0.18㎛ CMOS 공정을 이용한 MEMS 마이크로폰용 이중 채널 음성 빔포밍 ASIC 설계
장영종*ㆍ이재학**ㆍ김동순**ㆍ황태호**
An ASIC implementation of a Dual Channel Acoustic Beamforming for MEMS microphone in 0.18㎛ CMOS technology
Young-Jong Jang*ㆍJea-Hack Lee**ㆍDong-Sun Kim**ㆍTae-ho Hwang**
요 약
음성 인식 제어 시스템은 사용자의 음성을 인식하여 주변 장치를 제어하는 시스템이다. 최근 음성 인식 제 어 시스템은 스마트기기 뿐만 아니라, IoT(: Internet of Things), 로봇, 차량에 이르기까지 다양한 환경에 적용 되고 있다. 이러한 음성 인식 제어 시스템은 사용자의 음성 외에 주변 잡음에 의한 인식률 저하가 발생한다.
이에 본 논문은 사용자의 음성 외에 주변 잡음을 제거하기 위하여 MEMS(: Microelectromechanical Systems) 마이크로폰용 이중 채널 음성 빔포밍 하드웨어 구조를 제안하였으며, 제안한 하드웨어 구조를 TowerJazz 0.18
㎛ CMOS(: Complementary Metal-Oxide Semiconductor) 공정을 이용하여 ASIC(: Application-Specific Integrated Circuit)을 설계하였다. 설계한 이중 채널 음성 빔포밍 ASIC은 48㎟의 Die size를 가지며, 사용자의 음성에 대한 지향성 특성을 측정한 결과 4.233㏈의 특성을 보였다.
ABSTRACT
A voice recognition control system is a system for controlling a peripheral device by recognizing a voice. Recently, a voice recognition control system have been applied not only to smart devices but also to various environments ranging from IoT(: Internet of Things), robots, and vehicles.
In such a voice recognition control system, the recognition rate is lowered due to the ambient noise in addition to the voice of the user. In this paper, we propose a dual channel acoustic beamforming hardware architecture for MEMS(: Microelectromechanical Systems) microphones to eliminate ambient noise in addition to user’s voice. And the proposed hardware architecture is designed as ASIC(: Application-Specific Integrated Circuit) using TowerJazz 0.18㎛ CMOS(: Complementary Metal-Oxide Semiconductor) technology. The designed dual channel acoustic beamforming ASIC has a die size of 48㎟, and the directivity index of the user’s voice were measured to be 4.233㏈.
키워드
Acoustic Beamforming, MEMS microphone, Noise Cancelling, Noise Reduction, PDM/PCM convertor.
음성 빔포밍, MEMS 마이크로폰, 잡음 제거, 잡음 감소, PDM/PCM 컨버터
** 전자부품연구원([email protected], [email protected] ,[email protected])
* 교신저자 : 전자부품연구원 SoC플랫폼연구센터 ㆍ접 수 일 : 2018. 07. 02
ㆍ수정완료일 : 2018. 08. 23
ㆍReceived : July. 02, 2018, Revised : Aug. 23, 2018, Accepted : Oct. 15, 2018 ㆍCorresponding Author : Young-Jong Jang
Korea Electronics Technology Institute Email : [email protected]
http://dx.doi.org/10.13067/JKIECS.2018.13.5.949
그림 2. PDM/PCM 컨버터 주파수 응답 Fig. 2 PDM/PCM convertor frequency response
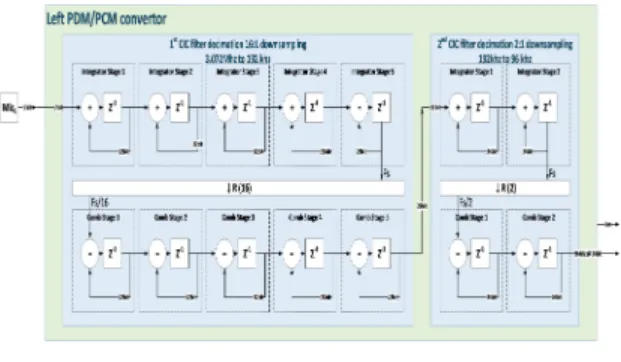
그림 1. PDM/PCM 컨버터 Fig. 1 PDM/PCM convertor
Ⅰ. 서 론
최근 스마트기기 뿐만 아니라, IoT, AI 스피커, 자 율주행 차량에 이르기까지 다양한 분야에서 음성 인 식 기반의 제어시스템에 대한 연구가 활발히 진행되 고 있다. 이러한 음성 인식 제어 시스템은 사용자의 음성 이외의 차량 엔진, 음악 소리와 같은 주변 잡음 신호 제거가 매우 중요하다. 이에 다양한 환경에서 안 정적인 잡음 제거 성능 확보를 위해 여러 잡음 제거 기술들이 연구되어 왔다[1-6].
잡음의 종류는 자동차 엔진 소리와 같이 주기적으 로 발생되는 정상성 잡음과 사람의 음성, 음악 소리와 같이 주기적인 특징이 없는 비정상성 잡음으로 분류 된다. 정상성 잡음 제거에는 위너 필터나 칼만 필터를 많이 사용하나, 이러한 필터들은 비정상성 잡음 제거 에는 효과가 적어 LCMV(: Linearly Constrained Minimum Variance) 알고리즘이나 RGSC(: Robust Generalized Sidelobe Canceller) 알고리즘을 주로 사 용한다[4, 7-9]. 두 알고리즘 모두 사용자 음성을 고 속 푸리에 변환시켜 주파수 영역으로 처리가 가능하 나, ASIC 하드웨어 크기의 최소화를 위하여 시간 영 역에서의 알고리즘 수식을 바탕으로 설계하였다. 또 한, RGSC 알고리즘은 MIC(: Multiple-Input Canceller) 부분 최적화에 따라 LCMV 알고리즘보다 나은 성능을 가진다[10]. 이에 본 논문에서는 RGSC 알고리즘 기반의 이중 채널 음성 빔포밍 하드웨어 구 조를 제안하였다. 제안한 이중 채널 음성 빔포밍 입력 은 PCM(: Pulse-Code Modulation) 형태의 음성 신호 를 사용하며, 이를 위해 MEMS 마이크로폰의 출력 PDM(: Pulse-Density Modulation) 음성 신호를 PDM/PCM 컨버터를 설계하여 처리하였다. 본 논문에 서는 이중 채널 PDM/PCM 컨버터와 이중 채널 음성 빔포밍 하드웨어를 통합하여, TowerJazz 0.18㎛
CMOS 공정을 통해 ASIC 칩을 설계하였으며, 설계한 ASIC 칩의 성능을 검증하였다.
Ⅱ. MEMS 마이크로폰 신호 변환 MEMS 마이크로폰은 사용자의 음성을 3.072㎒의 샘플링 주기를 갖는 1 bit의 PDM 데이터로 변환하여
출력한다. 출력된 PDM 데이터는 이중 채널 음성 빔 포밍 하드웨어 구조에 입력되기 전에 PCM 형태의 데이터로 변환되어야 한다. 본 논문에서는 MEMS 마 이크로폰의 3.027㎒, 1bit PDM 데이터를 96㎑, 24bis PCM 데이터로 변환하기 위하여 그림 1과 같이 2단 의 CIC(: Cascaded Integrator-Comb) 데시메이션 필 터를 사용하였다. 1단 CIC 데시메이션 필터는 16:1 다 운 샘플링을 위하여 5 stage, 1 샘플 방식으로 구성하 였으며, 2단 CIC 데시메이션 필터는 2:1 다운 샘플링 을 위하여 2 stage, 1 샘플 방식을 사용하였다.
CIC 데시메이션 필터는 그림2와 같이 저역 필터의 특성을 포함하고 있으며[11], 설계한 PDM/PCM 컨버 터의 주파수 응답을 보면 20㎑ 대역에서 –1.73㏈의 Normalized Gain을 가진다. 이를 통해 설계한 PDM/PCM 컨버터가 20㎐부터 20㎑의 가청주파수 내 에서 손실 없이 변환이 가능한 것을 확인할 수 있다.
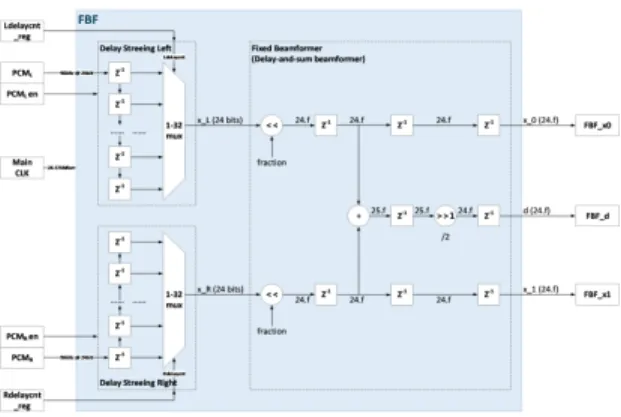
그림 4. FBF(: Fixed Beamformer) 블록 하드웨어 구조 Fig. 4 FBF(: Fixed Beamformer) block hardware
architecture
그림 3. RGSC 기반의 이중 채널 음성 빔포밍 하드웨어 구조
Fig. 3 RGSC based dual channel acoustic beamforming hardware architecture
Ⅲ. RGSC 기반의 이중 채널 음성 빔포밍 구조
본 논문에서 설계한 RGSC 기반 이중 채널 음성 빔포밍 하드웨어 구조는 RGSC 알고리즘을 시간 영 역에서의 수식으로 풀어 음성 빔포밍을 처리하도록 설계하였으며, 그림 3과 같이 FBF(: Fixed Beamformer) 블록, BM(: Blocking Matrix) 블록, MIC(: Multiple-Input Canceller) 블록으로 구성된다.
본 논문에서 제안한 하드웨어 구조는 각 연산 단계에 서 24 bits 소수부를 가지는 고정 소수점 연산을 수행 하도록 설계되었다.
3.1 FBF(: Fixed Beamformer) 블록 구조 FBF 블록은 PDM/PCM 컨버터에서 입력된 이중 채널 PCM 데이터를 이용하여 가상 음성 빔포밍 데 이터를 생성하며, 이를 식(1)로 표현한다.
(1)
이 때, 는 FBF 블록의 가상 음성 빔포밍 출력 데이터를 나타내며, 은 채널의 수, 는 번 째 채널 마이크로폰의 번째 입력 PCM 데이터를 나타낸다. 즉, 개의 마이크로폰에서 입력되는 PCM 데이터를 더한 다음 채널의 수로 나누어 출력을 구한 다. 본 논문에서 설계한 FBF 블록은 그림 4와 같이, MEMS 마이크로폰 간의 거리가 5 ~ 50 ㎝의 가변적
인 환경에서도 처리 가능하도록 설계되었다.
3.2 BM(: Blocking Matrix) 블록 구조
BM 블록은 FBF 블록에서 생성한 가상 음성 빔포 밍 데이터와 각 채널에서 입력되는 음성 데이터를 이 용하여 각 채널별 오류 값을 생성한다. 이 때, 8 단 CCAF(: Coefficient-Constrained Adaptive Filter) 필 터를 사용하여 오류 값 생성 비율을 실시간으로 변경 하여 필터 계수가 점차 안정화되도록 설계하였다.
BM 블록의 오류 값 생성은 식(2)로 표현된다. 또한, CCAF 필터 계수 벡터는 식(3)으로, 가상 음성 빔포 밍 데이터 벡터는 식(4)로 표현된다.
(2)
≐ (3)
≐ (4)
식(3), 식(4)의 기호는 vector transpose를 나타 낸다. 식 (2)의 는 번째 채널의 BM 블록 오 류 값, 는 번째 채널의 입력 음성 데이터를 나타낸다. 와 은 8 단 CCAF 필터를 사용했기 때 문에 8로 고정된다. 식(3)의 는 번째 채널의 CCAF 필터 계수 벡터이며, 식(4)의 는 FBF 블 록에서 출력된 가상 음성 빔포밍 데이터를 8 샘플 지연시켜 저장한 벡터이다. 즉, 8개의 가상 음성 빔포
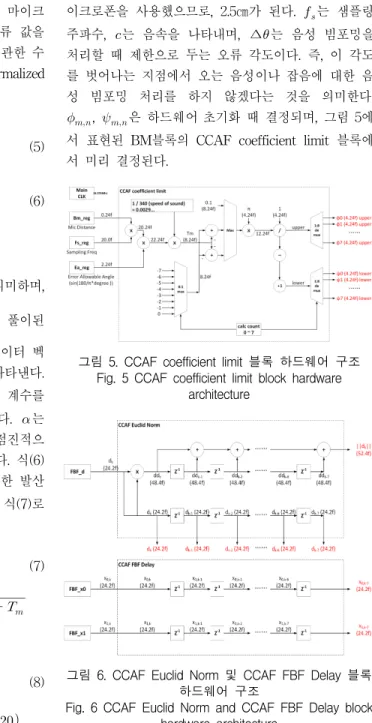
그림 5. CCAF coefficient limit 블록 하드웨어 구조 Fig. 5 CCAF coefficient limit block hardware
architecture
그림 6. CCAF Euclid Norm 및 CCAF FBF Delay 블록 하드웨어 구조
Fig. 6 CCAF Euclid Norm and CCAF FBF Delay block hardware architecture
밍 데이터와 8 단 CCAF 필터 계수를 곱하여 마이크 로폰에서 입력된 데이터에 뺄셈 연산하여 오류 값을 추출한다. BM 블록 CCAF 필터 계수 갱신에 관한 수 식은 식(5), 식(6)으로 표현하며, NLMS(: Normalized Least Mean Squares) 알고리즘을 사용한다.
′ ∥∥
(5)
for ′
for ′
′
(6)
식(5)에서 ∥∥은 Euclid norm을 의미하며,
∥∥
로 풀이된 다. 이는 이전에 입력된 가상 음성 빔포밍 데이터 벡 터를 Euclid norm 연산을 수행하는 것을 나타낸다.
′ 은 최종 필터 계수 갱신 전 임의의 필터 계수를 의미하며, 식(6)의 제한 조건 함수에 사용된다. 는 단계 크기를 나타내며 필터 계수의 갱신을 점진적으 로 할지, 급격하게 진행할지 결정하는 항목이다. 식(6) 에서 , 는 필터 계수가 갱신 시에 무한 발산 하지 못 하도록 막는 역할을 하며, 이 값은 식(7)로 표현된 수식에 의해 결정된다.
(7)
max
∆ (8)
×
× sin
×
위의 식(7), 식(8)은 하드웨어 초기화 단계에서 결 정되는 것으로, 은 이중 채널 MEMS 마이크로폰의 가운데에서 각 마이크로폰과의 간격을 나타내는 것으 로 본 논문에서는 5cm 간격의 이중 채널 MEMS 마
이크로폰을 사용했으므로, 2.5㎝가 된다. 는 샘플링 주파수, 는 음속을 나타내며, ∆는 음성 빔포밍을 처리할 때 제한으로 두는 오류 각도이다. 즉, 이 각도 를 벗어나는 지점에서 오는 음성이나 잡음에 대한 음 성 빔포밍 처리를 하지 않겠다는 것을 의미한다.
, 은 하드웨어 초기화 때 결정되며, 그림 5에 서 표현된 BM블록의 CCAF coefficient limit 블록에 서 미리 결정된다.
그림 6은 CCAF의 Euclid Norm을 연산하는 블록 과 FBF 블록에서 출력되는 가상 음성 빔포밍 데이터 를 8 샘플 지연시켜 저장하기 위한 블록을 나타내며, 각 블록의 출력은 그림7의 채널별 오류 값 생성 및 CCAF 필터 계수 갱신에 사용된다.
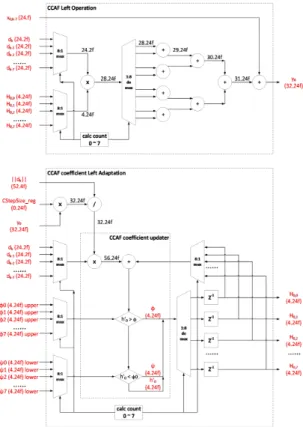
그림 7. CCAF Operation 및 CCAF Coefficient Adaptation 블록 하드웨어 구조 Fig. 7 CCAF Operation and CCAF Coefficient
Adaptation block hardware architecture
그림 8. NCAF Euclid Norm 및 NCAF FBF Delay 블록 하드웨어 구조
Fig. 8 NCAF Euclid Norm and NCAF FBF Delay block hardware architecture
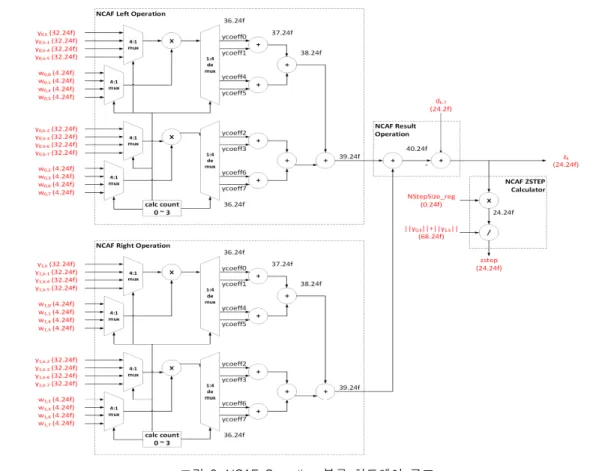
3.3 MIC(: Multiple-Input Canceller) 블록 구조 MIC 블록은 BM 블록에서 생성한 각 채널별 오류 값을 반영 비율에 따라 계산하고 이를 모두 합한 뒤, FBF 블록에서 생성한 가상 음성 빔포밍 데이터에 빼 서 최종 음성 빔포밍 데이터를 구한다, 이 때, 8 단 NCAF(: Norm-Constrained Adaptive Filter) 필터를 사용하여 오류 값 반영 비율을 실시간으로 변경하여 필터 계수가 점차 안정화되도록 설계하였다. MIC 블 록의 오류 값 반영은 식(9)로 표현된다.
(9)
≐ (10)
≐ (11)
식(10), 식(11)의 기호는 vector transpose를 나 타낸다. 식(9)의 는 MIC 블록에서 출력되는 최 종 음성 빔포밍 데이터를 나타내며, 는 FBF 블록에서 출력되는 가상 음성 데이터를 나타낸다. 와 은 8 단 NCAF 필터를 사용했기 때문에 8로 고 정된다. 식(10)의 는 번째 채널의 NCAF 필 터 계수 벡터이며, 식(11)의 는 BM 블록에서 출력된 오류 값을 8 샘플 지연시켜 저장한 벡터이다.
즉, 8개 오류 값을 8 단 NCAF 필터 계수와 곱하여 FBF 블록에서 생성한 가상 음성 빔포밍 데이터에 뺄 셈 연산하여 최종 음성 빔포밍 데이터를 추출한다.
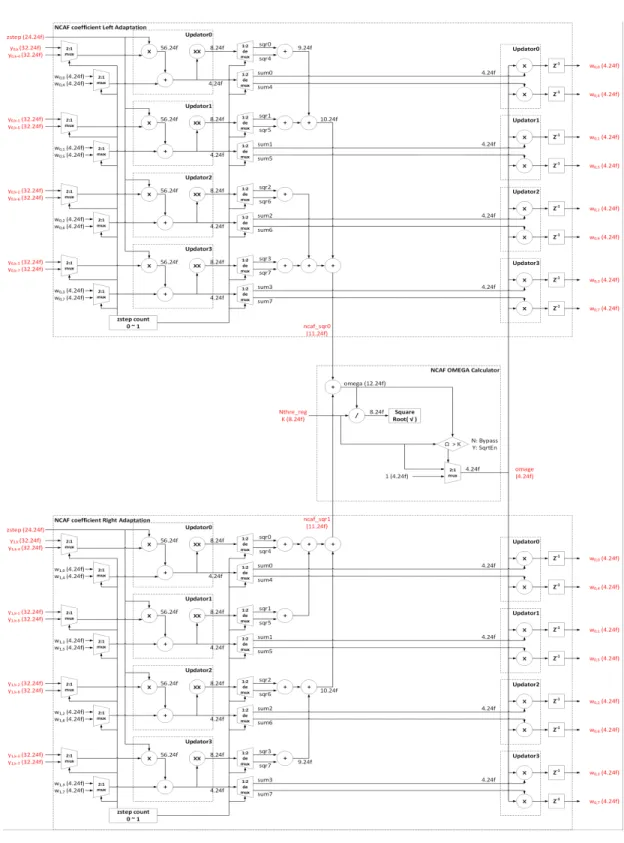
MIC 블록 NCAF 필터 계수 갱신에 관한 수식은 식 (12), 식(13), 식(14)로 표현하며, NLMS(: Normalized Least Mean Squares) 알고리즘을 사용한다.
′
∥∥
(12)
그림 9. NCAF Operation 블록 하드웨어 구조 Fig. 9 NCAF Operation block hardware architecture
∥′ ∥ (13)
′ for
′
(14)
식(12), 식(13)에서 ∥∥은 Euclid norm을 의미하 며, ∥∥
로 풀이 된다. 이는 이전에 채널별 오류 값 벡터를 Euclid norm 연산을 수행하는 것을 나타낸다. 식(12)의 ′ 은 최종 필터 계수 갱신 전 임의의 필터 계수를 의미 하며, 식(14)의 제한 조건 함수에 사용된다. 는 단계 크기를 나타내며 필터 계수의 갱신을 점진적으로 할
지, 급격하게 진행할지 결정하는 항목이다. 식(14)의
는 필터 계수가 갱신 시에 무한 발산하지 못 하도 록 막는 역할을 하며, 음성 빔포밍 하드웨어 사용자가 임의로 지정한다. 본 논문에서는 0.5를 값으로 사 용하였다. 본 논문에서 제안하는 이중 채널 음성 빔포 밍 하드웨어 구조에서 MIC 블록은 8 단 NCAF 필터 를 사용하였기 때문에 그림 8과 같이 BM 블록에서 출력되는 오류 값과 FBF 블록에서 출력되는 가상 음 성 빔포밍 데이터를 8 샘플 지연시켜 저장한 후 처리 해야 된다. MIC 블록의 최종 음성 빔포밍 출력 연산 은 그림 9와 같이 하드웨어 크기를 최소화하기 위하 여 1개의 연산 블록을 8번 반복하여 처리하는 공유형 구조로 설계하였다. MIC 블록에서 최종 음성 빔포밍 데이터가 결정되면, 이를 바탕으로 NCAF 필터 계수 에 대한 갱신을 진행한다. 그림 10은 NCAF 필터 계 수의 갱신 연산을 수행하는 블록으로서 하드웨어 최
그림 10. NCAF Coefficient Adaptation 블록 하드웨어 구조
그림 12. 이중 채널 음성 빔포밍 ASIC 실험 환경 Fig. 12 Dual Channel acoustic beamforming ASIC
experiment environment
그림 13. 뉴스 스피치와 화이트 잡음 실험 Fig. 13 News speech and white noise experiment 그림 11. 이중 채널 음성 빔포밍 ASIC 레이아웃 및
패키지
Fig. 11 Dual channel acoustic beamforming ASIC layout and package
소화를 위하여 4개의 갱신 연산기를 공유하는 구조로 설계하였다.
3.4. 이중 채널 음성 빔포밍 ASIC 설계
본 논문에서 제안한 RGSC 기반의 이중 채널 음성 빔포밍 ASIC 칩은 TowerJazz 0.18㎛ CMOS 공정을 사용하여 설계되었으며, 4.8㎟의 다이 크기를 가진다.
패키지는 64 핀의 QFN 타입으로 제작되었다. 그림 11은 설계한 ASIC의 레이아웃과 패키지를 나타낸 것 이다.
Ⅳ. 이중 채널 음성 빔포밍 ASIC 실험 4.1 실험 환경
본 논문에서 설계한 이중 채널 음성 빔포밍 ASIC 의 실험 환경은 그림 12와 같다. 이중 채널 음성 빔 포밍 ASIC 칩 검증용 보드, 5 ㎝간격으로 장착된 2개 의 MEMS 마이크로폰 및 5도 단위로 회전이 가능한 회전 장치로 구성된다. 또한, 스피커에서 출력되는 소 리의 음압을 MEMS 마이크로폰과 동일한 위치에서 음압 측정기로 측정하였다.
4.2 사용자 음성과 화이트 잡음 음성 빔포밍 첫 번째 실험은 전방 0도 방향 스피커에서 70㏈ 음 압으로 뉴스 소리, 45도 방향 스피커에서 같은 음압의 화이트 잡음을 출력시켜 이중 채널 음성 빔포밍 ASIC의 잡음 제거 성능을 측정하였다. 그림13은 MEMS 마이크로폰을 통해 입력된 음성과 이중 채널 음성 빔포밍 ASIC의 출력 음성을 스펙트럼 아날라이
이트 잡음만 측정한 차트이고, 가운데 2개는 입력된 뉴스 소리만 측정한 차트이다. 아래 3개 차트 중 LEFT, RIGHT는 뉴스 소리와 화이트 잡음이 섞인 입력 음성을 측정한 차트이고, BF는 음성 빔포밍 처 리 후 출력 음성을 나타낸 차트이다. 스펙트럼 차트를 통해 화이트 노이즈 대비 뉴스 소리가 10㏈ 증가한 것을 확인할 수 있었다.
4.3 지향성 이득 측정
두 번째 실험은 설계한 이중 채널 음성 빔포밍 ASIC의 지향성 이득(directivity index)을 측정하였다.
전방 0도 방향 스피커에서 70㏈ 음압의 뉴스 소리를 출력시키고, 그림 14와 같이 –90도에서 90도까지 5도 단위로 회전시켜 이중 채널 음성 빔포밍 ASIC의 출 력 음성 37개를 획득하였다. 획득한 37개의 음성 데
그림 14. -90 ~ 90도, 5도 단위 회전 Fig. 14 –90 ~ 90 degree rotation by 5 degree
그림 15. 이중 채널 음성 빔포밍 ASIC의 지향성 이득 Fig. 15 Directivity Index of dual channel acoustic
beamforming ASIC
이터를 사용하여 매트랩에서 지향성 이득을 계산하였 으며, 그림 15와 같은 사용자 음성에 대한 지향성 이 득 4.233㏈를 도출하였다.
Ⅴ. 결 론
본 논문은 음성 인식 제어 시스템에서 주변 잡음 신호 제거를 위한 이중 채널 음성 빔포밍 ASIC 설계 에 대한 연구이다. MEMS 마이크로폰의 출력 PDM 음성 신호를 이중 채널 음성 빔포밍 ASIC에서 사용 하기 위해 PDM/PCM 컨버터를 내장하였다. 또한, RGSC 기반 이중 채널 음성 빔포밍 하드웨어 구조를 제안하였으며, 제안한 하드웨어 구조를 기반으로 TowerJazz 0.18㎛ CMOS 공정을 사용하여 ASIC 칩
으로 설계하였다. 설계한 ASIC 칩의 성능을 측정하여 지향성 이득 4.233㏈를 도출하였으며, 사용자 음성과 화이트 잡음이 섞여있는 환경에서 사용자의 음성이 10㏈ 증가하는 것을 확인하였다. 이를 통해 설계한 ASIC 칩이 사용자의 음성 외에 주변 잡음을 제거하 는 데 효과적임을 확인하였다.
감사의 글
위 논문은 “2018년 한국전자통신학회 봄철학술 대회 우수논문”입니다. 본 논문은 2018년도 산업 통상자원부 및 산업기술평가관리원(KEIT) 연구 비 지원에 의한 연구임(‘10070055’, 높은 신호대 잡음비를 갖는 지향성 MEMS 마이크로폰 모듈 개발‘).
References
[1] M. Brandstein and D. Ward, Microphone arrays: signal processing techniques and applications. Berlin, Heidelberg: Springer Science & Business Media, 2013.
[2] P. C. Loizou, Speech enhancement: theory and practice. New York: CRC press, 2013.
[3] J. Benesty, C. Jingdong, and H. Yiteng, Microphone array signal processing, Berlin, Heidelberg: Springer Science & Business Media, 2008.
[4] O. Frost, “An algorithm for linearly constrained adaptive array processing,” Proc.
of the IEEE, vol. 60, no. 8, Aug. 1972, pp.
926-935.
[5] V. Yoganathan and T. Joir, “Multi-microphone adaptive neural switched Griffiths-Jim beamformer for noise reduction,” In Signal Processing (ICSP), 2010 IEEE 10th Int. Conf. on.
IEEE, Beijing, China, Oct. 2010, pp. 299-302.
[6] C. Lee and D. Kim, “Adaptive Noise Reduction of Speech Using Wavelet Transform,” J. of the Korea Institute of Electronic Communication Sciences, vol. 4, no. 3, Sept. 2009, pp. 190-196.
[7] J. Choi, “Noise Reduction Algorithm in
Speech by Wiener Filter,” J. of the Korea Institute of Electronic Communication Science, vol. 8, no. 9, Sept. 2013. pp. 1293-1298.
[8] O. Hoshuyama, A. Sugiyama, and A. Hirano,
“A Robust Adaptive Beamformer with a Blocking Matrix Using Coefficient-constrained Adaptive Filters,” IEICE Trans. Fundamentals, vol. E82-A, no. 4, Apr. 1999, pp. 640-647.
[9] O. Hoshuyama, A. Sugiyama, and A. Hirano,
“A robust adaptive beamformer for microphone arrays with a blocking matrix using constrained adaptive filters,” IEEE Trans. Signal Processing, vol. 47, no. 10, Oct.
1999, pp. 2677-2684.
[10] S. Gannot, D. Burshtein, and E. Weinstein,
“Signal enhancement using beamforming and nonstationarity with applications to speech,”
IEEE Trans. Signal Processing, vol. 49, no. 8, Aug. 2001, pp. 1614-1626.
[11] E. Hogenauer, “An economical class of digital filters for decimation and interpolation,“ IEEE Trans. Acoustics, Speech, and Signal Processing, vol. 29, no. 2, Apr. 1981, pp. 155-162.
저자 소개
장영종(Young-Jong Jang) 2013년 경북대학교 IT대학 전자공 부 졸업(공학사)
2015년 경북대학교 대학원 전자공 학부 졸업(공학석사)
2015년∼현재 전자부품연구원 SoC플랫폼연구센터 전임연구원
※ 관심분야 : 음성 신호 처리, SoC 설계
이재학(Jea-Hack Lee) 2011년 아주대학교 대학원 전자공 학과 졸업(공학석사)
2017년 아주대학교 대학원 전자공 학과 졸업(공학박사)
2017년∼현재 전자부품연구원 SoC플랫폼연구센터 선임연구원
※ 관심분야 : SoC 설계, 유무선 통신시스템
김동순(Dong-Sun Kim) 1999년 인하대학교 전자재료공학과 졸업(공학석사)
2005년 인하대학교 미디어시스템학 과 졸업(공학박사)
2011년~2014년 인하대학교 정보통신공학과 겸임 교수
1999년∼현재 전자부품연구원 SoC플랫폼연구센터 센터장
※ 관심분야 : 임베디드 하드웨어, 멀티미디어 SoC 설계
황태호(Tae-Ho Hwang) 2000년 한국외국어대학교 컴퓨터공 학과 졸업(공학석사)
2013년 한국외국어대학교 컴퓨터공 학과 졸업(공학박사)
2000년∼현재 전자부품연구원 SoC플랫폼연구센터 수석연구원
※ 관심분야 : 실시간 운영체제, 뉴로모픽 컴퓨팅, 이기종 컴퓨팅