Predictive genomics를 통한 종양 임상 표현형을 예측하는 방법론 이성환 Page 1 / 11 BRIC View 2018-T33
Predictive genomics를 통한 종양 임상 표현형을
예측하는 방법론
이 성 환
The University of Texas MD Anderson Cancer Center / 연세의대 외과학교실 E-mail: [email protected] / [email protected]
요약문 전세계적으로 수년간 진행된 대규모 암 유전체 프로젝트들의 결과로 광범위한 대규모 유전체 데이터가 수집되었지만, 아직 개별 환자에 대한 암의 발생 및 진행 예측 그리고 최적화된 항암 치료 전략 수립은 아직 걸음마 단계이다. 최근 대두된 정밀 의학(Precision medicine)은 환자의 유전체 및 임상 정보를 통합하여 개별 환자에게 최적화된 맞춤형 치료 제공을 목표로 하며, Predictive genomics는 정밀 의학 실현을 위한 핵심 방법론으로 이용되고 있다. 암 환자의 종양 검체 등을 이용하여 암종의 분자생물학적 아형(Molecular subtype), 종양 면역학적(Immuno-oncology) 특성, 항암 약물 반응성(Drug response for cancer therapeutics) 등의 종양 임상 표현형(Tumor clinical phenotype)을 예측하는 데에 Predictive genomics의 여러 연구 방법이 사용되고 있다. 본 동향리포트에서는 Predictive genomics의 개념 및 최근 연구 동향 그리고 실제 구현을 위한 다양한 방법 및 도구들을 소개하고자 한다.
Key Words: Predictive genomics, Tumor clinical phenotype, Precision medicine, Molecular subtype, Immuno-oncology, Drug response
목 차
1. 서론 2. 본론 2.1 Predictive genomics의 개념 2.2 다중 오믹스 데이터를 활용한 종양 임상 표현형 예측 2.3 Predictive genomics를 활용한 항암 정밀 의료의 실현 2.4 종양 임상 표현형 예측을 위한 Predictive genomics의 실제 및 활용 가능한 도구들 BRIC View 동향리포트Predictive genomics를 통한 종양 임상 표현형을 예측하는 방법론 이성환 Page 2 / 11 3. 결론 4. 참고문헌
1. 서론
최근 보건의료 분야 연구개발의 최대 화두 중 하나는 정밀 의료(Precision medicine)이다. 정밀 의료란 유전체 정보, 진료 및 임상 정보, 생활습관과 관련된 다양한 보건의료 데이터를 통합 분석하여 개개인 환자에게 가장 적합한 맞춤형 의료서비스를 제공하는 것을 의미한다[1-3]. 전통적인 보건의료의 개념이 환자에게 획일적으로 선험적(Empirical) 혹은 보편적인 치료를 제공하는 것이였다면, 최근의 정밀 의료의 개념은 유전체 정보를 주축으로 환자의 다양한 건강 관련 데이터를 통합하여 환자의 예후를 예측하고 이를 개선하기 위한 최선의 의료 서비스를 제공하는 데에 집중한다. 정밀 의료 실현을 위해 다양한 생의학 데이터 및 보건의료 데이터가 필요하며, 이중 유전체 데이터는 가장 중요한 정보 자원으로 사용 되고 있다. 환자의 질병 예후를 예측하여 사전에 적합한 치료를 제공하기 위한 질병 관련 유전체 분석은 이제 선택이 아닌 필수적 의료 행위가 되었으며, 특히 암 환자의 생존율 향상과 삶의 질 개선을 위해 필수적인 의료 서비스로 활용되고 있다[4]. 암 환자에서 유래된 다양한 검체(종양, 정상조직, 혈액, 소변, 대변 및 각종 체액)를 활용하여 다중 오믹스(Multi-omics) 데이터 분석을 수행하여 환자의 다양한 종양 임상 표현형을 예측하고 최적의 치료 방법을 찾는 일련의 과정을 Predictive genomics로 정의할 수 있다. 따라서 Predictive genomics는 정밀 의료의 핵심 방법론으로 각광 받고 있으며, 전세계적으로 암 환자의 예후 및 삶의 질 개선을 위한 다양한 연구가 진행되고 있다[5-7]. 본 동향리포트에서는 Predictive genomics의 포괄적이고 실제적인 개념을 설명하고, 이를 구현하기 위한 다양한 방법과 도구들을 소개하고자 한다.2. 본론
2.1 Predictive genomics의 개념
정밀 의료(Precision medicine)는 개별 환자에 최적화된 건강관리(Healthcare), 의학적 판단(medical decision), 약물치료(Medication), 의료행위(Medical practice) 등의 시행을 목표로 한다. 이를 위하여 환자의 검체에서 획득한 유전체 정보가 필수적으로 사용되며, Predictive genomics는 이러한 유전체정보를 통하여 환자의 질병 예후 및 약물 반응성 등을 예측하는 정보를 제공한다. Predictive genomics는 개별 환자의 질병 관련 예후를 예측하기 위하여 다양한 학문의 개념 및 방법론을 포괄적으로 활용한다. 다양한 환자 관련 정보를 활용하여 환자의 질병 예후를 예측하는 Predictive medicine, 개별 환자의 다양한 검체에서 유전체를 추출하여 활용하는 Personal genomics, 그리고 획득된 유전체 데이터를 활용하기 위하여 데이터의 정제 및 가공, 해석을 수행하는
Predictive genomics를 통한 종양 임상 표현형을 예측하는 방법론 이성환 Page 3 / 11
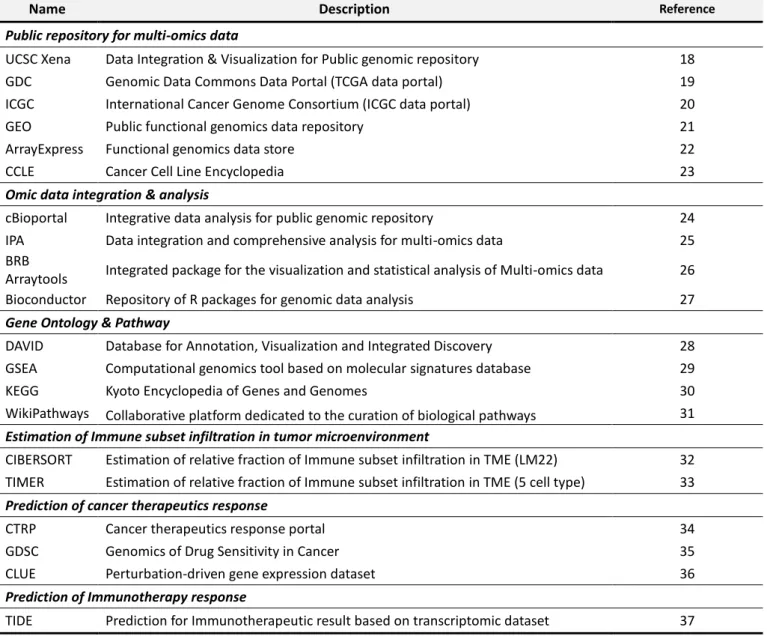
Translational bioinformatics 등의 정밀 의학 핵심 방법론의 접점에 Predictive genomics가 있다[4, 6](그림 1).
그림 1. Predictive genomics의 개념.
이를 위해 생물정보학(Bioinformatics)뿐만 아니라 데이터 사이언스(Data Science)의 다양한 방법론이 활용 되어야 하며, 질병 관련 정보를 적극 활용하기 위한 의료진의 참여 또한 필수적이다. 최근 다양한 학문의 융합과 협업을 통해 이전에 없었던 새로운 지식이 생성되고 여러 분야의 난제가 해결되는 사례들은 정밀 의료 영역에서도 쉽게 찾아볼 수 있으며, Predictive genomics는 이러한 다양한 학문의 융합과 협업의 핵심 무대로 활용되고 있다[8-9].
2.2 다중 오믹스 데이터를 활용한 종양 임상 표현형 예측
기존의 전통적인 생의학적 연구방법론들은 복잡 다단한 생명 현상의 이해뿐만 아니라 질병의 발생과 진행에 대한 체계적 해석과 예측에 있어 한계를 드러내어 왔다[10]. 질병의 특정 표현형 (Phenotype)이 단일 유전형(Genotype)으로 설명될 수 있는 경우는 매우 제한적이며, 대부분의 질병 관련 표현형은 다양한 유전형이 관여하는 것으로 알려져 있다. 또한 단일 유전형이 여러 표현형과 연계된다는 실험적 관찰은 생체 내에서 발생하는 다양한 생명 현상의 복잡성(Complexity)을 방증(Corroboration)한다. 미시적(Microscopic)으로는 주요 생체 분자(DNA, RNA, Protein)들의 생화학적 구조 및 다양한 상호 작용(interaction)에 발생한 이상 변화가 정교하게 조절되던 생명 현상의 오류 및 이로 인한 질병 발생에 관여하며, 거시적(Macroscopic)으로는 인체 조직과 장기 간의 내분비 시스템(Endocrine system)을 통한 신호 전달 및 면역 체계(Immune system)의 질병에 대한 반응, 더 나아가 인체 내에 공생하는 다양한 미생물계(Microbiome)의 분획Predictive genomics를 통한 종양 임상 표현형을 예측하는 방법론 이성환 Page 4 / 11
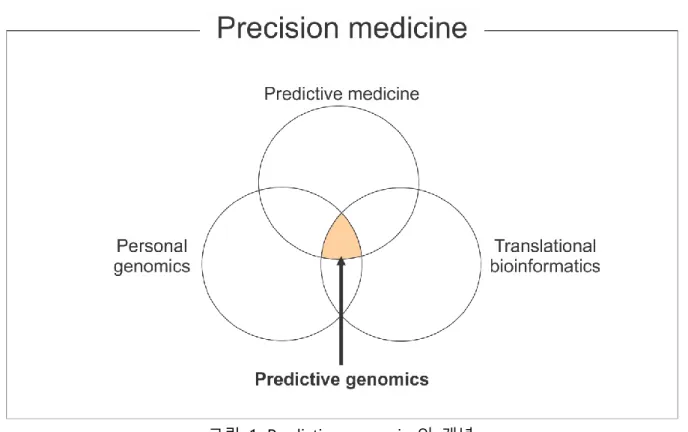
및 면역 체계와의 조화가 각종 질병 발생과 예후에 관여한다는 것이 질병 현상에 대한 현재의 시스템 생물학(Systems Biology)적 이해이다[8, 11-12]. 따라서 생명 현상에 대한 근본적 이해 및 질병에 대한 체계적인 접근을 위하여 차세대 염기서열 분석(Next Generation Sequencing)을 필두로 다양한 High throughput genomic technique들이 개발 되었고, 이를 통해 질병과 관련된 유전체(Genome), 후성유전체(Epigenome), 전사체(Transcriptome), 단백체(Proteome), 대사체(Metabolome) 등에 대한 대규모의 데이터가 수집 되었다[13]. 이러한 다중 오믹스(Multi-omics) 데이터의 수집과 체계적인 분석은 복잡한 생명 현상의 예측과 치료적 개입(Therapeutic Intervention)에 중요한 단서로 활용되고 있다. 특히 종양학 분야에서 이러한 연구 동향은 주요 연구 방법론으로 자리 잡고 있다(그림 2).
그림 2. 질병 표현형 분석 및 예측을 위한 다중 오믹스 데이터의 활용.
[SNP, Single Nucleotide Polymorphism; InDel, Insertion and Deletion; CNV, Copy Number Variation; SV, Structural Variation; LncRNA, Long non-coding RNA; PTM, Post-translational Modification]
2006년에 시작되어 2017년에 종료된 TCGA (The Cancer Genome Atlas) 프로젝트는 33개의 암종, 11,000명의 환자에서 7종류의 다중 오믹스 데이터 및 주요 임상 데이터를 획득하였으며 이를 전세계 연구자들에게 무상으로 공개하고 있다[14]. 대규모로 진행된 TCGA, ICGC (International Cancer Genome Consortium) 프로젝트뿐만 아니라 소규모 연구자 중심의 유전체 데이터 또한 NCBI GEO, ArrayExpress 등의 다양한 공공 저장소(Public repository)에 수집되어 활용 가능하다. 이를 통해 전세계적으로 활발한 암 유전체 관련 중개연구가 수행되고 있으며, Predictive genomics는 다중 오믹스 데이터 분석의 핵심 연구 분야로 활용되고 있다.
Predictive genomics를 통한 종양 임상 표현형을 예측하는 방법론 이성환 Page 5 / 11
2.3 Predictive genomics를 활용한 항암 정밀 의료의 실현
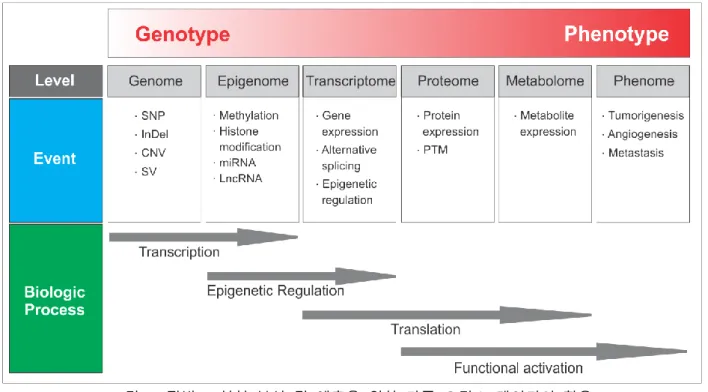
위에서 언급한 암 관련 중개연구, 다중 오믹스 데이터 분석 연구는 최종적으로 각종 암종의 발생 기전 규명, 분자 아형의 선별을 통한 암 환자군의 재분류, 이를 통한 암 관련 예후의 정밀 예측 및 바이오마커를 기반으로 한 개별 환자에 대한 최적의 치료법 도출을 목적으로 한다(그림 3). 그림 3. 정밀 의료 실현을 위한 Predictive genomics 방법론. 이는 정밀 의료의 핵심 가치와 일맥상통 하며, 향후 환자 건강 관련 데이터와 결합될 경우 고위험군에서의 암 발생 예측과 선제적 예방, 조기 발견을 통한 생존율 향상, 암 환자의 삶의 질 개선에 큰 기여를 하게 될 것으로 예상된다. 이를 위해 환자의 다양한 검체에서 획득된 다중 오믹스 데이터의 체계적(Integrative)이고 통합적인(Comprehensive) 분석이 필요하며 환자의 임상 데이터(Clinical Data)와의 밀접한 연계 분석이 필수적이다[15]. 최근 급격히 발전하고 있는 머신 러닝(Machine Learning)을 필두로 한 데이터 사이언스(Data Science)의 다양한 데이터 분석 방법론들은 다중 오믹스 데이터 분석에 적극적으로 사용되고 있다. 복잡하게 얽혀 있는 방대한 데이터 속에 숨겨진 핵심 정보를 찾아 내어, 현재를 진단하고 미래를 예측하며 효과적으로 대비할 수 있는 통찰을 얻는다는 데이터 사이언스의 핵심 가치는 Predictive genomics가 추구하는 주요 연구 목표와 온전히 맞닿아 있다. 최근 암 유전체 연구 동향은 다중 오믹스 데이터와 임상 데이터의 실제적인 융합과 통합적 분석을 위해 기존의 통계학적 방법론뿐만 아니라 최신 머신 러닝 방법론들을 적극적으로 활용하고 있다[16-17].Predictive genomics를 통한 종양 임상 표현형을 예측하는 방법론 이성환 Page 6 / 11
2.4 종양 임상 표현형 예측을 위한 Predictive genomics의 실제 및 활용 가능한 도구들
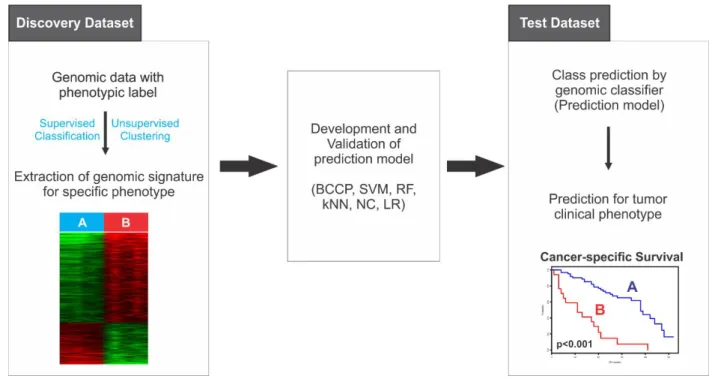
암종의 임상 관련 표현형(Tumor clinical phenotype)을 예측하기 위하여 다양한 분석 방법이 적용될 수 있다. 원칙적으로 높은 신뢰도 및 재현성을 가진 연구 결과를 얻기 위하여 복수의 코호트에서 획득된 대규모의 데이터를 이용한 타당성 검증(Internal and External Validation) 및 연구 결과의 유의성에 대한 엄격한 통계학적 확인(Statistical Evaluation)이 필수적이다[38]. 이를 위하여 암 환자들의 비식별화된 다중 오믹스 데이터를 제공하는 공공 저장소(Public Repository for Multi-omics data)를 연구에 적극 활용할 수 있다. 본 동향리포트에서는 Predictive genomics를 활용하여 암종의 임상 관련 표현형을 예측하기 위한 중개 연구(Translational research)의 대표적인 연구 모델 중 하나를 소개하고자 한다. 연구자가 가진 개별 유전체 데이터(In-house Genomic dataset)에서 특정 phenotype의 현격한 차이를 보이는 유전체의 변이 혹은 발현 패턴을 확인하였고, 이 패턴이 다른 유전체 코호트의 동일한 암종 내에서 혹은 다른 암종에서도 같은 종양 표현형을 일관되게 예측하는 지를 체계적으로 검증하기 원한다면 다음의 분석 방법을 수행할 수 있다.
그림 4. 종양 임상 표현형 예측 모델의 구축과 검증.
[BCCP, Bayesian Compound Covariate Predictor; SVM, Support Vector Machine; RF, Random Forest; kNN, k-Nearest Neighbor; NC, k-Nearest Centroid; LR, Lasso Regression]
우선 Discovery dataset에서 Supervised classification 혹은 Unsupervised clustering (Hierarchical clustering or Dimension reduction)을 통하여 분류된 그룹이 특정 phenotype의 현격한 차이를 보일 경우 이를 반영하는 Genomic signature를 추출할 수 있다. 이어서 다양한 통계학적 추론, 머신 러닝 기법을 통하여 고성능의 예측 모델을 구축(Development) 및 교차 검증(Cross
Predictive genomics를 통한 종양 임상 표현형을 예측하는 방법론 이성환 Page 7 / 11
validation)하게 되며, 이 과정을 통하여 요약 정리된 핵심 유전체, 전사체, 단백체 등의 변이 혹은 발현 패턴은 특정 표현형을 예측 한다고 가정할 수 있다. 이에 대한 최종 확인을 위하여 여러 Test dataset에 prediction model을 적용하여 각 tumor sample의 표현형(Phenotypic class)을 예측하고 실제 표현형과의 일치 여부에 대한 통계학적 검증을 거치게 되면 연구자가 제시한 유전체 패턴의 표현형 예측 가능성을 확인할 수 있다[39].
그림 5. 암 유전체를 이용한 중개연구와 관련된 핵심 키워드. [API, Application Programming Interface; TME, Tumor Micro-environment]
위에서 소개한 방법론은 Predictive genomics, 더 나아가 중개 의학 연구(Translational biomedical research)에서 사용하는 다양한 분석 방법 중 일부에 불과하다. 연구자가 가진 가설(Hypothesis) 혹은 대규모 오믹스 데이터에서 발굴된 유의한 관찰(Significant observation)이 종양의 주요 표현형으로 의미있게 귀결되는 지 확인하기 위해 주요 암 유전체 코호트의 체계적인 수집 및 생명 현상을 조절하는 다양한 분자 수준 체계적 데이터(유전체, 후성유전체, 전사체, 단백체,
Predictive genomics를 통한 종양 임상 표현형을 예측하는 방법론 이성환 Page 8 / 11 대사체) 에 대한 포괄적이고 통합적인 분석, 그리고 분석 결과의 생의학적인 의미에 대한 심도 있는 통찰이 필요하다. 따라서 다양한 플랫폼의 분석 방법론과 알고리즘이 유전체 데이터 분석 전반에 효과적으로 사용되어야 하며, 이를 통해 도출된 분석 결과에 대한 생물정보학자, 생물학자, 임상의사의 의견 공유와 합의된 결과 도출이 필요하다. 암 유전체를 이용한 중개연구의 성공을 위해 생물정보학 및 데이터 사이언스의 다양한 플랫폼과 알고리즘이 적재적소에 사용될 수 있으며, 분자 수준에서의 암 유전체의 변이 및 발현 특징을 종합하여 암 환자가 가진 생체 시스템(Ecosystem)을 규명하고 이상을 탐지하는 일련의 과정은 Predictive genomics를 통한 암 중개연구의 핵심이다. 이를 통하여 개별 암 환자가 가진 암 유전체의 특성, 즉 분자생물학적 아형(Molecular subtype) 및 종양 면역학적 특징(Immuno-oncologic trait)들을 암 치료에 적극 반영하고 바이오마커에 기반한 약물 반응성 예측 데이터를 환자의 항암 약물 치료에 반영한다면 항암 정밀 의료는 비로소 실현될 수 있다(그림 5).
표 1. 암 유전체 데이터 수집과 분석에 활용되는 대표적인 도구
Name Description Reference
Public repository for multi-omics data
UCSC Xena Data Integration & Visualization for Public genomic repository 18 GDC Genomic Data Commons Data Portal (TCGA data portal) 19 ICGC International Cancer Genome Consortium (ICGC data portal) 20
GEO Public functional genomics data repository 21
ArrayExpress Functional genomics data store 22
CCLE Cancer Cell Line Encyclopedia 23
Omic data integration & analysis
cBioportal Integrative data analysis for public genomic repository 24 IPA Data integration and comprehensive analysis for multi-omics data 25 BRB
Arraytools Integrated package for the visualization and statistical analysis of Multi-omics data 26 Bioconductor Repository of R packages for genomic data analysis 27
Gene Ontology & Pathway
DAVID Database for Annotation, Visualization and Integrated Discovery 28 GSEA Computational genomics tool based on molecular signatures database 29
KEGG Kyoto Encyclopedia of Genes and Genomes 30
WikiPathways Collaborative platform dedicated to the curation of biological pathways 31
Estimation of Immune subset infiltration in tumor microenvironment
CIBERSORT Estimation of relative fraction of Immune subset infiltration in TME (LM22) 32 TIMER Estimation of relative fraction of Immune subset infiltration in TME (5 cell type) 33
Prediction of cancer therapeutics response
CTRP Cancer therapeutics response portal 34
GDSC Genomics of Drug Sensitivity in Cancer 35
CLUE Perturbation-driven gene expression dataset 36
Prediction of Immunotherapy response
Predictive genomics를 통한 종양 임상 표현형을 예측하는 방법론 이성환 Page 9 / 11 실제적으로 암 유전체의 체계적인 분석과 임상 데이터와의 효율적인 연계를 위해 다양한 암 유전체 코호트의 수집과 연구 목적에 맞는 다양한 분석 기법이 사용되어야 한다. 암 유전체 데이터의 수집과 분석을 위해 사용될 수 있는 다양한 도구 중 대표적인 몇 가지를 소개하고자 한다(표 1).
3. 결론
암 유전체 관련 대형 프로젝트들의 성과로 현재 우리는 과거에 상상할 수 없던 수준의 대규모 생체 데이터를 확보하였다. 인체에서 발생 가능한 주요 암종에 대한 광범위한 유전체 변이 및 이상 관련 정보들의 축적은 대중으로 하여금 암 정복에 근접했다는 장미빛 전망을 낳게 했다. 하지만 실제로 인체 내에서 벌어지는 복잡한 생명 현상의 대부분은 아직 베일에 쌓여 있으며, 암의 발생과 진행에 대한 정확한 예측 및 개별 환자에 대한 최적화된 치료적 접근은 아직 요원한 상태이다. 이러한 난제를 해결하기 위해서는 암과 관련된 복잡한 생명 현상에 대한 다학제적인 접근(Multidisciplinary approach)과 다양한 지식의 통합(Consilience)이 필수적이다. 인류의 과학사(History of Science)에 획기적 발전(Breakthrough) 들은 전통적 학문의 경계가 허물어지고 그 핵심 이론들이 통합되어 상승 효과(Synergic effect)를 거둘 때 일어났음을 우리는 기억해야 한다. 분자생물학(Molecular biology) 기초 위에 쌓아 올려진 현재의 생의학(Biomedical science) 정보 자산은 데이터 사이언스(Data science)의 분석 도구로 정밀하게 가공 및 변형되어 더욱 빛을 발할 수 있으며, 이는 임상의학(Clinical medicine)에 적극적으로 활용되어 암 환자의 예후 개선과 삶의 질 향상에 크게 기여할 것이다.4. 참고문헌
[1]. Brenton, J. D., & Caldas, C. (2003). Predictive cancer genomics—what do we need?. The Lancet, 362(9381), 340-341.
[2]. Wang, E., Zaman, N., Mcgee, S., Milanese, J. S., Masoudi-Nejad, A., & O’Connor-McCourt, M. (2015, February). Predictive genomics: a cancer hallmark network framework for predicting tumor clinical phenotypes using genome sequencing data. In Seminars in cancer biology (Vol. 30, pp. 4-12).
[3]. Hood, L., & Friend, S. H. (2011). Predictive, personalized, preventive, participatory (P4) cancer medicine. Nature reviews Clinical oncology, 8(3), 184.
[4]. Collins, F. S., & Varmus, H. (2015). A new initiative on precision medicine. New England Journal of Medicine, 372(9), 793-795.
[5]. Ritchie, M. D., Holzinger, E. R., Li, R., Pendergrass, S. A., & Kim, D. (2015). Methods of integrating data to uncover genotype–phenotype interactions. Nature Reviews Genetics, 16(2), 85.
[6]. Friedman, A. A., Letai, A., Fisher, D. E., & Flaherty, K. T. (2015). Precision medicine for cancer with next-generation functional diagnostics. Nature Reviews Cancer, 15(12), 747.
[7]. Letai, A. (2017). Functional precision cancer medicine—moving beyond pure genomics. Nature medicine, 23(9), 1028.
Predictive genomics를 통한 종양 임상 표현형을 예측하는 방법론 이성환 Page 10 / 11
[8]. Hood, L., Heath, J. R., Phelps, M. E., & Lin, B. (2004). Systems biology and new technologies enable predictive and preventative medicine. Science, 306(5696), 640-643.
[9]. Yang, L., Tan, J., O’Brien, E. J., Monk, J. M., Kim, D., Li, H. J., ... & Du, B. (2015). Systems biology definition of the core proteome of metabolism and expression is consistent with high-throughput data. Proceedings of the National Academy of Sciences, 112(34), 10810-10815.
[10]. Larance, M., & Lamond, A. I. (2015). Multidimensional proteomics for cell biology. Nature Reviews Molecular Cell Biology, 16(5), 269.
[11]. Kitano, H. (2002). Systems biology: a brief overview. Science, 295(5560), 1662-1664. [12]. Kitano, H. (2002). Computational systems biology. Nature, 420(6912), 206.
[13]. Weinstein, J. N., Collisson, E. A., Mills, G. B., Shaw, K. R. M., Ozenberger, B. A., Ellrott, K., ... & Cancer Genome Atlas Research Network. (2013). The cancer genome atlas pan-cancer analysis project. Nature genetics, 45(10), 1113.
[14]. Grossman, R. L., Heath, A. P., Ferretti, V., Varmus, H. E., Lowy, D. R., Kibbe, W. A., & Staudt, L. M. (2016). Toward a shared vision for cancer genomic data. New England Journal of Medicine, 375(12), 1109-1112.
[15]. Gomez-Cabrero, D., Abugessaisa, I., Maier, D., Teschendorff, A., Merkenschlager, M., Gisel, A., ... & Tegnér, J. (2014). Data integration in the era of omics: current and future challenges.
[16]. Malta, T. M., Sokolov, A., Gentles, A. J., Burzykowski, T., Poisson, L., Weinstein, J. N., ... & Colaprico, A. (2018). Machine learning identifies stemness features associated with oncogenic dedifferentiation. Cell, 173(2), 338-354. [17]. Camacho, D. M., Collins, K. M., Powers, R. K., Costello, J. C., & Collins, J. J. (2018). Next-Generation Machine Learning for Biological Networks. Cell.
[18]. UCSC Xena, https://xena.ucsc.edu/ [19]. GDC, https://portal.gdc.cancer.gov/ [20]. ICGC, https://dcc.icgc.org/ [21]. GEO, https://www.ncbi.nlm.nih.gov/geo/ [22]. ArrayExpress, https://www.ebi.ac.uk/arrayexpress/ [23]. CCLE, https://portals.broadinstitute.org/ccle [24]. cBioportal, http://www.cbioportal.org/ [25]. IPA, https://www.qiagenbioinformatics.com/products/ingenuity-pathway-analysis/ [26]. BRB Arraytools, https://brb.nci.nih.gov/BRB-ArrayTools/ [27]. Bioconductor, https://www.bioconductor.org/ [28]. DAVID, https://david.ncifcrf.gov/ [29]. GSEA, http://software.broadinstitute.org/gsea/index.jsp [30]. KEGG, https://www.genome.jp/kegg/ [31]. WikiPathways, https://www.wikipathways.org/index.php/WikiPathways [32]. CIBERSORT, https://cibersort.stanford.edu/ [33]. TIMER, https://cistrome.shinyapps.io/timer/ [34]. CTRP, https://portals.broadinstitute.org/ctrp/ [35]. GDSC, https://www.cancerrxgene.org/ [36]. CLUE, https://clue.io/ [37]. TIDE, http://tide.dfci.harvard.edu/
Predictive genomics를 통한 종양 임상 표현형을 예측하는 방법론 이성환 Page 11 / 11
for chemotherapy response in resectable gastric cancer: a multi-cohort, retrospective analysis. The Lancet Oncology, 19(5), 629-638.
[39]. Oh, S. C., Sohn, B. H., Cheong, J. H., Kim, S. B., Lee, J. E., Park, K. C., ... & Jang, H. J. (2018). Clinical and genomic landscape of gastric cancer with a mesenchymal phenotype. Nature communications, 9(1), 1777.
The views and opinions expressed by its writers do not necessarily reflect those of the Biological Research Information Center.
이성환(2018). Predictive genomics 를 통한 종양 임상 표현형을 예측하는 방법론. BRIC View 2018-T33 Available from http://www.ibric.org/myboard/read.php?Board=report&id=3065 (Sep 11, 2018) Email: [email protected]
![그림 5. 암 유전체를 이용한 중개연구와 관련된 핵심 키워드. [API, Application Programming Interface; TME, Tumor Micro-environment]](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5123479.86613/7.892.91.796.245.870/유전체를-이용한-중개연구와-관련된-application-programming-interface-environment.webp)