상대투과도 규명을 위한 메모리분산 병렬처리 GA 역산 모델 개발
권순일1)· 황상훈2)· 장영호2)· 허대기3)· 이원석3)*
Development of an Inverse Model Based on Memory-shared Parallel GA for Characterizing a Relative Permeability Curve
Sunil Kwon, Sanghoon Hwang, Youngho Jang, Daegee Huh and Wonsuk Lee
*Abstract : This paper presents the development of inverse model equipped with the memory-shared parallel genetic algorithm (GA) to characterize permeability, water influx and relative permeability, simultaneously. The optimum relative permeability model is selected by GA automatically among the relative permeability models obtained by core analysis in the developed model. By utilizing that, we have estimated the permeability distribution and water influx, and selected the relative permeability model for 3-layered heterogeneous reservoir system with the observed production data during three years. This work was carried out with PC-cluster. From the results of the inverse calculation, it was found that it was converged at thirty generations, and the fitness of the best individual was 0.000112. The pressure matching results showed that the maximum relative error was 3.1% at the fifth producer, and the developed model has generated the favorable permeability distributions, water influx and relative permeability model. The process of selecting the relative permeability model was as follows; The number of individual in each node was twenty at the first generation, but it was converged into the only relative permeability model at fifth generation.
Key words : Relative permeability, Water Influx, Reservoir characterization, Inverse calculation, Genetic algorithm, Parallel processing, PC-cluster
요 약 : 본 연구에서는 생산 자료의 역산을 통해 투과도, 상대투과도와 대수층 물 유입량을 규명할 수 있는 메모리분산 병렬처리 GA에 기반한 역산 모델을 개발하였다. 이 모델에서 상대투과도는 코아 분석 등을 통해 선정된 상대투과도 모델 중에서 최적의 모델을 GA가 자동으로 선택하도록 개발되었다. 개발된 모델을 3개 층으 로 구성된 불균질 저류층에 적용하여 3년간 관측된 생산 자료의 역산을 통해 투과도, 상대투과도, 물 유입량을 규명하는 작업을 PC-클러스터에서 수행하였다. 역산을 수행한 결과, 30세대만에 수렴되었으며 이 때 적합도 값이 0.000112이였다. 생산 압력 매칭 결과, 생산정 5에서 최대 상대오차가 3.1%로서 산출된 상대투과도, 투과도, 물 유입량은 신뢰할 만한 결과임을 알 수 있다. 상대투과도 모델 수렴양상을 살펴보면, 1세대에서 20개씩 동일했
던 개체들은 5세대만에 한 개의 상대투과도 모델로 수렴되었다.
주요어 : 상대투과도, 물 유입량, 저류층 특성 규명, 역산기법, 유전자알고리즘, 병렬처리, PC-클러스터
2009년 2월 28일 접수, 2009년 7월 13일 채택 1) 동아대학교 에너지・자원공학과
2) 한양대학교 자원환경공학과
3) 한국지질자원연구원 석유해저연구본부
*Corresponding Author(이원석) E-mail; [email protected]
Address; Petroleum & Gas Resource Department, Korean Institute of Geoscience and Mineral Resources
서 론
동적자료를 활용하는 저류층 특성 규명은 유정압력, 생산량 등의 다양한 생산자료로부터 투과도, 상대투과
도, 물유입량 등의 불확실성이 큰 변수들을 역산하여 규 명하는 작업으로 저류전산 시뮬레이터를 현장화하는데 필수적이다. 위에서 언급한 불확실성 변수중에서 상대투 과도는 2상 이상의 유체가 동시에 유동하는 경우, 그 상 대적인 유동도를 나타내는 것으로 저류층 생산 거동에 큰 영향을 미치는 변수이다. 또한 주변에 큰 대수층이 존 재하는 경우, 대수층으로부터의 물 유입으로 인하여 저 류층의 압력이 유지되면서 많은 양의 오일을 생산할 수 있으나, 과다한 물 유입으로 인하여 생산이 조기에 종료 되는 문제가 발생하기도 한다. 이러한 이유로 상대투과도 와 물 유입량(Water influx)은 실제 현장에서 투과도, 공 연구논문
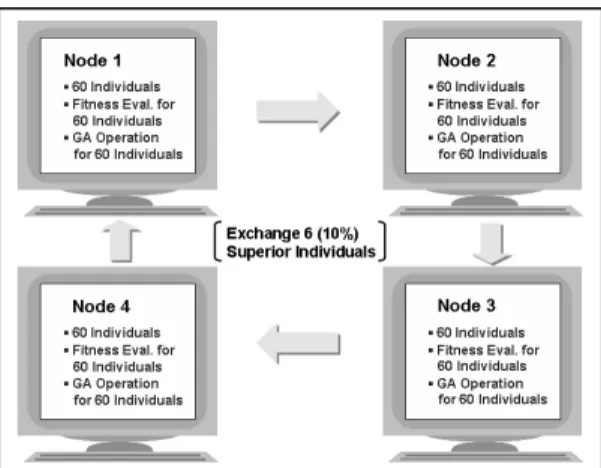
Fig. 1. Memory-shared Parallel Processing Genetic Algorithm.
극률 못지않게 생산 추이에 영향을 미치는 인자이다.
동적자료를 역산하는 저류층 특성 규명 작업은 여러 변수들을 순차적으로 대입하여 산출된 가상의 생산 자료 를 실제 관측 자료와 비교하는 것으로 수작업으로 이를 수행할 경우 엄청난 시간과 비용이 소요된다. 이 때문에 자동화 역산 기법이 다양하게 연구되어 왔다(Gomez et al., 1999; Gallo and Ravalec-Dupin, 2000). 자동화 역 산 작업은 수십번에서 수백번의 저류 전산 시뮬레이션을 수행하여야 하므로 연산시간을 줄이기 위한 병렬처리 기 법의 적용이 필수적이다(Ouences et al., 1995; Schiozer and Sousa, 1997; Leitao and Schiozer, 1999). 병렬처리 는 알고리즘을 병렬화하고 이를 슈퍼 컴퓨터에서 수행하 게 되는데 최근에는 범용 하드웨어와 네트워크 장비의 발달로 인해 PC 클러스터라는 고계산용 병렬 컴퓨터를 쉽게 구성할 수 있게 되었다. 즉 상기의 PC 클러스터로 구성된 각각의 PC에서 분석변수의 탐색을 분산하여 수 행하는 경우, 노드(PC) 수만큼의 연산 속도 증가 효과를 얻을 수 있다.
위에서 언급한 사항들을 종합해 보면, 저류층 특성 규 명 작업을 정확하게 수행하기 위해서는 다상, 다차원 저 류 전산 시뮬레이터의 개발(박용찬, 1995), 생산자료 매 칭을 위한 역산 최적화 기법 개발(Sung et al., 2004), 역 산의 효율성을 높이기 위한 병렬처리 기법의 도입(권순 일 등, 2003, 한충용과 카미 세퍼누리, 2004) 등의 연구 가 선행되어야 한다. 본 연구에서는 Kwon 등(2007)이 개발한 병렬처리 유전자 알고리즘(GA)에 기반한 역산 모델을 확장・개선하여 상대투과도와 대수층 물유입량을 규명할 수 있는 역산 모델을 개발하였다. 또한, PC-클러 스터를 사용하여 개발된 병렬처리 모델의 타당성을 검증 하였다.
본 론
역산 모델 개발
1975년 Holland에 의해 제안된 유전자 알고리즘(Genetic Algorithm: GA)은 유전학과 자연 진화를 흉내 낸 적응 탐색법으로서, 복잡한 최적화 문제를 해결하기 위해서 집단을 사용하고 여기에 선택, 교배, 돌연변이로 이어지 는 모의진화를 일으켜 집단을 점진적으로 개선해 나가게 된다. 따라서 매우 복잡하고 규모가 큰 탐색공간에서도 원만히 작동하며, 목적함수를 선택하는데 있어서도 매우 유연하다.
GA는 공학 전반의 최적화 문제에 널리 활용되어 왔는 데 석유공학 분야에서는 특히 상평형 거동 해석(성원모 등, 1998), 유정시험 자료해석(유인항과 성원모, 1997;
Guyaguler et al., 2003), 저류층 특성 규명(Sung et al., 2004) 등에 이용되어 왔다. 이러한 GA는 초기값에 민감 하지 않고, 광역적 탐색을 통해 지역해가 존재하는 탐색 환경에서도 광역해를 산출할 수 있다는 장점이 있으나, 석유공학 분야의 저류층 특성 규명을 위한 역산 작업의 경우, 저류 전산 시뮬레이션 때문에 적합도 평가에 많은 시간이 소요된다. 따라서 GA를 역산 최적화 알고리즘으 로 활용하기 위해서는 저류 전산 시뮬레이션을 통한 적 합도 평가 부분을 병렬화하는 것이 효과적이다.
Kwon 등(2007)은 메모리분산 병렬처리 GA와 HYBOS 저류전산 시뮬레이터를 결합하여 생산자료의 역산을 통 해 저류층 투과도와 공극률 분포를 규명할 수 있는 모델 을 개발하였다. 또한 개발된 모델을 3개 층으로 구성된 불균질 저류층에 적용하여 그 타당성을 입증하였다. 이 연구에서 개발된 메모리분산 병렬처리 GA는 Fig. 1과 같이 각 노드들이 독립적으로 일괄처리 유전자 알고리즘 연산 즉 선택, 교배, 돌연변이 연산을 수행하고 매 세대 마다 산출된 우량해들을 일정한 비율로 각 노드 간에 서 로 교환함으로써 최적해를 산출하게 된다. 즉, 각 노드에 60개씩 초기 후보해를 생성하고 각각의 노드가 독립적 으로 60개 개체에 대하여 GA 연산을 수행한다. 이 모델 이 10%의 우량 개체(적합도가 높은 개체)를 서로 교환 한다고 가정하면 유전 연산이 완료된 후 6개의 개체를 근접 노드로 보내고 다른 인접 노드에서 6개의 우량 개 체를 전송받아 열등 개체(적합도가 낮은 개체)와 교체하 는 과정을 거친다. 따라서 실제 GA 연산은 각각 독립된 노드에서 한정적으로 이루어지나 우량 개체들을 서로 교 환함으로써 전체 240개 개체에 대한 GA 탐색을 수행하 는 것과 같은 효과를 기대할 수 있다. 정리하면, 각 노드 에서 운영할 수 있는 최대 개체 수와 클러스터 노드 수
Permeability Water influx Relative Perm. index
kr Model 1
kr Model 2
kr Model 3
1
2
3 1 1 1
2 2 2
3 3 3
Fig. 2. Schematic diagram of GA individual. Fig. 3. Flow chart of the inverse model.
의 곱만큼의 개체에 대해 GA 연산을 수행하는 것이 가 능하다. 이로 인해 저류 전산 시뮬레이션에 많은 메모리 가 이미 할당되는 경우에도 충분한 수의 개체에 대하여 역산을 수행하는 것이 가능하다.
본 연구에서는 위의 메모리분산 병렬처리 GA 역산 모 델을 기반으로 상대투과도와 대수층 물유입을 규명할 수 있는 역산 모델을 개발하여 현장 활용성을 높이는 연구 를 수행하였다. 개발된 모델은 상대투과도와 대수층 물 유입을 규명하기 위해 GA 각 개체를 Fig. 2와 같이 정의 하였다. 여기서 각 개체는 전반부에 투과도 값을 저장하 고, 중반부에는 대수층 물 유입량 값을 저장하며, 마지막 부분에는 이 개체의 상대투과도 모델을 지정한다. 상대 투과도 모델의 규명과정을 살펴보면, GA 1세대에 각 노 드에서 상대투과도 모델마다 동일한 수의 개체를 생성하 여 역산을 시작하고, 역산 과정에서 각 상대투과도 모델 의 적합도 평균값에 근거하여 개체 수를 조정한다. 따라 서 상대적으로 적합도가 높은 상대투과도 모델은 개체 수가 계속적으로 증가하여 결국 하나의 상대투과도 모델 로 수렴하게 된다.
대수층 물 유입량은 물-오일 경계면(WOC)에 주입정 을 위치시키고 전위모델링(적합도 평가를 위한 저류 시 뮬레이션) 시 주입량을 변화시키면서 역산을 수행하여 규명하게 된다. 개발된 모델에서 물 유입량은 투과도와 마찬가지로 지질학적 구조와 주입정의 위치 등의 관계를 고려하여 일정수의 주입정을 1개 그룹으로 구분하는 과 정을 거쳐 각 그룹에서의 대푯값을 산출하였다.
상기의 개체들로 구성된 역산 모델의 연산과정(Fig. 3) 을 살펴보면, 먼저 각 상대투과도 모델의 개체 수가 같도 록 PC 클러스터 노드에 후보해를 생성한다. 즉 상대투과 도 모델마다 20개 개체를 생성하고 3개의 상대투과도 모델을 적용한다면, 각 노드당 60개의 개체를 생성하고 역산이 진행되는 동안 총 개체 수는 유지된다. 각 노드들 은 독립적으로 목적함수(식 (1))의 역수인 개체의 적합
도를 계산하고 상대투과도 모델마다 평균 적합도를 산출 한다. 이 평균 적합도에 근거하여 각 상대투과도 모델의 개체 수를 총 60개 내에서 조정한다. 식 (1)의 목적함수 는 압력차와 WOR에 스케일링 변수를 곱하여 산술적으 로 합한 값으로 적합도의 크기차이가 선택에 영향을 미 치지 않는 선택연산자(토너먼트 연산자 등)가 적용된 유 전자알고리즘에서 제한적으로 사용될 수 있다.
(1)
여기서 i : 생산정의 수, j : 관측 생산 자료의 수
wf : WOR과 압력의 스케일을 맞추기 위한 변수 P : 정저압력(psia),
WOR : 물오일생산비(ratio)
개체 수 조정이 완료되면 각 상대투과도 모델의 개체 끼리 선택, 교배, 돌연변이 연산을 노드들이 독립적으로 수행한다. 노드마다 독립적인 GA 연산이 완료되면 메모 리분산 병렬처리 과정이 시작된다. 이 때 각 노드 간 일 정수의 우량 개체를 교환하게 되는데 기 개발된 메모리 분산 병렬처리와 달리 노드 간 전송된 우량 개체는 같은 상대투과도 모델의 열등 개체를 대체해야 한다. 이 때 동 일한 상대투과도 모델이라도 각 노드마다 평균적합도가 다르기 때문에 개체 수도 다를 수 있다. 이에 노드들은 상대투과도 모델들의 개체 수 정보를 먼저 교환하고 나 서 필요한 수만큼의 개체를 서로 교환한다. 이 과정을
Table 1. Production data of each producer
Producer
Permeability (md) Daily Production
(BOPD) Layer 1 Layer 2 Layer 3
Producer 1 143 135 323 800
Producer 2 230 325 800
Producer 3 181 193 257 200
Producer 4 58 284 305 100
Producer 5 66 293 221 200
Producer 6 260 313 207 800
Fig. 6. Bottomhole pressure data at producers during 3 years.
Node 1 Node 2 Node 3 Node 4
(3)
(1) (2)
(2)
(3) (1) kr Model 1
kr Model 2 kr Model 3
20 (2) 16 (2) 24 (2)
30 (3)
10 (1) 20 (2)
20 (2)
30 (3) 10 (1)
20 (2) 10 (1)
30 (3) (2)
(1) (3)
(2)
(2) (2)
Fig. 4. Schematic diagram for exchanging superior individuals among nodes.
Fig. 5. Reservoir system for inverse calculation.
Fig. 4에 나타내었는데, 2번 노드와 1번 노드를 기준으 로 살펴보면, 2번 노드는 1번 노드에 자신의 상대투과도 모델의 개체 수 30, 10, 20에 대한 정보를 전송한다. 전 송이 완료되면, 1번 노드는 개체 수의 10%에 해당하는 개체 수인 6개의 우량 개체를 상대투과도 모델 1에서 3 개, 2와 3에서 각각 1개, 2개씩 선정하여 2번 노드로 전 송한다. 우량 개체를 받은 2번 노드는 같은 상대투과도 모델의 열등 개체를 우량 개체로 교체된다.
역산 모델 적용
개발된 모델을 활용하여 저류층-대수층 특성을 규명하 기 위한 저류층 시스템은 Fig. 5와 같다. 이 저류층은 3 개의 불균질한 층으로 구성되어 있으며 주변부에 대수층 이 존재하는 구조이다. 대상 저류층의 6개 생산정에서 Table 1과 같이 총 2900 BOPD로 3년간 생산을 수행하
였다. Fig. 6의 생산기간 동안 생산정 압력과 필드 전체 의 WOR 값을 매칭하는 역산을 수행하여 투과도, 상대 투과도, 물 유입량을 규명하였다. 또한 역산을 위한 초기 분포 산출을 위해 6개 생산정에서 취득된 투과도 자료가 사용되었다. 먼저 역산을 위한 전위 모델링 과정인 저류 전산 시뮬레이션을 수행하고자 각 층을 300(20(900ft)
×15(600ft))개의 격자로 나누고 대수층으로부터 물 유입 을 묘사하기 위해 물-오일 경계면 부근에 Fig. 7과 같이 15개의 주입정을 설정하였다.
역산을 통해 저류층의 투과도 분포를 산출하기 위해 Fig. 8과 같이 전체 저류층을 총 60개의 투과도 블록으 로 구분하였다. 1번 층은 6개 생산정에서 취득된 투과도 값으로부터 Kriging을 통해 초기 분포를 산출한 결과, 저류층 중심부에 저투과도 지역이 존재하고 양쪽으로 투 과도가 증가되었다가 감소되는 양상을 보여 정밀한 분석 을 위해 31개 투과도 블록으로 구분하였다. 2번 층과 3 번 층은 투과도 초기 분포 산출결과 투과도 변화 양상이
Fig. 7. Position and groups of injectors.
Fig. 8. Inverse blocks and initial distribution calculated by Kriging method.
Table 2. Initial permeability distribution of inverse block
Layer 1 Layer 2 Layer 3
Block Perm. (md) Perm. (md) Perm. (md)
min max min max min max
1 151.2 157.2 137.1 158.2 327.8 342.4 2 148.7 151.2 134.7 140.6 288.0 327.5 3 153.3 167.3 136.9 193.1 323.6 345.8 4 147.3 155.6 134.7 191.5 295.0 342.4 5 147.6 151.2 225.4 294.4 248.6 327.4 6 166.6 181.1 247.9 308.2 233.5 302.4 7 156.5 187.7 182.1 308.2 230.9 330.4 8 143.0 179.9 184.5 297.6 203.6 308.3 9 147.6 161.4 283.0 309.6 199.2 257.8 10 134.6 183.4 295.8 316.0 199.1 237.3 11 132.7 230.0 304.2 315.6 203.7 261.1 12 127.3 215.2 286.9 313.3 192.1 212.6 13 127.9 180.7 271.6 305.8 189.6 199.3 14 142.5 160.1 313.6 316.3
15 104.1 146.9 306.3 314.9 16 58.7 130.7 296.7 311.1 17 66.6 130.7
18 82.1 140.8 19 135.2 153.7 20 117.2 208.1 21 102.1 245.5 22 108.5 260.0 23 109.9 223.1 24 142.6 196.5 25 195.3 242.1 26 225.1 244.1 27 198.5 230.3 28 188.5 219.7 29 230.1 234.7 30 220.0 230.9 31 210.0 225.0
점진적으로 나타나 1번 층에 비해 많은 수의 격자를 하 나의 투과도 블록으로 결정하여도 대표성을 가질 것으로 판단되어 비교적 적은 16개, 13개 투과도 블록으로 구분
하였다. Kriging을 통해 투과도의 초기 분포를 산출한 후 60개 투과도 블록에 대해 각 블록에서 최소, 최대 투 과도 값을 선정하였다(Table 2). 이 값의 범위 내에서 1 개의 투과도 값을 무작위로 산출하여 60개의 투과도 값 으로 구성되는 GA 개체들을 생성하였다.
본 분석에서는 개발된 모델의 상대투과도 규명의 타당
(a) Relative permeability model 1
(b) Relative permeability model 2
(c) Relative permeability model 3
Fig. 9. Relative permeability model for inverse calculation.
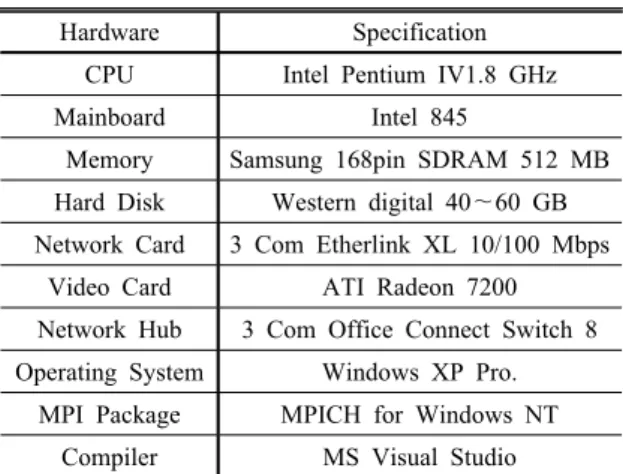
Table 3. Features of PC-cluster
Hardware Specification
CPU Intel Pentium IV1.8 GHz
Mainboard Intel 845
Memory Samsung 168pin SDRAM 512 MB Hard Disk Western digital 40~60 GB Network Card 3 Com Etherlink XL 10/100 Mbps
Video Card ATI Radeon 7200 Network Hub 3 Com Office Connect Switch 8 Operating System Windows XP Pro.
MPI Package MPICH for Windows NT Compiler MS Visual Studio
Table 4. GA operator and rate for inverse calculation GA input Operator and Probability Selection operator Tournament Crossover operator Modified simple crossover
Mutation operator Uniform mutation Crossover probability 0.9
Mutation probability 0.1
성을 검증하기 위해 Fig. 9와 같이 3개의 상대투과도 모 델을 임의로 선정하여 3개 중에서 어느 모델이 본 시스 템에 적정한지를 평가하였다. 또한 대수층으로부터의 물 유입은 Fig. 7과 같이 15개의 주입정을 통해 물을 주입 하는 것으로서 묘사하였다. 본 연구에서는 15개 주입정 을 5개의 주입정 블록으로 구분하고 각 주입정 블록에서 대푯값을 산출하였다.
개발된 모델을 이용하여 생산 압력과 필드 WOR을 매 칭하는 작업을 통해 투과도, 물 유입량, 상대투과도를 규 명하는 작업을 수행하였다. 역산에는 Table 3과 같은 4 대의 PC로 연결된 PC-클러스터가 사용되었다. 초기 후 보 개체는 각 노드 당 3개의 상대투과도 모델에 대해 20 개 개체를 생성하여 각 노드당 60개, 총 240개이다. 역 산에 사용된 GA 연산자는 권순일 등(2003)의 연구 결과 에서 불균질 저류층에 대해 정확성과 수렴성이 검증된 이진 토너먼트 연산자와 수정 단순 교배 연산자이다. 돌 연변이 연산자로 균등 돌연변이 연산자를 적용하였다 (Table 4). 또한 이전 세대의 최적 개체를 보존하기 위한 엘리트 전략이 적용되었다. 마지막으로 역산 과정에서 유전자 알고리즘 각 세대마다 우수한 개체를 각 노드간 교환하게 되는데 본 연구에서는 적합도가 높은 우량 개
Fig. 10. Individuals of each relative permeability model every generation.
0 10 20 30
GENERATION 0.00002
0.00004 0.00006 0.00008 0.00010 0.00012
FITNESS OF BEST INDIVIDUAL
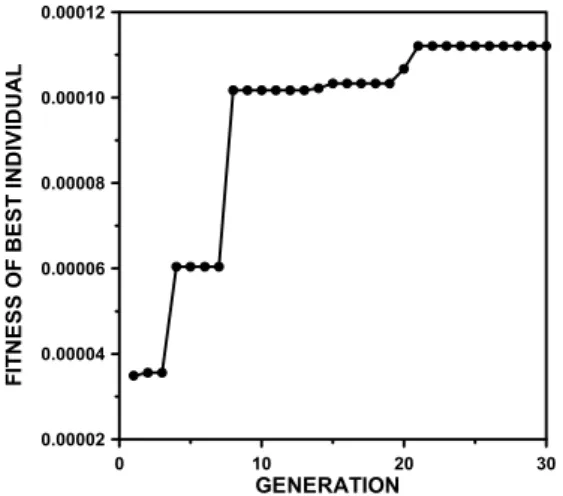
Fig. 11. Convergence of fitness of best individual.
0 360 720 1080
TIME, DAY 1600
2000 2400 2800
BOTTOMHOLE PRESSURE, PSIA
OP 1 (OBS) OP 1 (CAL) OP 3 (OBS) OP 3 (CAL)
Fig. 12. The matching results of the production data for pro- ducer 1, 3.
Table 5. Pressure matching results for each producer Producer Relative RMS error (%)
Producer 1 0.30
Producer 2 0.32
Producer 3 1.52
Producer 4 1.59
Producer 5 3.11
Producer 6 0.29
체 중에서 10%를 각 노드가 세대마다 교환하도록 설정 하였다. 이 역산 작업은 10세대 이상 최적 적합도가 개선 되지 않으면 수렴한 것으로 판단하고 역산을 종료하였다.
역산 결과, 상대투과도 모델은 유전자 알고리즘 5세대 에 상대투과도 모델 1로 수렴되었다. 수렴양상을 1번 노 드 결과를 통해 살펴보면, Fig. 10에 나타난 바와 같이 1세대에서 20개씩 동일했던 개체들은 2세대에서 적합도 에 따라 상대투과도 1이 34개, 2와 3이 각각 14, 12개로 조정되었다. 이 후 4세대에서 상대투과도 모델 3은 소멸 하였고, 5세대에서 상대투과도 2도 소멸하여 5세대 이후 에는 상대투과도 모델 1의 개체들만 남는 결과가 산출되 었다. 따라서 5세대 이후부터는 투과도와 물 유입량에 의해서만 매칭 작업이 수행되었다.
Fig. 11은 역산과정에서 목적함수의 역수인 적합도의 변화를 도시한 것으로 역산이 완료된 시점인 30세대에 서 적합도 값은 0.000112이였다. Fig. 12는 생산정 1과 생산정 3의 압력매칭결과를 도시한 것으로 평균 상대오 차가 각각 0.3%, 1.5%로 산출되었으며, 상대오차가 가
장 큰 생산정 5에서도 3.1%로 양호한 일치를 보이는 것 으로 나타났다(Table 5).
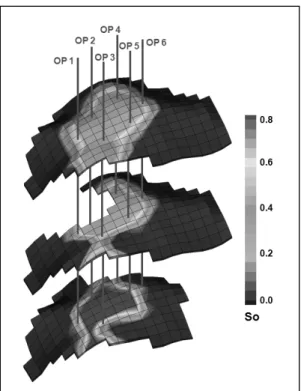
Fig. 13은 역산을 통해 산출된 최적 투과도 분포를 도 시한 것으로 1번 층의 경우 투과도 값이 12~231 md 정 도이고 분포는 저류층 중심부에 저투과도 지역이 존재하 는 것을 확인할 수 있다. 2번 층의 경우, 투과도 값이 전 체적으로 16~299 md 이고 좌측부분에 저투과도 지역 이 존재한다. 또한 3번 층의 경우, 투과도 분포가 17~
313 md 정도이고 우측하단부분에 저투과도 지역이 존 재한다. 각 주입정 그룹에서 산출된 주입량을 살펴보면 그룹 1의 경우, 주입정 당 1116.7 BWPD, 그룹 2, 3, 4, 5는 각 주입정당 1160.4 BWPD, 959.9 BWPD, 1364.1 BWPD, 1952.7 BWPD로 산출되었다. 차후 저류 전산 시뮬레이션을 통한 생산 거동 예측 시 15개 주입정에 대 해 산출된 주입량을 적용하면 대수층 효과를 고려한 생 산 거동 예측을 수행할 수 있을 것이다.
Fig. 13. Permeability distribution calculated by inverse model.
결 론
본 연구에서는 생산 자료의 역산을 통해 투과도, 상대 투과도와 대수층 물 유입량을 규명할 수 있는 메모리분 산 병렬처리 GA에 기반한 역산 모델을 개발하였다. 개 발된 모델에서 상대투과도는 코아 분석을 통해 선택된 상대투과도 모델 중에서 최적의 모델을 GA가 자동으로 선택하도록 개발되었다. 개발된 모델을 3개 층으로 구성 된 불균질 저류층에 적용하여 3년간 관측된 생산 자료의 역산을 통해 투과도, 상대투과도, 물 유입량을 규명하는 작업 PC-클러스터에서 수행한 결과, 다음과 같은 결론을 도출하였다.
1. 6개 유정에서 취득된 투과도 값으로부터 Kriging 기법에 의해 투과도 분포를 산출하여 60개 역산블록에 서 초기 후보해를 결정하였다. 상대투과도는 본 저류층 시스템에 적용 가능한 3개의 상대투과도 모델을 가정하 였다. 마지막으로 5개의 주입정 블록을 선정하여 각 블 록에서 물 유입량 초기 후보해를 결정하였다.
2. 역산을 수행한 결과, 30세대만에 수렴되었으며 이 때 적합도 값이 0.000112이였다. 생산 압력 매칭 결과, 생산정 5에서 최대 상대오차가 3.1%로서 산출된 상대투
과도, 투과도, 물유입량은 신뢰할 만한 결과임을 알 수 있다.
3. 상대투과도 모델 수렴양상을 살펴보면, 1세대에서 20개씩 동일했던 개체들은 2세대에서 적합도에 따라 상 대투과도 1이 34개, 2와 3이 각각 14, 12개로 조정되었 다. 이 후 4세대에서 상대투과도 모델 3은 소멸되었고, 5세대에서 상대투과도 2도 소멸하여 상대투과도 모델 1 로 수렴하였다.
4. 대수층 물 유입량을 나타내는 각 주입정 블록에서 주입량을 살펴보면 블록 1의 경우, 주입정 당 1116.7 BWPD, 블록 2, 3, 4, 5는 각 주입정당 1160.4 BWPD, 959.9 BWPD, 1364.1 BWPD, 1952.7 BWPD로 산출되 었다.
사 사
이 연구는 2007-2008년도 에너지관리공단에서 시행한 ETI 프로젝트 중 “균열저류층 유동해석 S/W 개발” 과제 의 일환으로 수행되었습니다. 이에 감사드립니다.
참고문헌
권순일, 김현태, 허대기, 김세준, 이원석, 성원모, 2003, “병 렬처리 유전자 알고리즘을 적용한 저류층 특성 역산모델 개발 및 응용,” 한국지구시스템공학회지, 제40권 5호, pp. 321-328.
박용찬, 1995, 지역적 격자 세분화 기법이 적용된 HYBOS 모델을 활용한 와다구조의 최적생산방안 도출에 관한 연 구, 석사학위논문, 한양대학교, 서울, 한국.
성원모, 권오광, 서정규, 류상수, 1998, “유전자알고리즘이 적용된 상평형 모델의 개발 및 탄화수소 혼합물의 상거 동 분석,” 한국자원공학회지, 제35권 6호, pp. 547-553.
유인항, 성원모, 1997, “유전자알고리즘을 이용한 자동표
준곡선 중첩법에 의한 유정시험자료의 해석,” 한국자원
공학회지, 제34권 2호, pp. 218-225.
한충용, 카미 세퍼누리, 2004, “병렬 프로세스 연산기법을
사용한 완전 음역 다성분 저류층”, 한국지구시스템공학
회지, 제41권 3호, pp. 242-252.
Gallo, Y.L and Ravalec-Dupin, M.L., 2000, “History Matching Geostatistical Resrvoir Models with Gradual Deformation Method,” Paper SPE 62922, presented at the SPE Annual Technical Conferences and Exhibition held in Dallas, Texas, October 1-4.
Gomez, S., Gosselin, O. and Barker, J.W., 1999, “Gradient -Based History-Matching with a Global Optimization Method,”
Paper SPE 56756, presented at the SPE Annual Technical Conferences and Exhibition held in Houston, Texas, Oc-
권 순 일
현재 동아대학교 에너지자원공학과 조교수 (本 學會誌 第45券 第4号 參照)
장 영 호
2009년 한양대학교 지구환경시스템공학 과 공학사
현재 한양대학교 자원환경공학과 석사과정 (E-mail; [email protected])
허 대 기
현재 한국지질자원연구원 석유해저자원연구부 책임연구원 (本 學會誌 第44券 第6号 參照)
황 상 훈
2008년 한양대학교 지구환경시스템공학 과 공학사
현재 한양대학교 자원환경공학과 석사과정 (E-mail; [email protected])
이 원 석
1993년 한양대학교 자원공학과 공학사 1995년 한양대학교 자원공학과 공학석사 2000년 한양대학교 자원공학과 공학박사
현재 한국지질자원연구원 석유해저자원연구부 선임연구원 (E-mail; [email protected])
tober 3-6.
Guyaguler, B., Horne, R.N. and Tauzin, E., 2003, “Au- tomated Reservoir Model Selection in Well-Test Interpre- tation,” SPE Reservoir Evaluation & Engineering, Vol. 6, No. 2, pp. 100-107.
Kwon, S.I., Sung, W.M., Huh, D.G. and Lee, W.S., 2007,
“Characterization of Reservoir Heterogeneity Using Inverse Model Equipped with Parallel Genetic Algorithm”, En- ergy Sources, Vol. 29, No. 9, pp. 823-838.
Leitao, H.C. and Schiozer, D.J., 1999, “A New Automated History Matching Algorithm Improved by Parallel Com- puting,” Paper SPE 53977, presented at the SPE Latin American and Caribbean Petroleum Engineering Confer- ence held in Caracas, Venezuela, April 21-23.
Ouenes, A., Weiss, W., Sultan, A.J. and Anwar, J., 1995,
“Parallel Reservoir Automatic History Matching Using a Network of Workstations and PVM,” Paper SPE 29107, presented at the 13th SPE Symposium on Reservoir Sim- ulation held in San Antonio, Texas, February 12-15.
Schiozer, D.J. and Sousa, S.H.G, 1997, “Use of External Parallelization to Improve History Matching,” Paper SPE 39062, presented at the Fifth Latin American and Carib- bean Petroleum Engineering Conferences and Exhibition held in Rio de Janeiro, Brazil, August 30 - September 3.
Sung, W.M., Kwon, S.I., Huh, D.G., Kim, H.T., Kim, S.J.
and Lee, W.S., 2004, “Development and Application of Inverse Model Using Genetic Algorithm for Reservoir Characterization,” Energy Sources, Vol. 26, No. 6, pp.
595-609.