2021, 32
(1)
,25–35
딥러닝을 이용한 통계적 가설검정:
이표본 t-검정을 중심으로 †
기
ᆷ상웅
1
· 송준모2
12경북대학교 통계학과
ᄌ ᅥ
ᆸᄉ ᅮ 2020ᄂ ᅧ ᆫ 12ᄋ ᅯ ᆯ 28ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2021ᄂ ᅧ ᆫ 1ᄋ ᅯ ᆯ 15ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2021ᄂ ᅧ ᆫ 1ᄋ ᅯ ᆯ 21ᄋ ᅵ ᆯ
요 약
ᄇ
ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄉ ᅵ ᆷᄎ ᅳ ᆼᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼᄋ ᅳ ᆯ ᄋ ᅵᄋ ᅭ ᆼ ᄒ ᅡ ᆫ ᄐ ᅩ ᆼ ᄀ ᅨᄌ ᅥ ᆨ ᄀ ᅡᄉ ᅥ ᆯᄀ ᅥ ᆷᄌ ᅥ ᆼᄋ ᅦ ᄃ ᅢᄒ ᅡᄋ ᅧ ᄃ ᅡᄅ ᅮ ᆫ ᄃ ᅡ. ᄐ ᅩ ᆼ ᄀ ᅨᄌ ᅥ ᆨ ᄀ ᅡᄉ ᅥ ᆯᄀ ᅥ ᆷᄌ ᅥ ᆼᄋ ᅳ ᆫ ᄌ ᅮᄋ ᅥ ᄌ
ᅵ ᆫ ᄌ ᅡᄅ ᅭᄅ ᅳ ᆯ ᄇ ᅡᄐ ᅡ ᆼᄋ ᅳᄅ ᅩ ᄀ ᅱᄆ ᅮᄀ ᅡᄉ ᅥ ᆯᄋ ᅴ ᄀ ᅵᄀ ᅡ ᆨᄋ ᅧᄇ ᅮᄅ ᅳ ᆯ ᄀ ᅧ ᆯᄌ ᅥ ᆼᄒ ᅡᄂ ᅳ ᆫ ᄀ ᅪᄌ ᅥ ᆼᄋ ᅳᄅ ᅩ, ᄀ ᅵᄀ ᅡ ᆨᄃ ᅬᄂ ᅳ ᆫ ᄀ ᅧ ᆼᄋ ᅮ ᄋ ᅵᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄃ ᅢᄋ ᅡ ᆫᄋ ᅳᄅ ᅩ ᄃ ᅢ ᄅ ᅵ
ᆸᄀ ᅡᄉ ᅥ ᆯᄋ ᅳ ᆯ ᄉ ᅥ ᆫᄐ ᅢ ᆨᄒ ᅡᄀ ᅦ ᄃ ᅬ ᆫ ᄃ ᅡ. ᄌ ᅳ ᆨ, ᄐ ᅩ ᆼ ᄀ ᅨᄌ ᅥ ᆨ ᄀ ᅡᄉ ᅥ ᆯᄀ ᅥ ᆷᄌ ᅥ ᆼᄋ ᅳ ᆫ ᄀ ᅱᄆ ᅮᄀ ᅡᄉ ᅥ ᆯᄀ ᅪ ᄃ ᅢᄅ ᅵ ᆸᄀ ᅡᄉ ᅥ ᆯ ᄌ ᅮ ᆼ ᄒ ᅡ ᆫ ᄀ ᅡᄉ ᅥ ᆯᄋ ᅳ ᆯ ᄉ ᅥ ᆫᄐ ᅢ ᆨᄒ ᅡᄂ ᅳ ᆫ ᄆ ᅮ ᆫ ᄌ ᅦᄅ ᅩ ᄉ ᅢ
ᆼᄀ ᅡ ᆨᄒ ᅡ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄂ ᅳ ᆫ ᄃ ᅦ, ᄋ ᅵᄂ ᅳ ᆫ ᄀ ᅵᄀ ᅨᄒ ᅡ ᆨᄉ ᅳ ᆸ ᄋ ᅦᄉ ᅥᄋ ᅴ ᄇ ᅮ ᆫ ᄅ ᅲᄆ ᅮ ᆫ ᄌ ᅦᄅ ᅩ ᄀ ᅡ ᆫᄌ ᅮ ᄃ ᅬ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄃ ᅡ. ᄋ ᅵᄋ ᅦ ᄇ ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄀ ᅡᄉ ᅥ ᆯᄀ ᅥ ᆷᄌ ᅥ ᆼᄋ ᅳ ᆯ ᄇ
ᅮ ᆫ ᄅ ᅲᄆ ᅮ ᆫ ᄌ ᅦᄅ ᅩ ᄋ ᅧᄀ ᅵᄀ ᅩ, ᄉ ᅵ ᆷᄎ ᅳ ᆼᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼᄋ ᅳ ᆯ ᄋ ᅵᄋ ᅭ ᆼ ᄒ ᅡ ᆫ ᄐ ᅩ ᆼ ᄀ ᅨᄌ ᅥ ᆨ ᄀ ᅡᄉ ᅥ ᆯᄀ ᅥ ᆷᄌ ᅥ ᆼᄋ ᅳ ᆯ ᄉ ᅮᄒ ᅢ ᆼᄒ ᅡ ᆫᄃ ᅡ. ᄀ ᅮᄎ ᅦᄌ ᅥ ᆨᄋ ᅳᄅ ᅩ, ᄃ ᅮ ᄆ ᅩᄇ ᅮ ᆫ ᄑ ᅩᄋ ᅴ ᄑ ᅧ ᆼ ᄀ
ᅲ ᆫ ᄇ ᅵᄀ ᅭ ᄀ ᅥ ᆷᄌ ᅥ ᆼᄋ ᅦ ᄃ ᅢᄒ ᅡᄋ ᅧ ᄉ ᅵ ᆷᄎ ᅳ ᆼᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼᄋ ᅳ ᆯ ᄒ ᅡ ᆨᄉ ᅳ ᆸ ᄉ ᅵᄏ ᅵᄀ ᅩ, ᄀ ᅥ ᆷᄌ ᅥ ᆼ ᄉ ᅥ ᆼᄂ ᅳ ᆼᄋ ᅳ ᆯ ᄀ ᅵᄌ ᅩ ᆫ ᄋ ᅴ ᄋ ᅵᄑ ᅭᄇ ᅩ ᆫ t-ᄀ ᅥ ᆷᄌ ᅥ ᆼᄀ ᅪ ᄇ ᅵᄀ ᅭᄒ ᅡ ᆫᄃ ᅡ. ᄇ ᅩ ᆫ ᄋ
ᅧ ᆫᄀ ᅮᄋ ᅦᄉ ᅥ ᄒ ᅡ ᆨᄉ ᅳ ᆸᄃ ᅬ ᆫ ᄉ ᅵ ᆷᄎ ᅳ ᆼᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼᄋ ᅳ ᆫ ᄋ ᅲᄋ ᅴᄉ ᅮᄌ ᅮ ᆫ 5% ᄋ ᅴ t-ᄀ ᅥ ᆷᄌ ᅥ ᆼᄀ ᅪ ᄇ ᅵᄉ ᅳ ᆺ ᄒ ᅡ ᆫ ᄉ ᅮᄌ ᅮ ᆫ ᄋ ᅴ ᄀ ᅥ ᆷᄌ ᅥ ᆼᄀ ᅧ ᆯᄀ ᅪᄅ ᅳ ᆯ ᄇ ᅩᄋ ᅧ ᆻᄋ ᅳᄆ ᅧ, ᄉ ᅵ ᆯᄒ ᅥ ᆷᄀ ᅪ ᄌ ᅥ
ᆼᄋ ᅳ ᆯ ᄐ ᅩ ᆼ ᄒ ᅡᄋ ᅧ ᄌ ᅦᄀ ᅵ ᄃ ᅬ ᆫ ᄃ ᅵ ᆸᄅ ᅥᄂ ᅵ ᆼᄋ ᅳ ᆯ ᄋ ᅵᄋ ᅭ ᆼ ᄒ ᅡ ᆫ ᄀ ᅥ ᆷᄌ ᅥ ᆼᄋ ᅴ ᄋ ᅵᄉ ᅲᄋ ᅪ ᄌ ᅡ ᆼᄃ ᅡ ᆫᄌ ᅥ ᆷ ᄃ ᅳ ᆼ ᄋ ᅦ ᄃ ᅢᄒ ᅡᄋ ᅧ ᄉ ᅡ ᆯᄑ ᅧᄇ ᅩ ᆫ ᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄃ ᅵ ᆸᄅ ᅥᄂ ᅵ ᆼ, ᄇ ᅮ ᆫ ᄅ ᅲ, ᄉ ᅵ ᆷᄎ ᅳ ᆼᄉ ᅵ ᆫᄀ ᅧ ᆼᄆ ᅡ ᆼ, ᄋ ᅵᄑ ᅭᄇ ᅩ ᆫ ᄑ ᅧ ᆼᄀ ᅲ ᆫ ᄇ ᅵᄀ ᅭ ᄀ ᅥ ᆷᄌ ᅥ ᆼ, ᄋ ᅵᄑ ᅭᄇ ᅩ ᆫ t-ᄀ ᅥ ᆷᄌ ᅥ ᆼ, ᄐ ᅩ ᆼ ᄀ ᅨᄌ ᅥ ᆨ ᄀ ᅡᄉ ᅥ ᆯᄀ ᅥ ᆷᄌ ᅥ ᆼ.
1. 서론 과
ᆫ찰된자료를이용하여 귀무가설 (null hypothesis)의 기각여부를결정하는과정을 통계적 가설검정 (statistical hypothesis testing)이라고 한다. 귀무가설을기각할만한 뚜렷한 반증이 있을때 이를기각 ᄒ
ᅡ고 이에 대한 대안으로 대립가설 (alternative hypothesis)을선택하게된다. 이때 귀무가설의 기각여 ᄇ
ᅮ는 귀무가설 하에서 유도되는 기각역 또는 유의확률로부터 결정된다. 간단하게는모평균 및 모분산 ᄋ
ᅦ 대한 검정에서부터 모분포 또는모형에 대한 적합도 검정 (goodness of fit test), 모수의 변화점 검정 (parameter change test),시계열모형에서의 단위근검정 (unit root test) 등다양한 종류의 검정문제 ᄃ
ᅳ
ᆯ이 연구되었으며, 새로운검정통계량 및 방법들이 계속해서 개발되고 있다.
보
ᆫ 논문에서는 심층신경망 (deep neural network, 이하 DNN)을이용한 가설검정에 대하여 다룬다.
DNN은 입력층 (input layer)과 출력층 (output layer) 사이에 여러 개의 은닉층 (hidden layer)으 ᄅ
ᅩ 구성된 인공신경망 (artificial neural network)의 일종으로, 주어진 자료를 이용하여 DNN을 학 ᄉ
ᅳᆸ(training)시키는 과정을 딥러닝 (심층학습, deep learning)이라고 한다. 기계학습 (machine learn- ing)의 한 분야인 딥러닝은 음성 및 이미지 인식, 자연어 처리 등 이전에는 다루기 힘들었던 문제들을 서
ᆼ공적으로 해결하면서 크게 주목받고 있으며, 그외의 분야에서도 빠르게 적용되면서 괄목할만한 성과
†
ᄇ ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄂ ᅳ ᆫ ᄉ ᅡ ᆫᄅ ᅵ ᆷᄎ ᅥ ᆼ(ᄒ ᅡ ᆫᄀ ᅮ ᆨᄋ ᅵ ᆷᄋ ᅥ ᆸᄌ ᅵ ᆫᄒ ᅳ ᆼᄋ ᅯ ᆫ) ᄉ ᅡ ᆫᄅ ᅵ ᆷᄀ ᅪᄒ ᅡ ᆨᄀ ᅵᄉ ᅮ ᆯ ᄋ ᅧ ᆫᄀ ᅮᄀ ᅢᄇ ᅡ ᆯᄉ ᅡᄋ ᅥ ᆸ (2019149B10-2023-0301)ᄀ ᅪ ᄌ ᅥ ᆼᄇ ᅮ(ᄀ ᅭᄋ ᅲ ᆨ ᄇ ᅮ) ᄌ
ᅢᄋ ᅯ ᆫ ᄋ ᅴ ᄒ ᅡ ᆫᄀ ᅮ ᆨᄋ ᅧ ᆫᄀ ᅮᄌ ᅢᄃ ᅡ ᆫ ᄀ ᅵᄎ ᅩᄋ ᅧ ᆫᄀ ᅮᄉ ᅡᄋ ᅥ ᆸ (NRF-2019R1I1A3A01056924)ᄋ ᅴ ᄌ ᅵᄋ ᅯ ᆫ ᄋ ᅦ ᄋ ᅴᄒ ᅡᄋ ᅧ ᄉ ᅮᄒ ᅢ ᆼᄃ ᅬᄋ ᅥ ᆻᄉ ᅳ ᆸ ᄂ ᅵᄃ ᅡ.
1
(41566) ᄃ ᅢᄀ ᅮᄉ ᅵ ᄇ ᅮ ᆨ ᄀ ᅮ ᄉ ᅡ ᆫᄀ ᅧ ᆨᄃ ᅩ ᆼ ᄃ ᅢᄒ ᅡ ᆨᄅ ᅩ 80, ᄀ ᅧ ᆼᄇ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄉ ᅥ ᆨᄉ ᅡᄀ ᅪᄌ ᅥ ᆼ.
2
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (41566) ᄃ ᅢᄀ ᅮᄉ ᅵ ᄇ ᅮ ᆨ ᄀ ᅮ ᄉ ᅡ ᆫᄀ ᅧ ᆨᄃ ᅩ ᆼ ᄃ ᅢᄒ ᅡ ᆨᄅ ᅩ 80, ᄀ ᅧ ᆼᄇ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄇ ᅮᄀ ᅭᄉ ᅮ. E-mail: [email protected]
르
ᆯ 내고 있다 (LeCun 등, 2015). 이에 더 많은 응용분야에서 딥러닝을 활용하고자 하는 시도와 함께 DNN이 보여주고 있는 비선형 함수관계에서의 뛰어난 근사능력 (universal approximation)을 밝히기 ᄋ
ᅱ한 이론적인 연구들도 깊이 있게 이루어지고 있다 (Funahashi, 1989, Bengio와 DelalleauLin, 2011, Lin 등, 2017, Ohn과 Kim, 2019). 통계학 분야에서도 많은연구자들에 의해 딥러닝 또는 DNN의활용 ᄋ
ᅦ 대한 연구가 이루어지고 있는데, 특히 시계열분석에서의 예측과관련된 연구들이활발하게 진행되고 이
ᆻ다 (Lee, 2017, Kim과 Baek, 2018, Lee 등 2019, Choi 등 2019).
ᄀ
ᅵ계학습에서 다루는 문제는크게 회귀 (regression)와 분류 (classification)로 나누어진다. 통계적 가 서
ᆯ검정은귀무가설과 대립가설 중한 개의 가설을선택한다는 측면에서 분류문제로 생각할 수 있다. 본 노
ᆫ문에서는 통계적 가설검정을 기계학습의 분류문제로 간주하고 이에 대한 DNN의 활용 가능성과 이 ᄀ
ᅪ정에서 고려해야할 사안 등에 대하여 살펴보고자 한다. 이를 위하여 본 연구에서는 다음의 이표본 펴
ᆼ균 비교 문제에 대하여 DNN을학습시키고 이후 DNN을 이용한 검정과 기존의 이표본 t-검정 (two sample t-test)을비교하고자 한다.
X1, · · · , Xn ∼ i.i.d. N (µ1, σ12), Y1, · · · , Ym ∼ i.i.d. N (µ2, σ22), H0: µ1= µ2 v.s. H1: µ1 ̸= µ2.
ᄀ
ᅵ계학습, 특히 딥러닝을이용한 추론의 가장큰 특징은 많은 양의 자료로부터 문제 해결을위한 패 ᄐ
ᅥᆫ이나 특성을찾아낸다는것이다. 통계적 추론의 경우 적절한 형태의 통계량이 먼저 제시되고 제시된 ᄐ
ᅩ
ᆼ계량의 확률분포를기반으로 추론이 이루어지기 때문에 문제해결을 위한 통계량의 제시와 분포이론 ᄃ
ᅳ
ᆼ이 중요하게 여겨지게 된다. 반면 딥러닝은 데이터로부터 문제해결을 위한 능력을학습하기 때문에 DNN의 구조 (structure)와 더불어 많은양의 학습데이터 (훈련데이터, training data)가 추론의 핵심 ᄋ
ᅭ소가된다. 예를 들어, 위 이표본검정의 경우 통계적 추론은표본평균의 차이를이용하여 검정통계량 으
ᆯ구축한 후 분포이론을이용하여 검정통계량의확률분포를유도함으로써 가설검정을위한 기반을 마 ᄅ
ᅧᆫ한다. 한편, DNN을이용할 경우 귀무가설과 대립가설로부터 샘플들을생성하고 각각의 샘플에 귀무 ᄀ
ᅡ설과 대립가설을나타내는레이블 (label)을부여하여 학습데이터를 준비한 후 적절한 신경망을선택 ᄒ
ᅡ여 지도학습 (supervised learning)시킴으로써 가설검정을위한 분류기 (classifier)가 준비된다. 이때, ᄉ
ᅵᆫ경망을 학습시킬 자료가 많으면 많을수록 DNN의 학습결과가 향상되므로 많은양의 자료는 성공적 ᄋ
ᅵᆫ 딥러닝을위한 중요한 토대가된다. 가설검정과 기계학습에서의 분류에 대한 추가적인 비교는 Li와 Tong (2020)을참조하길 바란다.
보
ᆫ연구의 가장큰 목적은 딥러닝이 통계적 가설검정에활용될수 있는지를확인하는것이다. 앞서 언 ᄀ
ᅳ
ᆸ한 바와 같이 가설검정을 기계학습의 분류문제로 간주하고 시뮬레이션을 통하여 생성한 자료를이용 ᄒ
ᅡ여 DNN을학습시키고 가설검정에서의활용가능성을확인하고자 한다. 본 논문의 구성은다음과 같 ᄃ
ᅡ. 2절에서는위 이표본평균비교 검정에 대한 학습데이터 생성 및 DNN 학습과정을소개하고 학습결 ᄀ
ᅪ를기존의 이표본 t-검정과 비교한다. 그리고, 학습과정에서 고려해야할 이슈들을제시한다. 3절에서 ᄂ
ᅳᆫ 본연구의 결론 및 DNN 기반 검정의 장단점과 향후 연구방향 등에 대하여 소개한다.
2. 딥러닝을 이용한 통계적 가설검정
2.1. 학습데이터의 생성 및 심층신경망 학습 ᄆ
ᅩ수적 세팅에서는모분포의 형태가 주어지므로, 모수에 대한 적절한 범위를 가정하면 학습데이터를 ᄉ
ᅵ뮬레이션을 통하여 충분히 얻을수 있다. 본 실험에서는 위 이표본 가설검정의 모평균 µ1과 µ2를 - 10에서 10 사이의 값을, 모표준편차 σ1과 σ2에 대해서는 0.5에서 10 사이의 값을가정하였다. Figure
2.1은 본 연구에서 사용한 학습데이터의 형태로서, (X1, · · · , Xn, Y1, · · · , Ym)은 입력벡터 (input vec- tor)이고 (C1, C2)는 원-핫 (one-hot) 인코딩 형태의 출력벡터 (output vector)이다. 본연구에서는귀 ᄆ
ᅮ가설과 대립가설에서 각각 25,000개의 입력벡터를발생시켜 총 r = 50, 000개의 샘플을포함하는 학 ᄉ
ᅳ
ᆸ데이터를생성하였다. 귀무가설과 대립가설에서의 입력벡터는다음과 같이 발생시켰으며, 이때 출력 베
ᆨ터는귀무가설에서는 (C1, C2) = (1, 0),대립가설에서는 (C1, C2) = (0, 1)로 설정하였다.
– Input vector from H0
(i) µ ∼ U (−10, 10), σ1, σ2∼ i.i.d.U (0.5, 10).
(ii) X1, · · · , Xn ∼ i.i.d. N (µ, σ12), Y1, · · · , Ym ∼ i.i.d. N (µ, σ22).
– Input vector from H1
(i) µ1, µ2∼ i.i.d.U (−10, 10), σ1, σ2∼ i.i.d.U (0.5, 10).
(ii) X1, · · · , Xn ∼ i.i.d. N (µ1, σ21), Y1, · · · , Ym ∼ i.i.d. N (µ2, σ22).
ᄋ
ᅵ후로 보고되는내용은 n = 20, m = 30에 대한 결과이며, 이외의 n과 m의 경우는비슷한 결과가 얻 ᄋ
ᅥ져 소개를생략한다.
Figure 2.1 Training data set for classifying the null and alternative hypotheses
DNN은기본 신경망을 사용하였으며, 활성화 함수 (activation function)로 각 은닉층에서는 ReLu ᄒ
ᅡᆷ수를, 출력층에서는 분류문제에서 이용되는 softmax 함수를 사용하였다. 위 가설검정 문제는 분류 ᄋ
ᅴ 클래스가 귀무가설과 대립가설 두 가지이므로 출력층의 뉴런 (neuron)의 수는 2개로 설정된다. 여 ᄀ
ᅵ서 출력층의 두 뉴런의 값은 귀무가설과 대립가설을선택할확률로 해석되며, 따라서 계산된확률이
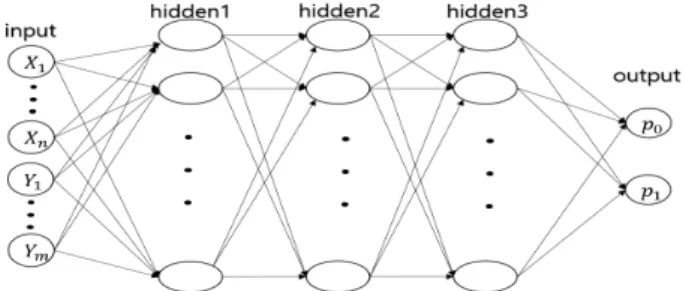
Figure 2.2 DNN structure for classifying the null and alternative hypotheses
ᄏ
ᅳᆫ 쪽의 가설이 선택된다. 손실함수 (loss function)로는교차 엔트로피 (cross entropy) 오차를사용하 ᄋ
ᅧᆻ으며 학습률 (learning rate)은 0.001로 설정하였다. Figure 2.2에서와 같이 50차원인 입력층과 각각 100개의 뉴런으로 구성된3개의 은닉층,그리고 2차원의 출력층으로 이루어진 DNN이 최종적으로 선택 ᄃ
ᅬ었다.
Figure 2.3 Plots of the cross entropy loss (L) and the accuracy (R) when dropout is not applied
Figure 2.4 Plots of the cross entropy loss (L) and the accuracy (R) of training data and validation data when dropout rate of 20% is applied
ᄉ
ᅵᆫ경망 학습에서 잘 알려져 있듯이 가중치 (weight)의 초깃값에 따라 학습결과가 크게 달라진다.이는 ᄎ
ᅩ깃값이 적절히 선택되지 않은경우 가중치와 편향 (bias)이 갱신되지 않아 올바른학습이 이루어지지 ᄋ
ᅡ
ᆭ기 때문이다. 본연구에서는 ReLU활성화 함수 사용시 주로 사용되는 He의 초깃값 (He 등, 2015)을 ᄉ
ᅡ용하였다. 즉,앞 계층의 노드의 수를 nin이라고 할 때 가중치에 대한 초기값은평균이 0이고 표준편 ᄎ
ᅡ가 q
2
nin인 정규분포로부터 발생된다. 편향에 대한 초깃값은 He의 균등분포 U(−q
6 nin,q
6 nin)에 ᄉ
ᅥ 발생시켰다. 또한 과대적합 (overfitting)을방지하기 위하여 모든노드의 일정비율을 랜덤하게 선택 ᄒ
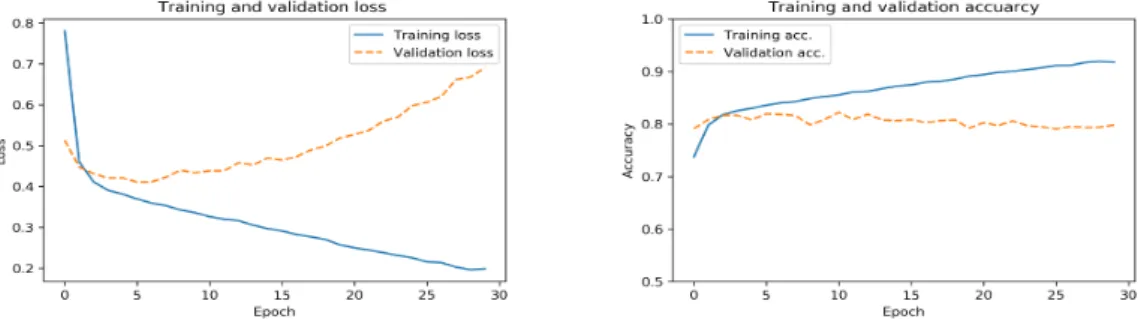
ᅡ여 배제시키는 dropout 기법을 적용하였다 (Srivastava 등, 2014). 본 실험에서는 dropout 비율을 20%로 하였으며, batch size를 250으로하여 30 epoch까지 학습시켰다.
Figure 2.3은 dropout을 적용하지 않았을 때의 교차엔트로피 손실값(좌)과 정확도(우)를 나타내고 이
ᆻ으며, Figure 2.4는 20%비율의 dropout을 적용했을때의 학습결과를 나타내고 있다. 여기서 검증 ᄃ
ᅦ이터 (validation data)는학습데이터와 같은방법으로 10,000개의 샘플을 발생시켜 얻었다. Figure 2.3에서확인할 수 있듯이 dropout이 적용되지 않은학습에서는 5 epoch 이전부터 과대적합이 발생하 ᄀ
ᅩ 있는반면, dropout이 적용된 경우에는학습기간 동안 과대적합이 일어나지 않는것을확인할 수 있 ᄃ
ᅡ.
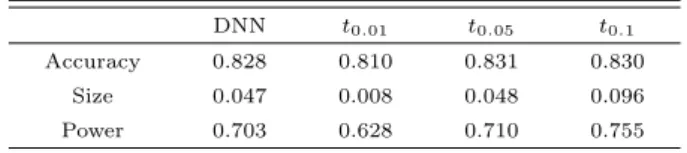
Table 2.1 Evaluation and comparison of DNN based test and t-test
DNN t
0.01t
0.05t
0.1Accuracy 0.828 0.810 0.831 0.830
Size 0.047 0.008 0.048 0.096
Power 0.703 0.628 0.710 0.755
2.2. 심층신경망을 이용한 가설검정 결과 ᄋ
ᅱ 2.1절에서 학습된 DNN의 검정 또는 분류 성능을 평가하기 위하여 새로운 시험데이터 (test data)를발생시키고, 이표본 t-검정과 비교하였다. 시험데이터는학습데이터와 같은방법으로 귀무가설 ᄀ
ᅪ 대립가설에서 각각 5,000개의 샘플, 총 10,000개의 샘플을발생시켰으며, 유의수준 1%, 5%,그리고 10%에서의 이표본 t-검정을함께 수행하였다. 분류의관점에서 보면, 유의수준 α에서의 t-검점은유의 화
ᆨ률 (p-value)이 α 보다 작으면 주어진 입력벡터를대립가설로, α보다 크면 귀무가설로 분류하게 된 ᄃ
ᅡ. 평가를위한 측도로서 정확도 (accuracy), 경험적 사이즈 (empirical size, 이하 사이즈), 그리고 경 ᄒ
ᅥ
ᆷ적 검정력 (empirical power, 이하 검정력)을 고려하였다. 여기서 정확도는 시험데이터의 입력벡터 10,000개를 올바르게 분류한 비율이며, 사이즈는귀무가설에서 발생된 5,000개의 입력벡터를귀무가설 ᄋ
ᅵ 아닌 대립가설로 잘못 분류한 비율, 검정력은대립가설에서 생성된나머지 5,000개의 샘플을대립가 서
ᆯ로 올바르게 선택한 비율로 계산된다.
Table 2.1에 DNN 기반의 검정과 유의수준별 이표본 t-검정의 정확도와 사이즈 및 검정력이 정리 ᄃ
ᅬ어 있다. 본 실험에서 훈련된 DNN 기반 검정의 정확도는 82.8%, 사이즈와 검정력은각각 4.7%와 70.3%정도로서 유의수준 5%의 이표본 t-검정과 비슷한 수준의 검정 성능을보였다. 이는 딥러닝이 통 ᄀ
ᅨ적 가설검정에서 충분히활용될수 있음을보여주는결과라고 할 수 있다. 참고로, 검정력이 70% 전 ᄒ
ᅮ로 나타난 이유는 대립가설에서 생성된 5,000개의 샘플 중 µ1과 µ2의 차이가 크지 않은 경우에서의 ᄋ
ᅩ분류로 인한 결과로서, 아래의 Figure 2.6에서확인하겠지만 그 차이가 클수록검정력은커지게된다.
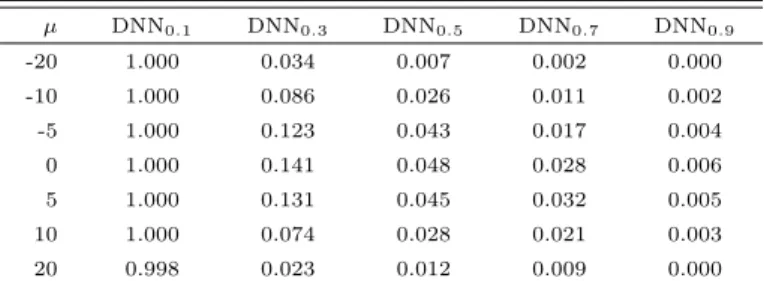
Table 2.2 Empirical sizes of DNN based test and t-test
µ DNN t
0.01t
0.05t
0.1-20 0.009 0.010 0.047 0.097
-10 0.027 0.008 0.045 0.094
-5 0.039 0.010 0.048 0.095
0 0.057 0.009 0.050 0.100
5 0.046 0.011 0.050 0.103
10 0.031 0.011 0.052 0.101
20 0.009 0.010 0.048 0.096
DNN을이용한 검정을 통계적인관점에서 평가하기 위하여 모평균에 따른사이즈와 검정력을살펴보 ᄋ
ᅡ
ᆻ다. 우선, 공통모평균 µ (= µ1 = µ2)에 대하여 각각 10,000개의 샘플을발생시키고 이로부터 각각 ᄋ
ᅴ 사이즈를계산하였다. 마찬가지로, µ1이 0과 20일 때 각각의 µ2에 대한 10,000개의 샘플로부터 검 저
ᆼ력을 계산하였다. 여기서 상기해야할 점은 평가하고 있는 DNN이 -10에서 10사이의 모평균에서 학 ᄉ
ᅳ
ᆸ된신경망이라는것이다. 이 범위를벗어난 모평균에서의 검정 성능을살펴보기 위하여 사이즈에서는 µ = ±20, 검정력에서는 µ1 = 20도 함께 고려하였다. 사이즈에 대한 결과는 Table 2.2와 Figure 2.5에, 거
ᆷ정력에 대한 결과는 Table 2.3과 Figure 2.6에 주어져있다.
Table 2.2를 보면, t-검정의 사이즈는모든 µ에 대하여 유의수준과 거의 비슷한 값으로 얻어졌으며,
Figure 2.5 Plot of empirical sizes of DNN based test and t-test
DNN 기반의 검정은 µ = 0에서 5.7%로 가장 높았고 µ가 ±20에 가까워질수록 작아지는경향을보였 ᄃ
ᅡ. 검정력에 대해서는 Table 2.3과 Figure 2.6에서 볼수 있듯이, µ1과 µ2의 차이가 클수록검정력이 노
ᇁ아지는이상적인 형태를보였으며, 특히 µ1 = 0인 경우 유의수준 5%와 10% t-검정 사이의 검정력을 ᄇ
ᅩ였다.
ᄇ
ᅩᆫ 실험의 DNN은전반적으로 학습되지 않은 입력벡터를귀무가설로 분류하도록학습된 것으로 추측 되
ᆫ다. 가정한 모수의 범위에서 멀어질수록제1종의 오류 (type I error)가 작아져 µ = ±20일 때는사이 ᄌ
ᅳ가 대략 1% 정도로관찰돠었으나, µ1= 20일 때의 검정력은 Figure2.6의 오른쪽그림에서 보는바와 ᄀ
ᅡ
ᇀ이 유의수준 1%의 t-검정의 검정력보다 더 작게관찰되어 사이즈에서 얻는이득보다 더큰검정력 손 시
ᆯ이 발생하였다. 이는학습이 이루어지지 않아서 나타난 결과로 해석할 수 있다.
Table 2.3 Empirical powers of the DNN based test and t-test
µ
1=0 µ
1=20
µ
2DNN t
0.01t
0.05t
0.1µ
2DNN t
0.01t
0.05t
0.10 0.072 0.010 0.046 0.102 20 0.014 0.008 0.049 0.098
2 0.362 0.160 0.306 0.403 18 0.051 0.162 0.305 0.399
4 0.749 0.475 0.670 0.761 16 0.359 0.480 0.671 0.759
6 0.936 0.760 0.895 0.937 14 0.797 0.755 0.890 0.934
8 0.987 0.921 0.973 0.986 12 0.963 0.921 0.976 0.988
10 0.997 0.980 0.995 0.998 10 0.993 0.979 0.996 0.998
12 1.000 0.995 0.999 1.000 8 0.999 0.995 0.999 1.000
Figure 2.6 Plots of empirical powers of the DNN based test and t-test when µ
1= 0 (L) and µ
1= 20 (R)
2.3. 심층신경망을 이용한 가설검정에서의 이슈
DNN기반의 가설검정에 대하여 다음의 사안들을고려해볼수 있다.
2.3.1. 학습데이터 생성 시 모수의 범위 보
ᆫ 실험에서는모수 µ1, µ2, σ1, σ2의 범위를미리 지정한 후 학습데이터를생성하였다. 위 2.2절의 Figure 2.5와 Figure 2.6에서확인하였듯이, 학습데이터가 실제 모수에 해당하는데이터를 충분히 포함 ᄒ
ᅡ고 있는경우 DNN 기반의 검정은 t-검정과 비슷한 수준의 검정능력을보였으나, 학습영역을벗어난 겨
ᆼ우에는검정력 손실이관찰되었다. 위 결과가 아니더라도, 보다 정확한 추론을위해서는당연히 실제 ᄆ
ᅩ수를포함한 범위에서 학습데이터를발생시켜야 할 것이다. 시계열분석의 정상 ARMA모형에서와 같 ᄋ
ᅵ, 모수의 범위가 한정된 경우에는주어진 범위의 모수를 균등하게 발생시킨 후 학습데이터를생성하면 되
ᆯ것이다. 반면, 모수의 범위가 특정되지 않은경우에는추정치를 이용하여 모수의 적당한 범위를 정 ᄒ
ᅡᆫ다며 보다 효율적인 학습데이터를생성할 수 있을것이다. 위 이표본검정의 경우 주어진 자료의 표 보
ᆫ평균과 표본 분산을 중심으로 적절한 범위, 예를 들면 99% 신뢰구간을또는상황에 따라 이보다 더 ᄇ
ᅩ수적인 구간을모수의 범위로 정할 수 있을것이다.지금까지는 균등분포를이용할 때 그 범위에 대하 ᄋ
ᅧ 언급하였으나, 베이지안 (Bayesian) 방법의 사후분포 (posterior distribution)로부터 모수를발생시 ᄏ
ᅵ는것도 좋은대안이될 것이다.
2.3.2. 학습데이터 생성 시 귀무가설과 대립가설의 구성비율 ᄋ
ᅱ DNN을 훈련시킨 학습데이터는귀무가설과 대립가설에서 생성된각각 5,000개의 샘플로 구성되 ᄋ
ᅥᆻ다. 귀무가설과 대립가설에서 발생된 샘플의 구성비율에 따라 학습결과가 달라질 것으로 예상되므로, 보
ᆫ소절에서는이에 대하여 살펴보고자 한다.
ᄒ
ᅡᆨ습데이터에서 귀무가설로부터 생성된 샘플의 비율을 p라고 할 때, 0.1,0.3,0.5,0.7,0.9의 p에 대하여 50,000개의 샘플로 이루어진 학습데이터를생성하였다. 예를 들어, p = 0.3은학습데이터의 총샘플개 ᄉ
ᅮ 중 30%는 귀무가설에서, 나머지 70%는 대립가설에서 발생된샘플임을 의미한다. 위 2.1절에서와 ᄀ
ᅡ
ᇀ은 형태의 DNN, 즉 3개의 은닉층으로 구성되면서 각 은닉층은 100개의 뉴런을 가지는 신경망을 동 이
ᆯ한 방법으로 각각의 학습데이터에 대하여 학습하시키고 위 2.2절에서처럼 사이즈와 검정력을계산하 ᄋ
ᅧᆻ다. Table 2.4와 Figure 2.7에 사이즈와 검정력 곡선이 주어져 있으며 이로부터 다음의 사항들을 관 ᄎ
ᅡᆯ할 수 있었다.
• 각각의 µ에 대하여 p가 커질수록사이즈는작아지는경향을보였다. 즉, 귀무가설에서 생성된데 ᄋ
ᅵ터가 많을수록귀무가설을선택할 가능성이 높게 학습되고 있음을확인할 수 있다.
• p가 작아질수록검정력은커지는경향을보였다. 즉,대립가설에서 생성된데이터가 많을수록대 리
ᆸ가설을선택하도록학습되고 있었다.
• 귀무가설의 비율이 가장 작은 p = 0.1인 경우 입력되는샘플의 종류에 상관없이 거의 대부분대립 ᄀ
ᅡ설을선택하도록학습되었다. 이 경우는 실제 가설검정에 사용될수 없음을의미한다.
• p = 0.9인 경우에는 p = 0.1과 반대로 대부분 귀무가설을 선택하도록 학습되어 검정력이 거의 0이될 것으로 예상되었으나, 이와 달리 모평균의 차이가 어느 정도 있을경우 대립가설을선택하 느
ᆫ결과를보였다. 하지만, 유의수준 1% t-검정보다 검정력이 낮았다.
• p = 0.5, 0.7인 경우 유의수준 5%의 t-검정과 비슷한 결과를보였다.
ᄋ
ᅱ 결과로부터 귀무가설의 비율이 대략 50% (또는 40%)에서 70% 사이가 되도록학습데이터를 준비하 ᄆ
ᅧᆫ 기존의 t-검정과 비슷한 수준의 결과를얻을수 있을것으로 판단된다. 이표본평균비교 외의 문제에
ᄃ
ᅢ해서도 비슷할 것으로 예상되나, 더 정확하게는위와 같이 p를달리하여 학습시키고 결과를확인한 후 ᄀ
ᅱ무가설의 구성비율을결정하면될 것이다.
Table 2.4 Empirical sizes of the DNN
pbased test µ DNN
0.1DNN
0.3DNN
0.5DNN
0.7DNN
0.9-20 1.000 0.034 0.007 0.002 0.000
-10 1.000 0.086 0.026 0.011 0.002
-5 1.000 0.123 0.043 0.017 0.004
0 1.000 0.141 0.048 0.028 0.006
5 1.000 0.131 0.045 0.032 0.005
10 1.000 0.074 0.028 0.021 0.003
20 0.998 0.023 0.012 0.009 0.000
Figure 2.7 Plot of empirical powers for different value of p (solid lines) compared to the powers of t-test (dotted lines)
2.3.3. 다중가설 검정으로의 확장 ᄐ
ᅩ
ᆼ계적 가설검정에서는귀무가설의 기각을위한 반증을찾기 때문에 귀무가설 하에서 기각역 또는유 ᄋ
ᅴ확률이 계산된다. 즉, 통계적 가설검정에서의 귀무가설은이론적 측면에서 특별한 의미를갖는다. 반 ᄆ
ᅧᆫ DNN을이용한 검정에서는귀무가설과 대립가설은 동등한 의미의 가설로서 두 가설의 구분은무의 ᄆ
ᅵ하게된다. 이는 DNN기반의 검정이 세 개 이상의 가설 중한 가설을선택하는 문제에서도 적용될수 이
ᆻ음을의미한다. 이에 대한 예로서 다음의 가설검정을생각해보자.
H0: µ1= µ2 v.s. H1: µ1< µ2 v.s. H2: µ1> µ2. ᄋ
ᅱ 가설을 검정하기 위해서는 Figure 2.8에서와 같이 3차원 출력층을 갖는 DNN을 고려할 수 있다.
Table 2.5는위 2.1절의 DNN에서 출력층만 3차원으로확장한 신경망을학습하여 얻은결과로서 각 가 서
ᆯ을 선택한 비율을나타내고 있다. 여기서 학습데이터는각각의 가설에서 생성된 샘플의 수가 같도록 ᄀ
ᅮ성하였다. DNN기반의 검정이 다중가설 문제에서도 적절하게 선택하고 있음을확인할 수 있다.
Figure 2.8 DNN for classifying multi hypotheses.
Table 2.5 Selection rates of H
0, H
1, and H
2µ
1µ
2H
0H
1H
2µ
1µ
2H
0H
1H
2µ
1µ
2H
0H
1H
220 20 0.900 0.041 0.059 0 2 0.642 0.353 0.005 2 0 0.568 0.004 0.428 10 10 0.911 0.043 0.046 0 4 0.248 0.752 0.001 4 0 0.191 0.000 0.809 5 5 0.935 0.039 0.026 0 6 0.064 0.936 0.000 6 0 0.045 0.000 0.955 0 0 0.963 0.032 0.006 0 8 0.013 0.988 0.000 8 0 0.008 0.000 0.992
3. 결론 보
ᆫ연구에서는 DNN을이용하여 이표본평균비교 검정을수행하였다. 시뮬레이션을 통하여 학습데 ᄋ
ᅵ터를 생성한 후 DNN을 선택하고 학습시켰으며, 이표본 검정문제에서는 기본 신경망으로도 충분한 거
ᆷ정성능을 보였다. 구체적으로 본 실험에서 학습된 DNN은 유의수준 5%의 이표본 t-검정과 비슷한 ᄉ
ᅮ준의 사이즈와 검정력을 보였다. 이를 통하여 딥러닝이 이표본 평균비교 검정에서도 충분히 활용될 ᄉ
ᅮ 있음을확인하였으며, 학습과정에서 고려해야할 사항들에 대하여 논의하였다.
ᄐ ᅩ
ᆼ계적 가설검정과 딥러닝을이용한 검정은검정을수행하는 원리가 다르기 때문에 이에 따른장단점 ᄋ
ᅵ 뚜렷하게 구분된다. 본연구를 통하여 파악된 DNN기반 검정의 장단점은다음과 같다. 우선, 검정 ᄐ
ᅩ
ᆼ계량 없이도 가설검정이 가능하다. 이는아직 해결하지 못한 검정문제에서 DNN이 대안적으로 사용 되
ᆯ수 있음을의미한다. 이에 대해서는추후 연구를 통하여확인해야할 것이다. 다중가설 검정문제로의 소
ᆫ쉬운확장 또한 DNN을이용한 검정의 장점이다. 한편, DNN을이용한 검정은사이즈와 검정력 등을 ᄋ
ᅵ론적으로 계산할 수 없어 검정에 대한 신뢰도를간접적으로확인해야 한다. 즉, 귀무가설과 대립가설 ᄀ
ᅡ
ᆨ각에서 발생된시험데이터를 통하여 사이즈와 검정력을경험적으로 파악해야하며 이 과정에서 시간이 ᄉ
ᅩ요될수 있다. 각각의 상황에 따라 DNN을 새로 세팅하고 학습시켜야하는 점과 학습데이터 준비 시 ᄆ
ᅩ수의 범위와 가설별 구성비율의 결정 또한 DNN 기반 검정의 단점이다. 이러한 점들을고려하여 다 ᄋ
ᅣᆼ한 검정문제에 대해서 딥러닝을적용해보고 기존 통계적 검정과 상호보안적 역할이 가능한지 등을살 ᄑ
ᅧ본다면 의미 있을것이다.
References
Bengio, Y. and Delalleau, O. (2011). On the expressive power of deep architectures. In International Conference on Algorithmic Learning Theory, 18-36.
Choi, Y., Lee, K. E. and Kim, G. (2019). Development and validation of a deep neural network for predicting
SPI of Nakdong river basin. Journal of the Korean Data & Information Science Society, 30, 1277-1287.
Funahashi, K. I. (1989). On the approximate realization of continuous mappings by neural networks. Neural Networks, 2(3), 183-192.
He, K., Zhang, X., Ren, S. and Sun, J. (2015). Delving deep into rectifiers: Surpassing human-level perfor- mance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, 1026-1034.
Kim, J. and Baek, C. (2018). Neural network heterogeneous autoregressive models for realized volatility.
Communications for Statistical Applications and Methods, 25(6), 659-671.
LeCun, Y., Bengio, Y. and Hinton, G. (2015). Deep learning. Nature, 521, 436-444.
Lee, J. H., Kim, J. S., Ahn, Y. H. and Cho, W. S. (2019). Daily forecasting of energy demand using SARIMA and LSTM method to support decision making on V2G. Journal of the Korean Data &
Information Science Society, 30, 779-795.
Lee, W. (2017). A deep learning analysis of the KOSPI’s directions. Journal of the Korean Data & Infor- mation Science Society, 28, 287-295.
Li, J. J. and Tong, X. (2020). Statistical hypothesis testing versus machine learning binary classification:
Distinctions and guidelines. Patterns, 1, 100115.
Lin, H. W., Tegmark, M. and Rolnick, D. (2017). Why does deep and cheap learning work so well? Journal of Statistical Physics, 168, 1223-1247.
Ohn, I. and Kim, Y. (2019). Smooth function approximation by deep neural networks with general activa- tion functions. Entropy, 21, 627.
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I. and Salakhutdinov, R. (2014). Dropout: A simple
way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15,
1929-1958.
2021, 32
(1)
,25–35
Statistical hypothesis testing using deep learning:
Focusing on two sample t-test †
Sangwoong Kim
1
· Junmo Song2
12Department of Statistics, Kyungpook National University
Received 28 December 2020, revised 15 January 2021, accepted 21 January 2021
Abstract
Hypothesis testing is a process of deciding whether to reject the null hypothesis.
When the null hypothesis is rejected, the alternative hypothesis is accepted. Since hy- pothesis testing chooses one between the null and alternative hypotheses, it can be viewed as a classification problem in machine learning. In this study, we investigate deep neural network as a classifier for classifying the null and alternative hypothe- ses. Particularly, focusing on testing for equality of two population means, we train deep neural network and then evaluate its performance compared to two sample t-test.
Through simulations, we demonstrate that our DNN trained in this study shows similar performance to level 5% two sample t-test. Additionally, we discuss some of the issues that arise when using DNN in hypothesis testing.
Keywords: Classification, deep learning, deep neural network, statistical hypothesis testing, testing for equality in two means, two sample t-test.
†
This research was supported by the Research Grants of Korea Forest Service (Korea Forestry Promotion Institute) project (No.2019149B10-2023-0301) and the National Research Foundation of Korea (NRF- 2019R1I1A3A01056924).
1
Graduate student, Department of Statistics, Kyungpook National University, Daegu 41566, Korea.
2