ARTICLE
International Journal of Advanced Robotic Systems
Multiple Kinect Sensor Fusion for Human
Skeleton Tracking Using Kalman Filtering
Regular Paper
Sungphill Moon
1, Youngbin Park
1, Dong Wook Ko
2and Il Hong Suh
3*
1 Department of Electronics and Computer Engineering, Hanyang University, Seoul, Republic of Korea 2 Department of Intelligent Robot Engineering, Hanyang University, Seoul, Republic of Korea 3 Department of Electronic Engineering, Hanyang University, Seoul, Republic of Korea *Corresponding author(s) E-mail: [email protected]
Received 26 October 2015; Accepted 05 February 2016 DOI: 10.5772/62415
© 2016 Author(s). Licensee InTech. This is an open access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/3.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Abstract
Kinect sensors are able to achieve considerable skeleton tracking performance in a convenient and low-cost man‐ ner. However, Kinect sensors often generate poor skeleton poses due to self-occlusion, which is a common problem among most vision-based sensing systems. A simple way to solve this problem is to use multiple Kinect sensors in a workspace and combine the measurements from the different sensors. However, this method creates a new issue known as the data fusion problem. In this research, we developed a human skeleton tracking system using the Kalman filter framework, in which multiple Kinect sensors are used to correct inaccurate tracking data from a single Kinect sensor. Our contribution is to propose a method to determine the reliability of each tracked 3D position of a joint and then combine multiple observations based on measurement confidence. We evaluate the proposed approach by comparison with the ground truth obtained using a commercial marker-based motion-capture system. Keywords Skeleton Tracking, Multiple Kinects, Data Fusion, Kalman Filter
1. Introduction
Capturing human motion can provide useful information for various robotic applications. For example, human
activity recognition based on skeleton tracking [26] might be a fundamental component for human robot interaction [24, 23], whereby humans and robots can cooperate in tasks in industrial environments based on human skeleton tracking [21]. Transferring human skills and teleoperation of human motions in robots require 3D body/hand poses [22, 25]. There are two ways to capture human motion: marker-based motion capture, and markerless motion capture. One drawback of marker-based motion capture is that the performing subject has to wear a suit covered with sensors or markers. On the other hand, it is not necessary for the subject to wear a suit in markerless motion capture, which has helped the technology gain significant attention recently. However, markerless motion capture is challeng‐ ing in the absence of accurate depth information. The release of the first version of Microsoft Kinect made a low-cost sensor for fast and high-quality dense depth images available for the first time. The introduction of Kinect had a significant impact in robotics as well as full-body pose tracking.
The second version of the kit, Microsoft Kinect for Win‐ dows v2 (Kinect v2), was released and made available to researchers in 2014. This new generation offers a higher resolution and a wider field of view compared to the original Kinect technology. Further, in terms of depth, Kinect v2 is based on the time-of-flight principle, whereas the previous version utilized structured light to reconstruct the third dimension. This has led to a considerable im‐ provement in the accuracy of depth sensing.
To enable the use of Kinect sensors for developers and researchers, the official Microsoft SDKs (Software Devel‐ opment Kits) 1.0 and 2.0 are freely available for Kinect v1 and v2, respectively. These SDKs provide not only the appropriate drivers, but also a set of functions such as a skeleton tracker and code samples that can be used for custom implementations. The skeleton tracker works by classifying each pixel of the depth image as part of a joint using trained decision forests [1]. The initial version of the Kinect SDK allowed tracking of up to 20 body joints, and the second allows tracking of up to 25, including fingertips and thumbs. Moreover, due to the enhanced depth sensor, tracking accuracy has been significantly improved. There‐ fore, in this work we developed our skeleton tracking system based on Kinect v2.
Although Kinect v2 provides better tracking results compared to Kinect v1, it often generates poor skeleton poses in the presence of self-occlusion, which is common among most vision-based sensing systems. One simple way to solve this problem is to use multiple cameras in the workspace. For instance, if a view of a body part is blocked from one camera, it might be possible to obtain a view of the body part from another camera. Appropriately com‐ bining data obtained from multiple Kinect sensors in this way can be used to achieve more accurate tracking com‐ pared with a single sensor.
However, the use of multiple sensors introduces a new problem called "data fusion". Therefore, it is necessary to determine a way to estimate the confidence of each measurement and to combine multiple observations in a suitable manner based on these confidence values. The data fusion problem can be investigated based on various existing models. Before determining a specific model to tackle the problem, it is necessary to consider the characteristics of the tracked skeleton pose. Specifically, the estimated position of a joint often varies discontinuously, and is noisy. Probabilistic filtering methods such as Kalman filtering may be suitable to address this problem. The transition model in probabilistic filtering usually helps to remove jitters and promote temporal continuity.
Data fusion with Kalman filtering has been studied by several researchers [2-5]. The two most commonly used kinds of fusion method for Kalman filtering are state-vector fusion methods and measurement fusion methods. State-vector fusion methods use a group of Kalman filters to obtain individual sensor-based state estimates, which are then fused to acquire an improved joint state estimate. Conversely, measurement fusion methods directly fuse the sensor measurements to a weighted or combined measure‐ ment, and use a single Kalman filter to access the final state estimate based upon the fused observation. Measurement fusion methods generally provide better overall estimation performance, while state-vector fusion methods have a lower computation requirement and the advantage of allowing parallel implementation. As mentioned above,
the number of joints in the Kinect body model is only 25. Thus, even if we consider the x, y, and z-coordinate for each joint, the dimension of the state vector is only 75, meaning that the computational cost of Kalman filtering is relatively low. Therefore, we used the measurement fusion method in our model.
In this paper, we developed a human skeleton tracking system in which Kalman filtering employing a weighted measurement fusion method was used to combine different tracking results acquired from multiple Kinect sensors. Our contribution in this work is to propose a method to determine the reliability of each tracked 3D position of joints and combine multiple observations according to measurement confidence.
The remainder of the paper is organized as follows. Section 2 provides a survey of the current literature related to skeleton tracking. Section 3 briefly describes Kalman filtering with weighted measurement fusion. In Section 4, the proposed model is described with an emphasis on the details of the proposed measurement fusion method. Section 5 presents our experimental setup and an evalua‐ tion of the performance of the proposed model. Finally, we present our conclusions in Section 6.
2. Related Works
Skeleton tracking algorithms can be classified in several different ways. First, we can consider tracking-based methods [6-8] and single-frame-based approaches [1, 9]. The former has a tracking step while the latter estimates the body pose based on a single frame, and has no tracking step. Tracking-based methods require initialization and encounter the issue of re-initialization of the tracked model whenever the tracking fails, while single-frame-based approaches are difficult because they do not make any assumptions for time coherence.
Shotton et al. [1] proposed a new method to predict 3D positions of body joints from a single depth image without temporal information and kinematic constraints. In their method, an intermediate representation of body parts was designed to map the pose estimation problem onto a per-pixel classification problem. An extensive and highly varied set of training data is employed for the random forest classifier to estimate body parts invariant to pose, body shape, clothing, etc. Finally, confidence-scored 3D proposals of several body joints are generated by re-projecting the classification results onto the 3D world and finding local modes. As a result, this approach can quickly and accurately predict the 3D positions of body joints. The skeleton trackers in both the first and second versions of the Kinect SDK are based on this algorithm.
Skeleton tracking algorithms can also be classified into single-view-based models [10-12] and multi-view-based models [13, 14]. The 3D body pose that is estimated using a single view frequently has problems determining positions of joints during self-occlusion motions. There‐
fore, approaches that utilize multiple views have recently begun to receive significant attention.
For example, Zhang et al. [15] fused individual depth images to a joint point cloud and used an efficient particle filtering approach for pose estimation. Likewise, Liu et al. [16] presented a markerless motion-capture approach for multi-view video that reconstructs the skeletal motion and detailed surface geometries of two closely interacting people.
The method presented in this paper is based on the pose estimation results provided by Kinect SDK 2.0, and differs from the methods used by the studies described above. Specifically, our goal was not to develop a method that estimates 3D positions of body joints directly from raw depth images or RGB images, but rather to investigate how to generate more realistic and accurate full-body poses in real time by combining the initially-estimated multiple 3D body poses.
Skeleton tracking performed by a single Kinect sensor also has problems of discontinuous movements, such as unwanted vibration and bone-length variation, because self-occlusion usually results in failure of 3D joint position estimation. Relatively few studies have sought to tackle this problem using multiple Kinect sensors.
Masse et al. [17] presented a framework that obtains 3D positions of body joints from multiple Kinect sensors and then inputs the measured skeletons into a Gated Kalman Filter. In their approach, the gated Kalman filter rejects skeleton poses during processing when the measurement residual, referred to as innovation, is lower than the gating threshold. This is done in order to discard faulty sensor readings and retain correct measurements. For quantitative evaluation, a commercial motion-capture system is used to obtain access to the ground truth. However, the processing step to reject measurements is quite simple and entirely relies on innovation. This might lead often to ineffective measurement fusion.
Yeung et al. [18] developed a single-frame-based approach synthesizing skeletons with duplex Kinect sensors that capture human motion in different views. In their study, each joint had two measurements, reported by two cam‐ eras. The major technical difficulties were how to evaluate the reliability of the two values at each joint, and how to resolve any inconsistencies. To address this problem, they developed a method to estimate confidence in the 3D positions obtained using the Kinect skeleton tracker. Specifically, the distance between a joint i and the closest joint j is estimated by Kinect A, and the distance between the corresponding joint i and the closest joint k is estimated by Kinect B ; then, if the distance between i and j is smaller than the distance between i and k, the joint i obtained by Kinect A is considered as an unreliable estimation; other‐ wise, the joint i obtained by Kinect B is considered as unreliable. This reliability is computed in advance, before the execution of the data fusion procedure based on
mathematical optimization. This data fusion procedure is formulated based on the mathematical optimization problem, in which the objective is to reduce the sum of differences between the estimated joint position and the corresponding more reliable position. The bone-lengths are given as equality constraints.
Both studies described above adopt approaches similar to that presented in the following. First, they do not conduct skeleton tracking based directly on raw depth or RGB images. Second, instead of this, they use estimated skeleton tracking based on multiple Kinect sensors as input, and then refine the initial tracking results based on a different sensor fusion method. However, if we consider the detail of the proposed method, our approach differs from the two methods mentioned above in its determination of the reliabilities of each 3D pose, which are obtained from multiple Kinects. Furthermore, unlike in our method, Yeung et al. do not consider temporal coherence of 3D poses between consecutive frames.
3. Kalman Filter with Weighted Measurement Fusion In this section, we briefly describe Kalman filtering and the data fusion method for achieving Kalman-filter-based multi-sensor data fusion. As mentioned in the Introduc‐ tion, the two most commonly used fusion methods for Kalman filtering are state-vector fusion and measurement fusion. Because the method used in this study involves directly combining sensor measurements to generate a weighted fused measurement, we only describe the measurement fusion method. For further detail see [3]. Consider a linear system. The dynamics and the sensors are modelled by the following discrete-time state-space model:
1 = k k k- + k k+ k x F x G u w (1) = . k k k+ k y H x v (2)
where k represents the discrete-time index and x, y, u, F, G and H are the state vector, measurement vector, input control vector, state transition matrix, input transition matrix, and measurement matrix, respectively. It is as‐ sumed that w is the process noise vector, which has has zero mean with a covariance matrix Q = E
{
wwT}
, and v is themeasurement noise vector, which also has zero mean with a covariance matrix R = E
{
vvT}
. In this work, since weconsider an uncorrelated covariance matrix, Q and R become diagonal matrices given by:
= { } = = 0 T ii ij E ìï í ïî Q ww Q Q (3)
= { } = = 0. T ii ij E ìï í ïî R vv R R (4)
where the dimension of measurement is D and the linear dynamic targets are tracked by N sensors. Both yk and vk
in Eq. (2) are augmented to establish the DN × 1 observation vector as follows: 1 2 = [( )T ( )T ... ( ) ]N T T k k k k y y y y (5) 1 2 = [( )T ( )T ... ( ) ] .N T T k k k k v v v v (6)
In measurement fusion, the N sensor models can be integrated into a single model. The fused measurement covariance, R¯k, fused measurement matrix, H¯k, and fused
measurement vector, y¯k, are given as
1 1 =1 = N( )i k k i -æ ö ç ÷ è
å
ø R R (7) 1 =1 = N( )i k k k k i -æ ö ç ÷ èå
ø H R R H (8) 1 =1 = N( )i . k k k k i -æ ö ç ÷ èå
ø y R R y (9)As shown in Eq. (9), the fused measurement vector y¯k is the weight sum of each measurement vector, in which the inverse of each measurement covariance matrix (Rki)−1 is
used as the weight. Consequently, if the variance of the observation is large, the observation has a weak contribu‐ tion for determining the fused measurement. Otherwise, the observation might have a significant influence on the fused value.
Given the state-space model described by (1) and (2), the Kalman filter provides an unbiased and optimal estimate of the state-vector in the sense of minimizing estimate covariance. The algorithm works in a two-step process, comprising prediction and update steps. The prediction step of the Kalman filter is given by:
| 1 1| 1 ˆk k- = k kˆ - k- + k k x F x G u (10) | 1= 1| 1 T , k k- k k- k- k + k P F P F Q (11)
where x^k |k −1 is an a posteriori state estimate at time k given
observations up to and including time k −1, and where
Pk |k −1 denotes the covariance matrix at time k given observations up to and including time k -1. The update step of the Kalman filter is given by:
(
)
| | 1 | 1 ˆk k=ˆk k- + k k- kˆk k -x x K y H x (12)(
)
| = k | 1, k k I- k k k -P K H P (13)where Kk denotes the Kalman gain matrix and y¯k−H¯kx^k |k −1
is called innovation. The Kalman gain matrix Kk and innovation matrix Sk are described by the following equa‐
tions: 1 | 1 = Tk k k k- k -K P H S (14) | 1 = k Tk k. k k k- + S H P H R (15)
4. Proposed Measurement Fusion Method
Equations (7-9) tell us that in order to fuse measurements appropriately, the most important issue is to determine the covariance matrix of each measurement. Specifically, our method controls the fusion of data by adjusting the augmented measurement noise vector, v, in Eq. (6), according to the reliability of each measurement. This section describes the proposed method to estimate reliabil‐ ity.
However, before explaining the detail of the proposed measurement fusion method, it should be noted that to the best of our knowledge, it is not currently possible for multiple Kinect v2 sensors to be attached to a single PC. Therefore, in this study, each Kinect device was connected to a separate PC. To fuse group sets of measurements, we time-synchronized the local PCs and compared the times at which they acquired measurements.
4.1 Determining measurement noise, vk, based on the predicted state
A measurement vector at time index k obtained from the i -th Kinect is given by:
,1 ,2 ,
= [( ) ( ) ...( ) ] ,
i i T i T i T T
k k k k M
y j j j (16)
where M is the number of joints to be tracked and the m -th joint jk ,m is expressed in Cartesian coordinates:
jk ,m= jk ,m,x jk ,m,y jk ,m,zT. Hence, if we consider M
different joints, the dimension of each measurement is D =3M. We define the state vector xk as the true 3D joint position at time k. Hence, the dimensions of the state and
measurement vector are identical, and Hk in Eq. (8) equals
the identity matrix.
In order to assign reliability of the estimated 3D joint positions acquired from the i -th Kinect at time k, we first calculated the conditional distribution given the predicted state, which is given by
2 | 1 | 1 ˆ ˆ ( |i ) = ( , ), k k k k k py x - N x - s I (17)
where x^k |k −1 is calculated according to Eq. (10) assuming a
multivariate Gaussian probability distribution.
In our model, the state transition matrix F is the D × D identity matrix I, while the D × D input transition matrix G is given as ΔtI, where Δt is the sampling interval. Thus, input control vector u represents the velocities of joints such that the predicted true x-position of the m -th joint at time k takes the following form:
, , | 1, , , , 1, ,
ˆk m x k- m x= k m x+ Dt k- m x,
x x x& (18)
where x˙k −1,m,x denotes the velocities of the joints.
The mean vector of the distribution in Eq. (17) is x^k |k −1 and
the D × D covariance matrix equals σ2I. Hence, if a specific value y' is observed for the x position of the m -th joint acquired from the i -th Kinect at time k, the measurement noise value, vk ,m,xi , becomes:
, , , , , , | 1, , 1 = . ˆ ( = | ) i k m x i ' k m x k m x k m x p y -v y x (19)
Equation (9) tells us that if the measurement noise value of the observation is small, the observation contributes strongly towards determining the fused measurement, whereas the observation might have a weak influence on the combined observations if the value is large. Here, it
should be noted that the measurement noise value in Eq. (19) decreases as the probability becomes greater, and vice versa. Consequently, if the probability in Eq. (19) is low, the corresponding observation yk ,m,xi has a weak contribution
to the fused value, and vice versa.
4.2 Determining measurement noise, vk, based joint motion continuity
The second technique used in this study for assigning reliability to a tracked skeleton is based on estimating continuity in human motion. As mentioned in Section 2, discontinuous motion is usually caused by a failure to estimate the 3D position of a joint, and can be further categorized into two cases. In the first case, the joint is actually moving fast, but the velocity of the joint calculated based on both the current and previous measurements is slow. In the first case, the joint is actually moving slowly, but the velocity of the joint as calculated based on the current and previous measurements is fast. In both cases, it is important to classify whether the joint is actually moving fast or slow: referred to respectively as fast move‐ ment joint and slow movement joint in this study. This classification was established using simple voting, after which high measurement noise values were assigned to the joint moving discontinuously so that the unreliable value had a weak influence on the fused measurement.
Algorithm I outlines the proposed method to detect the two types of discontinuous joint motion and assign high measurement noise value to the joint moving discontinu‐ ously. In this approach, the velocity of each measurement is not actually estimated, but instead is implicitly calculated by computing the distance between the current observation and previously estimated 3D joint positions in Kalman filtering. If the distance is greater than the threshold θf, the measurement is a positive case, which supports the hypothesis that the corresponding joint moves fast. Otherwise, the measurement is a negative case, which does not support the hypothesis. If the number of positive cases is more than half that of the Kinect sensors, the joint is
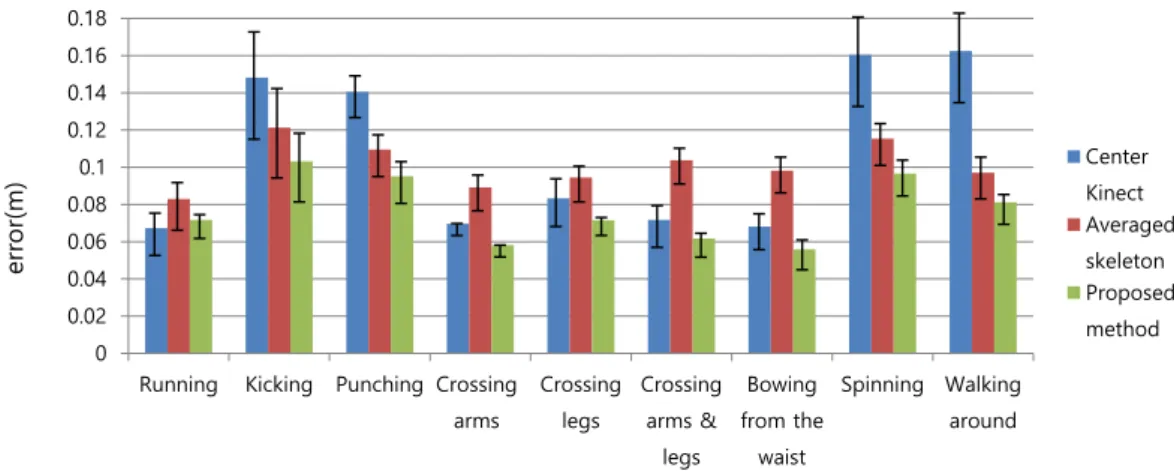
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18
Running Kicking Punching Crossing arms Crossing legs Crossing arms & legs Bowing from the waist Spinning Walking around Center Kinect Averaged skeleton Proposed method err or(m)
Figure 1. The average 3D position error of ten activities compared to the ground truth in a motion sequence. Blue, green, and red represent errors produced
regarded as a fast movement joint. Otherwise, the joint is considered as a slow movement joint. After determining the type of joint, reliability over the measurement acquired from each Kinect sensor is estimated. If a joint is actually moving fast and an observation is classified as a positive case that supports the hypothesis that the corresponding joint moves fast, then a high measurement noise value is assigned to the measurement, and vice versa.
Note that the maximum value among vk ,m,yn , γd(y k ,m n , and
yk −1,mn ) is determined for noise, whereby the value of vk ,m,yn
is assigned based on the predicted state. In practice, determining measurement noise based on continuity of joint motion is executed after choosing the measurement noise based on the predicted state. Thus, the maximum value between two assigned measurement noise values is selected.
5. Experiments 5.1 Experimental setup
We implemented the algorithm proposed in this paper using Visual C++ and the Microsoft Kinect SDK 2.0 on Windows 8 OS. All experimental tests were run on a PC with an Intel Core i5 1.8GHz processor and 4GB RAM. The
Algorithm I
Determining Reliability based on Continuity (yk, yk−1, vk) M : Number of joints to be tracked
N : Number of Kinects
χ[M][N]: M×N 2D array (non-fast joints:0, fast joints:1) d(y0, y00): Euclidean distance between y0and y00
θf : Threshold distance (cm) for fast & non-fast joint motion γ: Scaling factor for m←1 to M count←0 for n←1 to N if d(yn k,m, ynk−1,m) >θf χ[m][n] ←1 count←count+1 else then χ[m][n] ←0 end if end for if count>N2 then for n←1 to N if χ[m][n]= 0 vn k,m,x←max(vnk,m,x, γd(ynk,m, ynk−1,m)) vnk,m,y←max(vnk,m,y, γd(ynk,m, ynk−1,m)) vn k,m,z←max(vnk,m,z, γd(ynk,m, ynk−1,m)) end for else then for n←1 to N if χ[m][n]= 1 vnk,m,x←max(vnk,m,x, γd(ynk,m, ynk−1,m)) vn
k,m,y←max(vnk,m,y, γd(ynk,m, ynk−1,m)) vnk,m,z←max(vnk,m,z, γd(ynk,m, ynk−1,m)) end for
end if end for
4.2. Determining measurement noise, v
k, based joint motion continuity
The second technique used in this study for assigning reliability to a tracked skeleton is based on estimating continuity in human motion. As mentioned in Section 2, discontinuous motion is usually caused by a failure to estimate the 3D position of a joint, and can be further categorized into two cases. In the first case, the joint is actually moving fast, but the velocity of the joint calculated based on both the current and previous measurements is slow. In the first case, the joint is actually moving slowly, but the velocity of the joint as calculated based on the current and previous measurements is fast. In both cases, it is important to classify whether the joint is actually moving fast or slow: referred to respectively as fast movement joint and slow movement joint in this study. This classification was established using simple voting, after which high measurement noise values were assigned to the joint moving discontinuously so that the unreliable value had a weak influence on the fused measurement.
Algorithm I outlines the proposed method to detect the two types of discontinuous joint motion and assign high measurement noise value to the joint moving discontinuously. In this approach, the velocity of each measurement is not actually estimated, but instead is implicitly calculated by computing the distance between the current observation and previously estimated 3D joint positions in Kalman filtering. If the distance is greater than the threshold θf, the
measurement is a positive case, which supports the hypothesis that the corresponding joint moves fast. Otherwise, the measurement is a negative case, which does not support the hypothesis. If the number of positive cases is more than half that of the Kinect sensors, the joint is regarded as a fast movement joint. Otherwise, the joint is considered as a slow movement joint. After determining the type of joint, reliability over the measurement acquired from each Kinect sensor is estimated. If a joint is actually moving fast and an observation is classified as a positive case that supports the hypothesis that the corresponding joint moves fast, then a high measurement noise value is assigned to the measurement, and vice versa. Note that the maximum value among vnk,m,y, γd(ynk,m, and ynk−1,m)is determined for noise, whereby the value of vnk,m,yis assigned based on the predicted state. In practice, determining measurement noise based on continuity of joint motion is executed after choosing the measurement noise based on the predicted state. Thus, the maximum value between two assigned measurement noise values is selected.
Microsoft Kinect SDK 2.0 can extract skeleton data at approximately 30 frames per second (fps). The proposed skeleton enhancement algorithm generates results at a speed of 10 msec per frame, on average. As a result, the final tracking ran at approximately 20-25 fps, allowing real-time extraction of skeleton data.
To evaluate the proposed method in terms of the precision of 3D positions of the human body joints, we employed an OptiTrack motion-capture system to provide a set of ground truth trajectories. In addition, for quantitative comparison, the joint trajectories were recorded by a single Kinect and averaged across multiple Kinect sensors. We deployed five Kinect sensors covering 180°, resulting in an average angle of approximately 45° between two Kinect sensors. Berger [20] summarized state-of-the-art papers which have built on RGB-D camera setups that include two or more Kinect v1 sensors. In this study, different Kinect sensor setups for motion estimation, reconstruction, tracking, and recognition are introduced, including the right number of sensors with appropriate position, orien‐ tation, etc. These recommended conditions are determined mainly to mitigate interference error caused by inherent properties of the Kinect v1 sensor, and are changed depending on the type of task, for example tracking, reconstruction, or recognition, and the experimental setup, for example size of room.
However, there seems no agreement on the right number and appropriate poses of Kinect v2 sensors for effective skeleton tracking. Two mutually exclusive criteria that can be suggested intuitively are that the number of Kinect sensors should be as small as possible and that the size of the self-occlusion region should be reduced as much as possible. Some researchers [17, 19] have employed three cameras to tackle the occlusion issue in skeleton tracking, but we found in our experimental setup that five Kinect sensors can achieve the best performance. The distance from each Kinect to the centre position was about 3 m and the height of each Kinect above the ground plane was 130 cm.
Five Kinect sensors were extrinsically calibrated using a checkerboard. Specifically, the local coordinates of the centre Kinect sensor were considered as the global refer‐ ence frame, and each Kinect and the motion-capture system were then calibrated in relation to the centre Kinect sensor, so that each 3D skeleton pose was represented in the global coordinate system.
A total of 25 joints are supported by Kinect v2: spinebase, spinemid, neck, head, shoulderleft, elbowleft, wristleft, handleft, shoulderright, elbow-right, wristright, handright, hipleft, kneeleft, ankleleft, foot-left, hipright, kneeright, ankleright, footright, spineshoulder, handtipleft, thumbleft, handtipright, and thumbright. In the experiments, head, handleft, hand‐ right, handtipleft, thumbleft, handtipright, thumbright, footleft and footright were excluded to calculate the precision of tracked joints: some of these joints, such as thumbleft and 6 Int J Adv Robot Syst, 2016, 13:65 | doi: 10.5772/62415
thumbright, are very unstable, while others are not support‐ ed by the motion-capture system.
The parameters used in our method were sampling interval Δt in Eq. (18), threshold distance (cm) for dividing fast & non-fast measurement, θf, scaling factor γ in Algorithm I, variance σ2 in Eq. (17), and process noise matrix Q. These were set to 30 msec, 3 cm, 3.0, 0.1, and I, respectively, in all experiments.
5.2 Results and discussion
Experiments were conducted to compare the precision of the proposed algorithm with that of a single Kinect sensor and simple averaging of five skeleton poses. We tested ten activity classes consisting of running, kicking, punching, crossing arms, crossing legs, crossing arms and legs, bowing from the waist, sitting on the chair, spinning, and walking around.
Each activity class was repeated ten times and the average errors were computed for each activity. Every activity started with a standing pose, and certain activities were then repeated several times, for example crossing arms and punching. An activity was composed of approximately 200 300 frames. Every activity except spinning and walking around was performed facing the centre Kinect sensors. For the cases of spinning and walking around, the minimum and maximum orientations relative to the centre Kinect were -90° and 90°, respectively, because the five Kinect sensors covered 180° and we did not allow the centre Kinect to look at the performing subject’s back.
Figure 1 shows the average 3D position error of the ten activities compared to the motion sequence captured by the motion-capture system. In the figure, the blue, green, and red bars represent the level of error produced by the centre-Kinect, simple-average, and proposed methods, respec‐
-0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8
(a)
(b)
2.4 2.5 2.6 2.7 2.8 2.9 3 3.1 3.2 1 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 -0.75 -0.7 -0.65 -0.6 -0.55 -0.5(c)
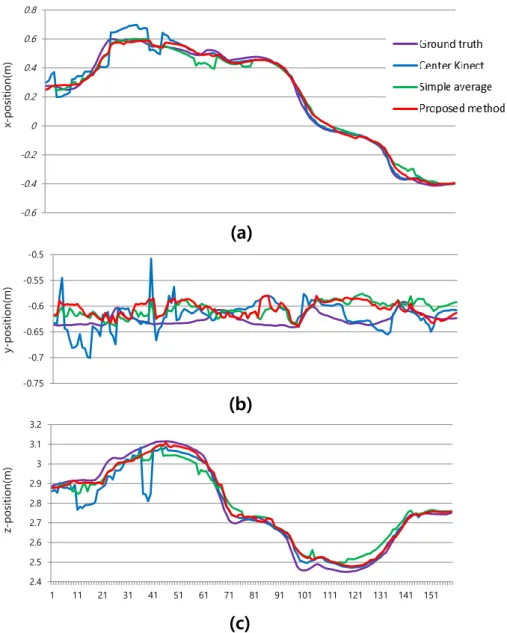
x-position(m) y-position(m) z-position(m)Figure 2. Graphs are obtained during walking around behaviour. The x-axes of the graphs denote frame number, and (a), (b), and (c) plot x, y, and z positions
of the right knee joint, respectively. The position trajectories for the single-Kinect, simple-average, and proposed methods are shown, with a comparison of errors with respect to the ground truth of the right knee position.
tively. In evaluating these data, it should be noted that the positions of the corresponding joints between the motion-capture system and Kinect were not matched perfectly, For example, if a performing subject was just standing facing the centre Kinect, i.e., the centre Kinect observed the performing subject without self-occlusion, the average position error of 16 joints observed by the centre Kinect was approximately 5.5 cm.
We noted that for the activities of spinning and walking around, the errors produced by the centre Kinect were much larger than those generated by the simple-average and proposed methods, which was attributed to the two activities involving poses in which half of the body was often self-occluded. It can be seen that five 3D poses simple-averaged gives better results than the centre-Kinect method. But the best performance was achieved with the proposed method for most activities except running. The average errors produced by the centre-Kinect, simple-average, and proposed methods are 9.71 cm, 9.12 cm, and 6.95 cm, respectively.
Figure 2 (a-c) shows the trajectories of the x, y, and z positions of the right knee joint during walking around behaviour, while the x-axes of the three graphs denote frame number. The position trajectories produced by a single Kinect, by a simple average, by the approach described in this study, and by the ground truth of the right knee position were compared. We observed that the estimated 3D joint positions produced by a single Kinect often deviated with considerable error. The average Euclidean distance errors were 6.03 cm, 6.26 cm, and 4.68 cm, respectively. The proposed method was thus able to track true 3D joint positions with relatively small error. For qualitative comparison, the tracking results generated by three comparative approaches are displayed along with increasing frame number. Figure 3 shows 3D skeleton poses obtained by the motion-capture system and the
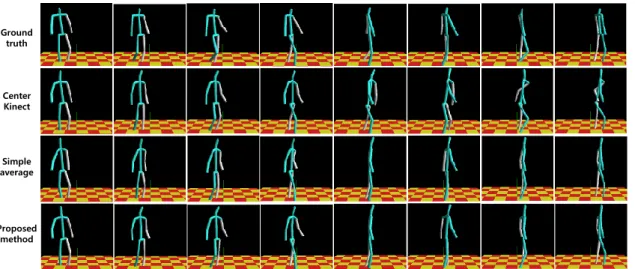
centre-Kinect, simple-average, and proposed methods during walking around behaviour. We observed that significant error was generated by the centre Kinect after five frames. In the case of the simple-average method, the distance between two shoulder joints is much shorter than with the motion-capture system from the first to the third frame. Our approach achieved the smallest error and reflected the natural movement of the performing subject more accurately than the other methods.
6. Conclusions
The goal of this paper was to enhance the skeleton poses extracted using a single Kinect v2, which often generates poor poses due to self-occlusion. To solve this problem, we proposed a real-time motion-tracking technique utilizing multiple Kinect sensors. In this approach, the major technical problem was how to resolve inconsistencies between the positions of each joint reported by the multiple Kinects. To address this issue, rather than changing the motion extraction method, we employed a Kalman filter framework to fuse five skeletons extracted per frame. The main contribution of the method described in this paper is the ability to determine the reliability of each tracked 3D position of a joint and combine multiple observations based on confidence. We evaluated the proposed method by comparison with the ground truth acquired from a commercial motion-capture system and results generated by a single Kinect sensor and a simple averaging technique. Among the different methods, our approach was the most robust and accurate, and performed considerably better than the two comparative approaches in the presence of occlusions.
7. Acknowledgements
This work was supported by the Global Frontier R&D Program on "Human-centered Interaction for Coexistence" Ground truth Center Kinect Simple average Proposed method
Figure 3. Walking around behaviour by a performance subject. The tracked 3D poses generated by the motion-capture, centre-Kinect, simple-average, and
proposed methods are displayed in the first through fourth rows, respectively. The horizontal axis represents time. Each column comprises the closest tracking results across the methods for each time; the maximum time difference within a column is 100 msec.
funded by the National Research Foundation of Korea, grant-funded by the Korean Government (MSIP) (2010-0029744).
8. References
[1] J. Shotton, A. Fitzgibbon, M. Cook, T. Sharp, M. Finocchio, R. Moore, A. Kipman, and A. Blake, "Real-time human pose recognition in parts from single depth images," International Conference on Computer Vision and Pattern Recognition (CVPR), 2011.
[2] S. T. Goh, O. Abdelkhalik, and S. A. Zekavat, "A Weighted Measurement Fusion Kalman Filter Implementation for UAV Navigation," Vol. 28, Aerospace Science and Technology, pp. 315-323, 2013.
[3] Q. Gan, C. Harris, "Comparison of two measure‐ ment fusion methods for Kalman filter-based multisensor data fusion," IEEE Transactions on Aerospace and Electronic Systems, vol. 37, no. 1, pp. 273-279, 2001.
[4] C. Ran, Z. Deng, "Two correlated measurement fusion Kalman filtering algorithms based on orthogonal transformation and their functional equivalence," in: Proceedings of the 48th IEEE Conference on Decision and Control, pp. 2351-2356, 2009.
[5] J. Roecker, C. McGillem, Comparison of two-sensor tracking methods based on state vector fusion and measurement fusion," IEEE Transactions on Aerospace and Electronic Systems, vol. 24, no. 4, pp. 447-449, 1988.
[6] I. Mikic, M. M. Trivedi, E. Hunter, and P. Cosman, "Human body model acquisition and tracking using voxel data," Int. J. Comput. Vis., vol. 53, no. 3, pp. 199-223, 2003.
[7] F. Caillette, A. Galata, and T. Howard, "Real-time 3-D human body tracking using learnt models of behaviour," Comput. Vis. Image Understand., vol. 109, pp. 112-125, 2008.
[8] J. Gall, B. Rosenhahn, T. Brox, and H. Seidel, "Optimization and filtering for human motion capture: A multi-layer framework," Int. J. Comput. Vis., vol. 87, no. 1-2, pp. 75-92, 2010.
[9] A. Sundaresan and R. Chellappa, "Model driven segmentation of articulating humans in Laplacian eigenspace," IEEE Trans. Pattern Anal. Mach. Intell., vol. 30, no. 10, pp. 1771-1785, 2008.
[10] S. Park and M. Trivedi, "Understanding human interactions with track and body synergies (TBS) captured from multiple views," Comput. Vis. Image Understand., vol. 111, no. 1, pp. 2-20, 2008. [11] J. Ziegler, K. Nickel, and R. Stiefelhagen, "Tracking
of the articulated upper body on multi-view stereo
image sequences," in Proc. Comput. Vis. Pattern Recognit., 2006.
[12] M. Hofmann and D. Gavrila, "Multi-view 3D Human Pose Estimation in Complex Environment," International Journal of Computer Vision, pp. 1-22, 2011.
[13] A. Baak, M. Muller, G. Bharaj, H.-P. Seidel, and C. Theobalt, "A data-driven approach for real-time full body pose reconstruction from a depth camera," In: ICCV, pp. 1092-1099, Nov. 2011.
[14] Q. Zhang, X. Song, X. Shao, R. Shibasaki, H. Zhao, "Unsupervised skeleton extraction and motion capture from 3D deformable matching," Neurocom‐ puting, Elsevier, pp. 170-182, 2013.
[15] L. Zhang, J. Sturm, D. Cremers, and D. Lee, "Real-Time Human Motion Tracking using Multiple Depth Cameras," Proc. of the International Confer‐ ence on Intelligent Robot Systems (IROS), 2012. [16] Y. Liu, J. Gall, C. Stoll, Q. Dai, H.-P. Seidel, and C.
Theobalt, "Markerless Motion Capture of Multiple Characters Using Multi-view Image Segmentation," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 11, pp. 2720-2735, 2013. [17] J.-T. Masse, F. Lerasle, M. Devy, A. Monin, O.
Lefebvre, and S. Mas, "Human Motion Capture Using Data Fusion of Multiple Skeleton Data," ACIVS, Lecture Notes in Computer Science, vol. 8192, pp. 126-137, Springer, 2013.
[18] K. Y. Yeung, T. H. Kwok, C. L. Wang, "Improved Skeleton Tracking by Duplex Kinects: A Practical Approach for Real-Time Applications," Journal of Computing and Information Science in Engineer‐ ing, vol. 13, no. 4, pp. 1-10, 2013.
[19] J. Deutscher and I. Reid, "Articulated Body Motion Capture by Stochastic Search," International Journal of Computer Vision, vol. 61, no. 2, pp. 185-205, 2005. [20] K. Berger, "A State of the Art Report on Multiple RGB-D Sensor Research and on Publicly Available RGB-D Datasets," Computer Vision and Machine Learning with RGB-D Sensors, pp. 27-44, Springer, 2014.
[21] J. Corrales, G. Garcia Gomez, F. Torres and V. Perdereau1, "Cooperative Tasks between Humans and Robots in Industrial Environments," Interna‐ tional Journal of Advanced Robotic Systems, vol. 9, no. 94, 2012.
[22] G. Du, P. Zhang, J. Mai and Z. Li, "Markerless Kinect-Based Hand Tracking for Robot Teleopera‐ tion" International Journal of Advanced Robotic Systems, vol. 9, no. 36, 2012.
[23] A. Cosgun, M. Bunger, and H. Christensen, "Accu‐ racy analysis of skeleton trackers for safety in HRI," in: Workshop on Safety and Comfort of Humanoid Coworker and Assistant (Humanoids), 2013. [24] G. Cicirelli, C. Attolico, C. Guaragnella, and T.
approach for a natural human robot interface," International Journal of Advanced Robotic Systems, vol. 12, 2015.
[25] D. Tommaso, S. Calinon and D. Caldwell, "A Tangible Interface for Transferring Skills - Using Perception and Projection Capabilities in
Human-Robot Collaboration Tasks," International Journal of Social Robotics, Special Issue on Learning from Demonstration, pp. 1-12, 2012.
[26] A. Yao, J. Gall, G. Fanelli and L. Gool, "Does Human Action Recognition Benefit from Pose Estimation?," in: BMVC, 2011.