서론
1.
정보 추출(information extraction)은 자연언어 처리 분야에서 중요한 과업 (natural language processing)
중 하나이며, DBpedia[1], Freebase[2], YAGO[3]와 같이 다양한 대규모 지식 베이스들을 기반으로 자연언어 텍스 트로부터 지식을 추출하는 다양한 연구가 진행중이다. 지식베이스 확장(knowledge base population)을 위한 정 보 추출 시스템은 개체 연결(entity linking)과 관계 추 출(relation extraction) 두 가지 단계가 필수적이다. 주어진 텍스트에서 지식베이스 개체와 연결 가능한 명사 혹은 명사구를 찾는 개체 연결 단계 후, 관계 추출 단계 에서는 텍스트 내 개체들 간의 의미적 관계(semantic 를 추출하여 지식베이스 단위 지식인 트리플 relation) 을 생성한다 (triple) . 원격 지도 학습[4]이 발표된 이래로 관계 추출에 대한 활발한 연구가 진행되어 왔으며, 최근에는 딥러닝(deep 모델을 이용한 관계 추출이 연구의 주류가 되 learning) 었다. 다양한 딥러닝 기반 관계 추출 모델들이 제안되었 지만, 많은 연구에서 CNN(convolutional neural 을 사용하며 의 장점은 모델 스스로 특 network)[5] , CNN 징을 추출해 학습을 진행한다는 것이다. 따라서 CNN 기 반 관계 추출 모델은 각 관계별 중요한 n-gram 단어를 인식하는 방식으로 모델을 학습한다. CNN 기반 관계 추 출 모델은 Yoon Kim[6]의 논문에서 제시한 기본 구조를 토대로 다양한 특징을 추가하는 방식으로 연구가 진행되 어왔다. PCNN 모델[7]은 입력 문장의 모든 토큰(token) 이 두 타겟 개체(target entity)와의 상대 거리 를 계산하고
(relative distance) , Piecewise Max 층으로 확장하였다 다른 연구에서는 형태소와 Pooling . 다중 어의 단어 임베딩을 특징으로 추가하는 연구- [8]가 수행되었다. 최근에는 Attention을 도입[9]하고, 강화학 습(reinforcement learning)을 적용하는 등의 연구[10, 가 진행중이다 11, 12] . 원격 지도 학습 방식의 가장 큰 문제는 노이즈 데이터 문제이다 원격 지도 학습은 지식베이스 (noise data) . 트리플의 두 개체를 포함하는 모든 문장을 코퍼스에서 수집하여 트리플의 관계로 자동 레이블링(labeling)하는 방식으로, 자동 레이블링된 문장 중 하나 이상은 해당 관계를 의미할 것이라는 가정을 기반으로 한다. 따라서 두 개체 사이의 관계를 설명하지 않는 문장이 훈련 데이 터로 수집되는 경우가 많다. 최근 한 연구[12]에서 원격 지도 학습 수집 데이터의 노이즈 데이터 비율을 분석한 결과, W ikipedia와 YAGO를 기준으로 했 을 때 뉴74.1%, 욕 타임즈 코퍼스(NYT News)와 Freebase를 기준으로 했 을 때 31.0%로 상당히 높은 노이즈 비율을 보였다. 여기 서 노이즈 데이터라고 함은 문장에서 관계를 설명하는 결정적 단서가 존재하지 않는 경우를 의미한다예. 를 들 어아, 래의 경우는 세종대왕의 국적(nationality)이 조 선이라는 트리플과 연결되나, 국적을 알 수 있는 결정적 단서가 없으므로 이는 노이즈 데이터에 해당한다. S1: “세종대왕이 조선에서 태어났다.” T1: nationality(세종대왕, 조선)
원격 지도 학습 데이터 노이즈 제거를 위해 확장된 최단
의존 경로를 이용한
CNN
기반 관계추출
남상하O, 한기종 최기선, 한국과학기술원, 시맨틱웹첨단연구센터 {nam.sangha, han0ah, kschoi}@kaist.ac.krA CNN-based Relation Extraction with Extended Shortest Dependency
Path for Noise Reduction of Distant Supervision
Sangha NamO, Kijong Han, Key-Sun Choi KAIST, Semantic W eb Research Center
요 약 관계 추출을 위한 원격 지도 학습은 사람의 개입 없이 대규모 데이터를 생성할 수 있는 효율적인 방법이 다 그러나 원격 지도 학습은 노이즈 데이터 문제가 있으며 노이즈 데이터는 두 가지 유형으로 나눌 수 . , 있다 첫 번째는 관계 표현 자체가 없는 문장이 연결된 경우이고 두 번째는 관계 표현은 있는 문장이지만 . , 다른 관계 표현도 함께 가지는 경우이다 주로 문장의 길이가 길고 복잡한 문장에서 두 번째 노이즈 데이. 터 유형이 자주 발견된다 본 연구는 두 번째 경우의 노이즈를 줄임으로써 관계 추출 모델의 성능을 향상. 시키기 위해 확장된 최단 의존 경로를 사용하는 CNN 기반 관계 추출 모델을 제안한다 본 논문에서 제안. 한 방법의 우수성을 입증하기 위해 한국어 위키피디아와 , DBpedia 기반의 원격 지도 학습 데이터를 수집 하여 평가한 결과 본 논문에서 제안한 방법이 위 문제를 해결하는데 효과적이라는 것을 확인하였다, . 주제어 원격 지도 학습 관계 추출 합성곱 신경망 노이즈 필터링: , , ,
원격 지도 학습 기반 관계 추출의 많은 연구들이 위와 같은 잘못 된 문장을 제거하는 것에 초 점이 맞 추어져 있 으나, 본 연구에서는 주로 복잡한 문장에서 발생하는 현 상에 대해 정의하고, 이를 해결할 수 있는 방법에 대해 제안한다. S2: “1570년에 기사도 로망스 소설 돈키호테를 쓴 작 가 미구엘 세르 반테스가 나폴리에서 스페인 군인으로 복 무하였다.” T2-1: notableWork(미구엘 세르반테스_ , 돈키호테) T2-2: occupation(미구엘 세르반테스군인_ , ) T2-3: nationality(미구엘 세르반테스_ , 스페인) 위의 경우는 하나의 문장에 개의 관계가 레이블링 된 3 경우이다. 즉동, 일한 입력 문장으로 타겟 개체만 바뀐 채 개의 서로 다른 관계를 구분해야 하는 경우이다3 . 특 히, T 2-1(writer)의 경우는 노이즈 데이터가 아닌 긍적 적 레이블링 결과이다. CNN 모델의 장점이 중요 n-gram 키워드를 스스로 골 라 학습한다는 점이지만, 위 경우처 럼 비슷한 유형의 문장이 서로 다른 관계로 학습이 되는 데이터가 많을 경우 그 분별력은 떨어질 수밖에 없다 . 이런 데이터는 영어에서 뿐만 아니 라, W한국어 ikipedia 와 DBpedia 간 수집한 원격 지도 학습 데이터에서도 발 생하는 경우이며, 골드 스탠다드를 기준으로 약 35.8%가 해당한다. 위와 같은 경우가 발생하는 조건은, 한 문장 내 최소 개 이상의 개체와 이 개체들간의 조합으로 이3 루어진 관계가 최소 개 이상인 것으로2 , 주로 길이가 길 고 복잡한 문장에서 발생한다. 따라서 본 논문에서는 다양한 데이터 분석을 통 해 두 개체간의 관계를 설명하는 설명 이외에 불 필요한 표현 을 제거하기 위한 확장된 최단 (irrelevant expression)
의존 경로(ESDP: extended shortest dependency path)를 이용한 CNN 관계 추출 모델을 제안한다. 일반적으로 두 개체간의 관계를 표현하는 핵심 표현은 최단 의존 경로
의 표현들이지만 (SDP: shortest dependency path) , SDP 만 사용할 경우 다음 가지 문제가 생길 수 있다2 . 관계를 분별하기에 좋은 표현이 에서 제외되는 1. S DP 경우 서로 다른 관계들이 동일한 를 가지는 경우 2. SDP 따라서 본 논문에서는 ESDP를 정의하고, 이를 CNN 기 반 관계 추출 모델 적용하고 실제 원격 지도 학습 데이 터에서 실험한 결과에 대해 소개한다.
2. ESDP
두 개체간의 관계를 추출하기 위해 필요한 핵심 정보 는 SDP에 표현되어 있 는 경우가 많다그. 러나 장에서 1 언급하였듯이, SDP만 사용해서 관계 추출의 표현으로 학 습을 진행하기에는 가지 문제가 발생할 수 있다2 . 그림 1 ESDP 예시1. 붉은 실선은 두 타겟 개체 사이의 를 나타내고 점선은 로 확장 표현되는 것을 나 SDP , ESDP 타낸다. 먼저 첫 번째 문제에 해당하는 예시는 그림 과 같다1 . 위 그림의 예시를 보면, 타겟 개체인 돈키호테 와 미구‘ ’ ‘ 엘 세르 반테스’ 사이의 SDP는 [e1, 쓴, e2]로쓰, ‘ 다 가 ’ 다양한 의미로 쓰일뿐더러 SDP 주변 단어인 작 가‘ ’, ‘소 설 등이 함께 학습에 사용된다면 ’ CNN 모델이 특징을 잡 아내기 더 쉬워진다. 게다가 나폴리에서 스페인 군인으“ 로 복무 하였다 는 ” writer를 학습하는데 불 필요한 정보 로, 이를 미리 모델 입력에서 걸러준다면 빠르고 정확한 모델 학습이 가능하다. 그림 2 ESDP 예시 2 두 번째 문제에 해당하는 예 시는 그림 와 같다2 . 위 그림의 예 시를 보면, order와 languageFamily 두 관계는 분명 그 의미가 다름에도 불구하고 타겟 개체만 바뀐 채 가 동일하다또 한 속 하다 는 뜻 도 관계되어 딸리 SDP . ‘ ’ ‘ 다 의 의미를 공유한다’ . 즉이, 런 경우는 단순히 SDP만 가지고 두 관계를 구분할 수 있는 단서가 부족한 문제가 발생한다. 본 연구에서는 원격 지도 학습 데이터 중 노이즈 데이 터를 제거한 골드 스탠다드 중 위와 같은 경우가 발생하 는 사례 분석을 통해 ESDP를 다음과 같이 정의하였다. ESDP = [NPM of e1, SDP, EV, NPM of e2] 먼저 SDP는 최단 의존 경로로 두 타겟 개체 사이의 의존 구조 경로 상 최단 경로를 의미하며 두 타겟 개체 또 한 포함된다그. 리고 NPM(noun phrase modifier)은 명사 구 수식어로 두 타겟 개체의 의존 구조 상 수식 관계를 가지는 모든 단어들을 뜻 한다. EV(external verb)는 만 약 SDP에 동사 표현이 하나도 없을 경우 문장의 핵심 동 사인 Root V erb를 ESDP에 포함시킨다. 추가적으로, 의존 구조 경로 상 밝혀진 레이블(label)을 토큰 사이에 추가 하여 ESDP를 완 성한다. 그림 의 예 시에 대한 1 ESDP는 기사도 로망스 소설 돈 키호테를 [ _ , NP, , NP, _ , , NP_OBJ, 쓰미구, VP_MOD, 엘 데 세르반테스_ _ , 가, NP_SBJ, 작가, 이며 그림 의 예 시에 대한 는 각각 비단털쥐 NP] , 2 ESDP [ 과, NN, 설치류, 에, NP_AJT, 속하목, VP_MOD, 화쥐아 과, 의, NP_MOD, 남아메리카인도, NP], [ 유럽어족의, , 발틱어 에속 하 리투아니아
NP_MOD, , , NP_AJT, , VP_MOD,
어, 를, NP_OBJ] 이다. 본 연구에서는 ETRI 한국어 의존 구조 분석 도구를 사용하여 ESDP를 자동 생성하였다.
3. ESDP CNN
모델의 특징이자 장점 중 하나는 가장 유익한 CNN 단어를 스스로 학습할 수 있 다는 (informative) n-gram 것이다. 본 연구에서는 Zeng의 연구[7]J를 ava 기반의 로 재구현하고 를 적Deeplearning4J Framework[13] , ESDP 용하였다. 3.1 Input Vector 기반 관계 추출 모델을 설계함에 있어 중요한 요 CNN 소 중 하나는 입력 벡 터이다. 입력 벡 터로는 단어 임베 딩(word embedding)이 필수적이며, 형태소나 개체 위치 임베딩(position embedding)이 추가될 수 있 다. 따라서 단어 임베딩을 어떻게 학습하느냐가 CNN 기반 관계 추출 모델을 설계하는데 있 어 매 우 중요하다. 영어권의 많은 연구들에서는 미리 학습된 단어 임베딩을 가져다 사용하 지만, 한국어에서는 어미에 따라 단어의 성질이 바뀌 고 어근이 띄어쓰기 기준으로는 구분하기 힘들다는 성격 때 문에 형태소 단위의 단어 임베딩을 새 로 만들어서 사용 하는 것이 일반적이다. 본 연구에서는 형태소 단위의 단 어 임베딩에 여러 단어로 구성된 개체(multi-word 가 하나의 임베딩 값 을 가지도록 단어 임베딩을 entity) 학습하였다. 여러 단어로 구성된 개체를 하나의 임베딩 값으로 만드는 방법은 여러 가지가 있고, 대표적으로 두 단어의 임베딩 값 을 더 하는 것이 일반적이다예. 를 들 어, ‘스티브 잡 스 라는 단어는 스티브 의 임베딩 값 과 ’ ‘ ’ 잡스 의 임베딩 값 을 단순히 더함으로써 스티브 잡스 ‘ ’ ‘ ’ 의 임베딩 값을 구할 수 있 으나, 본 연구에서는 스티브 ‘ 잡스 를 하나의 토큰으로 구성하여 ’ Skip-gram 알고리즘 을 통해 학습을 진행하였다그 결과 알버트 아인 [14] . , ‘ 슈타인 과 벡 터 공간상 근접한 단어들로 아 인슈타인’ ‘ ’, 아이작 뉴턴 상대성 이론 그리고 제임스 클러크 맥 ‘ ’, ‘ ’, ‘ 스웰 등이 위치하는 단어 임베딩 결과를 얻었다’ . 3.2 Model Architecture 그림 3 ESDP CNN 모델 아키텍처 그림 은 3 ESDP CNN 모델 아키텍처를 나타낸 것이다. 모델의 기본 구조는 Zeng의 모델과 동일하며 문장 전체, 를 입력으로 사용하지 않고 두 타겟 개체 사이의 ESDP 를 입력으로 사용한 점이 차이점이다. 첫 번째 단계로 입력 문장에 대해 각 단어마다 형태, 소 단위로 분할한다 그 다음 모델의 입력을 . !"∈# $ 이라 고 할 때 번째 토큰의 단어 임베딩 값과 위치 임베딩 i 값을 가져온다 그리고 . feature map은 %∈#&×$ 로 표현 할 수 있고 각 , fea ture ci는 (")*+,⊙%"./01. 23로 계산
된다. *는 하이퍼 탄젠트(hyperbolic tangent)와 같은 활 성 함수(activation function)이고, 2∈#는 바이어스(bias), ⊙은 element-wise 곱 연산을 뜻한다 이 . feature는 모든 입력 단어들에 대해 h-window씩 적용하여 4 )5(16(76⋯6 (&0/.19을 생성한다. Max-pooling 단계에서는
(max)max+43로 최대값을 추출한다. Piecewise max 은 을 개체의 두 위치를 기준으로 분 pooling max-pooling 할하여 5(max=9 ) max+4 164764>3로 각 최대값을 추출한다. 그리고 모델에 복수개의 convolution layer를 도입하여 여러 feature map을 학습하기 위해서 ? )5(1max6(7max6…6 (@max9를 적용한다.
실험
4.
4.1 Dataset 본 연구에서는 한국어 위키피디아(2017.06.01.) 전문 과 한국어 디 비피디아[15]를 이용해 원격 지도 학습 데 이터를 생성하였고, ESDP CNN 모델의 성능 평가 실험 및 결과 분석을 수행하였다. 원격 지도 학습 결과 생성되는 레이블 데이터(labeled data)는 두 개체를 포함한 문장 과 그 관계 쌍(pair)를 의미한다. 원격 지도 학습으로 수집된 레이블 데이터 중 관계별 빈도수가 높 은 54개 관계를 학습과 평가에 사용하였고, 이는 영 어에서 공 용데이터로 활용되는 TAC-KBP slot 의 개 관계 의 개 관계와 비 filling[16] 41 , NYT10[17] 51 교했을 때 조금 더 많은 수준이라고 볼 수 있다 . 개 관계로 수집된 약 만개 레이블 데이터 중 사람 54 24 이 수작업으로 노이즈를 제거한 약 만개 레이블 데이터 8 중 절반인 만개를 평가에 사용하였으며4 , 나머지 21만개 를 학습에 사용하였다.4.2 Results
Model Embedding Precision Recall F1
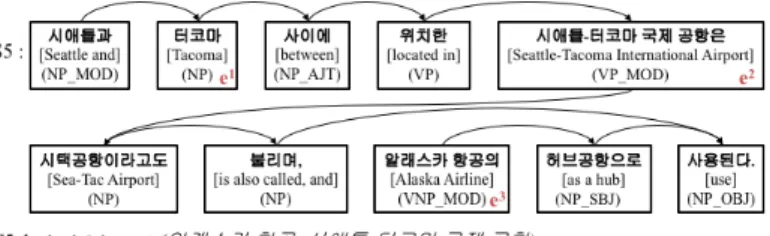
Baseline Space 56.67 30.58 39.51 MSWE MSWE 52.35 44.95 48.37 ALL POS 51.02 42.94 46.63 SDP POS 53.9 47.77 50.65 ESDP POS 53.06 51.68 52.36 표 1 입력 형태에 따른 성능 비교 평가표 본 연구에서 제안한 ESDP CNN 방식의 우수성을 입증하 기 위해 다른 모델들과의 성능 비교 실험을 수행하였고, 결과는 표 과 같다먼저1 . Baseline은 Zeng의 논문을 재 구현한 모델로영, 어와 동일한 방식으로 공백 단위의 토 큰화 기반의 단어 임베딩을 학습하여 적용한 것이다. 두 번째인 MSWE CNN[8]은 단어 중의성 해소(word sense 모듈을 활용한 단어 임베딩 학습 모델 disambiguation) 어의 중의성 해소 모델 로 쓰 다 의 의미가 글을 쓰는 ( - ) “ ” “ 지”, “모자를 쓰 는지”, “도구를 활용하는지맛”, “ 이 쓴 지” 등을 미리 구분하여 단어 임베딩을 학습한 모델이 다세. 번째 인 ALL은 본 연구에서 제안한 방식의 단어 임베딩과 전체 문장을 모델의 입력으로 넣었을 때의 결 과이며, S나머지 DP와 ESDPSDP는 각각 전 체 문장 대신 와 ESDP를 입력으로 넣은 모델이다. 실험 결과로 우리는 총 가지 결론을 얻을 수 있다4 . 첫 번째는 Baseline과 MSWE CNN, ALL의 비교로, 한국어 와 같은 교착어는 형태소 단위의 토큰화가 단어 임베딩 학습과 CNN 기반 관계 추출 모델의 성능 향 상에 효과적 임을 알 수 있다. 두 번째는 어의 중의성 해소 모델이 -형태소 단위의 단어 임베딩만 사용한 경우보다 성능이 높지만, SDP 보다는 성능이 낮다는 것을 알 수 있다. 세 번째는 SDP 모델이 문장 전 체를 입력으로 사용한 것 보 다 성능이 나아짐을 알 수 있 으며네, ESDP 번째는 가 는 물론이고 다른 비교 모델보다 성능이 높다는 것을 SDP 알 수 있다. 특히 Baseline을 기준으로 F1 score 13% 가 량 향상됨을 확인할 수 있다. 4.3 Analysis 의 성능 비교 실험을 통 해 가 관계 추출 모델 4.2 ESDP 의 성능을 향 상시킬 수 있는데 효과적임을 알 수 있다 . 추가적으로, 본 논문에서 제안한 문제인 복잡한 문장에‘ 서의 불필요한 표현 제거 에 ’ ESDP가 효과가 있었는지 확 인하는 실험을 수행하였다. 실험 데이터는 골드 스탠다 드 약 만개 레이블 데이터이며8 , 우리는 두 그룹으로 데 이터를 분할하였다첫. 번째는 복잡 한 문장으로 구성된 그룹이며, 30,326 레이블 데이터로 구성된다. 복잡한 문 장의 기준은 문장이 최소 개 이상의 개체를 가지고 있3 으며, 이 개체들 간의 조합으로 최소 개 이상의 서로 2 다른 관계로 레이블 데이터가 생성되는 경우이다. 그림 4 복잡한 문장의 의존 구조 예시 그림 는 복잡한 문장의 예시를 나타낸 것으로4 , 3개의 개체 타코마타코‘ ’, ‘ 마 공항’, ‘알라스카 항공 이 있으’ 며, h이들간의 관계는 알ubAirport< 라스카 항공, 타코마 공항>, city<타코마 공항타코, 마 로 개이다> 2 . 즉, 동일 한 문장으로 서로 다른 두 관계를 구분해야 되는 경우에 해당한다. 두 번째 그룹은 단순한 문장으로 구성된 그룹 이며, 54,441 레이블 데이터로 구성된다.
Model Group Precision Recall F1 Length ALL complexsimple 49.2452.48 42.4442.88 45.5947.2 25.330 SDP complexsimple 52.3654.5 47.4447.27 50.7349.68 8.757.85 ESDP complexsimple 53.5252.21 50.6451.8 52.6551.41 10.158.9
표 2 두 그룹 간 성능 비교 평가표 우리는 이 두 그룹의 데이터를 각 모델의 테스트 데이 터로 사용하여 성능을 측 정해보았으며그, 결과는 표 2 와 같다. 표 의 결과에서 알 수 있듯이2 , 복잡한 문장은 단순한 문장보다 평균 길 이가 더 길다는 것을 알 수 있 고, ESDP를 사용하였을 때 의 관계 추출 성능은 복잡한 문장이 단순한 문장보다 더 높은 성능 향상 정도를 보여 준다.
결론
5.
본 연구에서는 원격 지도 학습 데이터에서 발생하는 복잡한 문장에 대한 불 필요한 표현 문제 해소를 위해 모델을 제안하였고 성능 비교 평 가 및 결과 ESDP CNN , 분석을 통 해 본 제안 방법이 효과가 있음 을 입증하였다. 또한 한국어에서는 영 어와 달리 형태소 단위의 토큰화 단어 임베딩이 관계 추출 모델의 성능에 있어 중요한 요 소임을 확인하였고, 향후에는 원격 지도 학습 데이터의 일반적인 노이즈 문제 해결 방법과 결합하여 두 가지 노 이즈를 모두 해소할 수 있는 모델에 대한 연구를 진행할 계획이다 .사사
이 논문은 2018년도 정부 과학기술정보통신부 의 재원으( ) 로 정보통신기술진흥센터의 지원을 받아 수행된 연구임 빅데이터 이해 기반 자가학습형 (2013-0-00109, WiseKB: 지식베이스 및 추론 기술 개발)참고문헌
[1] Soren Auer, Christian Bizer, Georgi Kobilarov, JensLehmann, Richard Cyganiak, and Zachary Ives. "Dbpedia: A nucleus for a web of open data." In The semantic web, pages 722 735. Springer, 2007.– [2] Kurt Bollacker, Colin Evans, Praveen Paritosh,
TimSturge, and Jamie Taylor. " Freebase: a collaboratively created graph database for structuring h uman knowledge." In Proceedings of the 2008 ACM SIGMOD international conference on Management of data, pages 1247 1250. AcM, 2008.– [3] Fabian M S uchanek, Gjergji Kasneci, and
GerhardWeikum. "Yago: a core of semantic knowledge." I n Proceedings of the 16th international conference on World Wide Web, pages 697 706. ACM, 2007.–
[4] Mike Mintz, Steven Bills, Rion Snow, and Dan Jurafsky. "Distant supervision for relation extraction without labeled data." I n Proceedings of the J oint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Vol-ume 2-Volume 2, pages 1003– 1011. Association for Computational L inguistics, 2009.
[5] Yoshua Bengio et al., "Learning deep architectures for ai." Foundations and trendsR©in MachineLearning, 2(1):1 127. 2009.– [6] Yoon Kim. "Convolutional neural networks for
sentence classification." In Proceedings of EMNLP, pages 1746 1751. 2014. –
[7] Daojian Zeng, Kang Liu, Yubo Chen, and Jun Zhao. "Distant supervision for relation extraction viapiecewise convolutional neural networks." In Proceedings of EMNLP, pages 1753 1762. 2015.– [8] Sangha Nam, Kijong H an, Eun-kyung Kim, and
Key-Sun Choi. " Distant supervision for relation extraction with multi-sense word embedding." In Global Wordnet Conference, Workshops on Wordnets and Word Embeddings. 2018.
[9] Yankai Lin, Shiqi Shen, Zhiyuan Liu, Huanbo Luan,and Maosong S un. "Neural relation extractionwith selective attention over instances." In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pages 2124 2133. 2016.–
[10] Xiangrong Z eng, Shizhu H e, Kang L iu, and Jun Zhao. "Large scaled relation extraction with reinforcement learning." Relation, 2:3. 2018. [11] Jun Feng, Minlie Huang, Li Zhao, Yang Yang, and
Xiaoyan Zhu. "Reinforcement learning for rela-tion classification from noisy data." In
Proceedings of AAAI. 2018.
[12] Chengsen R u, Jintao Tang, Shasha Li, S ongxian Xie,and Ting Wang. "Using semantic similarity to reduce wrong labels in distant supervision for relation extraction." I nformation Processing & Management, 54(4):593 608. 2018.– [13] Team, D., et al. "Deeplearning4j: Open-source
distributed deep learning for the jvm." Apache Software Foundation License 2. 2016.
[14] Mikolov, T omas, et al. "Distributed representations of words and phrases and their compositionality." Advances in neural information processing systems. 2013.
[15] Eun-kyung Kim, Matthias Weidl, Key-Sun Choi, and S oren Auer. "Towards a korean dbpedia and anapproach for complementing the korean wikipedia based on dbpedia." OKCon, 575:12 21. – 2010.
[16] Mihai Surdeanu. " Overview of the tac 2013 knowledge base population evaluation: English slot filling and temporal slot filling." I n TAC. 2013.
[17] Sebastian Riedel, S ebastian Riedel, Limin Yao, and Andrew McCallum. " Modeling relations and their mentions without labeled text." I n Proceedings of ECML PKDD, pages 148 163. 2010.–