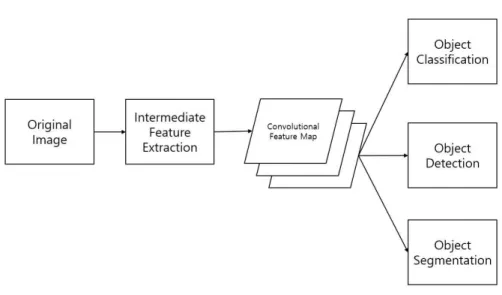
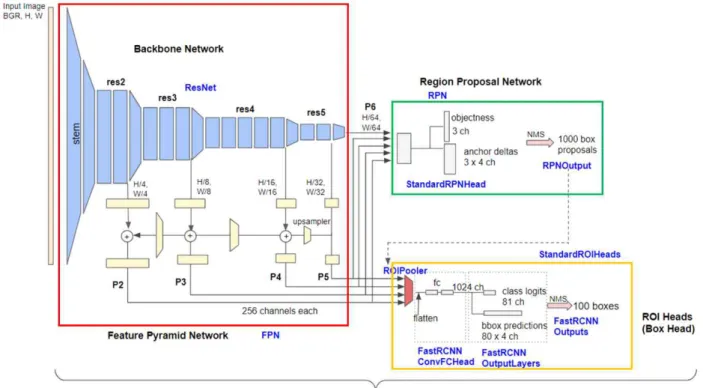
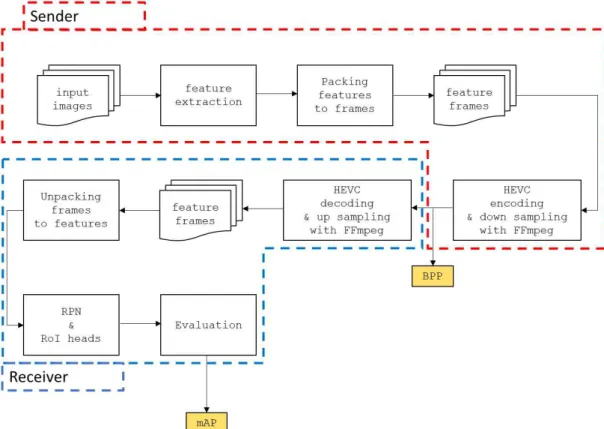
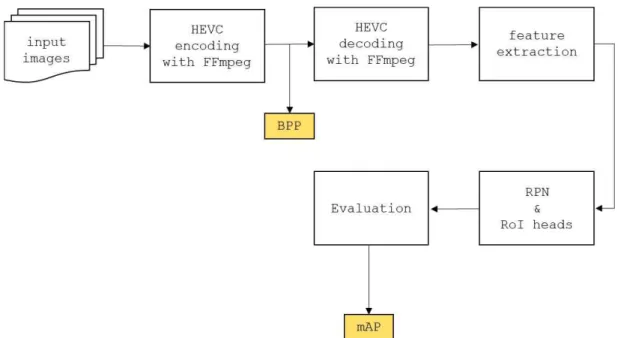
Experiment on Intermediate Feature Coding for Object Detection and Segmentation
14
0
0
전체 글
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
(13)
(14)
수치
+6

관련 문서
Belongie, “Feature pyramid networks for object detection,” in Proceeding of the 2017 IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA,
Towards Accurate Region Proposal Genera- tion and Joint Object Detection,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp..
Among the necessary technologies to perform collision avoidance, object detection and position estimation algorithm are being studied using various sensors such
Jones, “Rapid object detection using a boosted cascade of simple features,” In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and
His research interest is deep learning, computer vision, and abnormal object detection using machine learning and adversarial training. Jeonghwan Gwak received
However, its usefulness in close range has been proved in many studies, especially for navigation. Thus, in this paper, vision-based object detection and tracking
Color histogram is a classical image feature and used for object tracking [3] , texture representation [4~5] , matching [6] and other problems in the field of computer
