Video Expression Recognition Method Based on Spatiotemporal Recurrent Neural Network and Feature Fusion
전체 글
수치
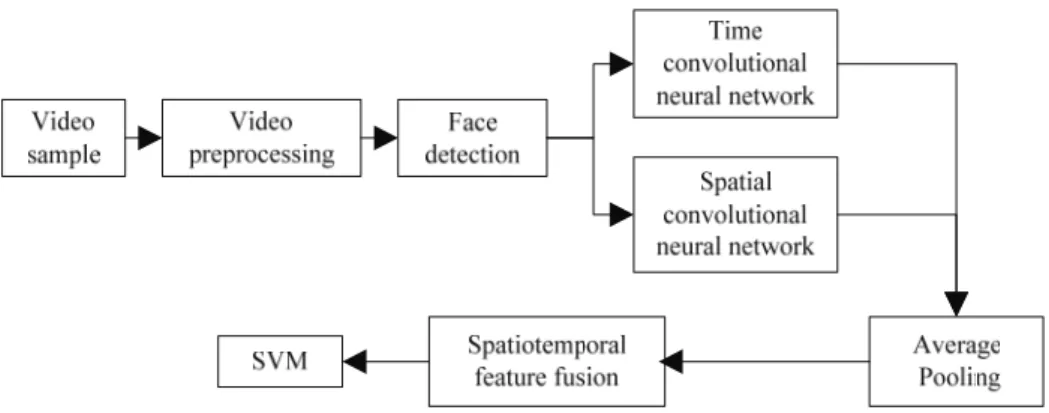

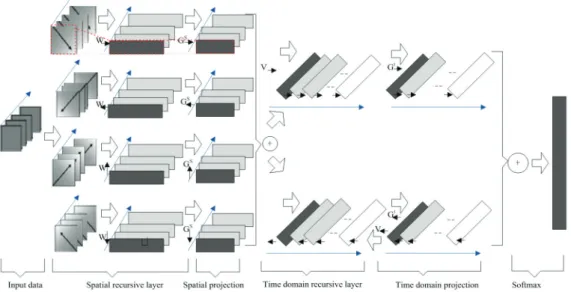
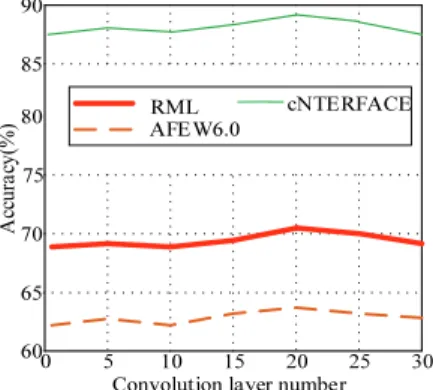

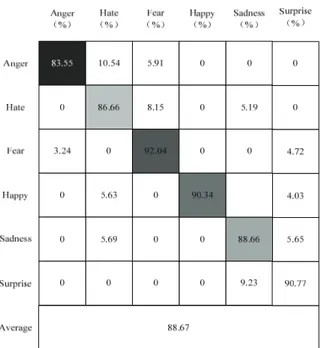
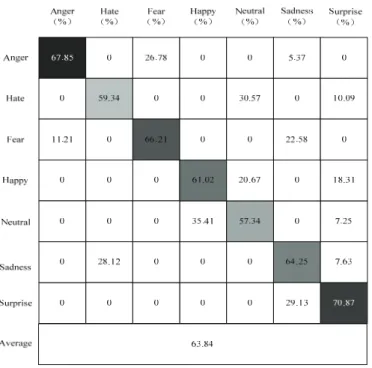
관련 문서
Herein we address this problem by proposing a hierarchical cascaded classifier for video face recognition, which is a multi-layer algorithm and accounts for the
In this chapter, we introduce unsupervised pattern recognition using a spiking neural network (SNN) based on the proposed synapse device and neuron circuit.. Unsupervised
1 John Owen, Justification by Faith Alone, in The Works of John Owen, ed. John Bolt, trans. Scott Clark, "Do This and Live: Christ's Active Obedience as the
The results of the UoB database showed that the largest recognition rate of the proposed method was delivered by using five training sets, which is the
– An artificial neural network that fits the training examples, biased by the domain theory. Create an artificial neural network that perfectly fits the domain theory
As for learning participation frequency, physical recognition, performance recognition, social recognition, and psychological recognition concerning on
Motivation – Learning noisy labeled data with deep neural network.
A Study on the Evaluation of Space Recognition Space Recognition Space Recognition in the Space Recognition in the in the in the Concourse of Hospital using the
