데이터 수집방법에 따른 딥러닝 기반 산림수종 자동분류 정확도 변화에 관한 연구
김보미
1
⋅우희성2
⋅박주원2
*1
충청남도 산림자원연구소,2
경북대학교 산림과학· 조경학부A Study on the Performance of Deep learning-based Automatic Classification of Forest Plants: A Comparison of Data Collection Methods
Bomi Kim 1 , Heesung Woo 2 and Joowon Park 2
*1 Chungnam Forest Environment Research Institute, Sejong 30085, Korea.
2 School of Forestry Sciences and Landscape Architecture, Kyungpook National University, Daegu 41566, Korea.
요 약: 최근 급변하는 컴퓨터 기술의 발전을 통해 컴퓨터 비전과 머신러닝을 이용한 사물인식 기법이 다양한 학문 분야에서
사용되고 있다. 국내의 연구 사례를 보면 주로 대면적 산림을 분석하기 위한 이미지 학습 및 객체인식 기법이 사용되는 반면 개체목 단위의 수종 분류 및 특징을 학습하는 연구는 아직 미미한 실정이다. 이에 본 연구는 한국의 침엽수 5종을 대상으로 이미지 학습을 통한 자동분류 연구의 가능성을 분석해 보았다. 데이터 형태에 따른 분류 결과의 차이를 분석하기 위하여 산림전 문가가 직접 촬영한 영상(D1)과 웹크롤링을 이용한 영상(D2)을 사용하여 수종 분류를 실시하였다. 그 결과 D1과 D2의 분류 정확도에 유의미한 차이가 있는 것으로 나타났으며, D1은 D2보다 높은 분류 정확도를 나타냈다. 또한, D2의 분류 정확도를 높이기 위해서는 검열되지 않은 영상 데이터의 노이즈를 줄이기 위한 추가 데이터 필터링 기법이 필요한 것으로 사료된다.
Abstract: The use of increased computing power, machine learning, and deep learning techniques have dramatically increased in various sectors. In particular, image detection algorithms are broadly used in forestry and remote sensing areas to identify forest types and tree species. However, in South Korea, machine learning has rarely, if ever, been applied in forestry image detection, especially to classify tree species. This study integrates the application of machine learning and forest image detection; specifically, we compared the ability of two machine learning data collection methods, namely image data captured by forest experts (D1) and web-crawling (D2), to automate the classification of five trees species. In addition, two methods of characterization to train/test the system were investigated. The results indicated a significant difference in classification accuracy between D1 and D2: the classification accuracy of D1 was higher than that of D2. In order to increase the classification accuracy of D2, additional data filtering techniques were required to reduce the noise of uncensored image data.
Key words: deep learning, image detection, classification, identification, tree species
서 론
1)
생물다양성협약 이후 생명공학의 발달과 식물자원의
* Corresponding author E-mail: [email protected] ORCID
Bomi Kim https://orcid.org/0000-0002-2617-8953 Heesung Woo https://orcid.org/0000-0002-7649-0953 Joowon Park https://orcid.org/0000-0001-7505-6912
경제적 가치가 증대하면서 국가별 식물주권 확보의 중요 성이 증가하고 있다. 식물자원은 식량, 건축재, 의약품 뿐 아니라 인간 생활에 유용한 물질을 추출하는 데 이용되 고 있다. 또한, 식물주권을 확보하고 자산으로 관리하는 것은 국가의 경제적 이익과(로열티, 특허 등) 직·간접적 으로 연관되어 있어 국내에 자생하는 식물의 특징을 정 확하게 이해하고 자원화 하는 것은 또 다른 형태의 국가 의 큰 경제적 자산이다.
식물을 분류하는 방법은 Engler, APG III 등 식물분류
J OURNAL OF K OREAN S OCIETY OF F OREST S CIENCE ISSN 2586-6613(Print), ISSN 2586-6621(Online) http://e-journal.kfs21.or.kr
https://doi.org/10.14578/jkfs.2020.109.1.2323
체계에 따라 연구자가 직접 분류하는 방법을 통상적으로 사용하고 있으나 기존의 방법은 분류자의 식물분류학 학 습수준에 많은 영향을 받는다는 한계가 있다.
이를 개선하기 위해 식물의 주요 분류 요소 중 하나인 잎의 이미지 데이터를 이용하여 머신러닝 기법을 도입한 연구가 세계적으로 활발하게 진행되고 있다. 이와 관련된 연구로는 잎의 모양에 따른 형태적 특징을 추출하여 식물 을 분류하거나(Kumar et al., 2012; Aakif and Khan, 2015;
Kalyoncu and Toygar, 2015; Hall et al., 2015; Lee et al., 2017; Zhang et al., 2017) 픽셀분포를 기반으로 잎 표면의 질감에 따라 식물을 분류하는 연구(Backes et al., 2009;
Beghin et al., 2010; Rashad et al., 2011; Olsen et al., 2015) 엽맥의 패턴을 이용하여 콩과 등 식물을 판별하는 연구 (Charters et al., 2014; Larese et al., 2014; Grinblat et al., 2016) 등이 있다.
하지만 이들 연구는 주로 활엽수를 중심으로 형태적 차이가 뚜렷한 잎 이미지를 대상으로 분류하였기 때문에 침엽수에 적용이 어렵고 시계열에 따른 잎의 형태적 변 화를 반영할 수 없다는 한계가 있다.
최근에는 딥러닝 기반의 이미지 자동 인식 기술이 발 달하면서 수종별로 수집된 다양한 이미지 데이터에서 잎, 꽃 등 부분적 특징을 추출하거나 배경을 삭제하는 등 의 과정이 없이 사람이 인지하는 것처럼 식물을 자동으 로 분류하는 연구를 독일, 미국, 일본, 프랑스 등에서 하 였다(Lee et al., 2017; Liu et al., 2018).
하지만 이러한 노력에도 불구하고 식물 종 이미지 분 류연구는 여전히 자동 인식의 정확도 향상에 많은 한계 가 있다. 최근 개인 블로그 이용의 발달로 식물학자 또는 식물애호가의 블로그와 웹 페이지, 온라인 식물 소매상 등을 통해 인터넷상의 식물 영상에 관한 자료가 증가하 고 있고 이러한 데이터를 이용하여 Goeau et al.(2017)은 딥러닝 기법을 이용한 식물 종 이미지를 자동분류한 학 자들의 연구를 정리하고 이미지의 질적 차이에 따른 학 습 정확도를 리뷰하였으며 이 리뷰를 통해 웹크롤링을 이용한 식물 이미지 데이터도 기계학습을 통한 이미지 분류에 활용 가능하다고 평가하였다.
반면 국내의 경우 국내 서식종의 분류를 위한 이미지 자동 인식 연구, 특히 수목을 대상으로 하는 연구는 매우 취약한 실정이다. 국내 연구 사례를 보면, 딥러닝 기반의 DenseNet 알고리즘을 이용해 식물 잎을 분류하는 연구 (Park et al., 2018), 전이학습을 이용한 외래식물 분류연 구(Kim et al., 2018) 등이 있었으나 국내 서식하는 수목 의 이미지 데이터에 관한 연구는 매우 취약 한 실정이다.
이에 본 연구에서는 국내에 서식하는 5가지의 침엽수종 (개비자나무 Cephalotaxus koreana Nakai, 구상나무 Abies
koreana Wilson, 분비나무 Abies nephrolepis (Trautv.) Maxim., 전나무 Abies holophylla Maxim., 주목 Taxus cuspidata Siebold & Zucc.)의 이미지 데이터를 기반으로 딥러닝 기법 의 이미지 자동분류 연구의 가능성을 분석해 보았다. 더불어 두 가지 이미지 구축 방법에 따른 이미지 자동분류 결과 정확도를 비교하여 향후 국내 자생하는 침엽수종의 이미지 자동 인식 시스템 구축에 적합한 데이터 수집 방법을 제시하 고자 한다.
자료 및 연구방법
1. 자료 수집
본 연구의 전체적인 흐름은 Figure 1과 같다. 두 가지 방법으로 데이터를 수집하고, 각 수집된 데이터별 CNN 학습 및 검증을 통한 최종 테스트 영상 분류 분석 결과에 대한 정확도를 비교하였다.
분석 대상 수종은 꽃과 잎의 특징이 뚜렷한 활엽수보 다 침엽수의 이미지 자동분류 난이도가 높은 것을 고려 하여 국내 자생하는 침엽수 5종(개비자나무, 구상나무, 분비나무, 전나무, 주목)으로 선정하였다. 데이터 수집 방 법의 차이에 따른 이미지 분류 정확도 차이를 비교하기 위 하여 두 가지 방식으로 이미지 데이터를 구축하였다. 본 연구의 대상 수종에 관한 잎의 사진은 Figure 2와 같다.
2. 산림전문가가 직접 촬영한 이미지 데이터 수집 및 구축 방법(D1)
첫 번째 이미지 데이터 수집 방법은 대상 수종의 전경, 잎, 꽃, 열매 등을 시계열에 따라 산림전문가가 직접 촬영 하여 수집하는 방법이다. 수집된 이미지 데이터는 수종별 100개로 총 500개이다. 연구에 사용된 전문가가 사용한 이미지의 예시는 Figure 3과 같다. 수집된 이미지 데이터 는 모델 생성과정에서 사용되는 훈련(Training), 검증 (Validation) 데이터와 테스트 시 사용하는 테스트(Test) 데 이터로 구분하였으며 전체 이미지 데이터 중 10%를 테스 트용 데이터로 사용하였다. 훈련 데이터는 모델을 학습시 키는 자료이며, 검증 데이터는 학습 중 모델의 정확도 및 훈련 정도 평가 시 사용되는 자료이다. 테스트 데이터는 생성된 모델의 최종 성능을 평가하기 위하여 사용되었다.
3. 웹크롤링(Web-crawling) 기술을 이용한 이미지 데이터 수집 및 구축 방법 (D2)
두 번째 이미지 데이터 수집방법은 웹크롤링(Web- crawling) 기술을 이용해 웹사이트에서 대상 수종의 이미 지를 일괄 수집하는 방법으로 국내의 대표적 포털망인
‘구글’과 ‘네이버’에서 추출한 이미지를 사용하였다. 웹크 롤링을 이용한 자료수집을 위해 Python 3.6을 이용하였고,
Figure 1. Overall research flowchart from data collection to analysis.
Figure 2. Five species of coniferous trees with difficulty in visual identification used in the study (a. Cephalotaxus koreana Nakai, b. Abies koreana E.H.Wilson, c. Abies nephrolepis (Trautv. ex Maxim.) Maxim., d. Abies holophylla Maxim., e. Taxus cuspidata
Siebold & Zucc.).
Figure 3. Example of plant image data taken by forest expert.
Figure 4. Coding for web crowling using python beautifulsoup, requests library.
Figure 5. Examples of image construction data collected from naver and google servers using wep-crowling technique.
개발환경은 Visual Studio 2017을 이용하였다(Figure 4).
웹크롤링 기법을 이용하여 수집된 데이터는 Figure 5와 같다. 이미지 분류에 딥러닝 기법을 사용할 경우 학습 이 미지 데이터가 많을수록 이미지 자동분류 모델 성능 향 상에 유리하지만, 산림전문가가 직접 촬영한 이미지 데 이터 수가 수종별 100개로 한정되었기 때문에 이미지 데 이터의 양적 차이에 따른 영향을 최소화하기 위해 웹사 이트에서 추출된 이미지 중 수종별 100개씩 500개를 선 정하여 학습에 사용하였다. 이때 대상 수종과 연관도가 낮은 이미지를 제외하고 해상도가 높은 이미지를 우선으 로 선정하였다. 수집한 이미지 데이터는 훈련, 검증, 테스 트용 데이터로 구분하고 전체 데이터의 10%를 테스트 데이터로 사용하였다.
자료 분석
1. 학습모델
학습을 위한 모델구축에서는 딥러닝(Deep Learning) 기술 중 CNN(Convolution Neural Network) 기법을 사용 한 이미지 학습 및 분류 모델을 이용하였다. 첫 번째 모델 D1은 전문가에 의해 촬영된 이미지를 기반으로 학습 및 분류하는 모델을 개발하여 이미지 분류 정확도를 산출하 고, 두 번째 모델 D2는 웹크롤링 기법을 이용한 이미지를 기반으로 구축된 모델을 이용하여 최종적으로는 두 모델의 정확도를 비교하여 모델 간의 정확도 분류 결괏값을 비교 하였다. CNN 기법은 컨볼루션 계층(Convolution Layer)과 풀링 계층(Pooling Layer)을 조합하여 이미지가 갖는 픽셀
값을 기계가 스스로 학습하고 마치 인간이 객체를 분류 하는 것처럼 객체를 분류하는 기법으로 촬영한 이미지에 서 특정 개체만 출력하도록 구역을 지정하는 전처리 과 정이 필요하지 않고 다량의 데이터를 학습할수록 모델의 신뢰도와 정확도가 높아지는 특징이 있다.
본 연구에서는 CNN 기반의 모델 중 구글이 개발한 인 셉션 V3 CNN 아키텍처를 사용하여 산림 수종의 이미지 를 분류하였다. 모델 선정의 근거는 인셉션 V3 CNN 아 키텍처가 1,000종의 개체 이미지를 93.33%의 정확도로 분류한 이미지 자동분류 성능이 우수한 모델로 선행된 이미지 분류 학습 결과를 활용해 새로운 이미지를 분류 하기 때문에 데이터 처리 시간이 짧다는 장점이 있기 때 문이다.(Szegedy et al., 2016). 이미지 학습 및 분류 분석 은 구글에서 개발한 오픈소스 라이브러리 Tensorflow 1.8.0와 Python 3.6.1를 이용하여 분석하였다.
2. 산림수종 이미지 자동분류 모델 생성(훈련, 검증)과 테스트 모델훈련과 검증 과정을 진행할 때마다 정확도와 손실 함수를 출력했다. 훈련 단계에서 출력된 정확도와 손실함 수는 훈련 정확도(Training Accurucy), 훈련 손실함수(Training Loss Function)로 검증 단계에서 출력된 정확도와 손실함수는 검증 정확도(Validation Accurucy), 검증 손실함수(Validation Loss Function)로 정의하였다. 생성된 산림수종 이미지 자 동분류 모델은 테스트용 데이터를 정확하게 분류하는지 확인하는 테스트를 시행하고 테스트 결과 출력되는 정확 도와 손실함수를 테스트 정확도(Test Accuracy), 테스트 손 실함수(Test Loss Function)로 정의하였다.
3. 산림수종 이미지 자동분류 모델 성능 평가
딥러닝의 목표는 정확도가 높고 손실함수가 낮은 모델 을 생성하는 것이므로 본 연구에서는 생성된 두 모델 중
테스트 정확도가 높고 손실함수가 낮을수록 모델의 성능 이 좋다고 판단했다. 또한, 기계학습 시 정확도는 학습 횟수가 증가할수록 1에 가까워지고 손실함수는 0에 가까 워지며 학습 단계와 검증 단계의 결과가 유사하게 나타 날 때 학습 과정에 문제가 없다고 판단하기 때문에 각 모 델의 학습 단계와 검증 단계의 정확도와 손실함수의 차 이를 비교하였다. 차이가 클수록 과적합(Overfitting)을 의심할 수 있으므로 최종테스트 정확도가 높더라도 학습 단계와 검증 단계의 결과가 차이가 크면 이미지 분류 모 델로 부적합하다고 판단하였다.
본 연구에서는 모델 성능 평가의 기준으로 훈련, 검증, 테스트 단계의 정확도와 손실함수를 비교하여 평가했으 며 텐서보드(Tensorboard)를 사용하여 각 정확도와 손실 함수를 그래프로 나타내 시각화하였다.
결과 및 고찰
1. 산림수종 자동분류 모델 정확도 비교
테스트 정확도는 산림전문가가 직접 촬영한 산림수종 이미지 데이터를 이용한 딥러닝 기반 모델(D1) 94.4%, 웹이미지 데이터를 이용한 딥러닝 기반 모델(D2) 60.9%
로 모델 D1의 테스트 정확도가 월등히 높게 나타났다.
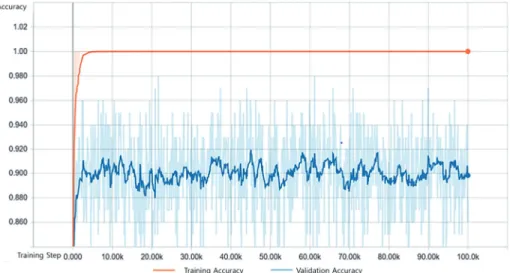
훈련 정확도와 검증 정확도는 텐서보드의 그래프로 표현 하면 진동 폭이 커 데이터의 흐름을 판단하기 어려우므 로 텐서보드에서 제공하는 스무딩(Smoothing) 기능을 사 용하여 90% 스무딩 처리 후 결과를 정리하였다. 모델 D1 의 학습 정확도는 학습 직후 급상승하여 1.0에 수렴하였 고, 검증 정확도는 약 3,000회의 학습까지 급상승하여 약 0.910의 정확도를 얻었으나 이후 0.88~0.92 사이에서 진 동했다(Figure 6).
모델 D2의 훈련 정확도는 약 1,000회의 학습 시 1.0에
Figure 6. The accuracy of forest species automatic classification mode Dl.
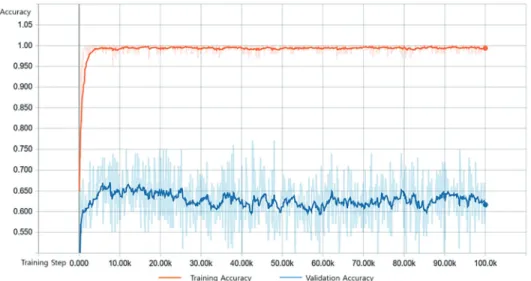
Figure 7. The accuracy of forest species automatic classification model D2.
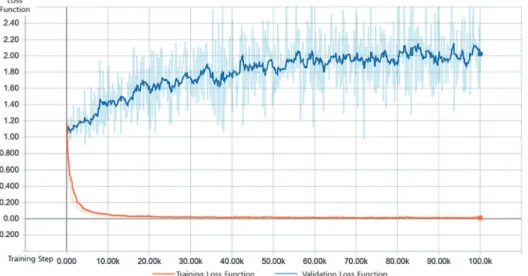
Figure 8. Loss function of forest species automatic classification model D1.
이르렀으나 유지하지 못하고 0.95~1.0 사이에서 진동을 나타냈다. 모델 D2의 검증 정확도는 약 5,800회의 학습 까지 점차 상승하여 0.67에 다다른 후 0.6~0.65 사이에서 진동하였다(Figure 7).
모델 D2는 모델 D1보다 약 0.22~0.27 정도 검증 정확 도가 떨어지는 것으로 나타나 모델 D1의 성능이 모델 D2보다 우수한 것으로 판단되었다. 또한, 생성된 모델의 과적합 여부를 판단하기 위해 훈련 정확도와 검증 정확 도의 차이를 확인한 결과 모델 D1은 0.08~0.12, D2는 0.35~0.40으로 나타났다. 각 정확도의 차이가 크면 데이 터 부족으로 인한 과적합 가능성을 의심할 수 있다. 보유 한 수종별 촬영 이미지 데이터의 수가 한정되어 있어 데 이터양 부족으로 인한 과적합 여부를 확인할 수 없는 것
이 본 연구의 한계이며 이는 Hervé Goëau(2017)의 연구 결과와 차이가 있어 추후 다량의 데이터를 기반으로 한 추가 연구가 필요하다고 생각한다.
2. 산림 수종 자동분류 모델 손실함수
훈련 손실함수와 검증 손실함수도 텐서보드에서 90%
스무딩 처리 후 결과를 정리하였다. 모델 D1의 훈련 손 실함수는 학습 직후 빠르게 하강하여 약 55,000회의 훈 련 단계에서 0에 수렴하였다. 모델 D1의 검증 손실함수 는 학습 초기 0.45였으며 2,120회의 검증 단계에서 0.135 의 최솟값을 가졌으나 이후 0.25~0.35에서 진동하였다.
이에 검증 손실함수를 감소시킬 방안에 관한 연구가 추 가로 필요하다(Figure 8).
Figure 9. Loss function of forest species automatic classification model D2.
모델 D2의 훈련 손실함수는 학습 직후부터 꾸준히 감 소해 약 26,000회의 훈련테스트에서 0.02에 도달한 후 서 서히 감소하여 100,000회의 학습단계에서 0.0118의 값을 가졌으며 0에 수렴하지 못했다. 모델 D2의 검증 손실함 수는 학습초기 1.05였으며 4,450회의 검증 단계에서 0.903의 최솟값을 가졌다. 하지만 학습을 진행할수록 손 실함수는 점차 증가하여 100,000회의 검증 단계에서 2.02 값을 가져 학습 초기보다 높아진 것을 확인할 수 있었다.
검증 손실함수는 모델의 성능을 평가하는 지표 중 하나 로 학습이 진행될수록 점차 감소하여야 하나 모델 D2의 검증 손실함수는 점차 증가하는 문제가 발생했다. 따라 서 모델 D2 생성에 사용한 웹크롤링을 통해 수집한 산림 수종 이미지 데이터는 산림 이미지 자동분류 모델 생성 에 적합하지 않은 것으로 판단하였다(Figure 9).
결 론
식물은 국가가 보유한 가장 소중한 자원이며 실생활에 밀접한 영향을 가지고 있음은 물론 일반인의 관심도 높 은 분야 중 하나이다. 식물분류는 관련 학술적 연구에 국 한되는 것이 아니라 식물자원을 활용한 관련 산업의 발 전과도 연계되어 있어 식물의 이미지를 자동으로 인식하 고 응용하는 기술이 빠르게 발전하고 있으며 유럽과 북 미에서는 식물 이미지 자동인식 시스템 구축이 활발하게 진행되고 있다. 하지만 국내에 서식하는 산림수종을 자 동으로 인식하는 연구가 미흡하여 우리나라 산림수종 이 미지 자동 인식 시스템 구축이 더디게 진행되고 있다. 이 에 본 연구에서는 인공지능 기반의 딥러닝 기법을 적용 한 산림수종 이미지 자동분류 모델의 표준 이미지 수집
법을 마련하고자 이미지의 질과 수집효율을 고려하여 각 수집방법에 따른 산림수종 이미지 자동분류 모델 성능을 비교하였다.
그 결과 산림전문가가 직접 촬영한 이미지 데이터를 사용한 모델 D1의 테스트 정확도가 매우 높고 훈련 정확 도와 검증 정확도의 차이가 크지 않아 신뢰성이 있다고 판단되었다. 단, 검증 손실함수가 학습 초기에 일부 감소 한 후 감소하지 않는 형태를 나타내고 있어 손실함수를 감소시키기 위한 추가 연구를 시행한다면 모델의 성능을 높일 수 있을 것으로 생각된다.
웹사이트에서 수집한 이미지 데이터를 사용한 모델 D2 는 모델 D1과 비교할 때 테스트 정확도가 현저하게 낮고 훈련 정확도와 검증 정확도의 차이가 크게 나타나 데이 터양이 충분하지 않아서 발생하는 과적합이 의심되었다.
더불어 검증 손실함수가 점차 증가하는 흐름을 보여 다 량의 이미지 데이터를 이용한 검증을 통해 웹페이지 등 에서 손쉽게 수집 가능한 대량의 식물 이미지 데이터를 활용하는 방안을 마련할 필요가 있다.
연구의 결과가 보여주듯 산림수종 이미지 데이터 수집 방법은 산림수종 이미지 자동 인식 모델 성능에 영향을 미치기 때문에 국내 산림수종 이미지 자동 인식 시스템 구축에 앞서 표준 이미지 데이터 수집 방법을 정립을 위 한 향후 추가적인 연구의 필요성이 요구된다.
감사의 글
본 연구는 산림청(한국임업진흥원) 산림과학기술 연구 개발사업 ‘빅데이터 기반 산림 산업 공동연구 2019149 C10-1923-0301’의 지원으로 이루어진 것입니다.
References
Aakif, A. and Khan, M.F. 2015. Automatic classification of plants based on their leaves. Biosystems Engineering 139;
66-75.
Backes, A.R., Casanova, D. and Bruno, O.M. 2009. Plant leaf identification based on volumetric fractal dimension.
International Journal of Pattern Recognition and Artificial Intelligence 23(6): 1145-1160.
Beghin, T., Cope, J.S., Remagnino, P. and Barman, S. 2010.
Shape and texture based plant leaf classification. Lecture Notes in Computer Science 6475(2): 345-353.
Charters, J., Wang, Z., Chi, Z., Tsoi, A.C., and Feng, D.D.
2014. Eagle: A novel descriptor for identifying plant species using leaf lamina vascular features. IEEE International Conference on Multimedia and Expo Workshops (ICMEW).
2014: 1-6.
Goëau, H.G., Bonnet, P., and Joly, A. 2017. Plant identification based on noisy web data: the amazing performance of deep learning. Conference and Labs of the Evaluation Forum.
Sep 2017; hal-01629183.
Grinblat, G.L., Uzal, L.C., Larese, M.G. and Granitto, P.M.
2016. Deep learning for plant identification using vein morphological patterns. Computers and Electronics in Agriculture 127: 418-424.
Hall, D., McCool, C., Dayoub, F., Sunderhauf, N., and Upcroft, B. 2015. Evaluation of features for leaf classification in challenging conditions. 2015 IEEE Winter Conference on Applications of Computer Vision. 797-804.
Kalyoncu, C. and Toygar, Ö. 2015. Geometric leaf classifi- cation. Computer Vision and Image Understanding 133:
102-109.
Kim, N.K., Lee, J.W., Kim, J.I. and Hong, S.H. 2018. Exotic plants classification using the transfer learning. The Institute of Electronics and Information Engineers 2018 (11): 477-480.
Kumar, N., Belhumeur, P.N., Biswas, A., Jacobs, D.W., Kress, W.J., Lopez, I.C. and Soares, J.V. 2012. Leafsnap: A computer vision system for automatic plant species identi- fication. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 7573(2): 502-516.
Larese, M.G., Namías, R., Craviotto, R.M., Arango, M.R., Gallo, C. and Granitto, P.M. 2014. Automatic classification of legumes using leaf vein image features. Pattern Recognition 47(1): 158-168.
Lee., B.Y., Kim, J.S., Chung, G.Y. and Kim, J.H. 2018. Plant taxonomy. Korea National Open University press, Seoul.
p. 1.
Lee, S.H., Chan, C.S., Mayo, S.J. and Remagnino, P. 2017.
How deep learning extracts and learns leaf features for plant classification. Pattern Recognition 71: 1-13.
Liu, X., Xu, F., Sun, Y., Zhang, H., and Chen, Z. 2018. Con- volutional recurrent neural networks for observation- cen- tered plant identification. Journal of Electrical and Computer Engineering 2018: 1-7.
Olsen, A., Han, S., Calvert, B., Ridd, P. and Kenny, O. 2015.
In situ leaf classification using histograms of oriented gradients. 2015 International Conference on Digital Image Computing: Techniques and Applications (DICTA). pp.
1-8.
Park, Y.M., Gang, S.M., Chae, J.H. and Lee, J.J. 2018. Classi- fication method of plant leaf using densenet. Journal of Korea Multimedia Society 21(5): 571-582.
Rashad, M., El-Desouky, B. and Khawasik, M.S. 2011. Plants images classification based on textural features using combined classifier. International Journal of Computer Science and Information Technology 3(4): 93-100.
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. and Wojna, Z. 2016. Rethinking the inception architecture for computer vision. Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2818-2826.
Yoon, Y.C., Sang, J.H., and Park, S.M. 2018. Trends of plant image processing technology. Electronics and Telecom- muniCaTions Trends 33: 54-60.
Zhang, S., Zhang, C., Zhu, Y., and You, Z. 2017. Discriminant WSRC for large-scale plant species recognition. Computa- tional Intelligence and Neuroscience 2017: 9581292.