*
정회원, 한국산업기술대학교, 컴퓨터공학과
**
정회원, 경기과학기술대학교, 미디어디자인학과 접수일자: 2018년 5월 21일, 수정완료: 2018년 6월 8일 게재확정일자: 2018년 6월 8일
Received: 21 May, 2018 / Revised: 8 June, 2018 Accepted: 8 June, 2018
*
Corresponding Author: [email protected]
Professor, Dept. of Computer Engineering, Korea Polytechnic University, Korea
https://doi.org/10.7236/JIIBC.2018.18.3.127
JIIBC 2018-3-17
3D 캐릭터에서의 자동 립싱크 MAYA 플러그인 개발
Development of Automatic Lip-sync MAYA Plug-in for 3D Characters
이상우
*,**, 신성욱
*, 정성택
*Sang-Woo Lee *,** , Sung-Wook Shin * , Sung-Taek Chung *
요 약 본 논문에서는 한국어를 기반으로 음성 데이터와 텍스트 정보에서 한국어 음소를 추출하고 분할된 음소들을 사용하 여 정확하고 자연스러운 3D 립싱크 애니메이션을 제작하기 위한 오토 립싱크 Maya 플러그인을 개발하였다. 여기서 개발된 시스템에서는 음소 분할은 Microsoft Speech API 엔진 SAPI에서 제공하는 49개의 음소를 참조하여 한글에 사용되는 음소들 을 모음 8개, 자음 13개로 분류하였다. 또한 모음과 자음의 발음들은 다양한 입모양을 가지지만 일부 동일한 입모양에 대하여 같은 Viseme을 적용할 수 있도록 구현하였다. 이를 바탕으로 파이썬(Python) 기반의 오토 립싱크 Maya 플러그인을 개발하 여 립싱크 애니메이션이 한 번에 자동으로 구현할 수 있게 하였다.
Abstract
In this paper, we have developed the Auto Lip-Sync Maya plug-in for extracting Korean phonemes from voice data and text information based on Korean and produce high quality 3D lip-sync animation using divided phonemes.In the developed system, phoneme separation was classified into 8 vowels and 13 consonants used in Korean, referring to 49 phonemes provided by Microsoft Speech API engine SAPI. In addition, the pronunciation of vowels and consonants has variety Mouth Shapes, but the same Viseme can be applied to some identical ones. Based on this, we have developed Auto Lip-sync Maya Plug-in based on Python to enable lip-sync animation to be implemented automatically at once.
Key Words :
3D Character, Automatic Lip-sync, Phonemic Separation, VisemeⅠ. 서 론
최근 컴퓨터 기술의 발전으로 캐릭터 애니메이션 산 업이 과거에 비해 비약적으로 발전하고 있다. 일반적으 로 캐릭터 애니메이션은 2차원 또는 3차원의 기하정보로 표현된 캐릭터가 살아있는 것처럼 움직임을 구현하는 과 정을 의미한다. 이와 같은 애니메이션 산업은 영상뿐만 아니라 캐릭터 사업을 통한 막대한 부가가치 증대 가능 성이 높은 분야로 주목받고 있다
[1-2].
이러한 미래형 고부가가치 문화산업으로 부각되고 있
는 애니메이션 산업이 한국에는 2017년도 기준으로 애니
메이션 콘텐츠 관련 기업 200여개에 약 5천여명 정도로
매우 영세한 실정이다
[3]. 특히, 가상과 현실의 경계를 모
호하게 만드는 3D 캐릭터 애니메이션 기술은 제작된 캐
릭터에 생명력을 불어넣었고, 이 캐릭터를 사용한 영화,
만화, 게임, 광고 및 교육 등 다양한 분야에 적용되고 있
다
[4]. 그러나 국내 캐릭터 애니메이션 산업이 안고 있는
문제점은 기획력과 전문 인력의 부족으로 대부분 OEM
으로 이루어지고 있다는 것이다. 이러한 국내의 애니메 이션 기술 수준으로는 높은 부가가치 창출은 기대할 수 없을 뿐만 아니라 현재의 OEM도 중국이나 베트남 등과 같은 가격 경쟁력이 높은 국가들의 등장으로 경쟁력은 급격히 약해지고 있는 추세이다. 반면에 해외 애니메이 션 기업으로부터의 OEM으로 계속적인 기술력 축적을 통해 국내 기술력은 매우 높은 수준으로 발전했다는 것 이며, 다양한 장르의 애니메이션 콘텐츠들의 수요가 증 가함에 따라 새로운 기업과 종사자가 계속적으로 증가할 뿐만 아니라 애니메이션의 질적 향상이 이루어지고 있다 는 것이다. 이러한 OEM 위주의 소규모 제작사들이 인력 유지에 필요한 비용을 충당하기엔 현실적으로 매우 어렵 기 때문에 창작을 위한 기회비용의 재고를 위해서는 기 존 OEM과 자체 프로젝트 제작 방식에서 제작 시간과 공 정의 효율성을 높이는 방법이 필요하다.
일반적으로 한 명의 애니메이터가 TV 시리즈 기준으 로 한 달에 작업할 수 있는 분량은 60초~120초 정도이다.
애니메이터가 한 달 평균 90초를 작업하였을 때 립싱크 (Lip-sync) 작업 분량은 약 4일 정도가 소모되는 것이다. 이 것은 제작된 캐릭터의 자연스러운 립싱크(Lip-sync)구 현에는 한국어 음성에 따라 음소 분할을 하고 동기화를 통해 자연스럽게 어울리는 입 모양을 표현하는 데 많은 시간이 필요할 뿐만 아니라 여러 가지 요소들의 적절한 조절이 필요하기 때문이다.
예를 들어 현재까지 3D 캐릭터 애니메이션에서의 페 이셜 애니메이션은 표정이나 감정을 얼마나 자연스럽게 표현할 수 있는 지가 매우 중요하다. 페이셜 애니메이션 이란 사람의 표정의 특징점을 추출하여 캐릭터로 표정을 표현하는 기술로서 음성 신호에 맞춰 캐릭터의 입 모양 을 발음에 맞게 변화를 시키거나 일부 문장의 뜻을 이해 하여 그에 맞는 표정을 짓게 함으로써 상대방에게 더욱 실감나게 의미를 전달할 수 있다
[5-6]. 하지만 3D 캐릭터 애니메이션의 얼굴 표정이 자연스럽게 표현된다고 보기 어렵다. 이것은 캐릭터가 말하고 있는 음성 신호와 입술 움직임과의 동기화로 발생하는 문제점이다. 대부분 국내 에서 제작되어지는 애니메이션의 캐릭터들은 영어 형식 으로 분할된 음소를 이용한 한국어의 음성과 동기화가 이루어지기 때문에 자연스러운 립싱크가 이루어지지 않 는 것이다
[7].
이와 같은 페이셜 애니메이션을 구현하기 위한 컴퓨 터 그래픽스 동기화 기술은 3차원 기하 정보의 미세한 변
화까지 표현해야 하는 기술적인 문제로 여러 방법이 시 도되고 있다
[8]. 그 중 3차원 애니메이션 클립을 제작할 때 각각의 프레임을 수작업을 통하여 제어하거나 재사용이 불가능한 페이셜 트래킹방식의 모션 캡쳐 방법이 이용되
었다
[9-11]. 이것은 마커나 움직임 센서가 부착된 장비를
갖추고 원하는 움직임에 따라 발생하는 위치를 측정한 후 이를 데이터화하여 그 값으로 개체를 생성하는 것이 다. 또 다른 방법으로는 키프레임 애니메이션 기법으로 임의의 표정을 만들기 위해 중요한 키프레임들에 대해 얼굴 모델의 상태를 지정하고 키프레임 사이를 부드럽게 연결해주는 인-비트윈(In-between)에 의해 보간하여 애 니메이션을 생성한다. 여기서 키프레임 방식의 보간법은 두 키프레임 사이의 중간 프레임들을 정보의 평균값으로 계산하여 정지 프레임 시퀀스를 만들고 이를 객체의 움 직임에 적용하는 것이다. 그러나 키프레임 방법은 수작 업에 의존해야 하는 부분이 많기 때문에 제작시간이 길 고 사실적인 표정 애니메이션을 생성하기가 까다롭다는 단점이 있다
[12]. 이러한 이유로 제작기간이 상당히 길고, 고비용 저효율 때문에 고가의 영화나 광고 동영상에 주 로 사용되어왔다. 그래서 이와 같은 어려움을 해결하기 위해 자동으로 음성에 영상을 동기화할 수 있는 페이셜 애니메이션 연구들이 이루어지고 있다.
본 논문에서는 애니메이션 페이셜 사운드 자동 생성 기술로 수작업으로 작업했던 립싱크 부분을 완전 자동화 하여 작업시간을 단축할 수 있는 시스템을 제안한다. 대 부분 제작되는 애니메이션은 영어기반으로 음소가 분할 되어 립싱크가 자연스럽지 않거나 제작된 애니메이션을 수작업으로 재 작업해야 하는 경우가 많다. 그래서 한국 어의 음운론과 발음법에 맞는 방법을 사용하여 음소를 분할이 필요하다. 본 논문에서의 음소 분할은 음성 인식 과 텍스트 음성 변환을 사용하는 어플리케이션에 필요한 코드 오버 헤드를 크게 줄여 주어 광범위한 어플리케이 션에서 음성 기술에 접근하기 쉽고 강력한 Microsoft Speech API 엔진 SAPI에서 제공하는 49개의 음소를 참 조하여 한글에 사용되는 음소들을 모음 8개, 자음 13개로 분류한 후 이를 적용하여 개발하였다
[13].
Ⅱ. 관련 연구
1. 오픈소스 립싱크 소프트웨어
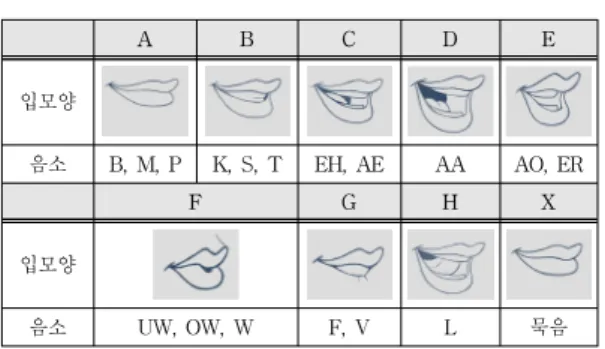
대부분의 상용 프로그램들은 립싱크를 위하여 비슷한 기능들을 포함하고 있지만, 음소 분할에 있어서는 한국 어의 음소 분할과 전혀 다르다. 많은 립싱크 애니메이션 프로그램에서 참조하고 있는 여러 가지 오픈소스 소프트 웨어들이 어떤 방식으로 립싱크를 하였는가를 분석하고 한국어의 음소 분할을 쉽게 하고 립싱크 부분을 완전 자 동화하고자 하였다. 첫째, 음성 녹음을 통해 2D 립싱크 애니메이션을 자동으로 생성하는 Rhubarb 립싱크 엔진 은 표 1과 같이 음소 A부터 F까지 6개의 기본 입모양과 G, H, X 3개의 입모양을 옵션으로 추가하여 모두 9개의 입모양을 사용한다
[14]. 하지만 이 방법은 2D 애니메이션 에 최적화 되어 있으므로 추출할 수 있는 음소의 개수가 적어 정확도가 떨어진다는 단점을 가지고 있다.
A B C D E
입모양
음소 B, M, P K, S, T EH, AE AA AO, ER
F G H X
입모양
음소 UW, OW, W F, V L 묵음
표 1. Rhubarb 립싱크 엔진의 음소 분할 예
Table 1. Example of Phonemic Separation using Rhubarb Lip-Sync Engine
두 번째, Papagayo 립싱크 엔진은 Preston Blair Phoneme Series를 사용하여 오디오 파일의 소리와 함께 입모양을 쉽게 정렬할 수 있는 프로그램이다. Preston Blair Phoneme Series에서의 음소 분할 특징으로는 모음 위주 로 발음 현상이 나타나는 한국어와는 달리 아예 발음할 수 없거나 표현 방식이 어려운 자음 발음인 /F/, /Th/를 감안하여 발음 구분을 하였다
[15-16]. 이와 같이 만들어진 Papagayo는 오디오 파일에서 재생하고 있는 단어를 직 접 타이핑하면, 이에 대해 발음사전을 이용하여 음소들 로 나누게 되는 것이다. 이 프로그램은 2D 애니메이션 제 작에 용이하게 사용될 수 있으나 단어를 직접 타이핑하 기 때문에 3D 애니메이션 제작에는 불편하다.
그래서 본 논문에서는 오디오 파일에서 자동으로 음 소를 추출할 수 있는 립싱크엔진을 사용하고, 한국어 음 소에 알맞은 포괄적인 입모양 이미지 Viseme을 개발하 였다. 특히 Microsoft Speech API 엔진 SAPI는 다양한
음성 엔진의 실시간 작동을 제어하고 관리하는 데 필요 한 모든 하위 레벨의 세부 사항을 구현할 수 있기 때문에 이를 적용하여 개발하였다. 또한 TTS 시스템은 합성음 (Synthetic Voices)을 사용하여 음성 오디오 파일과 텍스 트 문자열을 합성할 수 있고 음성 인식기는 사람의 오디 오를 텍스트 문자열로 변환 해줄 수 있다
[13].
2. 한글 및 영어 기반의 음소 분할
앞에서 언급한 립싱크 애니메이션 프로그램은 Microsoft Speech API 엔진 SAPI에서 제공하는 49개의 음소를 참 조하였으며, 한글에서는 모음 8개(AA, EH, UH, OH, OW, UW, IY, Y), 자음 13개(K, N, D, R, M, B, S, Z, CH, T, P, H)의 음소와 영어의 음소는 모음 8개(AA, AE, IY, AO, UW, AH, OH, ER), 자음 19개(P, B, T, D, G, F, TH, S, SH, ZH, CH, H, R, M, N, NG, L, J, W)로 분류하였다.
또한 한글과 영문의 기호화 테이블을 구성하기 위하여 발음과 기호를 대칭시키고 발음의 중복성(ㅏ와 ㅑ, ㅓ와 ㅕ 등)을 고려하였다. 이에 대한 결과는 표 2 및 3에서 한 글과 영어에 사용된 음소기호를 이용하여 한글과 영문의 기호화 테이블을 작성한 것을 나타내고 있다.
한국어 발음 (모음) 음소 한국어 발음
(자음) 음소
ㅏ, ㅑ AA ㄱ, ㄲ, ㅋ K
ㅐ, ㅒ, ㅔ, ㅖ EH ㄴ N
ㅓ, ㅕ UH ㄷ,ㄸ D
ㅗ, ㅛ OH ㄹ R
ㅘ OW ㅁ M
ㅙ, ㅚ OH + EH ㅂ, ㅃ B
ㅜ, ㅠ UW ㅅ, ㅆ S
ㅞ UW + EH ㅇ 모음에 따라
설정됨
ㅝ UW + UH ㅈ, ㅉ Z
ㅟ UW + IY ㅊ CH
ㅡ Y ㅌ T
ㅢ Y + IY ㅍ P
ㅣ IY ㅎ H
표 2. 한글에서의 음소 별 한글 기호화 테이블
Table 2. The Symbolic table using phonemes used in Hangul
일반적으로 한글은 모든 음절에 대한 입 모양을 정하
는 것이 매우 어렵고 그 수가 매우 많기 때문에 사실상
무의미하다. 음절에는 동일한 입 모양을 나타내는 동형
이음, 즉 음절의 음이 달라도 같은 형태의 입 모양 패턴
이 많이 존재하므로 대표적인 음절에 대해서만 입 모양
을 정하고 이를 결합하여 모든 음절의 입 모양으로 대체 하는 방법을 사용하였다. 이렇게 함으로써 비교적 적은 수의 입 모양의 변형 규칙을 정하여 페이셜 사운드 애니 메이션에 적용할 수 있는 것이다.
영어 발음 음소 영어 발음 음소
a, a: AA ɵ TH
e, e: AE ɗ D
I, I: IY s, z S
ɔ, ɔ:, ʌ AO ʃ SH
u, u: UW ʒ, dʒ ZH
ə, ə: AH ʃt CH
ai AA + IY h H
ei AE + IY r R
au AA + UW m M
ɔi AO + IY n N
ou OH + UW ɳ NG
iər IY + ER l L
ɛər AE + ER j J
uər UW + ER w W
p P wɑ W, AA
b B wɔ W, AO
t T ju J, UW
d D dʒa ZH, AA
k, g G tʃa CH, AA
f, v F
표 3. 영어에서의 음소 별 영어 기호화 테이블
Table 3. The Symbolic table using phonemes used in English
Ⅲ. 한국어 음소분할을 적용한 3D 립싱크 애니메이션 시스템 개발
1. 디지털 사운드 분석기 개발
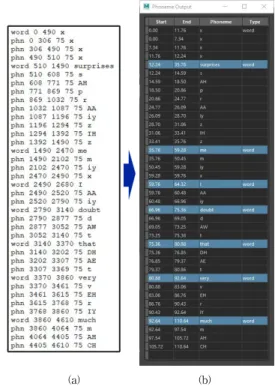
본 논문에서는 Microsoft Speech API 엔진 SAPI의 라이브러리를 이용하여 음성인식과 음소들을 제어하기 위한 디지털 사운드 분석기를 개발하였다. 이것은 대화 체 사운드 (wav, mp3)를 표 2 및 3에서 구현된 기호화 테 이블을 적용하여 기호화된 기호들과 시간에 따라 TXT 파일로 추출하는 기술이다. 예를 들어 “ Surprises me, I doubt that very much”라는 약 5초 동안의 사운드 파일 을 이용하여 그림 1과 같이 시간 경과에 따라 음소가 검 출되고 있는 것을 보여주고 있다. 그림 1(a)에서는 1/1000 초만큼 매우 적은 시간동안 각 음소들이 검출되는 과정 을 나타내고 있고. 이를 이용하여 Phoneme Output 프로 그램으로 각 프레임에서의 음소들이 추출된 것을 그림 1(b)에서 보여주었다. 예를 들어 12프레임부터 35프레임
까지 “Surprises”라는 단어에 대해 각각의 음소들(S, AH, P, R, AA, IY, Z, IH, Z)이 검출되고 있음을 알 수 있다.
즉 추출된 음소들은 표 3을 이용한 영문에서의 음소 별 기호화 테이블에 따르고 있음을 알 수 있다.
(a) (b)
그림 1. 시간에 따른 음소 검출Fig. 1. Phoneme detection by time-base
2. Viseme Manager 개발
Viseme이란 특정한 소리(음소)를 묘사하기 위한 얼굴 과 포괄적인 입모양의 이미지를 의미한다. 기본적으로 언어에는 특정 음소에 해당하는 Viseme 집합들을 가지 고 있다. 예를 들어 영어에서는 “pet” 과 “bet”이라는 단 어는 음향적으로는 다르지만 동일한 Viseme을 가진다.
이것은 Viseme 집합들을 분류해서 3D 캐릭터의 입모양 을 결정하고, 이를 애니메이션에 적용할 수 있다는 것을 의미한다.
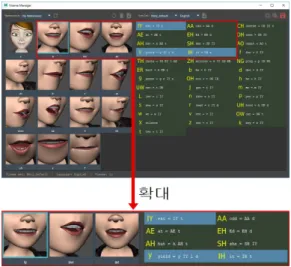
그래서 본 논문에서도 음소 분할로 얻어진 데이터를
활용하여 Viseme Manager를 구현하였다. 이를 사용하
여 그림 2에서 “IY”입모양(한국어로는 “이”와 비슷한 모
양)의 Viseme를 보여주고 있다. 만약 IY, Y, IH의 세 가
지 음소가 추출되면 이들은 동일한 입모양을 가지고 있
으므로 Viseme Manager에서는 “IY”의 해당하는 입 모
양의 Viseme이 적용되는 것이다.
그림 2. 구현된 Viseme Manager
Fig. 2. Implemented Viseme Manager
Visemes Phonemes Visemes Phonemes
AA UW
EH Y
UH K, N, D, S, Z, CH, T, H
OW R
IY B, M, P
OH
표 4. 한국어 음소에 적용되는 Visemes
Table 4. Visemes applied to Korean phonemes
Visemes Phonemes Visemes Phonemes AA K, N,D, G, S, CH,
T, H, L, J, ZH
AE R
IY TH
AO B, M, P
UW F
AH N, NG
OH W, SH
ER
표 5. 영어 음소에 적용되는 Visemes
Table 5. Visemes applied to English phonemes
전체적으로 본 논문에서 적용된 한국어와 영어에 대 한 Viseme들은 표 4 및 5에 나타냈다. 일반적으로 모음 에서는 입모양이 다양하게 구현되며, 반면에 자음에서는 동일한 입모양의 Viseme을 많이 사용하게 된다는 것을 알 수 있다. 특히, 영어는 한국어와는 달리 아예 발음할 수 없거나 표현 방식이 어려운 자음 발음인 F, TH에 대 해 발음 구분을 하였고, SH와 W발음은 동일한 입모양을 가지므로 같은 Viseme을 사용하였다.
3. 파이썬(Python) 기반의 오토 립싱크 Maya 플러그인 개발
구현된 기호화 테이블과 디지털 사운드 분석기를 바 탕으로 그림 3과 같이 애니메이션 필드를 구축하기 위한 파이썬(Python) 기반의 오토 립싱크 Maya 플러그인을 개발하여 립싱크 애니메이션이 한 번에 자동으로 구현할 수 있게 하였다.
그림 3. 파이썬(Python) 기반의 오토 립싱크 Maya 플러그인 화면
Fig. 3. Python-based automatic lip-sync Maya plug-in screen
그림 4는 사람이 실제적으로“아~”라고 발음하였을 때 1프레임에서 9프레임까지는 아무소리가 나지 않지만 6프레임부터 입이 움직이기 시작하고 9프레임에서 입과 혀 모양이 완전히 형성된 후 “아~”라고 소리가 나온다.
이후 소리는 점점 줄어들면서 20프레임에서 완전히 사
라졌다. 하지만 입모양은 20프레임까지 형성되고 26프
레임 이후에 입모양이 완전히 닫히는 것을 알 수 있다.
그러나 프로그램에서는 소리가 나오는 부분에서부터 음 소를 파악하고 그 시점의 시간을 측정하여 입모양이 만 들어지는 애니메이션 Key값을 적용하기 때문에 실제 사람이 발음하는 과정의 프레임을 만들어 낼 수 없다.
그림 4. “아~” 사운드에 따른 입모양의 타이밍 분석 Fig. 4. “Ah~”timing analysis of Mouth shape based
on sound
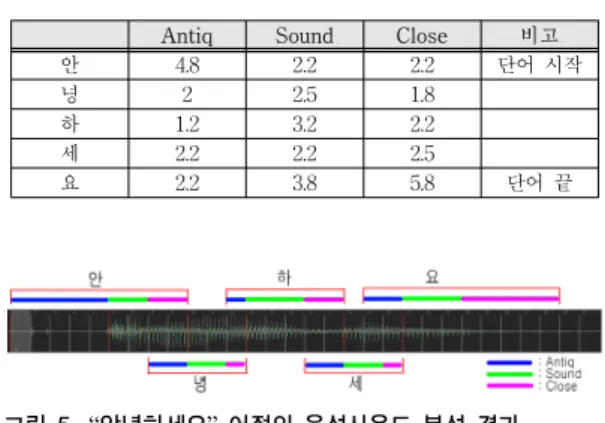
그래서 이 결과를 바탕으로 10명을 대상으로 “안녕하 세요”라는 어절을 녹음한 후 그림 4와 같은 실험을 통해 문제점을 확인하고자 하였다. 이에 대한 분석은 입모양 이 형성되기 시작하는 시점부터 소리가 나기 시작하는 시점을 Antiq, Sound는 입모양이 다 만들어진 후 소리가 나기 시작하는 시점부터 소리가 끝나는 시점, Close는 소 리가 끝나는 시점부터 입모양이 닫히는 시점에서 이루어 졌다. 표 6은 10명에 대한 Antiq, Sound, Close에서의 평 균 FPS를 나타냈으며, 이에 대한 어절의 음성사운드 분 석 결과는 그림 5에서 보여주었다. 어절이 시작되는 형태 소 “안”에서 Antiq 부분은 4.8 FPS으로 가장 길며, Sound 부분은 2~3 FPS으로 비슷하였다. 하지만 Close 부분에서는 1.8~2.5 FPS으로 비슷하지만 어절의 끝 “요”
에서는 5.8 FPS으로 길었다. 이것은 뒤에 이어지는 어절 이 없기 때문에 FPS가 길게 나오는 것으로 판단된다. 전 체적으로 중간 어절 “녕하세” 형태소들은 “안”의 Close와
“녕”의 Antiq 부분이 합쳐지면서 그 다음의 형태소를 시 작하게 된다. 이러한 이유로 소리를 내기 위해서는 입모 양이 2~3프레임(0.1초)정도 먼저 움직였다. 그래서 입모 양과 사운드가 일치시키기 위해서는 평균 2~3프레임 정 도의 애니메이션 Key값을 앞으로 이동해야만 입모양과 사운드가 자연스럽게 일치되는 것이다.
Antiq Sound Close 비고
안 4.8 2.2 2.2 단어 시작
녕 2 2.5 1.8
하 1.2 3.2 2.2
세 2.2 2.2 2.5
요 2.2 3.8 5.8 단어 끝
표 6. “안녕하세요” 어절의 음성사운드 분석표 Table 6. Voice sound analysis table of a word
“An-nyung-ha-se-yo”
(단위 : FPS)
그림 5. “안녕하세요” 어절의 음성사운드 분석 결과 Fig. 5. Results of Voice sound analysis table of a
word “An-nyung-ha-se-yo”
Ⅳ. 결 론
본 논문에서는 애니메이터 및 일반 사용자들이 시간 대비 높은 퀄리티의 페이셜 사운드 애니메이션 데이터를 획득할 수 있게 하였다. 그래서 다량의 얼굴관련 애니메 이션 콘텐츠를 손쉽게 제작할 수 있도록 한국어 음소분 할을 적용하여 3D 애니메이션 오토 립싱크 시스템을 개 발하였다. 이에 대한 개발 과정으로는 먼저 오디오 파일 에서 음소들을 자동으로 추출할 수 있는 Microsoft Speech API 엔진 SAPI를 사용하였다. 이 엔진은 49개의 영어 음소들을 분류할 수 있지만, 본 논문에서는 한글은 모음 8개와 자음 13개, 영어는 모음 8개와 자음 19개의 음소들로 분류하였다. 분류된 음소는 발음과 음소를 대 칭시키고 발음의 중복성을 고려하여 한글과 영문의 음소 별 테이블을 구성하였다. 여기서 구현된 음소 별 테이블 을 적용하여 음성인식과 음소들을 디지털 사운드 분석기 를 통해 시간에 따라 TXT파일로 추출하였다.
특히, 특정 음소에 해당하는 Viseme 집합들을 분류해
야만 3D 캐릭터의 입모양을 결정하고, 이를 애니메이션
에 적용할 수 있는 Viseme Manager를 구현하였다. 결과
적으로 디지털 사운드 분석기와 Viseme Manager를 통
합하여 파이썬(Python) 기반의 오토 립싱크 Maya 플러
그인을 개발함으로써 립싱크 애니메이션이 한 번에 자동
으로 구현할 수 있게 되었다.
본 논문에서 개발된 3D 애니메이션 오토 립싱크 시스 템을 사용한다면 애니메이션 회사나 OEM 애니메이션 회사들이 3D 애니메이션 제작 시 작업시간을 단축할 수 있을 것이다. 이것은 생산성을 높이고 조금이나마 인건 비를 줄일 수 있으므로 기업의 성장하는 데 도움을 줄 것 으로 기대된다. 또한 가상현실, 한국어 페이셜 사운드 관 련 분야, 청각 장애인, 유아 및 외국인을 위한 콘텐츠 개 발에도 활용할 수 있을 것이다.
References
[1] Yong Wook Kim, “Market Analysis & Industrial Trends of Cartoon·Game·Animation Contents Industry”, Review of Korea Contents Association, Vol. 13, No. 2, pp. 14-19, June 2015.
[2] Ji-Ae Kim, “A Study on Effective Facial Expression of 3D Character through Variation of Emotions - Model using Facial Anatomy”, The Journal of Korea Multimedia Society, Vol. 9, No. 7, pp. 894-903, July 2006.
[3] https://www.kocca.kr/
[4] Chul Hee Jung, Mingeun Lee, and Myeong Won Lee, “Development of Exchangeable Character Animation Using a Motion Sensor”, Korean Society For Computer Game, Vol. 27, No. 4, pp.
237-246, Dec. 2014.
[5] Youn Hwan Ha and Sung Hong Hong,
“Recognizing Human Facial Expressions and Gesture from Image Sequence”, Journal of Biomedical Engineering Research, Vol. 20, No. 4, pp. 419-425, 1999.
[6] Yu-Sin Park, Ko-Rock Sin, Tae-Yong Kim, and Jong Soo Cho, “Technical Analysis of Text to Lip Sync. Animation”, Korean Society For Computer Game, Vol. 1, No.2, pp. 36-45, June 2003.
[7] Hyewon Song, Suwoong Heo, Jiwoo Kang, and Sanghoon Lee, “3D Character Animation: A Brief Review”, Journal of International Society for Simulation Surgery, Vol. 2, No. 2, pp. 52-57, Dec.
2015.
DOI: http://dx.doi.org/10.18204/JISSiS.2015.2.2.052 [8] Dong Sun Shin and Jinoh Chung, “A Study on 3D Graphics Design System for the Korean Lip-Sync Synthesis”, Proceeding of HCI Korea 2016. pp.
1762-1769, 2016.
[9] John Lasseter, “Principles of Traditional Animation Applied to 3D Computer Animation”, Computer Graphics, Vol. 21, No. 4, pp. 35-44, July 1987.
DOI: http://dx.doi.org/10.1145/37401.37407 [10] Yongqiang Li and Shangfei Wang, “Simultaneous
Facial Feature Tracking and Facial Expression Recognition”, IEEE Transaction on Image Processing. Vol. 22, No. 7, pp. 2559-2573, July 2013.
DOI: http://dx.doi.org/10.1109/TIP.2013.2253477 [11] Seong-Ho Lee, Kyong-Ho Han, “Detection of
Moving Objects using Depth Frame Data of 3D Sensor”, The Journal of The Institute of Internet, Broadcasting and Communication(JIIBC), Vol. 14, No. 5, pp. 243-248, Oct. 2014.
DOI: http://dx.doi.org/10.7236/JIIBC.2014.14.5.243 [12] Min-Sung Kim, “A Study on Overcome of
Marker-based Motion Capture Environment”, Journal of the Korea Entertainment Industry Association, Vol. 10, No. 2, pp. 17-25, Apr. 2016.
DOI :
http://dx.doi.org/10.21184/jkeia.2016.04.10.2.17 [13] https://msdn.microsoft.com/en-us/library/ms71703
7(v=vs.85).aspx
[14] https://github.com/DanielSWolf/rhubarb-lip-sync.
[15] http://www.garycmartin.com/mouth_shapes.html [16] Il-Hong Jung, Eun-Ji Kim,“Natural 3D Lip-Synch
Animation Based on Korean Phonemic Data”,
Journal of Digital Contents Society, Vol. 9, No. 2,
pp. 331-339, June. 2008.
저자 소개
이 상 우(정회원)
∙2009년 : Academy of Art Univ.
Animation and Visual Effects 석사
∙2016년 ∼ 현재 : 한국산업기술대학교 컴퓨터공학과 박사과정
∙2016년 ∼ 현재 : 경기과학기술대학교 미디어디자인과 교수
신 성 욱(정회원)
∙2013년 : 한국산업기술대학교 컴퓨터공 학과 석사
∙2016년 : 한국산업기술대학교 컴퓨터공 학과 박사
∙2017년 ∼ 현재 : 한국산업기술대학교 컴퓨터공학과 조교수
정 성 택(정회원)
∙1995년 : 한국과학기술원 정보 및 통신 공학과 석사
∙2000년 : 한국과학기술원 전기 및 전자 공학과 박사
∙2004년 ∼ 현재 : 한국산업기술대학교 컴퓨터공학과 교수