정의된 문턱치 값을 통해 배경과 전경으로 분류 된다. 이러한 작업을 미확정 영역에 속하는 모든 화소 에 적용하여 다중 시점 배경 차분을 수행한다. 마지막 으로 기존의 단일 시점 배경 차분을 통해 전경으로 분 류된 영역과 다중 시점 배경 차분을 통해 전경으로 분 류된 영역을 통합하여 최종적인 전경 영역을 획득한다.
Ⅴ. 실 험 결 과
본 논문에서는 제안 기법의 성능을 분석하기 위해 Kung-Fu Girl data set[15]을 사용하였다. 제안 기법의 적용을 위해서는 객체가 포함되지 않은 다중 시점 배경 영상이 필요하며, 그림 1을 통해 설명한 바와 같이 시 점에 따른 배경의 변화가 존재하여야 한다. 이러한 가 정은 임의의 배경 설정을 하지 않는 자연 배경 상황에 부합되므로, 제안기법을 사용하면 향후 영상 기반 3차 원 객체 복원 시스템 구축을 용이하게 할 수 있다. 그러 나 현존하는 다중 시점 영상 dataset 대부분이 단일 색
그림 4. 실험에 사용한 Kung-Fu Girl 영상(1번째 행)과 정규 상관도 맵(2번째 행), 제안된 기법의 결과(3번째 행), M.
Toyoura et al.[13]의 기법의 결과(4번째 행)
Fig. 4. Kung-Fu Girl data set [15] (1st row), normalized cross correlation map (2nd row), results of the proposed method (3rd row), results of M. Toyoura et al.[13]’s method (4th row).
상의 배경을 설치하는 경우가 많아 이러한 조건을 만족 시키지 않았다. 반면 Kung-Fu Girl data set은 이러한 조건을 만족하여 제안 기법의 성능을 평가하기 위해 Kung-Fu Girl data set만을 활용하였다. Kung-Fu Girl data set은 총 25개의 시점에서 생성된 영상을 제공하 는데, 본 논문에서는 이 중 객체를 전 방향으로 감싸고 있는 8개의 시점 영상을 활용하여 제안 기법의 성능을 실험하였다. 그림 4의 1번째 행은 실험에 사용한 영상 중 일부를 나타낸다.
제안 기법의 성능을 평가하기 위해 제안 기법과 기존 기존기법의 성능을 정성적, 정량적으로 비교하였다. 먼 저 그림 4의 두 번째 행은 제안 기법을 통해 생성한 정 규 상관도 맵을 나타낸다. 제안 기법을 통해 영상 내 객 체를 추출하게 되면, 단일 시점 배경 차분 기법을 통해
미확정 영역으로 설정된 각 화소는 수식 (4)를 통해 하 나의 값을 가지게 된다. 이러한 값을 시각적으로 확인 하기 위해 영상으로 표현하였으며, 이를 정규 상관도 맵이라 명명하였다. 정규 상관도 맵을 생성에 있어서는 현재 영상과 학습된 배경 영상간의 GoNCC 차이가 적 을수록 푸른 값을, 차이가 클수록 붉은 색에 가깝도록 표현하였다.
본문에서 설명한 바와 같이 단일 시점 차분 기법에서 확실한 객체 영역으로 판단된 부분과 객체 존재 가능 영역 외부에 대해서는 현재 영상과 학습된 배경 영상간 의 GoNCC를 계산하지 않았다. 때문에 이러한 영역은 가장 낮은 값인 푸른 영역으로 나타나게 된다. 또한 단 일 시점 배경 차분 기법으로 판별이 어려운 미확정 영 역 중 객체 영역에 해당하는 부분이 배경 영상과 현재
View 1 2 3 4 5 6 7 8 단일 시점 차분 기법 79.02 83.74 80.01 70.43 78.93 84.93 84.68 85.02 Toyoura et al.[13]의 기법 85.36 86.90 84.19 82.78 85.32 87.08 88.63 87.93 제안 기법 99.69 99.74 100.00 98.40 100.00 99.72 99.97 99.51 표 1. 단일 시점 배경 차분 기법, M. Toyoura et al.[13]의 기법, 그리고 제안 기법을 사용한 전경 추출 성능 (단위: %) Table 1. Foreground extraction results using single-view background subtraction, M. Toyoura et al.[13]’s method, and the
proposed method (unit: %)
영상의 GoNCC의 차이가 크다는 것을 확인할 수 있다.
이를 통해 단일 시점 배경 차분 기법에서 추출하기 힘 든 전경 영역을 제안 기법을 통해 효율적으로 추출할 수 있음을 알 수 있다.
또한 그림 4의 3번째 행은 제안 기법을 실험 영상에 적용한 결과를, 4번째 행은 M. Toyoura et al.이 제안한 기법을 적용한 결과를 나타낸다. 그림에서 나타나듯이 본 논문에서 제안한 기법이 기존 기법에 비해 해당 객 체를 배경으로부터 성공적으로 추출하였다. 이를 통해 제안 기법은 자연 배경의 환경에 대해서도 성공적으로 객체를 추출할 수 있음을 알 수 있다.
표 1은 단일 시점 배경 차분 기법과 M. Toyoura et al.[13]이 제안한 기법과의 정량적 성능 비교의 결과를 나 타낸다. 여기서 표 1에 표기된 1∼8은 실험에 사용한 각 카메라의 시점을 의미한다. 전경 추출 성능 평가를 위해서는 객체 영역을 객체 영역으로 올바르게 검출하 는 비율을 계산하였다. 즉, 2차원 영상 내에서의 실제 전경 영역 대비(Kung-Fu Girl dataset은 객체 추출에 대한 검증자료(ground truth)를 제공한다) 객체 추출을 통해 전경으로 판단된 영역의 비율을 계산하였으며, 3 차원 복원 결과는 고려하지 않았다.
본 논문에서는 이러한 비율이 높을수록 객체 추출이 성공적으로 이루어졌다고 판단하였으며, 배경 영역을 객체 영역으로 오검출 하는 것에 대한 페널티는 부여하 지 않았다. 그 이유는 추출된 실루엣을 통해 계산되는 본 논문에서는 이러한 비율이 높을수록 객체 추출이 성 공적으로 이루어졌다고 판단하였으며, 배경 영역을 객 체 영역으로 오검출 하는 것에 대한 페널티는 부여하지 않았다. 그 이유는 추출된 실루엣을 통해 계산되는 비 주얼 헐이 일반적인 비주얼 헐이 가지는 특성, 즉 실제 객체를 항상 감싸고 있다는 특징을 유지하는 것이 중요 하기 때문이다. 표 1에서 보듯이 본 논문에서 제안한 기법이 약 99%의 정확도로 타 기법들과 더 우수한 성 능을 나타내는 것을 확인할 수 있었다.
(a) (b)
그림 5. 추출된 실루엣을 통해 생성한 비주얼 헐 (a) 제 안 기법을 통해 추출된 실루엣을 사용한 결과 (b) M. Toyoura et al.[13] 의 기법으로 추출된 실 루엣을 사용한 결과
Fig. 5. Visual hulls computed using the extracted silhouettes (a)Silhouettes generated by the proposed method (b)Silhouettes generated by M.
Toyoura et al.[13]
마지막으로 제안 기법 및 M. Toyoura et al.[13]이 제 안한 기법을 통해 추출된 객체 영역 정보를 통해 비주 얼 헐을 생성하였다. 그림 5(a)와 그림 5(b)는 각각 본 논문에서 제안한 기법과 기존 기법으로 추출된 결과를 이용하여 계산된 비주얼 헐을 나타낸다. 비주얼 헐 계 산을 위해서는 S. Kim et al.[16]이 제안한 기법이 사용 되었다. 그림 5(b)가 나타내듯이 객체 영역을 배경 영역 으로 오 검출하는 비율이 높을수록 부정확한 3차원 복 원이 이루어지게 된다. 반면 제안 기법은 실제 전경의 영역의 대부분을 올바로 추출하였으므로 생성된 비주얼 헐이 실제 객체의 기하 정보를 잘 반영하였다. 이러한 결과에서 나타나듯이 제안된 기법은 3차원 복원을 위한 전경 추출 기법으로서 적합하다고 볼 수 있다.
Ⅵ. 결 론
본 논문에서는 3차원 객체 복원을 위한 다중 시점 전 경 추출 기법을 제안하였다. 영상 내의 배경과 전경의 색상이 비슷할 경우, 단일 시점 배경 차분 기법만으로 는 성공적인 객체 추출을 수행할 수 없다. 이러한 단점 을 보완하기 위해 제안 기법은 인접 영상의 정보를 활 용하는 기법을 제안하였다. 이를 위해 GoNCC를 제안 하였고, 학습된 배경 영상과 현재 영상에서의 각 화소 별 GoNCC의 차이에 기반을 둔 전경 추출을 수행하였 다. 이러한 과정을 통해 제안 기법은 단일 시점 배경 차 분 기법으로 판단하기 어려운 영역을 배경과 전경의 영 역으로 보다 정확하게 구분할 수 있었다.
제안 기법은 영상 기반 객체 복원 시스템 구축에 필 수적인 전경 추출을 정확하게 수행하며, 이를 통해 영 상 기반 객체 복원 시스템을 통해 생성되는 3차원 콘텐 츠의 화질을 높이는 데에 기여할 수 있다. 또한 제안 기 법은 인위적인 배경 설치 없이 전경 추출을 수행할 수 있다. 이는 영상 기반 객체 복원 시스템의 구축을 용이 하게 하므로 제안기법은 보다 많은 3차원 콘텐츠 생성 에도 이바지 하게 될 것이다.
REFERENCES
[1] E. Stoykova, A. A. Alatan, P. Benzie, N.
Grammalidis, S. Malassiotis, J. Ostermann, S.
Piekh, V. Sainov, C. Theobalt, T. Thevar, and X. Zabulis, “3-D Time-Varying Scene Capture Technologies-A Survey,” IEEE Trans. Circuits
Syst. Video Tech., Vol.17, No.11, pp.1568-1586,
November, 2007.[2] 김한성, 손광훈, “다중 스테레오 카메라를 이용한 3차원 모델링 시스템,” 대한전자공학회 논문지 제 44권 SP편 제 1호, 1-9쪽, 2007년
[3] A. Laurentini, “The Visual hull Concept for Silhouette-based Image Understanding,” IEEE
Trans. Pattern Anal. and Machine Intell., Vol.
16, No.2, pp.150-162, Feb., 1994.
[4] Y.Furukawa and J.Ponce, “Carved Visual Hulls for Image-based Modeling,” in Proc. European
Conf. Computer Vision, pp.564-577, 2006.
[5] M.Piccardi, “Background Subtraction Techniques:
A Review,” in Proc. IEEE Int. Systems, Man
and Cybernetics, Oct. 2004.
[6] K.M. Cheung, T. Kanade, “A Real Time System
for Robust 3D Voxel Reconstruction of Human Motions,” in
Proc. Computer Vis. Pattern Recognition, 2000.
[7] T. Matsuyama, X. Wu, T. Takai and S.
Nobuhara, “Real-time 3D Shape Reconstruction, Dynamic 3D Mesh Deformation, and High Fidelity Visualization for 3D Video,” Computer
Vision and Image Understanding
Vol.96 pp.393-434, 2004.[8] O. Grau, T. Pullen and G.A. Thomas, “A Combined Studio Production System for 3-D Capturing of Live Action and Immersive Actor Feedback,” IEEE Trans. Circuits Syst. Video
Tech., Vol.14, No.3, pp.370-380, March, 2004.
[9] J. starck, A. Maki, S. Nobuhara, A.Hilton and T.
Matsuyama, “The Multiple-Camera 3-D Production Studio,” IEEE Trans. Circuits. Syst.
Video Tech., Vol.19, No.6, pp.856-869, June, 2009.
[10] G. Zeng and L. Quan, “Silhouette Extraction from Multiple Images of an Unknown Background,” in Proc. Asian Conf. Computer
Vision, Jan. 2004.
[11] T. Feldmann, B. Scheuemann, B. Rosenhahn, A.
Worner,“N-View Human Silhouette Segmentation in Cluttered, Partially Changing Environments,”
Lecture Notes in Computer Science, Volume
6376, Pattern Recognition, pp.363-372, 2010.[12] Wonwoo Lee, Woontack Woo and E. Boyer,
“Silhouette Segmentation in Multiple Views,”
IEEE Trans. Pattern Anal. and Machine Intell.,
Vol. 33, No. 7, pp.1429-1441, July, 2011.[13] M. Toyoura, M. Iiyama, K. Kakusho, and M.
Minoh, “Silhouette Extraction with Random Pattern Backgrounds for the Volume Intersection Method,” in Proc. 3-D Digital Imaging and
Modeling, pp.225-232, Aug. 2007.
[14] R. Hartley and A. Zisserman, “Multiple View Geometry in Computer Vision,”
Cambridge University Press, 2000.
[15] “Kung-Fu Girl data set”, http://www.mpi-inf.
mpg.de/departments/irg3/kungfu/
[16] S. Kim, H.D. Kim, W.J. Kim, S.D. Kim, “Fast Computation of a Visual Hull,” in Proc. Asian
Conf. Computer Vision, 2010, pp. 2075–2084.
저 자 소 개 팽 경 현(학생회원)
2011년 한국과학기술원 전기 및 전자공학과 학사 졸업.
2011년~현재 한국과학기술원 전기및전자공학과 석박통합과정.
<주관심분야 : 컴퓨터 비전, 패턴인식>
황 성 수(학생회원)
2008년 한동대학교 전산전자공학 부 학사 졸업.
2010년 한국과학기술원 전기및전 자공학과 석사 졸업.
2010년~현재 한국과학기술원 전 기및전자공학과 박사과정.
<주관심분야 : 컴퓨터 비전, 3차원 영상 압축>
김 희 동(학생회원)
2005년 부산대학교 전기 및 전자공학과 학사 졸업.
2007년 한국과학기술원 전기 및 전자공학과 석사 졸업.
2007년~현재 한국과학기술원 전기및전자공학과 박사과정.
<주관심분야 : 영상처리, 컴퓨터비전>
김 수 정(학생회원)
2005년 경북대학교 전자공학 및 컴퓨터과학과 학사 졸업.
2011년~현재 한국과학기술원 전기및전자공학과 석박통합과정.
<주관심분야 : 영상처리, 컴퓨터비전>
유 지 성(학생회원) 2010년 한국과학기술원 전기및전자공학과 학사 졸업.
2010년~현재 한국과학기술원 전기및전자공학과 석박통합과정.
<주관심분야 : 컴퓨터 비전, 패턴인식>
김 성 대(정회원)-교신저자 1977년 서울대학교 전자공학과 학사 졸업.
1979년 한국과학기술원 전기및전자공학과 석사졸업.
1983년 프랑스 ENSEEIHT 전자공학과 박사 졸업 2011년 대한전자공학회 회장
2012년~현재 한국공학 한림원 회원
1984년~현재 한국과학기술원 전기및전자공학과 교수
<주관심분야 : 영상처리, 컴퓨터비전>