An Efficient Cache Management Scheme of Flash Translation Layer for Large Size Flash Memory Drives
8
0
0
전체 글
(2)
(3)
(4)
(5)
(6)
(7)
(8)
수치
관련 문서
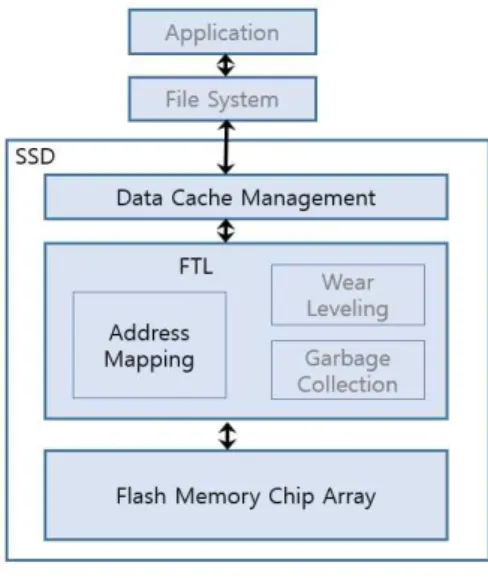
BFTL은 플래시 전환 계층 위에서 동작하는 소프트웨어 모듈이고 예약버퍼(reservation buffer) 와 노드 변환 테이블(node translation table)로 구성된다...
Jung, "A Log-based Flash Translation Layer for Large NAND Flash Memory," Proceedings of IEEE 8th International Conference on Advanced Communication Technology, Vol.
This paper presents an intelligent prefetching technique that significantly improves performance of hybrid fash-disk storage, a combination of flash memory and
Adaptive Mapping Information Management Scheme for High Performance Large Sale Flash Memory Storages
However, NAND flash cannot support in-place update so that it is mandatory to erase the entire block before overwriting the corresponding page. In order to
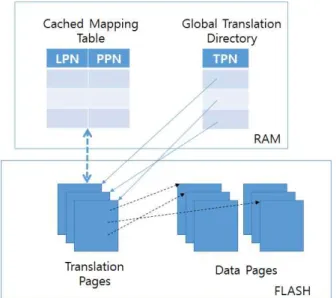
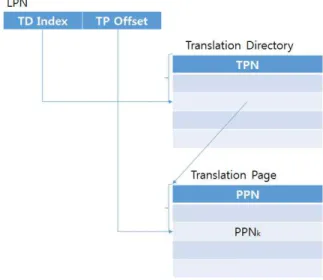
본 논문에서는 블록 변환 테이블을 이용하여 물리적 주소를 결정하고 특정 페이지를 이용하 여 결정된 블록내의 페이지 테이블을 이용하는 하이브리드 주소 변환(hybrid mapping)
